







文 | 水哥
源 | 知乎
Saying
1. attention要解决两个问题:(1)attention怎么加,在哪个层面上做attention;(2)attention的系数怎么来,谁来得到attention
2. Attention常见的本质原因是求和的普遍存在,只要有求和的地方,加权和的DNA就动了。有人对这种做法就直接叫attention非常不以为然(但是趋势却不可阻挡)
3. attention的本质可能是,极其紧凑的二阶人海战术,或者极其高效的复杂度换涨点方法
这是【从零单排推荐系统】的第19讲。上一讲对于attention开了一个头,主要为了说明的是,为什么我们要做attention,它能起到什么样的作用。DIN/DIEN对attention的作用主要是用作用户行为序列建模,目的是为了得到更好地用户特征表示。实际上,attention可以出现在其他很多环节,也可以起到五花八门的作用。在这一讲,我们对此做一个详细的总结。
从做法上来讲,attention分为这么几种:
加权和,最简单的,也是最常见的。原先的结构中存在一个求和,我们可以变为加权和
element/slot/module-wise乘,生成的attention分数虽然乘上了,但是不做求和,可以认为有体现重要性差异的作用
以Q-K-V的形式做抽象,这种就是特指transformer里面那种了
从作用上讲就比较丰富多彩了,在本讲中总结了这么几种,但实际上可以有很多其他的:
凸显用户的兴趣峰
特征进一步的细化/抽象
对模块进行分化
从输入上来讲,attention也可以分为self-attention和非self的attention,区别在于,产出attention和attention作用的对象,二者用的输入是不是一样的。
Attention的做法
加权和
如果要说最简单的attention方式,就是加权和了。在某环节我们可能需要对特征做sum pooling:
这个过程中每一个 地位是平等的。那么可以简单的给他们分配权重,变为:
此处的 就是attention系数。要注意的是, 可以是数量,向量,也可以是张量。
在推荐系统中使用这种方式的典型例子是这里的AFM(Attentional Factorization Machines,AFM[1])方法,求和的过程恰好是FM中各个embedding求和的操作。AFM的结构如下图:
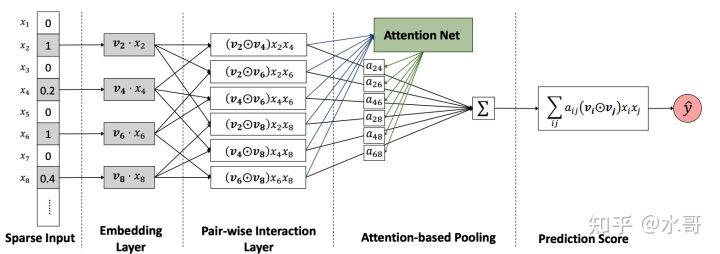
从sparse input这里,挑出所有非0的特征,拿出对应的embedding,然后两两交叉得到若干个pair-wise的interaction。其中每一个都是一个等长的向量 ,中间的 表示element-wise乘法。假如没有attention这回事,后面的结果就是把上面所有的交互结果加起来。那么可以看出这里有一个加的过程,我们attention的DNA就可以动了:在加的过程中给每一个embedding分配一个attention系数,则后面的结果变为:
其中所有的attention系数已经由Softmax归一化。
接下来要阐述的是attention系数怎么来,本文的每个成员的attention系数由它自己输入,即前面的向量 经过一个共享的FC层得到系数。注意一个点是,attention生成的时候一定要纵观全局 , 就是一定要有一个环节能看的见所有成员,否则attention这件事就无从谈起。AFM把看到全局的这个任务交给了一个共享的FC层,这个做法可能是考虑到前面的交互embedding很多,如果都做输入会放不下。
在DeepIntent: Learning Attentions for Online Advertising with Recurrent Neural Networks[2]中也提到了一个非常相似的做法,区别只是后者的主体网络建模是基于RNN的。
element/slot/module-wise乘
element-wise的典型例子是LHUC[3],即生成一个和原来激活元等长的attention向量,然后以element-wise的形式乘上去,在LHUC的原始论文中该系数是一个自由的参数(所以他们可能也不想把这个工作归类在attention上),而在 【1.9万亿参数量,快手落地业界首个万亿参数推荐精排模型[4]】 中,这个mask则是由输入特征变换得来的。
有的工作是把CV中的SENet用在推荐[5]:我们对所有特征的embedding先求和,可以视为Squeeze操作,然后经过DNN输出attention分数,输出的结果和slot数量,即特征数量是相等的。之后每一个特征的embedding整体乘上对应的attention分数,即Excitation操作。这就是slot-wise的乘法的例子,相当于在整段特征之间做轻重的区别。
Q-K-V的形式
这里专指transformer的做法,具体的细节我们留到下一讲。
Attention的作用
上面介绍了attention常见的几种做法,归纳起来其实就是“加权”,求不求和倒无所谓的。attention应用很广泛的原因并不在于操作有多新颖或者多复杂,而是它可以起到的作用非常丰富。在每一个环节都可以考虑。
Attention凸显最相关的兴趣峰
用来凸显用户行为中的兴趣峰就是特指上一讲提到的DIN和DIEN,由于已经详细介绍过这两个工作,这里就不展开了。我们放在一个attention的历史行程下来考虑,这类工作把attention应用到用户行为序列建模的动机还是在于凸显和当前item最相关的兴趣峰。这种用法在下一讲可以由transformer发扬光大。
Attention作为特征进一步细化/抽象工具
上面讲的SENet的操作体现在slot层面即特征层面上,那么对于下一层来说,输入特征的重要性相当于已经最了细化。
在AutoInt[6]中,attention没有作为结果融合或者接近结果处融合的工具,而是作为一个非线性环节出现。一开始把所有的embedding拼接起来,然后用Multi-Head Attention做一步抽象。这个过程会在下一讲详细描述,我们可以先粗略的知道对于Query(Q),Key(K)和Value(V)都是同样的输入,经过抽象后可以得到一个更进一步非线性的表示。那么把这个过程层层堆叠起来,实际上就用Multi-Head Attention替代了DNN在特征抽象上的作用,如下图:
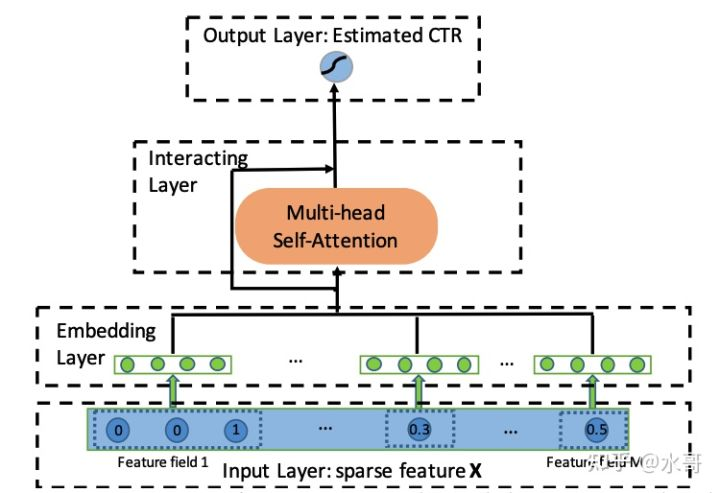
若干层Multi-Head Attention的输出结果直接经过激活函数就是输出了,相当于在这里,Attention替代了DNN原先在非线性映射方面的作用。
Attention用作分化模块的工具
Attention的操作是根据输入的不同,生成不同的权重,来决定后面模块中突出的是谁,抑制的是谁。那么反过来说,只要attention分数分布不是一成不变的情况下,后续的模块也会对输入产生特殊的倾向。某种输入产生了大的attention分数,那么对应位置的模块相当于更多承担这种输入的预测。久而久之,不同的模块会对不同的用户/任务有所专注,这就是标题所说的“分化”。
一个典型的例子就是MMoE[7],MMoE中根据任务的不同会生成不同的gate(attention),然后作用在module(expert)上。对于CTR任务,总有的gate输出会偏大,那么对应位置的expert在CTR任务中就要扛起责任,同理,有的expert就是专注在CVR任务上。
还有我们提出的POSO[8],POSO本身是我本年度最自豪的工作之一,其中的细节我们会留到难点篇,在用户冷启动问题上大讲(吹)特讲(吹),在这里只是先提一下,POSO的主要环节是模块的输出的加权和:
其中 是若干个形式一致的模块,而 是gating network的输出,也可以看做是attention的一种。其中控制attention的输入( 是新老用户,比如新用户attention分数中第1-2个数字比较大,而对于老用户则是3-4的分数较大,那么模块中1-2就会变的专注于新用户,而其他的专注于老用户。
为什么attention如此有用?
迄今为止,我们说attention非常有用,但没有讨论过它为什么这么有用。有读者可能会说,因为attention做了更高程度的个性化/因为attention非常符合人的认知呀!这样的大道理当然没错,但是要注意,这些说法只能说明attention可能有用,或者大概率有用,不能推出attention如此有用。现在的现状是什么呢?几乎只要是个地方放个attention就能涨点,有点太work了,这不是大道理能cover的。从CV领域的SENet,到NLP的Multi-head attention,似乎attention是哪里都能用的。而且最奇怪的点是,self-attention(即attention作用的对象和生成attention的特征都由相同的输入决定)也是很work的,比如SENet这样的做法。这不是很奇怪吗,没有添加额外的信息就涨点了,天上真的掉馅饼了?
我自己想了两点假说(没有搜到相关资料,如果有好的资料欢迎指出),供大家讨论:
attention的本质可能是,极其紧凑的二阶人海战术
即attention十分work的本质是因为人海战术十分work。当只有两个成员的时候,一个成员组成feature map,一个成员组成attention score,并且相互交叉乘起来的形式是只有两个成员情况下的最优(或者极优)形式。如果顺着这个思路的话,实验验证应该是两个模型分别训练,然后结果求和,和feature map x attention map这种形式做对比,如果后者比前者有效,是不是就能证明这一点?(ICML等等我)
2. attention是一种效率极高的复杂度换涨点方法
虽然attention轻,但它终究还是加了东西的。这些东西加在特征维度上,加在通道上,都不如加在mask上效率高。这个假说和上面那个不是完全互斥的,存在overlap。
下期预告
推荐系统精排之锋(14):Transformer的升维打击
往期回顾
14.DIN+DIEN,机器学习唯一指定涨点技Attention
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!

[1] Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks,IJCAI,2017 https://www.ijcai.org/proceedings/2017/0435.pdf
[2] DeepIntent: Learning Attentions for Online Advertising with Recurrent Neural Networks https://www.kdd.org/kdd2016/papers/files/rfp0289-zhaiA.pdf
[3] Learning Hidden Unit Contributions for Unsupervised Acoustic Model Adaptation,2016 https://arxiv.org/pdf/1601.02828.pdf
[4] https://zhuanlan.zhihu.com/p/358779957
[5] 1.9万亿参数量,快手落地业界首个万亿参数推荐精排模型 https://finance.sina.com.cn/tech/2021-02-03/doc-ikftpnny3601504.shtml
[6] AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks,CIKM,2019 https://arxiv.org/pdf/1810.11921.pdf
[7] Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts,KDD,2018 https://www.kdd.org/kdd2018/accepted-papers/view/modeling-task-relationships-in-multi-task-learning-with-multi-gate-mixture-
[8] POSO: Personalized Cold Start Modules for Large-scale Recommender Systems,2021 https://arxiv.org/pdf/2108.04690.pdf



















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









