







Pandas中Concat与Append
在Numpy中,我们介绍过可以用np.concatenate、np.stack、np.vstack和np.hstack实现合并功能。Pandas中有一个pd.concat()函数与concatenate语法类似,但是配置参数更多,功能也更强大。
主要参数:
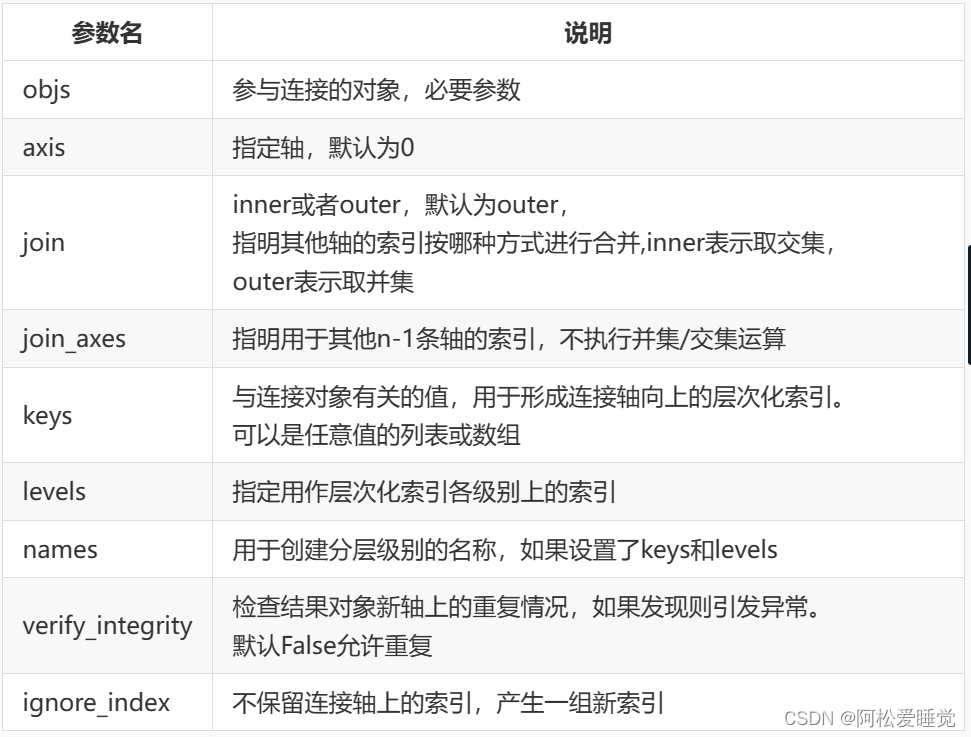
pd.concat()可以简单地合并一维的Series或DataFrame对象。
# Series合并
ser1 = pd.Series(['A', 'B', 'C'], index=[1, 2, 3])
ser2 = pd.Series(['D', 'E', 'F'], index=[4, 5, 6])
pd.concat([ser1,ser2])
Out:
1 A
2 B
3 C
4 D
5 E
6 F
dtype: object
# DataFrame合并,将concat的axis参数设置为1即可横向合并
df1 = pd.DataFrame([["A1","B1"],["A2","B2"]],index=[1,2],columns=["A","B"])
df2 = pd.DataFrame([["A3","B3"],["A4","B4"]],index=[3,4],columns=["A","B"])
pd.concat([df1,df2])
Out:
A B
1 A1 B1
2 A2 B2
3 A3 B3
4 A4 B4
合并时索引的处理
np.concatenate与pd.concat最主要的差异之一就是Pandas在合并时会保留索引,即使索引是重复的!
df3 = pd.DataFrame([["A1","B1"],["A2","B2"]],index=[1,2],columns=["A","B"])
df4 = pd.DataFrame([["A1","B1"],["A2","B2"]],index=[1,2],columns=["A","B"])
pd.concat([df3,df4])
Out:
A B
1 A1 B1
2 A2 B2
1 A3 B3
2 A4 B4
- 如果你想要检测pd.concat()合并的结果中是否出现了重复的索引,可以设置verify_integrity参数。将参数设置为True,合并时若有索引重复就会触发异常。
try:
pd.concat([df3, df4], verify_integrity=True)
except ValueError as e:
print("ValueError:", e)
Out:
ValueError: Indexes have overlapping values: [0, 1]
- 有时索引无关紧要,那么合并时就可以忽略它们,可以通过设置 ignore_index参数为True来实现。
pd.concat([df3,df4],ignore_index=True)
Out:
A B
0 A0 B0
1 A1 B1
2 A2 B2
3 A3 B3
- 另一种处理索引重复的方法是通过keys参数为数据源设置多级索引标签,这样结果数据就会带上多级索引。
pd.concat([df3, df4], keys=['x', 'y'])
Out:
A B
x 0 A0 B0
1 A1 B1
y 0 A2 B2
1 A3 B3
join和join_axes参数
前面介绍的简单示例都有一个共同特点,那就是合并的DataFrame都是同样的列名。而在实际工作中,需要合并的数据往往带有不同的列名,而 pd.concat提供了一些参数来解决这类合并问题。
df5 = pd.DataFrame([["A1","B1","C1"],["A2","B2","C2"]],index=[1,2],columns=["A","B","C"])
df6 = pd.DataFrame([["B3","C3","D3"],["B4","C4","D4"]],index=[3,4],columns=["B","C","D"])
pd.concat([df5,df6])
Out:
A B C D
1 A1 B1 C1 NaN
2 A2 B2 C2 NaN
3 NaN B3 C3 D3
4 NaN B4 C4 D4
可以看到,结果中出现了缺失值,如果不想出现缺失值,可以使用join和join_axes参数。
pd.concat([df5,df6],join="inner") # 合并取交集
Out:
B C
1 B1 C1
2 B2 C2
3 B3 C3
4 B4 C4
# join_axes的参数需为一个列表索引对象
pd.concat([df5,df6],join_axes=[pd.Index(["B","C"])])
Out:
B C
1 B1 C1
2 B2 C2
3 B3 C3
4 B4 C4
append()方法
因为直接进行数组合并的需求非常普遍,所以Series和DataFrame 对象都支持append方法,让你通过最少的代码实现合并功能。例如,df1.append(df2)效果与pd.concat([df1,df2])一样。
但是它和Python中的append不一样,每次使用Pandas中的append()都需要重新创建索引和数据缓存。
















 3115
3115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











