







文 | 陀飞轮&圈圈&年年的铲屎官
源 | 知乎
tips总结
知乎答主:陀飞轮
谈一下自己知道的。尽量避开优化器、激活函数、数据增强等改进。。先上完整列表:
Deep Learning: Cyclic LR、Flooding
Image classification: ResNet、GN、Label Smoothing、ShuffleNet
Object Detection: Soft-NMS、Focal Loss、GIOU、OHEM
Instance Segmentation: PointRend
Domain Adaptation: BNM
GAN: Wasserstein GAN
Deep Learning
Standard LR -> Cyclic LR
SNAPSHOT ENSEMBLES: TRAIN 1, GET M FOR FREE
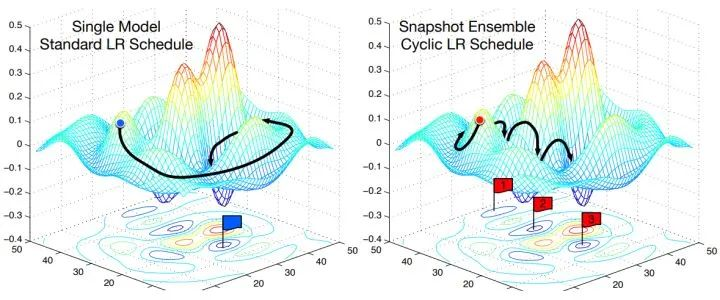
每隔一段时间重启学习率,这样在单位时间内能收敛到多个局部最小值,可以得到很多个模型做集成。
#CYCLE=8000, LR_INIT=0.1, LR_MIN=0.001
scheduler = lambda x:
((LR_INIT-LR_MIN)/2)*(np.cos(PI*(np.mod(x-1,CYCLE)/(CYCLE)))+1)+LR_MIN
Without Flooding -> With Flooding
Do We Need Zero Training Loss After Achieving Zero Training Error?
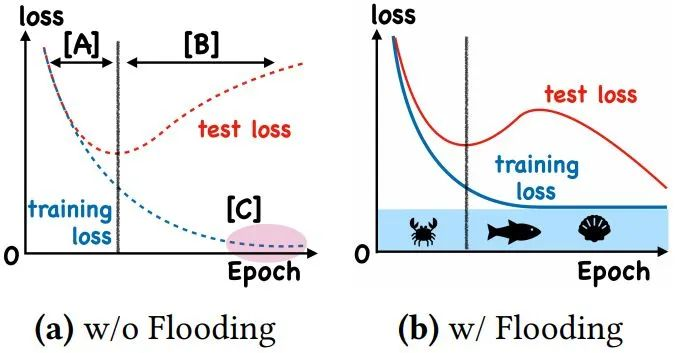
Flooding方法:当training loss大于一个阈值时,进行正常的梯度下降;当training loss低于阈值时,会反过来进行梯度上升,让training loss保持在一个阈值附近,让模型持续进行“random walk”,并期望模型能被优化到一个平坦的损失区域,这样发现test loss进行了double decent!
flood = (loss - b).abs() + b
Image classification
VGGNet -> ResNet
Deep Residual Learning for Image Recognition
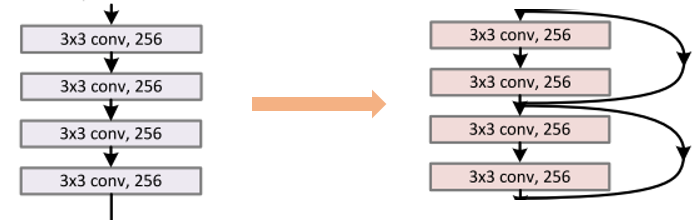
ResNet相比于VGGNet多了一个skip connect,网络优化变的更加容易
H(x) = F(x) + x
BN -> GN
Group Normalization
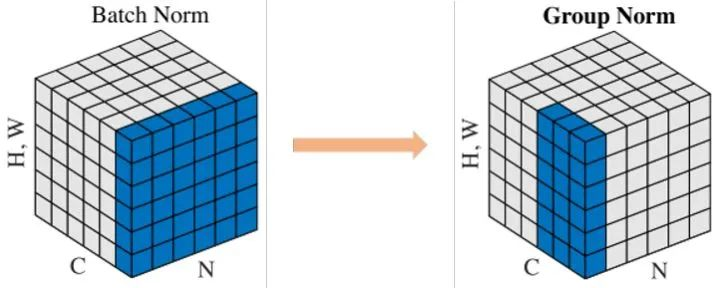
在小batch size下BN掉点严重,而GN更加鲁棒,性能稳定。
x = x.view(N, G, -1)
mean, var = x.mean(-1, keepdim=True), x.var(-1, keepdim=True)
x = (x - mean) / (var + self.eps).sqrt()
x = x.view(N, C, H, W)
Hard Label -> Label Smoothing
Bag of Tricks for Image Classification with Convolutional Neural Networks
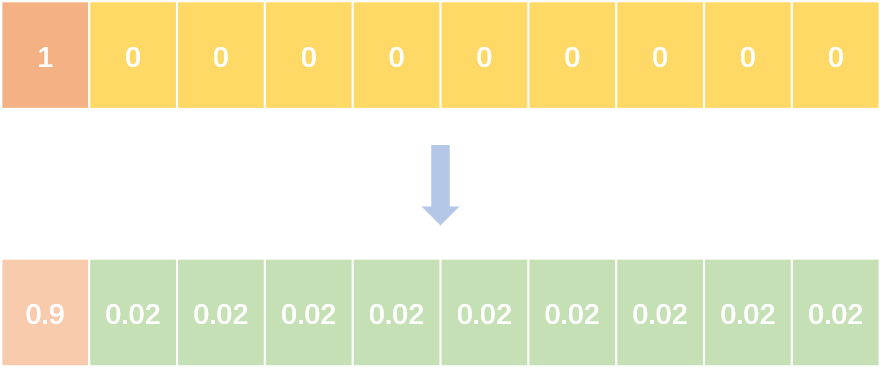
label smoothing将hard label转变成soft label,使网络优化更加平滑。
targets = (1 - label_smooth) * targets + label_smooth / num_classes
MobileNet -> ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
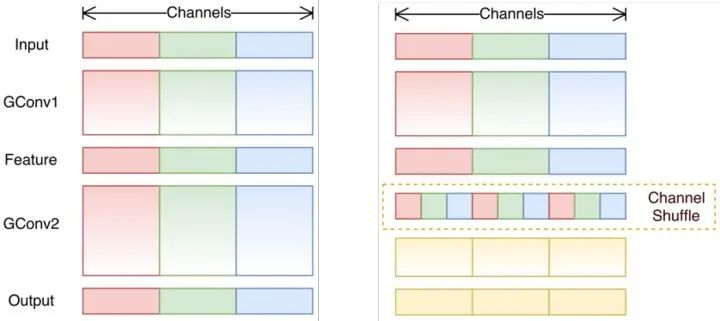
将组卷积的输出feature map的通道顺序打乱,增加不同组feature map的信息交互。
channels_per_group = num_channels // groups
x = x.view(batch_size, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
x = x.view(batch_size, -1, height, width)
Object Detection
NMS -> Soft-NMS
Improving Object Detection With One Line of Code
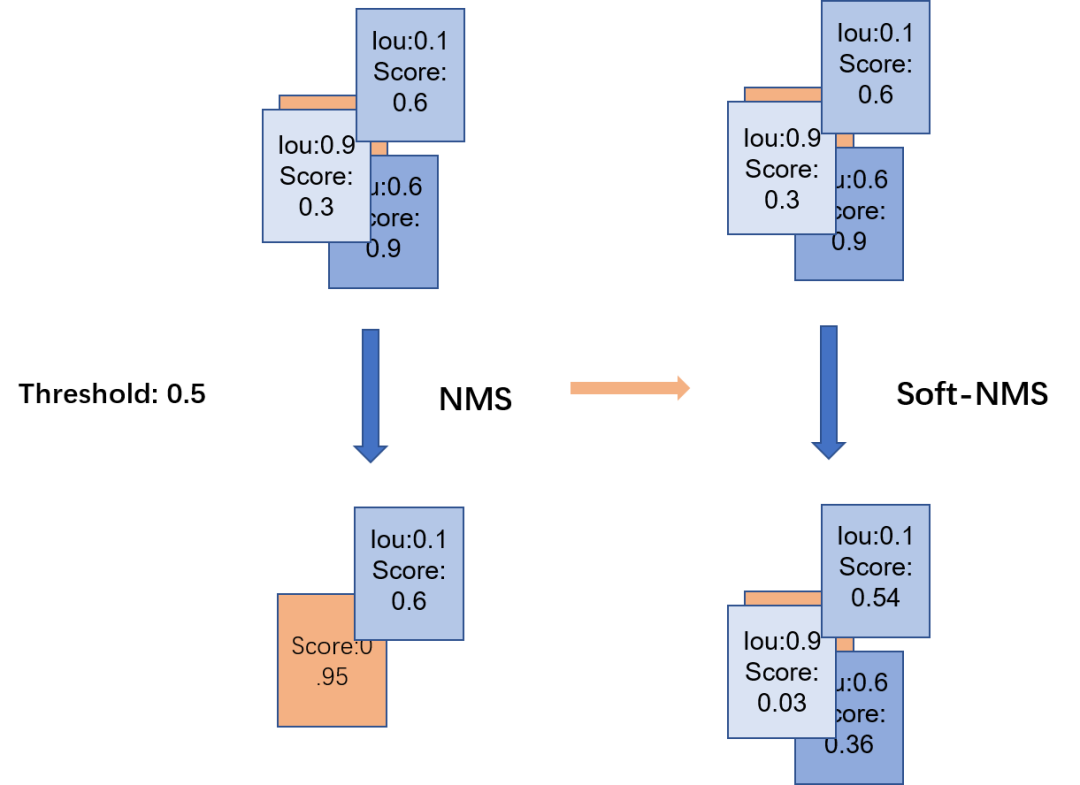
Soft-NMS将重叠率大于设定阈值的框分类置信度降低,而不是直接置为0,可以增加召回率。
#以线性降低分类置信度为例
if iou > threshold:
weight = 1 - iou
CE Loss -> Focal Loss
Focal Loss for Dense Object Detection
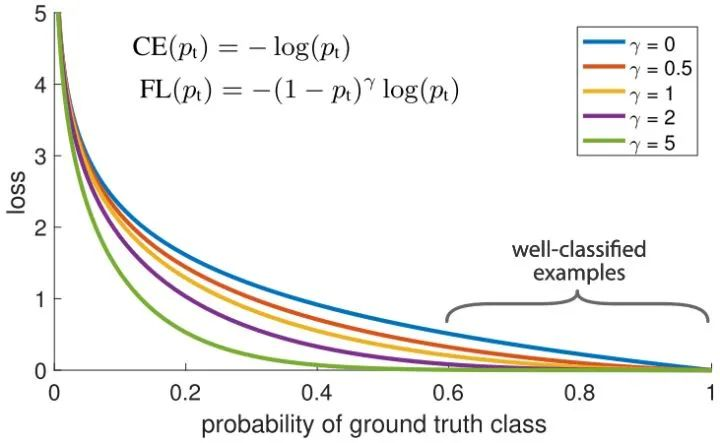
Focal loss对CE loss增加了一个调制系数来降低容易样本的权重值,使得训练过程更加关注困难样本。
loss = -np.log(p) # 原始交叉熵损失, p是模型预测的真实类别的概率,
loss = (1-p)**GAMMA * loss # GAMMA是调制系数
IOU -> GIOU
Generalized Interp over Union: A Metric and A Loss for Bounding Box Regression
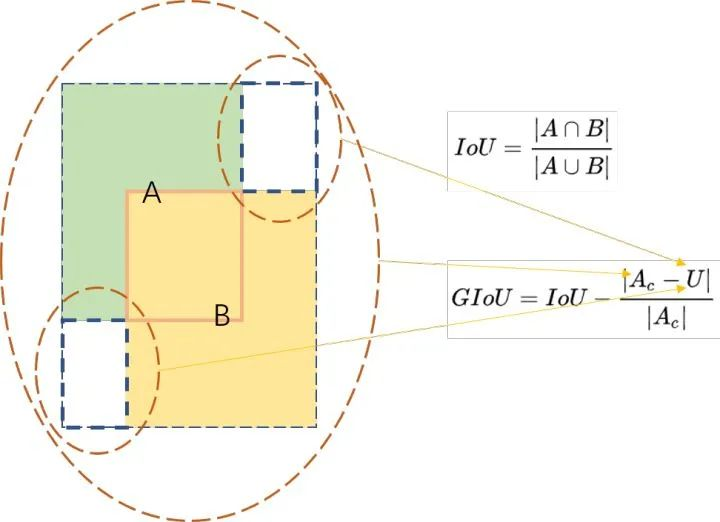
GIOU loss避免了IOU loss中两个bbox不重合时Loss为0的情况,解决了IOU loss对物体大小敏感的问题。
#area_C闭包面积,add_area并集面积
end_area = (area_C - add_area)/area_C #闭包区域中不属于两个框的区域占闭包区域的比重
giou = iou - end_area
Hard Negative Mining -> OHEM
Training Region-based Object Detectors with Online Hard Example Mining
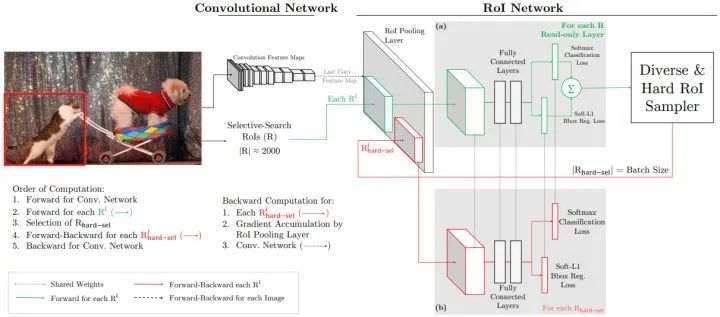
OHEM通过选择损失较大的候选ROI进行梯度更新解决类别不平衡问题。
#只对难样本产生的loss更新
index = torch.argsort(loss.sum(1))[int(num * ohem_rate):]
loss = loss[index, :]
Instance Segmentation
Mask R-CNN -> PointRend
PointRend: Image Segmentation as Rendering
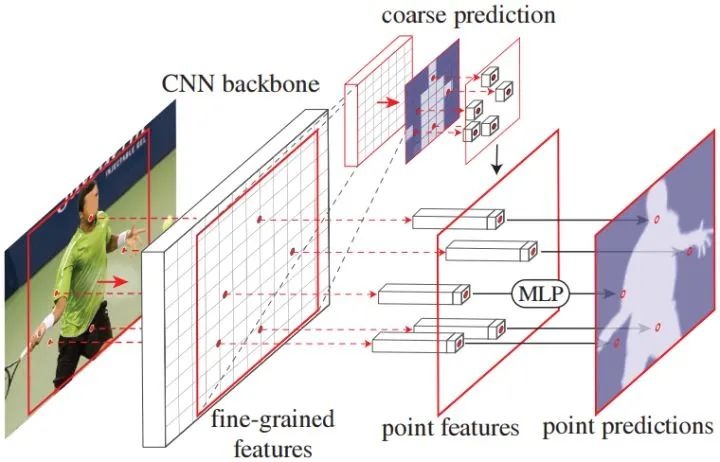
每次从粗粒度预测出来的mask中选择TopN个最不确定的位置进行细粒度预测,以非常的少的计算代价下获得巨大的性能提升。
points = sampling_points(out, x.shape[-1] // 16, self.k, self.beta)
coarse = point_sample(out, points, align_corners=False)
fine = point_sample(res2, points, align_corners=False)
feature_representation = torch.cat([coarse, fine], dim=1)
Domain Adaptation
EntMin -> BNM
Towards Discriminability and Diversity: Batch Nuclear-norm Maximization under Label Insufficient Situations
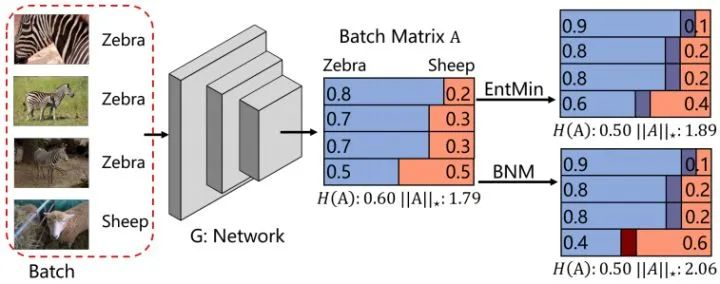
类别预测的判别性与多样性同时指向矩阵的核范数,可以通过最大化矩阵核范数(BNM)来提升预测的性能。
L_BNM = -torch.norm(X,'nuc')
GAN
GAN -> Wasserstein GAN
Wasserstein GAN
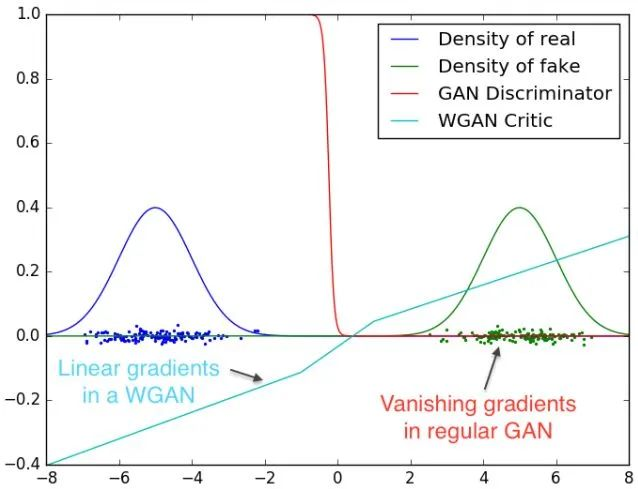
WGAN引入了Wasserstein距离,既解决了GAN训练不稳定的问题,也提供了一个可靠的训练进程指标,而且该指标确实与生成样本的质量高度相关。
Wasserstein GAN相比GAN只改了四点:
判别器最后一层去掉sigmoid
生成器和判别器的loss不取对数
每次更新把判别器参数的绝对值按阈值截断
使用RMSProp或者SGD优化器
知乎答主:圈圈
relu:用极简的方式实现非线性激活,还缓解了梯度消失
x = max(x, 0)normalization:提高网络训练稳定性
x = (x - x.mean()) / x.std()gradient clipping:直击靶心 避免梯度爆炸
hhhgrad [grad > THRESHOLD] = THRESHOLD # THRESHOLD是设定的最大梯度阈值dropout:随机丢弃,抑制过拟合,提高模型鲁棒性
x = torch.nn.functional.dropout(x, p=p, training=training) # 哈哈哈调皮了,因为实际dropout还有很多其他操作,不够仅丢弃这一步确实可以一行搞定x = x * np.random.binomial(n=1, p=p, size=x.shape) # 这里p是想保留的概率,上面那是丢弃的概率skip connection(residual learning):提供恒等映射的能力,保证模型不会因网络变深而退化
F(x) = F(x) + xfocal loss:用预测概率对不同类别的loss进行加权,缓解类别不平衡问题
loss = -np.log(p) # 原始交叉熵损失, p是模型预测的真实类别的概率loss = (1-p)**GAMMA * loss # GAMMA是调制系数attention mechanism:用query和原始特征的相似度对原始特征进行加权,关注想要的信息
attn = torch.softmax(torch.matmul(q, k), dim) #用Transformer里KQV那套范式为例v = torch.matmul(attn, v)subword embedding(char或char ngram):基本解决OOV(out of vocabulary)问题、分词问题。这个对encode应该比较有效,但对decode不太友好
x = [char for char in sentence] # char-level
知乎答主:年年的铲屎官
只改1行代码,bleu提高2个点。用pytorch的时候,计算loss,使用最多的是label_smoothed_cross_encropy或者cross_encropy,推荐把设置reduction为'sum',效果可能会比默认的reduction='mean'好一些(我自己的尝试是可以提高2个BLEU左右),以最常用的cross_entropy为例:
from torch import nn self.criterion = nn.CrossEntropyLoss(ignore_index=pad_id) # reduction默认为'mean'
改为:from torch import nn self.criterion = nn.CrossEntropyLoss( ignore_index=pad_id, reduction='sum')
发生的变化,实际上就是计算一个sequence的所有token,其loss是否平均(字不好看,请见谅~):
我的理解(不对请轻喷),这个trick之所以在一些任务中有用,是因为其在多任务学习中平衡了不同的loss的权重,至少在我自己做的image caption任务中看到的结果是这样的。beam search添加length_penalty
这一点多亏 @高一帆 的提醒,解码阶段,如果beam search不加任何约束,那么很容易导致生成的最终序列长度偏短,效果可能还不如greedy search。原因的话就是beam size大于1,比较容易在不同的beam中生成较短的序列,且短序列得分往往比长序列高。举个例子的话请看下图(假设beam size为2):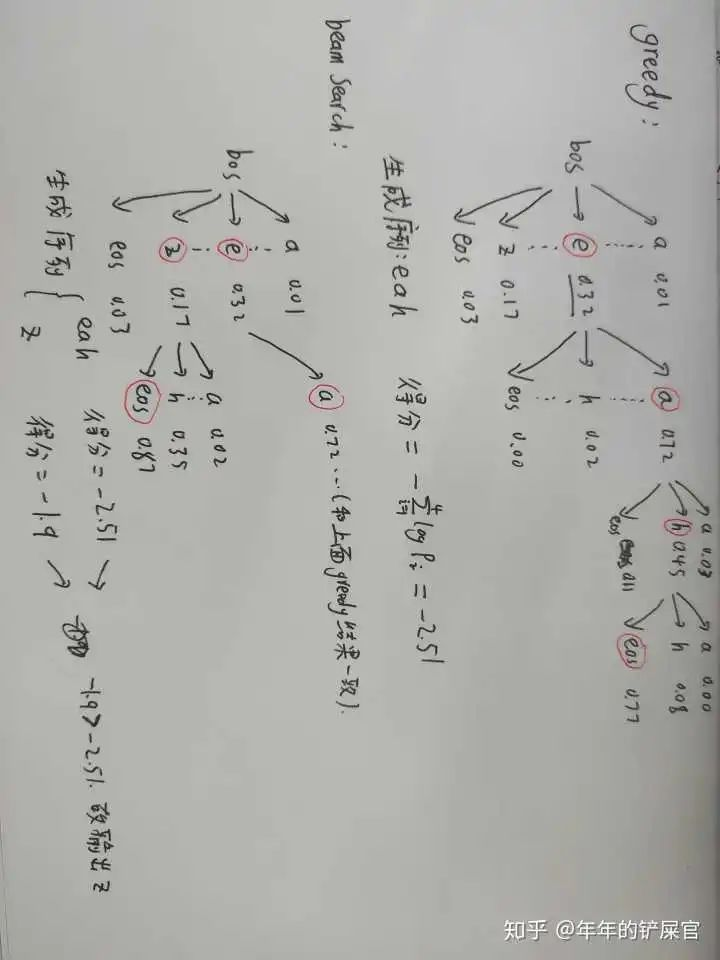
那么我们需要对较短的序列进行惩罚,我们只需一行代码就可以改善这个问题:# 假设原始生成序列的最终累积得分为accumulate_score,length_penalty是超参数,默认为1 accumulate_score /= num_tokens ** length_penalty假设encoder输出为encoder_out,是一个tensor(比如一个768的embedding,而非一组embedding),那么我们喂给rnn的输入,input除了上一步的 , 拼接上encoder_out,效果会涨不少。即:
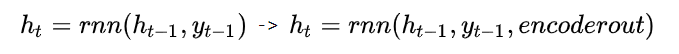
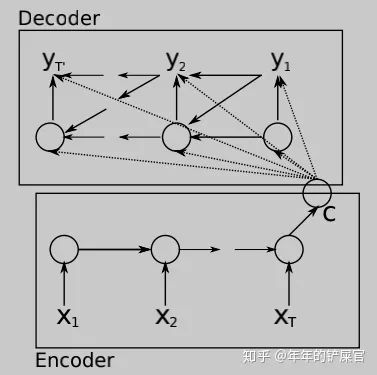
我自己的实验,每一个timestep给rnn的输入都拼接encoderout,bleu提高3个点(数据量4万)。
针对多层rnn,比如多层lstm,input feeding也是一个能提高模型表现的trick。就是lstm的第一层,其输入除了前一时刻的输出,还有最高一层前一时刻的隐状态 ,用图来表示就是:
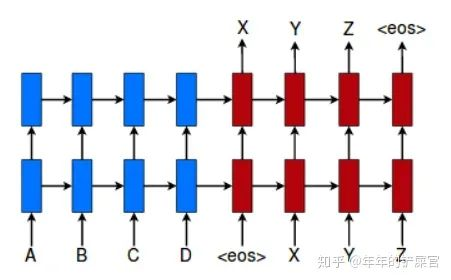
变为:
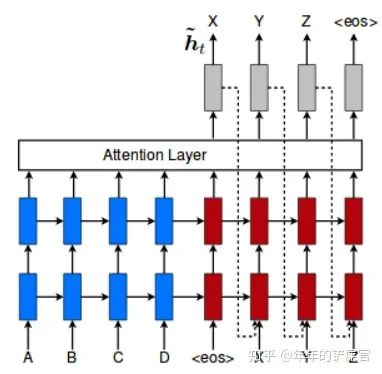
表现在代码上,就是:input = torch.cat((y[t-1], hiddens[t-1]), dim=1) # 原始的只有y[t-1]
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
有顶会审稿人、大厂研究员、知乎大V和妹纸
等你来撩哦~



















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









