







文 | 水哥
源 | 知乎
Saying
1. 工业特征处理和学术特征处理存在巨大差异,这里建议同学们一定认真阅读。这个差异可能引发未来各种方法落地的矛盾。
2. full embedding在概念上和one-hot的操作等价,但在操作上省略了这个过程。
3. hash是最省事的,一切特征转string,一切string转hash。
4. 在embedding分解这里没有融入一些语义信息是比较遗憾的,如果有万能的知友看完后搞出来了请给我一个致谢。
这是 【从零单排推荐系统】 系列的第17讲,承载上一讲,这里要详细聊聊特征生成和取embedding的过程是怎么样的。需要注意的是,这一讲的东西可能会构成学术界和工业界最大差异的两个地方。在阅读论文的时候,判断其中所讲的东西有多大概率能在实践中work,有两个参考问题:(1)该论文的特征机制如何处理源源不断的新的特征或者新的ID?(2)该论文的训练机制是否与online learning的习惯冲突? 根据我个人的经验,和上面两个点有冲突的方案难以在工业实践中带来提升,即使费了劲把这两个问题解决了,最后效果可能也是平的。
具体来讲,特征处理就是一个典型的学界/工业界有裂痕的例子,本讲会回到embedding+DNN这个范式的上面部分,聊一聊特征的生成方式和业界对于embedding的一些重新思考。
特征生成
在学术研究中,有很多特征本身就是类别(categorical)特征,比如城市,枚举国内的所有城市,你一定在其中之一。我们往往把各类ID也看做类别特征,比如总共有1000个用户,这次遇到的用户是哪一类。与类别特征直接相关的处理方式就是先变成one-hot的向量(只有属于的那一个bin是1,其他的都是0),在经过一个矩阵 转化到浮点向量参与后面的处理。举个例子,我们在用户侧有性别,User ID,城市三种特征。在科研情景中,我们就有三个one-hot的特征,每一个都通过乘以矩阵 转化为embedding,如下图所示:
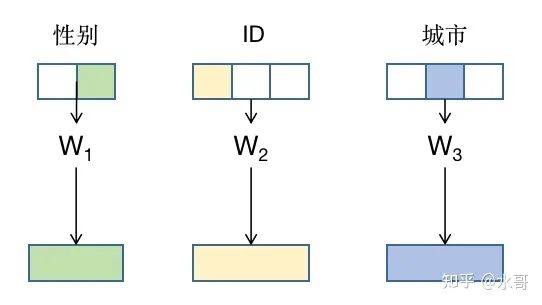
或者也可以把他们组合成multi-hot的向量,然后用一个统一的大 来映射。这是典型的科研场景下的问题描述形式。
工业界的处理方式大致符合上面的操作,但和常见学术论文有一个区别是,并不存在一个真正的one-hot特征,更不存在从one-hot特征乘以 再映射到向量的过程。这是大部分同学,或是初学者最容易不理解的地方。首先,在大型工业场景下,会源源不断出现新的item,新的用户,新的ID,原先的one-hot和 必须得不断扩充。但是这个过程并没有什么必要性,在one-hot乘以权重这个操作中,实际上就是取出了 1对应的 的那一列而已,等于0的那些列根本就没用。那我们干脆新出现哪个1,给它分配一个列向量就好了。这也就是embedding look-up table的操作。所以说工业实现概念上和one-hot一样,操作上不一样。
第二个区别是特征高度ID化,一切特征都可以是ID,原来不是ID的特征也转向ID。由于没有one-hot这个过程,还需要一个东西记录非0出现的位置,这个位置就可以看作是所有特征的ID。比如城市这个特征,我们可以把第一个出现的特征记为cityID=1,第二个出现的记为cityID=2等等。但是这样又会遇到一个问题:目前增长到哪了是需要记录的,而且需要在各个机器中互相传递,否则A机器上新出现了一个,你定义为第11,但是在B机器中出现可能是第13个,这就出问题了。如果要针对这个同步的问题做处理,那么又得在机器之间做通信,比较麻烦。防止这个问题的做法就是对特征本身做hash,将得到的数字作为它的ID。只要每台机器用的hash算法一样,出来的值就是一样的。
用hash还有第二个动机,就是其实我们也不希望ID是无限增长的。使用hash之后可以保证所有特征一定都在某个空间中不会出现意外。所以有一种做法是,我们给一种特征分配一个编号,称为Slot ID,每一个特征的取值,我们hash后得到一个ID,称为FID(feature ID),在一个n位的二进制数字中,前k位用slot ID的二进制表示填充,后面n-k位用FID填充,组成一个整体数字,作为这个feature的最终表示。经过这个操作,可以保证每一个特征的取值,都有唯一的取值(如果不考虑碰撞的话)。
hash表示的最大好处是它可以处理(至少是处理,处理的好不好是另一回事)所有类型的特征,只要你是能写出来的,就可以用string表示,只要你能用string表示,你就能hash。实际中完全可以先全部hash跑起来,然后再细分有些特征需不需要特别处理。
既然是使用hash,那么不可避免的会遇到碰撞的问题。原则上,我们不希望有任何两个不一样的特征被hash到同一个ID上,所以会尽量选择好的算法比如cityhash。但是问题也没有那么严重,很多特征都有生命周期。像广告中的item ID,预算没了,不投放了,可以认为那个ID没啥用了。可以设计遗忘机制。当我算出一个ID之后,看到记录上一次算出这个ID是很早之前了,就可以再次初始化embedding让一切重新开始。
Embedding压缩与分解
embedding+DNN是一个“头重脚轻”的方案,几乎所有的内存消耗都压在embedding的存储上面。如果是按照one-hot那样,内存会随着时间线性增加,这是一个很大的消耗。
如果按照上面说的hash的方法,可以避免内存线性增大,总的内存消耗和我们开的空间大小有关。但问题是既然是hash,就一定有碰撞。如果空间设的很大,碰撞概率低,效果好,但内存大;反之若空间开的很小,那么碰撞概率就会增大,对效果有不好的影响。有没有方法可以做巧妙的权衡?
这种动机在近两年引领了一波新的风潮,一种直接的思路是把一个大的ID,拆解成数个小的ID的组合[1]。然后最终的embedding也是在这两个小ID的embedding上做某种操作得到的。我们会想到可能有两个大ID在某一个小ID中出现了碰撞,但是只要最终的表示中,另一个小ID不同,我们就认为最终的表示是不同的。
首先介绍的是一个Facebook发表在KDD2020上的方案,把一个大的ID拆解成商+余数的组合。比如一种特征的ID取值介于1-1000000之间。完全保存这种特征的embedding需要 的空间,这里 代表平均的特征维度。我可以找一个除数 ,然后把特征ID唯一的表示为原始ID除以 后得到的商和余数。 这里就选1000,商会有大约1000种取值,而余数也是有大约1000种。然后原始特征的embedding,现在表示为商和余数的两个embedding的组合(可以是拼接,也可以是加起来或者element-wise乘)。由于商和余数各自只有1000种选择,现在整个空间压缩到了2000,相比于1000000,有500倍的压缩!这个压缩是一个平方级的减小。
当然,我们会有疑问,2001和2002这两个ID,算下来商是一样的,那不就意味着有一半的embedding都是一样的吗?是的,所以这个方法一定会带来性能折损,实验部分也能体现的出来。但是这个方法在实验中比直接hash到2000要好。
沿着上面的思路,还可以有更加通用的方案:分成固定的若干个互补分区。比如上面的商和余数的方案,还可以对余数再取 的商和余数,一直往下。也可以拿出这个ID范围内的所有质数,把能整除某个质数的放一起等等。综合下来,对原始复杂度是指数级的衰减。
类似的方法也有今年CIKM的一个方法[2],通过控制二进制表示来压缩空间,但这些方法有一个没有解决的问题是分配到多个分区的过程没有什么逻辑依据,缺乏“语义”。2001和2002因为商一样,所以前半段embedding都是一样的,但是它们也有可能是两个完全没有联系的特征,那有一半embedding都一样就不太合理了。根据我们在FM那几讲中提到的观点,embedding还是要承载一些语义信息的。期望中应该是类型上更接近的特征,共享的概率越大,反之亦然。现在还没有看到有工作涉及这方面,看到这里的读者可以赶紧动手攒paper了!
其实embedding压缩还涉及一个方向是Network Architecture Search(NAS),后面在热点篇里面专门做介绍,这里简单提一下也是可以给各个不同的特征分配不同的权重。
总结一下,无论什么样的压缩方案,肯定都会对效果有影响,毕竟天下没有免费的午餐。但是选用什么样的方案就是根据环境的。在业务还没完全起来的时候,用一些embedding压缩的方案是性价比较高的选择。
Deep Hash Embedding(DHE[3])
回到最开始的问题,我们说embedding占用的空间那么大,其本质原因在什么地方呢?在于我们把原始特征表示为one-hot的,不是0就是1的表示方式当然是需要很大维度才能表示的。如果我们有一个非学习性的方法一上来就把特征ID表示成浮点数会怎么样?如果能表示成一段浮点数的向量会怎么样?
如果找到了这样的方法,后面的事情是水到渠成的:可以就地接一个MLP,把前面的特征表示变换到一般要用的embedding,再接下面的DNN,这样空间的占用一下就下来了!如下图所示:
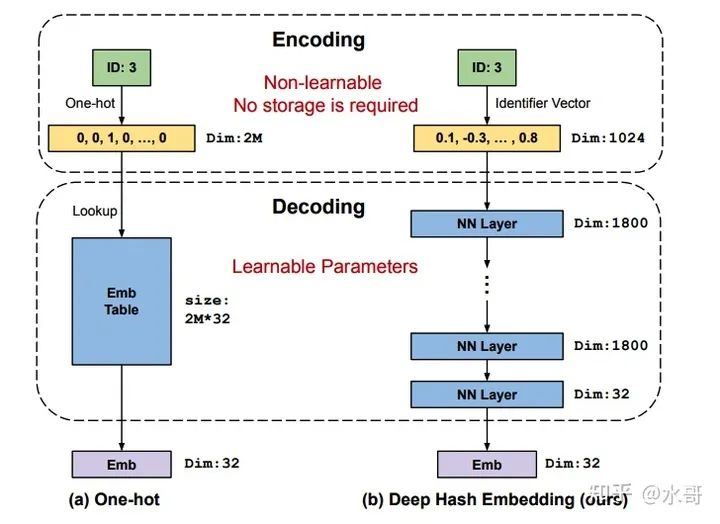
在第一步图上也强调了是non-learnable的,对应左边的look-up table需要占 的空间,而右边的MLP就少非常多了,这样就大大减小了存储消耗。那么怎么把一个原始的ID变成浮点向量呢?首先可以考虑变成整型的向量,我们可以联想到,不同的hash方式可以得到不同的int,同一种hash加不同的种子也可以做到这一点。
当使用各种hash方法/种子拼出一个高维的整数向量后,再做归一化+高斯化就可以得到所需要的浮点数向量,把这个向量送入下面的“decode” MLP即可。
这个方案的另外一个考虑是基于冲突,上面讲的hash方法其实都是存在冲突可能性的。即使是上面商+余数的方案,表面上看最终的embedding不一样,但是局部的冲突可能很大。而使用了许许多多hash方法的结果后,再经过网络变换,最终到了embedding表示这里,冲突的概率就很小了。有一个缺点是,由于embedding也是网络生成的了,一点参数的变化会引起全局特征漂移,这样对记忆性的原则有影响,因此论文中的实验还是没有打过完全不冲突的look-up table。
这个文章很有意思,它是完全根据实际应用场景遇到的问题提出的方案。如果这条路真的能走得深而且work的话可能会是一个很有前途的方向,还有不少可以做的事情。
下期预告
推荐系统精排之锋(12):DIN+DIEN,机器学习唯一指定涨点技Attention
往期回顾
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!

[1]Compositional Embeddings Using Complementary Partitions for Memory-Efficient Recommendation Systems,KDD,2020 https://arxiv.org/pdf/1909.02107.pdf
[2]Binary Code based Hash Embedding for Web-scale Applications,CIKM,2021 https://dl.acm.org/doi/pdf/10.1145/3459637.3482065
[3]Learning to Embed Categorical Features without Embedding Tables for Recommendation,KDD,2021 https://arxiv.org/pdf/2010.10784.pdf



















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









