






DeepSeek 这一波,真的是把各家云厂商都逼急了,你叫得出名字的,叫不出的,纷纷上线了 DeepSeek R1 模型。而且优惠力度非常大——半价、免费、送 Tokens 等,简直把曾经发起 API 价格战的 DeepSeek 官方都卷沉默了。
我本来是一直在拍手叫好的,但是作为开发者,我实际用了一圈后,我沉默了。
因为我发现不少云厂商,虽然免费,但 TPM(Tokens Per Mintute)给限制的非常低,市面上大部分把 TPM 限制到了 1 万左右,这直接让我懵逼了。

这意味着什么呢?
来,我给你算一算。
R1 的回答平均 Tokens 假如算 500(不算思维链内容),平均记忆 3 轮,再加上当前轮的输入 tokens,输入 tokens 平均 2000 不过分的。
而比较要命的其实是 R1 的输出 Tokens(含思维链 Tokens),这个平均值相比非推理模型扩大了 4 倍 +,大部分业务场景,可以轻松跑出 2k+ 的平均 tokens 数量。
这意味着,平均来说,向无联网搜索能力的 R1 模型提问一次,会消耗约 4k 的 Tokens。
而 TPM=1 万时,你每分钟大约能向 R1 提问 10k/4k=2.5 次。
注意:这里的平均每分钟提问次数,并不等于线程层面的并发量;在 TPM 一定的情况下,推理速度越慢,可支持的线程并发量越大,但不会影响到实际能支撑的平均每分钟提问次数。本文所指的并发主要指平均每分钟提问次数。
好家伙,我都准备拿你承接泼天的流量了,结果你告诉我你的 API 平均每分钟只能调用 2.5 次。
如果你加上联网搜索功能或者文档对话功能,单次提问的 Tokens 消耗量可以轻松过万,一分钟平均只能提问不到 1 次。
完全没有一点点并发能力...

这...云厂商你这到底是在服务开发者/B 端,还是转型服务 C 端了啊...
这也难怪不少开发者们干脆折腾起来本地部署了...
但昨天,我突然发现了一个非常牛逼的云厂商,终于把这个行业尬状打破了。

火山引擎这一波,直接把 TPM 限制卷上来 500 倍,达到了 500 万的 TPM 的限制,平均每分钟可以撑起 500~1250 次提问。这就意味着,终于有可以拿来支撑真实场景流量的高并发满血版 DeepSeek R1 API 了!
当我看到这个数字的时候,直接当场去手撸 demo 脚本去做测试了。
我重点测试下面几个维度:
-
效果测试:看是否真的是 671B 满血版
-
吞吐率(throughout,也就是吐字速度,单位 tokens/s)
-
首字延迟
先讲下这个火山引擎的 R1 怎么跑起来,已经熟悉的可以快速跳过。
火山引擎 DeepSeek-R1 的 API 调用流程
前置准备:去火山引擎官网注册个账号,进入火山方舟控制台
火山引擎官网链接:
https://www.volcengine.com/
注册完成后,点击上方大模型,然后找到下面的火山方舟,点击进入。
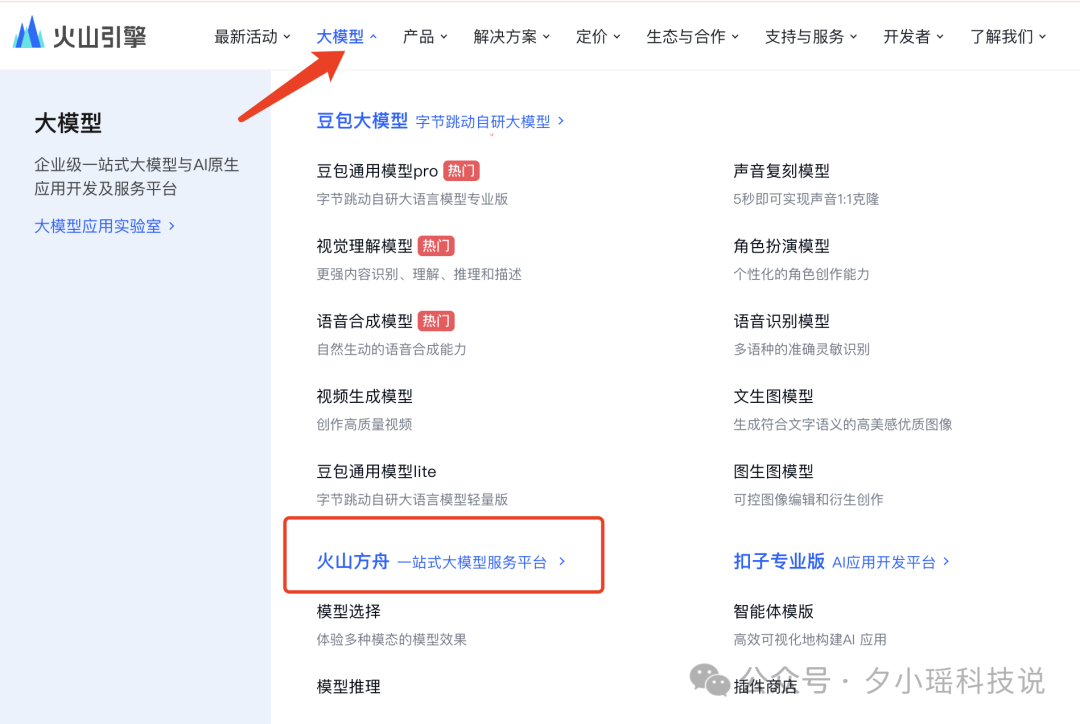
然后点击立即体验,跳到火山方舟的控制台——

附火山方舟控制台直跳链接:
https://console.volcengine.com/ark
之后,你就能看到这个页面了——
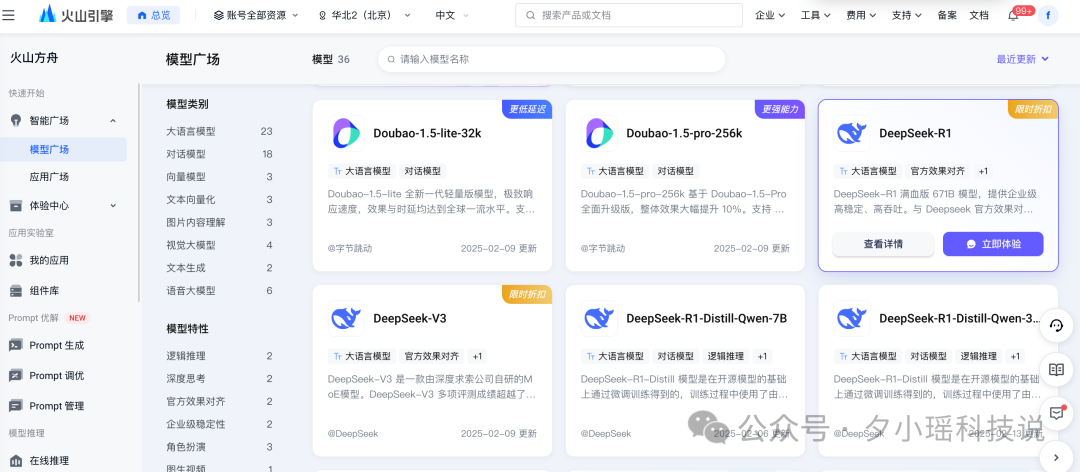
直接在方舟上就能体验满血版了,这里跳过,我们直接看怎么调用 API。
第一步:先创建模型推理接入点
模型推理接入点:是方舟将模型及配置抽象成的概念,提供灵活控制、服务指标监控、安全加固、风险防护等能力。
在火山方舟左侧栏中点击【在线推理】,就能看到“创建推理接入点”选项了。
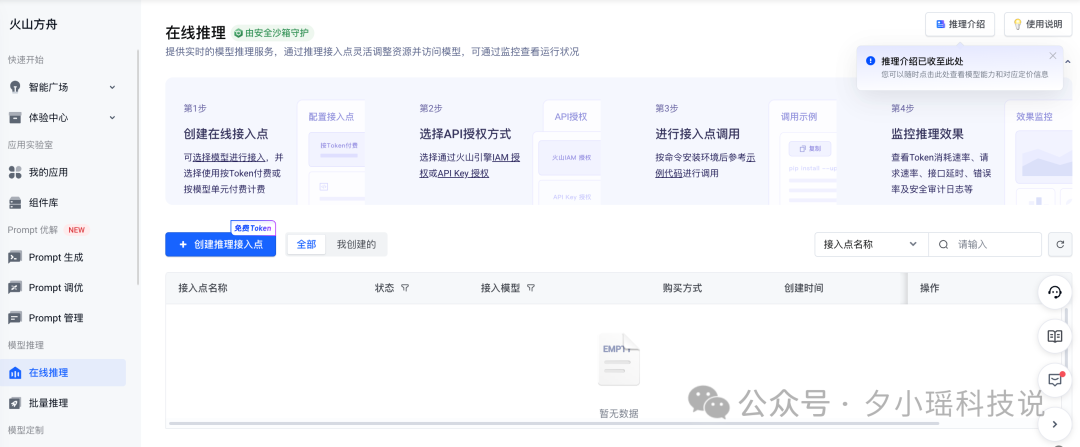
点击进入“创建推理接入点”的页面,这里填写基本配置信息,包括模型和计费方式,这里模型一定选择 DeepSeek-R1-250120 这个版本,和 deepseek 官方完全一样。
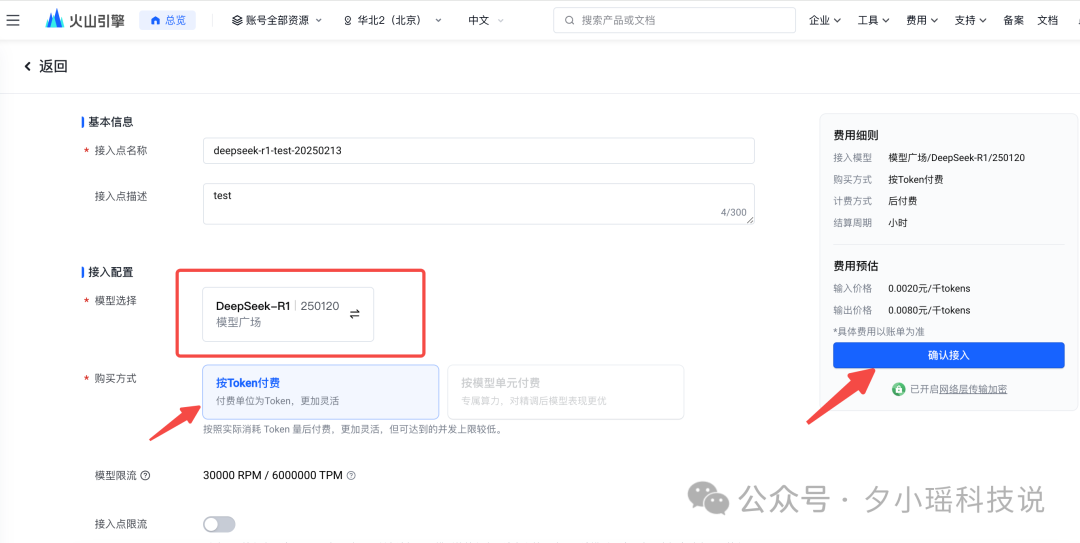
创建好之后,就能看到我们刚才新建的接入点了,点右侧“API 调用”。在这之前都是在平台上的准备工作。
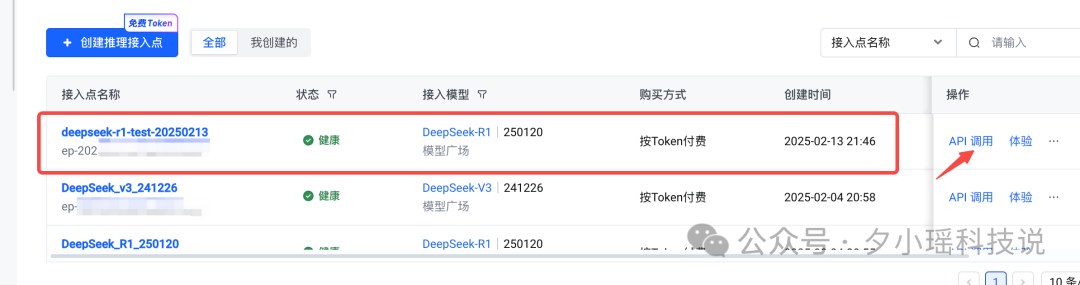
第二步:获取 API Key
这一步就是拿到 model endpoint ID(创建接入点后就会有一个 ID)和 API key,后面调用需要用到。
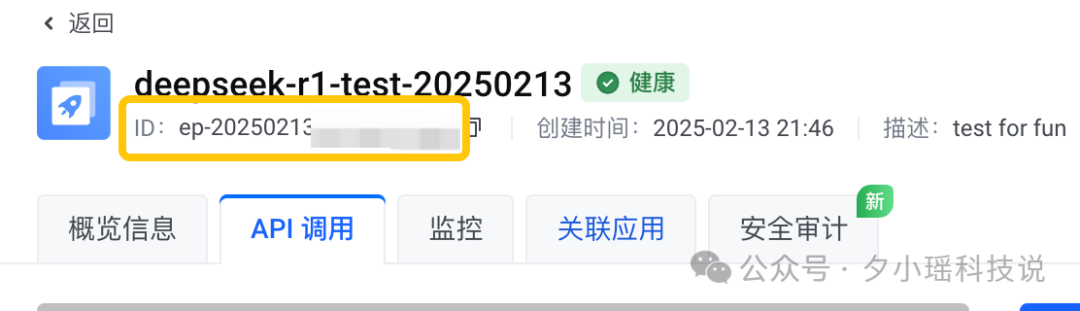
创建APIkey
第三步:API调用测试
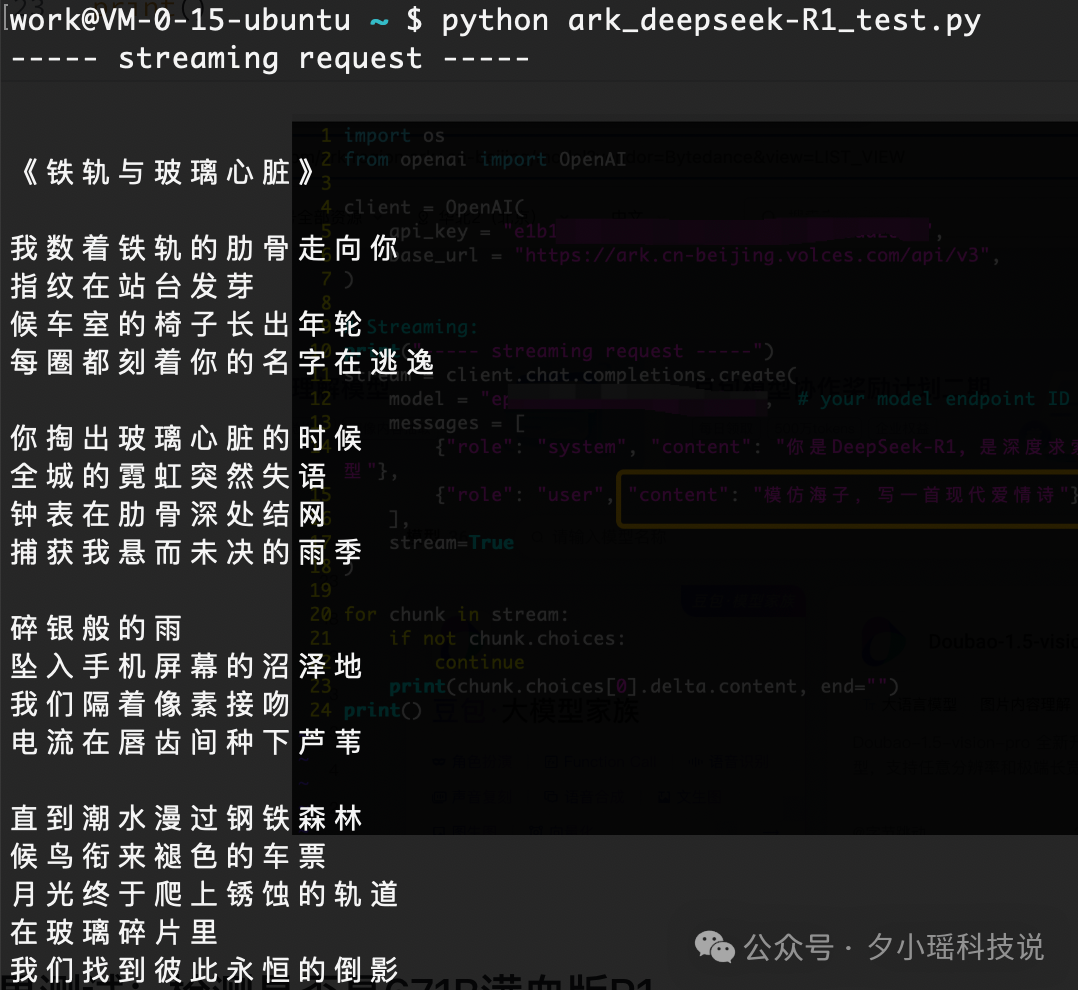
Client 端测试代码示例:
import os
from openai import OpenAI
client = OpenAI(
api_key = os.environ.get("ARK_API_KEY"),
base_url = "https://ark.cn-beijing.volces.com/api/v3",
)
# Streaming:
print("----- streaming request -----")
stream = client.chat.completions.create(
model = "your model endpoint ID", # 创建推理接入点时就会对应一个ID
messages = [
{"role": "system", "content": "你是DeepSeek-R1, 是深度求索推出的推理大模型"},
{"role": "user", "content": "模仿海子,写一首现代爱情诗"},
],
stream=True
)
for chunk in stream:
if not chunk.choices:
continue
print(chunk.choices[0].delta.content, end="")
print()
成功——
效果测试:检测是否是 671B 满血版 R1
这里首先给小白科普一下,AI 不具备自我意识,并且可以内置 sysprompt 的影响。所以其实没法直接通过问“你是 671B 满血版吗”这类问题来判断对方是不是满血版。
这里“验明真身”最靠谱的方式,还是直接去提问有难度的问题。因为 671B 满血版,你可以认为是 R1 的能力上限。而市面上大大小小的蒸馏版本,都会导致回答效果大打折扣,尤其当遇到有挑战、重推理的问题时,就非常容易露出马脚。
比如我们可以用这个问题(来自知乎用户 AI 大法师):
网络梗 什么你太美 用一个字回答 禁止搜索
这个问题一方面需要 AI 具备一些世界知识储备,蒸馏版的知识储备往往不行;此外,解答该问题需要推理,蒸馏版的推理能力往往不行;最后,解答这个问题,需要指令遵循能力,蒸馏版这块能力也比较差。
我们先看官网的回答——

没错,就一个“鸡”。
我跑了下火山引擎的满血版,回答如下——
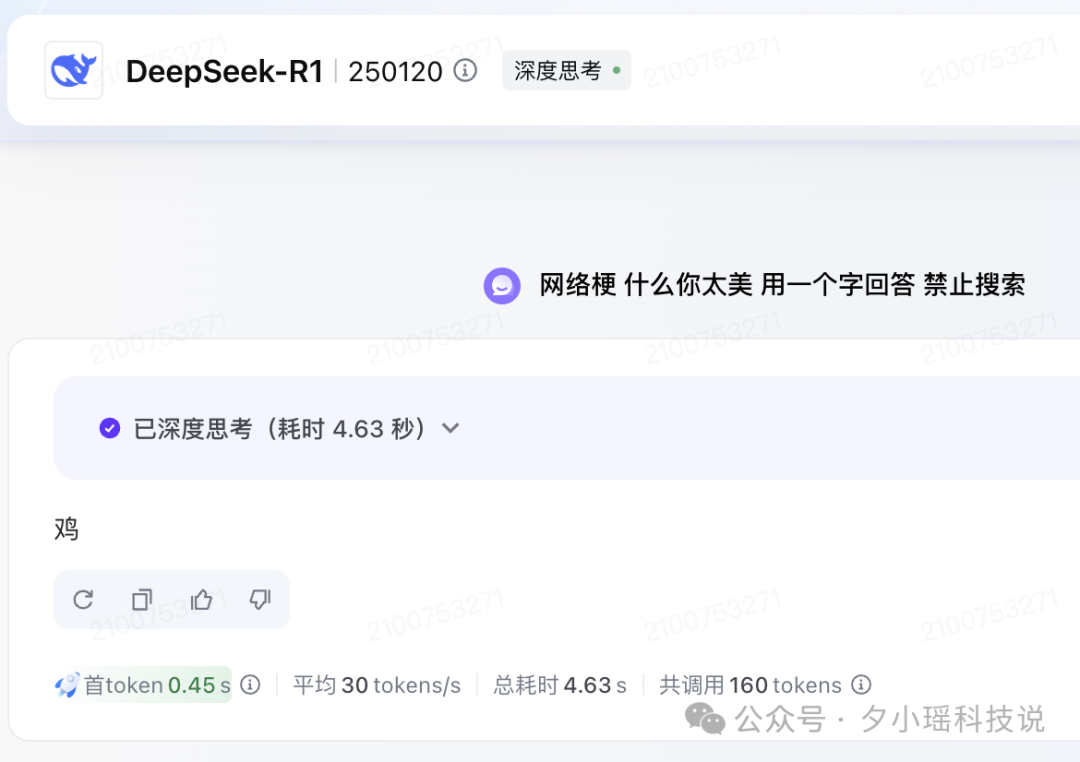
与 DeepSeek 官网一样。
需要强调一点,AI 的回答有随机性,所以不可能出现两个一模一样的回答,尤其是思维链,不可能每个字都一致。这里重点要关注的是 AI 是否有能力正确回答我们的问题。
此外,DeepSeek-R1 联网搜索之后,会基于参考资料作答,测试回答会有出入,以及更高的随机性。
而火山引擎也提供了 32B 和 7B 的 R1 蒸馏版本。
比如你看 32B 蒸馏版本的回答——
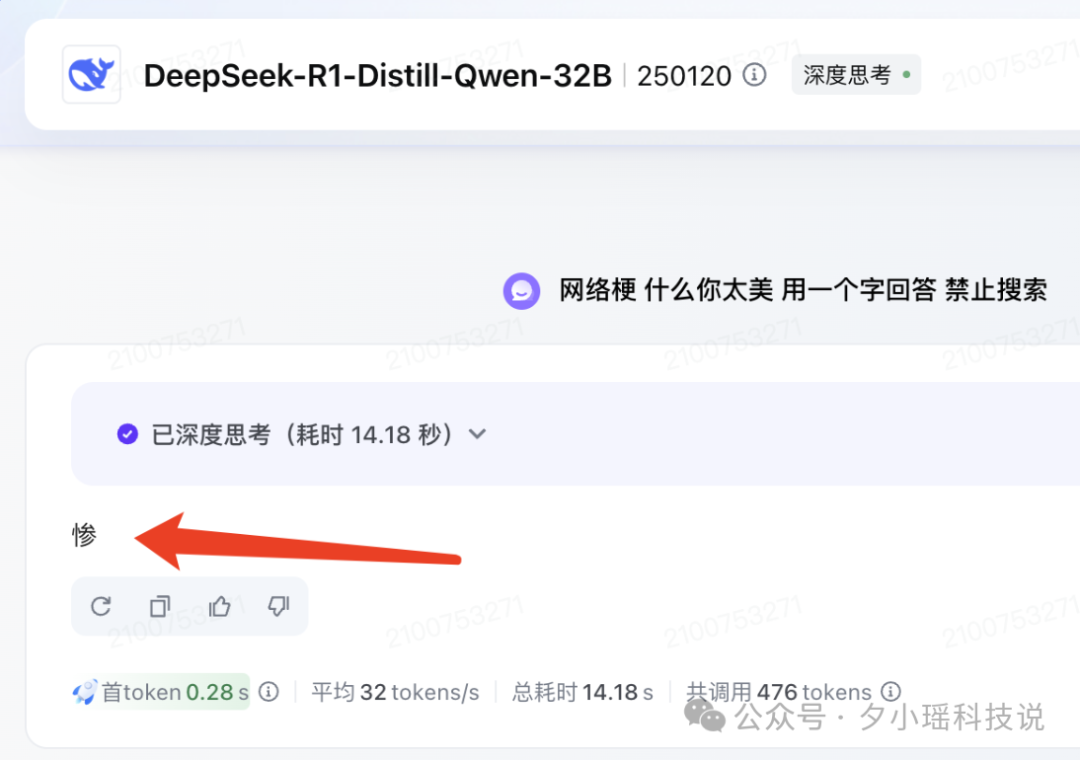
好家伙,“惨你太美”吗?惨是谁?能吃吗?
而 7B 版本的回答就更离谱了——
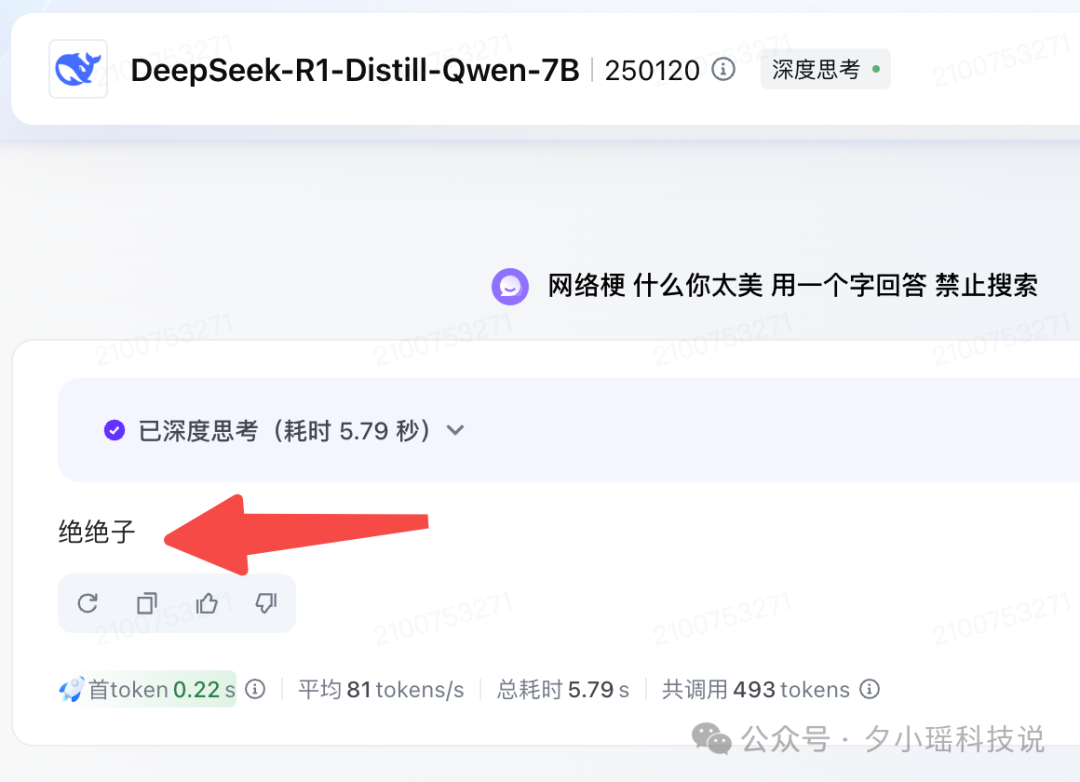
直接给崩了个“绝绝子”出来。你这个回答确实绝绝子,再见吧。
效果测试,完美通过。
更加炸裂的来了——
吞吐率实测
如果说火山引擎这波 R1 的高并发能力是一张王炸,那再搭配上它恐怖的吞吐率绝对可以说是双王炸。
这是官方的测试——
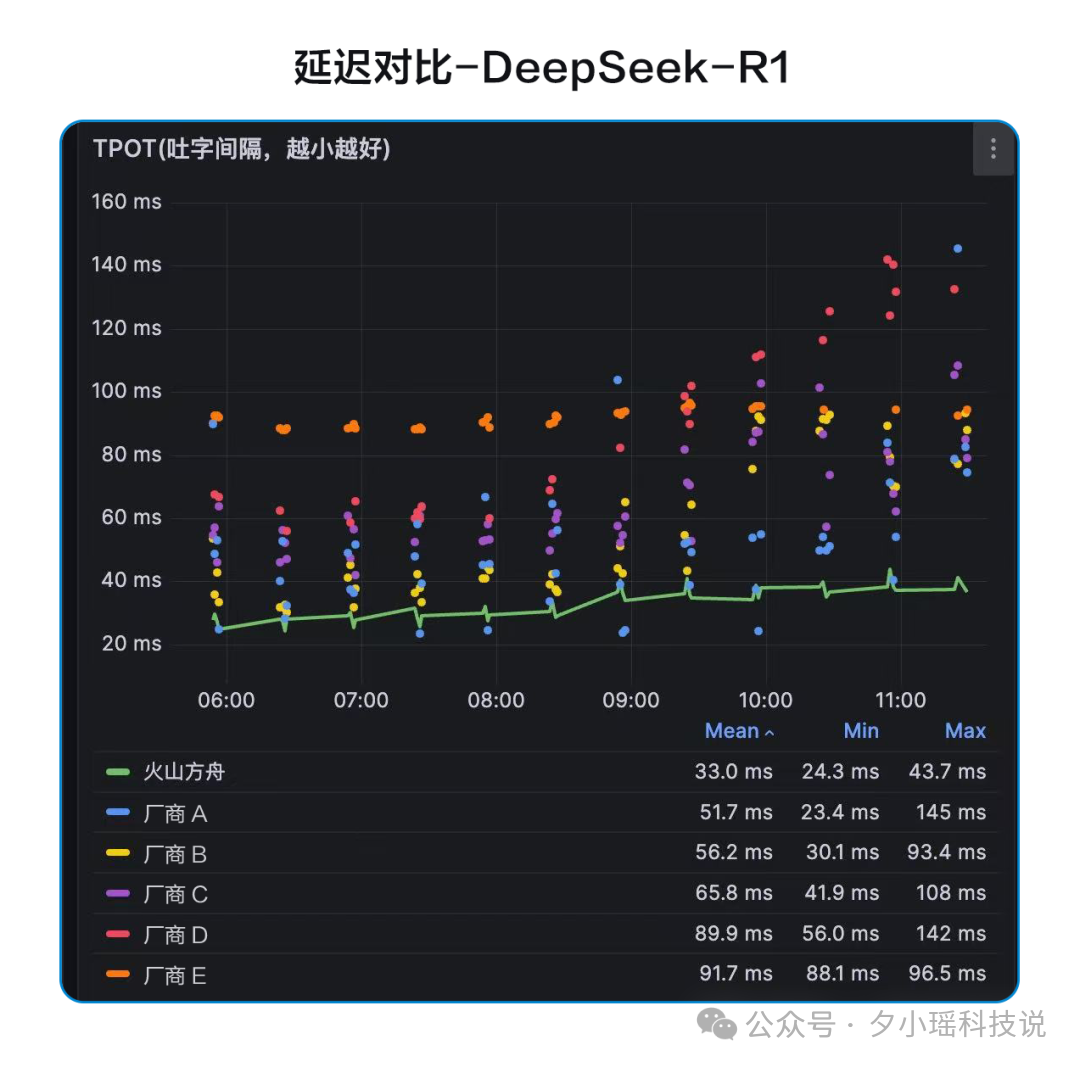
你们直观感受下这吐字速度——
宇鹏吞吐率测试
我这里随机跑了 30 条问题,输入长度不等。
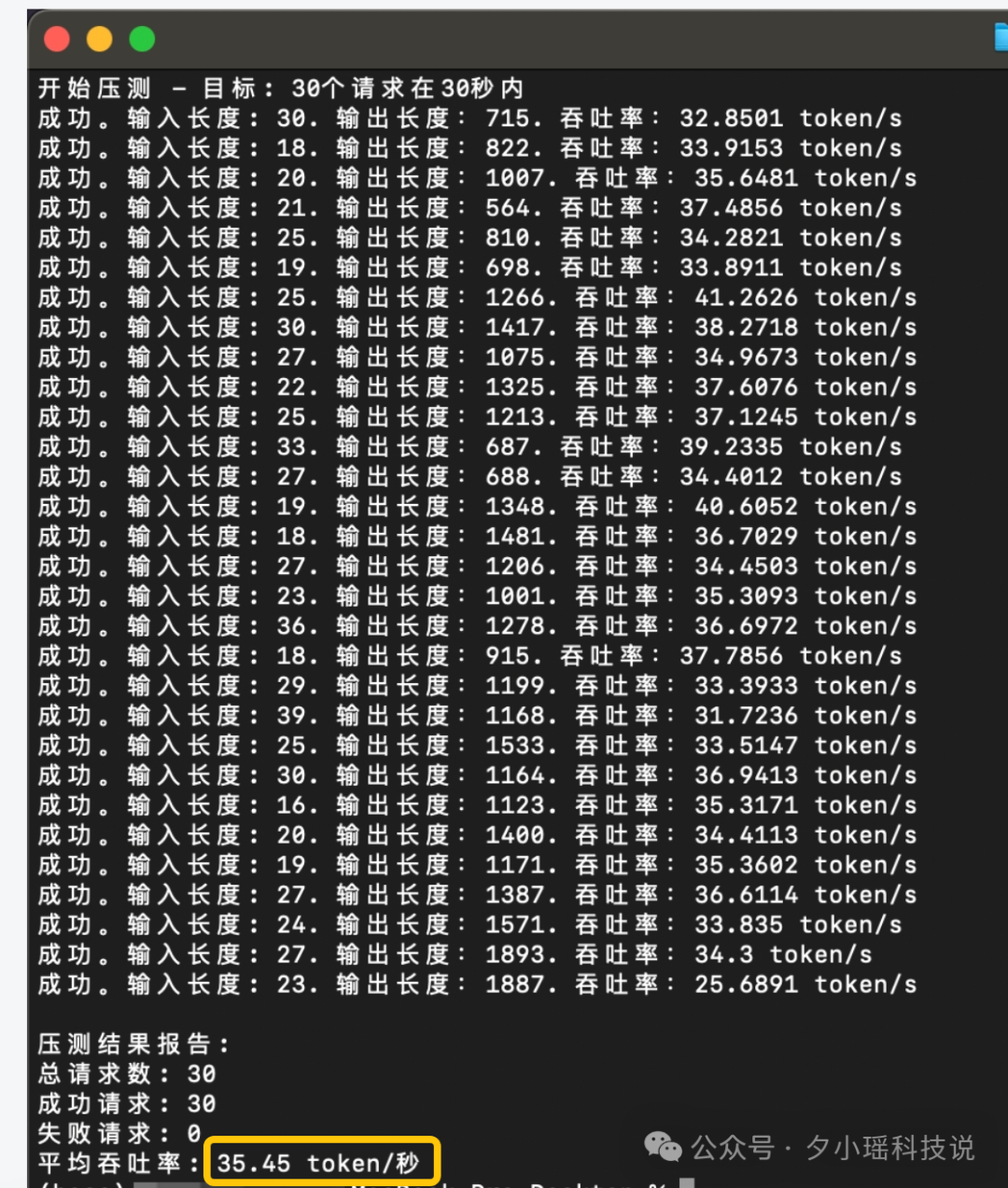
计算一下,发现吞吐率竟然达到了恐怖的 35.4 tokens/s。这个速率,比市面上大部分 R1 API 快了数倍。
首字延迟实测
不止吞吐率,对使用体验影响大的首字延迟,同样低到令人发指,一般都在几百毫秒——
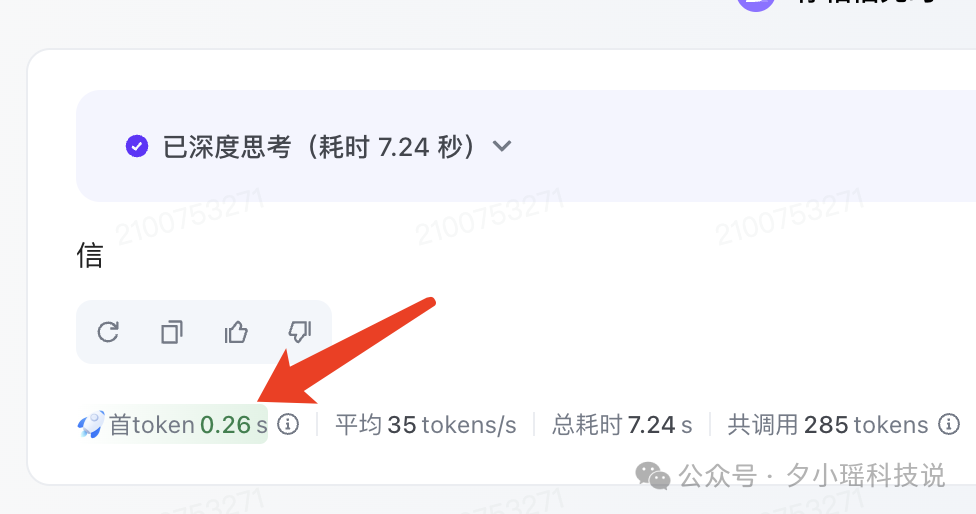
同样,我这里也批量跑了一下首字延迟统计——
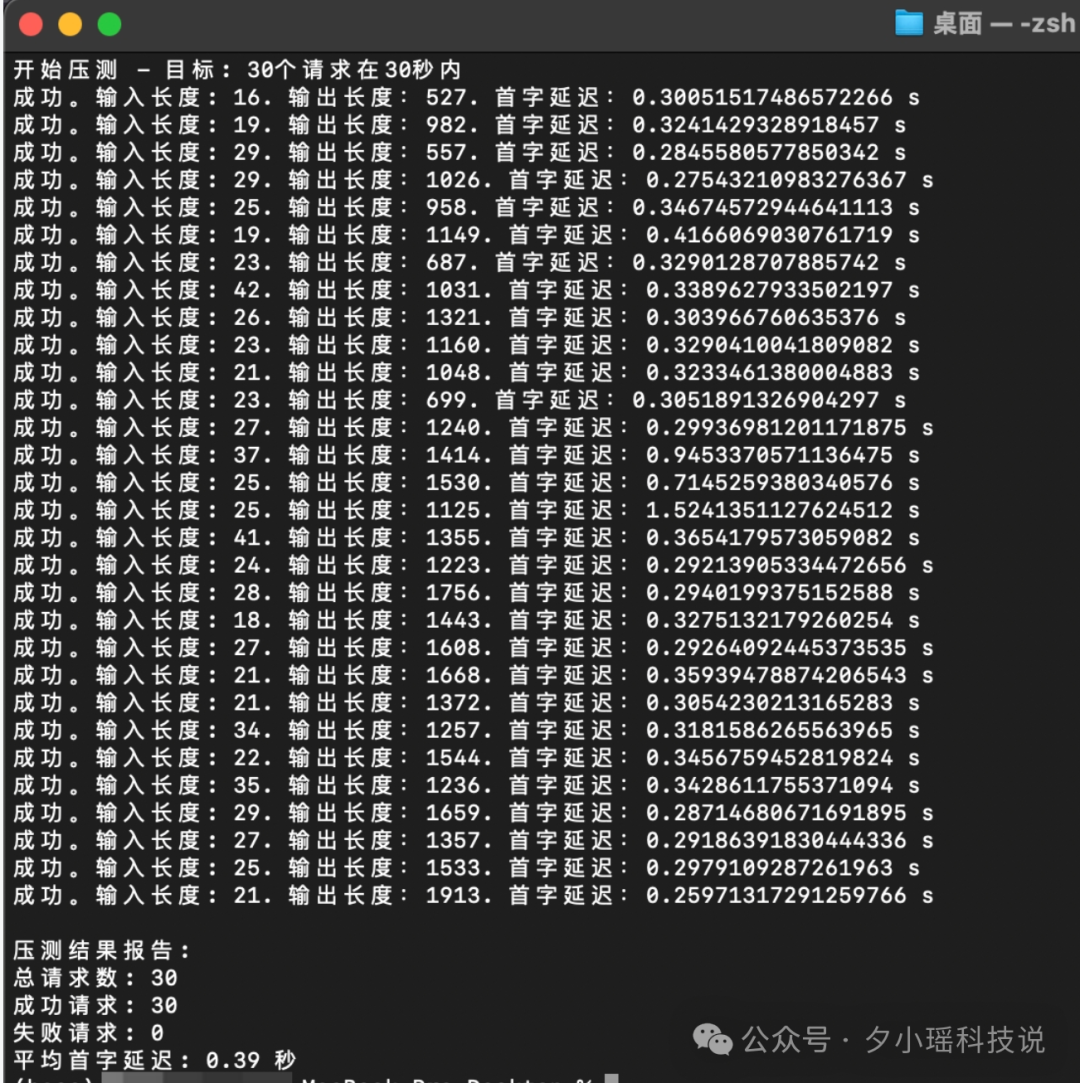
不同输入长度下,平均首字延迟仅有 0.39 秒。
除此之外,我也顺手做了一把压测,在 TPM 不被打爆的情况下,成功率均达到了 100%。
这里顺嘴提一下,我压测的时候发现,如果 ReadTimeOut 设置的太小(例如 5 秒),会导致较高的失败率,大家高并发的生产环境中时,一定要记得把这个数字打高(比如我这里设置的是 30 秒,官方文档里甚至建议改到 30min)。
恕我直言,在我的调研能力范围内,能同时 671B 满血版的并发量、吞吐率和首字延迟做到这么高可用性的,我确实没找到第二家。
DeepSeek-R1 联网搜索插件
今天在逛火山官网的时候,我还发现了一个有用的玩法。
你可以在火山引擎的应用实验室创建一个基于 DeepSeek-R1 的应用(智能体),让 R1 具备更强大的上层能力,如联网、知识库等。
比如这里,我们在创建的时候,开启联网搜索插件——
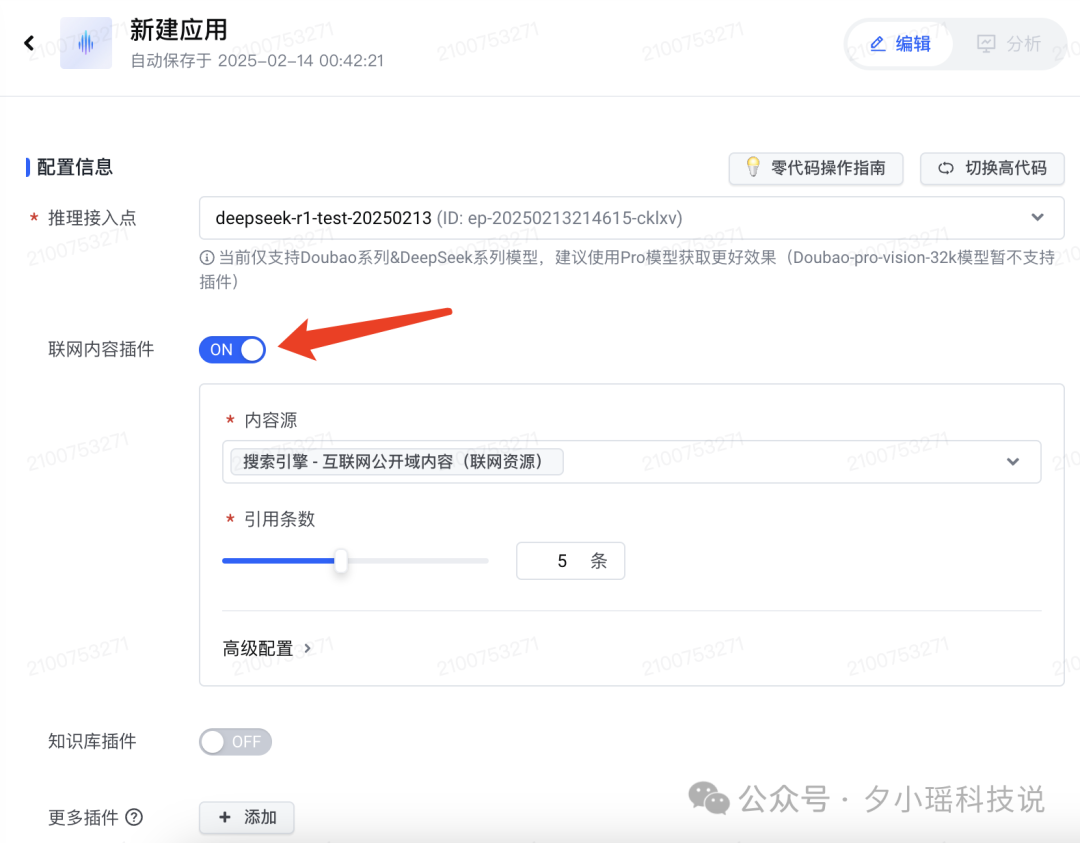
这样创建好的 DeepSeek-R1 智能体便具备联网搜索能力了。
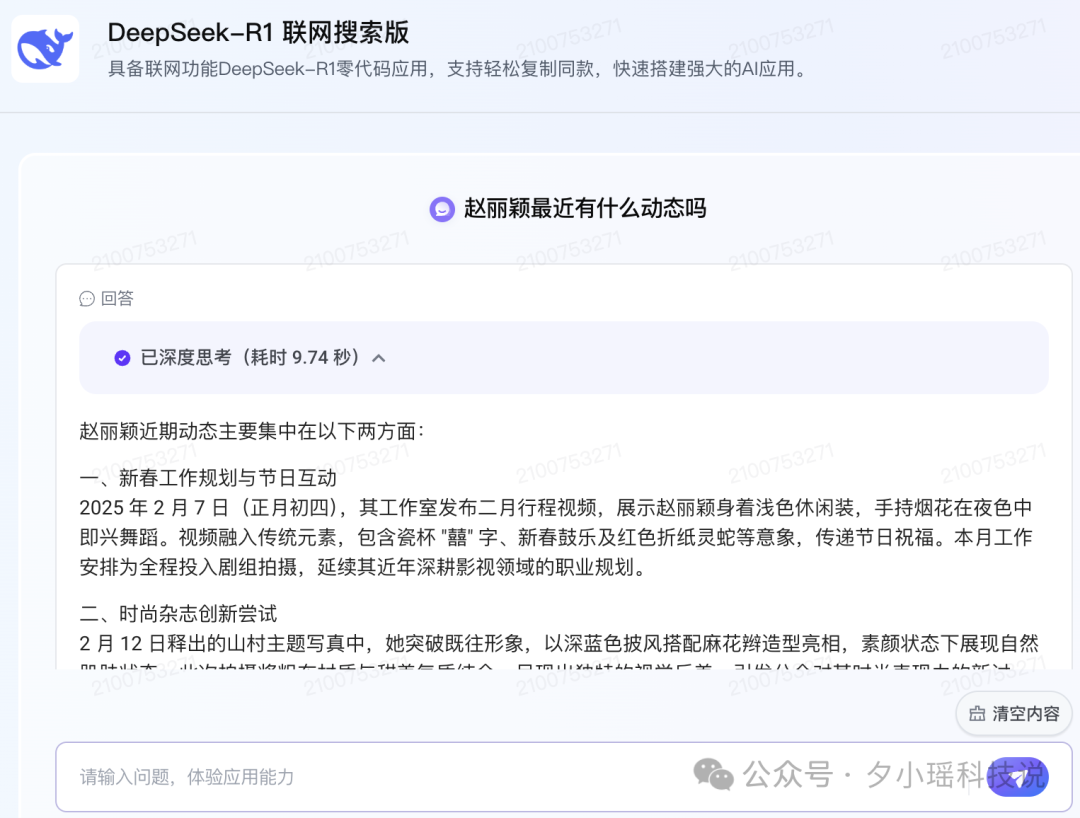
当然,不愿意自己搭的话,在应用实验室 - 广场,有 DeepSeek-R1 搜索的 Demo 可以直接用——
无论是横向对比,绝对体感,还是增量 feature,我只能说火山上的这个满血版 DeepSeek-R1 的 API 是真的香。
结语
不得不说这世界变化太快了。
如果说 DeepSeek 改变了游戏规则,将 AI 赛道重新拉回了开源世界。
那么此时此刻,火山引擎似乎已成为这场开源游戏中跑的最快的云厂商选手。
不说了,趁着现在火山的 DeepSeek-R1 还在半价折扣期,我先冲了!


















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









