






小时候看动画片时,总是震撼于动画梦工厂里能让一幅画动起来的操作。也幻想过有朝一日成为神笔马良,能够让照片的人物动起来,而现在已经有了让照片面部表情动态化的成熟产品。
那么给定一个人的照片,能不能让这个人模仿规定的动作动起来呢?与照片面部表情的动态生成相比,这个挑战更为复杂,因为它涉及对人体姿势随时间变化的理解,以及学习有关人类外观和服装细节的先验知识。

近期,加州大学伯克利分校的研究团队提出了 3DHM,这是一个基于扩散模型的两阶段框架,可以利用单张照片生成人物动画。首先,通过学习关于人体和服装的先验知识,以及单张照片中服装和纹理与动作的映射,然后渲染 3D 人物,从而合成一系列与目标动作相符,且与输入照片人物外观一致的人物运动视频。
论文题目:
Synthesizing Moving People with 3D Control
论文链接:
https://arxiv.org/abs/2401.10889
博客地址:
https://boyiliee.github.io/3DHM.github.io/
如何合成移动的人物?
如图 1 所示,首先介绍两种人物定义:
-
演员:可以执行各种动作(从简单行走跑步到复杂舞蹈动作)的人物,用来指导模型生成具有相似动作的动画人物。
-
模仿者:用于模仿他人动作的虚拟角色,通过学习目标演员的视觉先验知识,以不同的姿势和视角进行动画。

▲图1 模仿游戏,其中有“演员”和“模仿者”
3DHM(3D Human Motions)框架是用于模仿运动序列的两阶段方法,能准确跟踪人体动作,并提取演员视频的 3D 人体姿势,用来生成逼真的人物动画。其结构如图 2 所示,这两个阶段共同实现了纹理图案修复的目标,使得生成的人体动画更具真实感和细节丰富。
-
第一阶段:用于纹理图案修复的 Inpainting Diffusion
-
第二阶段:用于人体渲染的 Rendering Diffusion
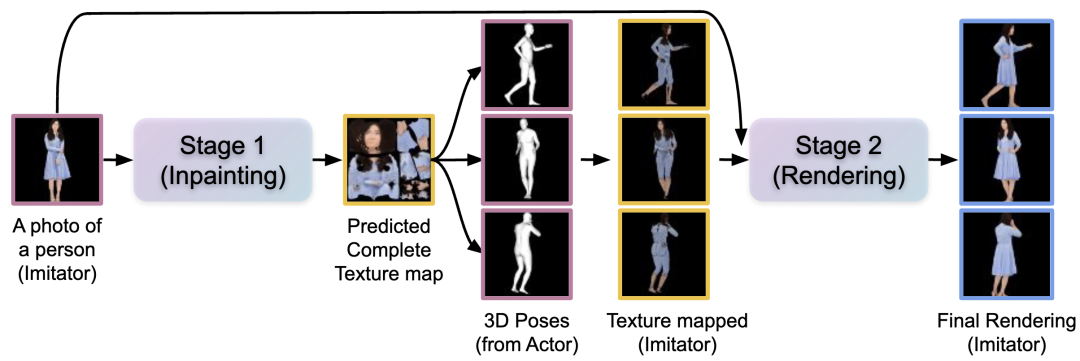
▲图2 3DHM 概述
阶段 1:纹理图案修复
在这一阶段,目标是利用单张照片生成不完整的纹理图案,再使用扩散模型修复以生成完整的纹理图案。
为实现这一目标,首先,从给定的单张照片中提取部分可见的纹理图案及其对应的 mask。然后,将这些输入传入扩散模型,以生成一个包含未见区域的完整纹理图案。
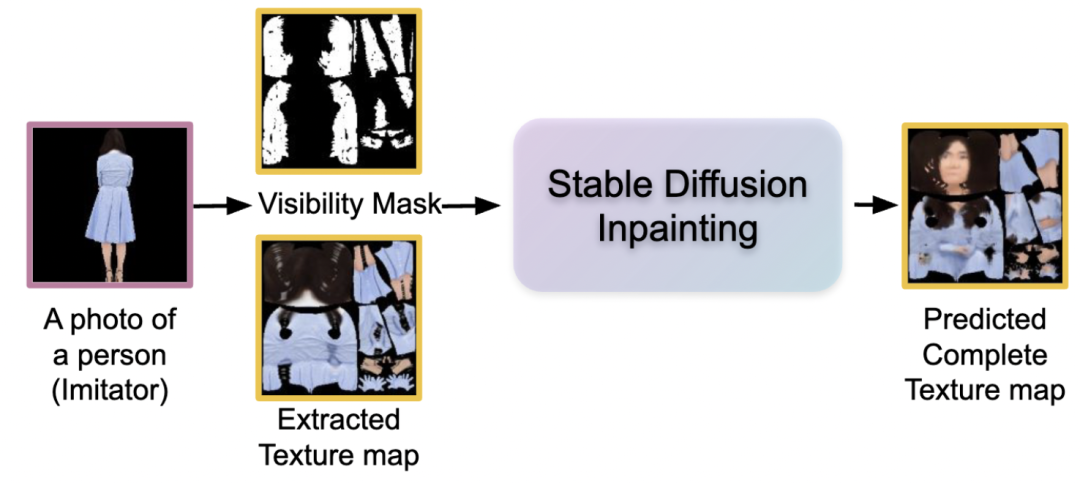
▲图3 3DHM 的第一阶段
-
输入:给定单张照片,首先使用 4DHumans 样式的采样方法提取部分可见纹理图并生成对应的可见 mask。
-
模型:直接在在图像修复任务中表现出色的 Stable Diffusion Inpainting 模型上进行微调。输入部分纹理图及对应的可见 mask,得到预测的修复纹理图。这个被训练后的模型称为 Inpainting Diffusion。
阶段 2:人体渲染
在第二阶段,目标是获得一个更真实的人物渲染,以包括衣物、发型和身体形状等细节。
为了实现该目标,首先将上一阶段生成的纹理图案应用于演员的 3D 身体网格序列,以生成一个模仿者执行演员动作的中间渲染。然后,将获得的中间渲染和原始人物照片输入到渲染扩散中,从而根据给定输入渲染具有真实外观的人物。
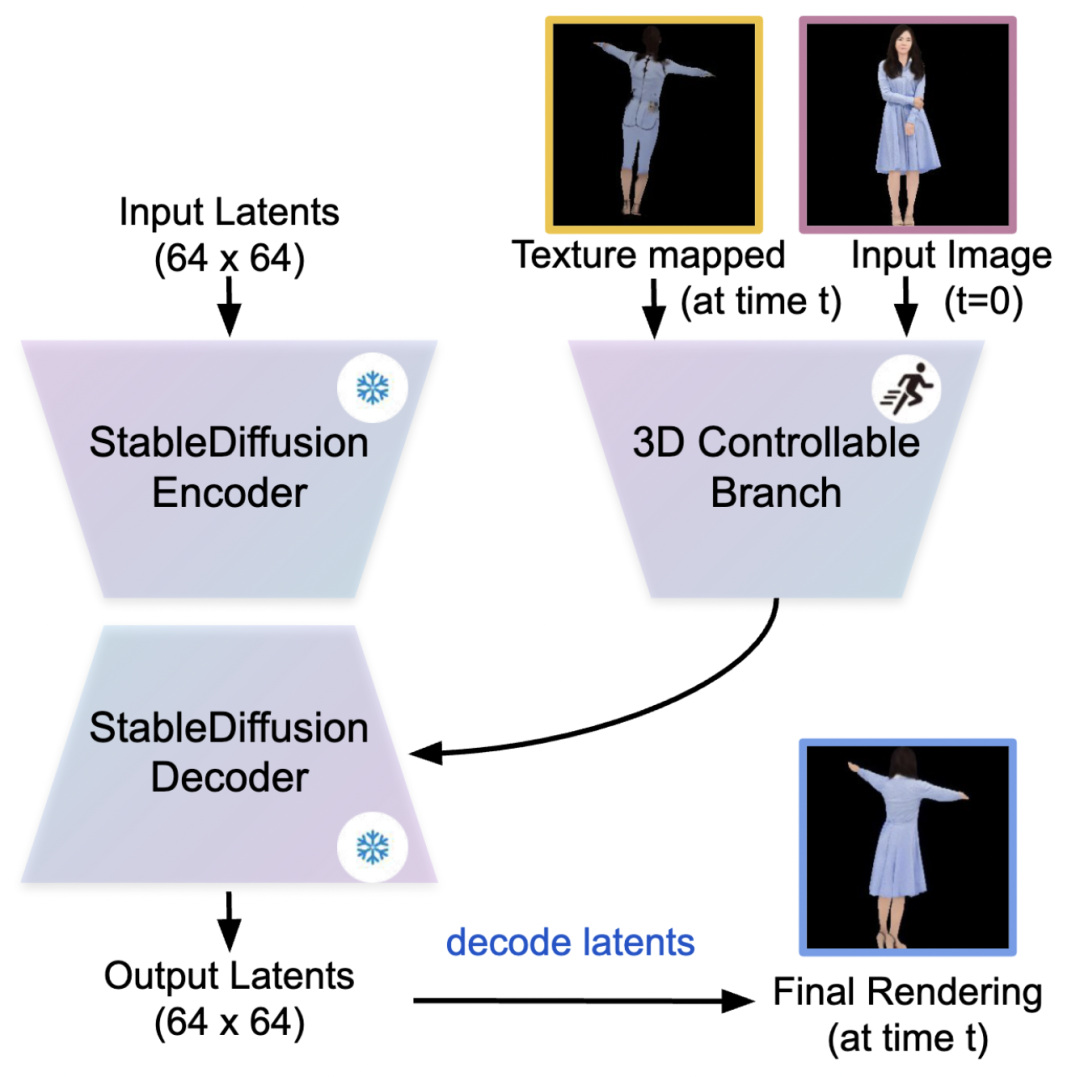
▲图4 3DHM 的第二阶段
-
输入:通过第一阶段所生成的完整纹理图案和原始人物照片。
-
模型:类似于 ControlNet,直接复制 Stable Diffusion 模型的编码器权重作为可控分支,通过控制模块以处理 3D 条件。同时,将演员的动作、纹理图案修复模型的输出和原始人物照片输入到固定的 VAE 编码器中,分别得到纹理映射的 3D 人体潜在表示和外观潜在表示,并将它们作为条件潜在表示,将其输入到 Rendering Diffusion 的可控分支中。
实验结果
与其他方法(DreamPose、DisCo 和 ControlNet)比较,3DHM 在各种指标上均表现出色。
帧生成质量
作者使用了一个包含 50 个未见过的人物视频的测试数据集,并将每个视频的 30 个帧作为样本进行评估。实验结果表明,3DHM 模型在生成质量方面表现出色。
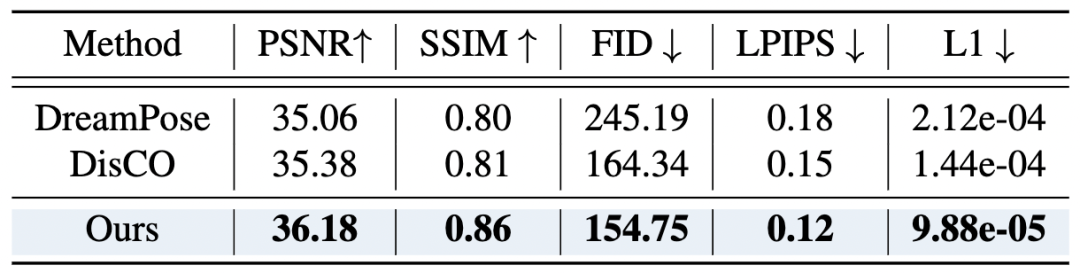
▲表1 帧生成质量
视频生成质量
此外,作者还对视频级生成质量进行了比较,尽管 3DHM 是逐帧训练和测试的,但仍然在保持时间一致性方面具有显著的优势,能够在长时间跨度内生成连贯的动作。
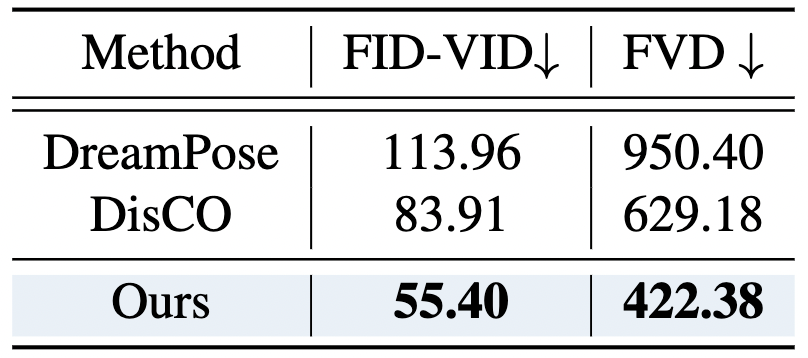
▲表2 视频级生成质量
姿态准确性
在 3D 姿态准确性方面,在处理各种 3D 姿势和运动时,3DHM 的表现也胜过其他直接预测姿势-像素映射的方法,具有较低的 MPVPE 和 PA-MPVPE 指标,这意味着其 3D 重建和姿态估计的准确度较高。

▲表3 姿态准确性
相同姿势但不同视角下,表现如何?
如图 5 所示,3DHM 能在各种场景中够较好地生成具有不同 3D 姿态的移动人物视频,无论测试视频是否在训练数据中从未出现过、或是来自 YouTube 任意视频、亦或是通过文本模态输入进行控制。
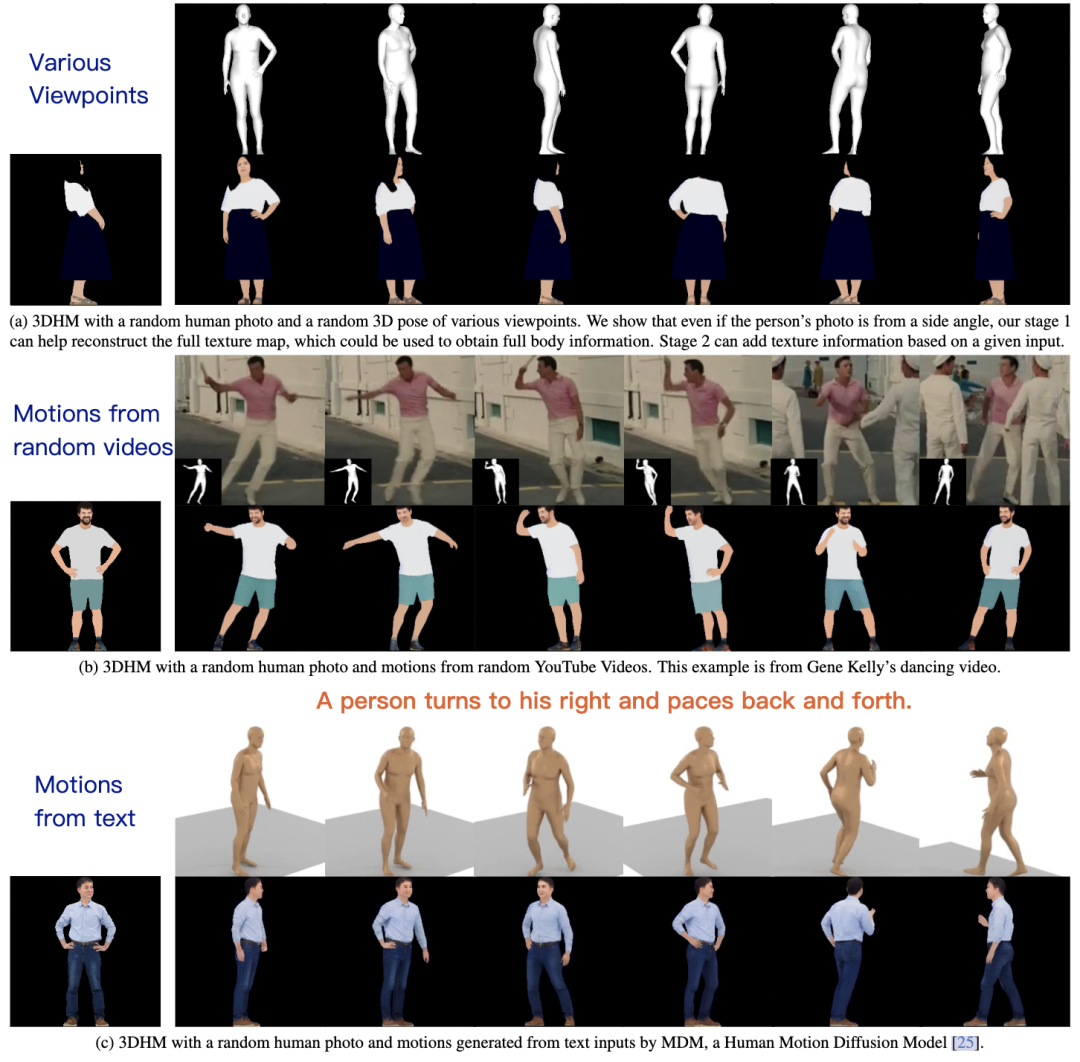
▲图5 相同姿势的不同视角下的结果
2D 控制和 3D 控制方面
与 ControlNet 相比,3DHM 在 2D 控制和 3D 控制方面都取得了优越的结果,这表明 3DHM 生成的图像具有较高的质量,能够更好地捕捉人物的细节和纹理。

▲图6 在随机的真人照片上使用其他 2D 控制方法
总结
3DHM 展现了在多个视角下生成逼真人物动画的强大能力,能够在模仿较长时间的动作和复杂姿势上有出色表现。
然而,该方法也存在一些局限性:
-
其一是由于其独立生成每帧的特性,无法保证在时间上的一致性,可能导致连续帧之间出现服装、光照等细微差异。由此,可以考虑训练模型以同时预测多帧,或通过随机条件来影响生成过程,以增强时间上的一致性,从而解决该问题。
-
另外,由于模型的训练数据集规模相对较小,对于某些细节纹理(如服装上的独特标志)的完全重建存在一定挑战。未来或许可以考虑使用更大规模的人体数据集,以提高模型的泛化能力。
但总而言之,3DHM 在人体动画合成领域取得了显著效果,为生成更为逼真和多样化的人物动画提供了新的可能性,有朝一日,或许真的有机会看到“神笔马良”画笔下的人物跃然于纸上。



















 401
401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









