







词云对于网络文本中出现频率较多的关键词予以视觉上额突出,形成“关键词云层”或“关键词渲染”,从而过滤掉大量的文本信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨。
安装相关的包
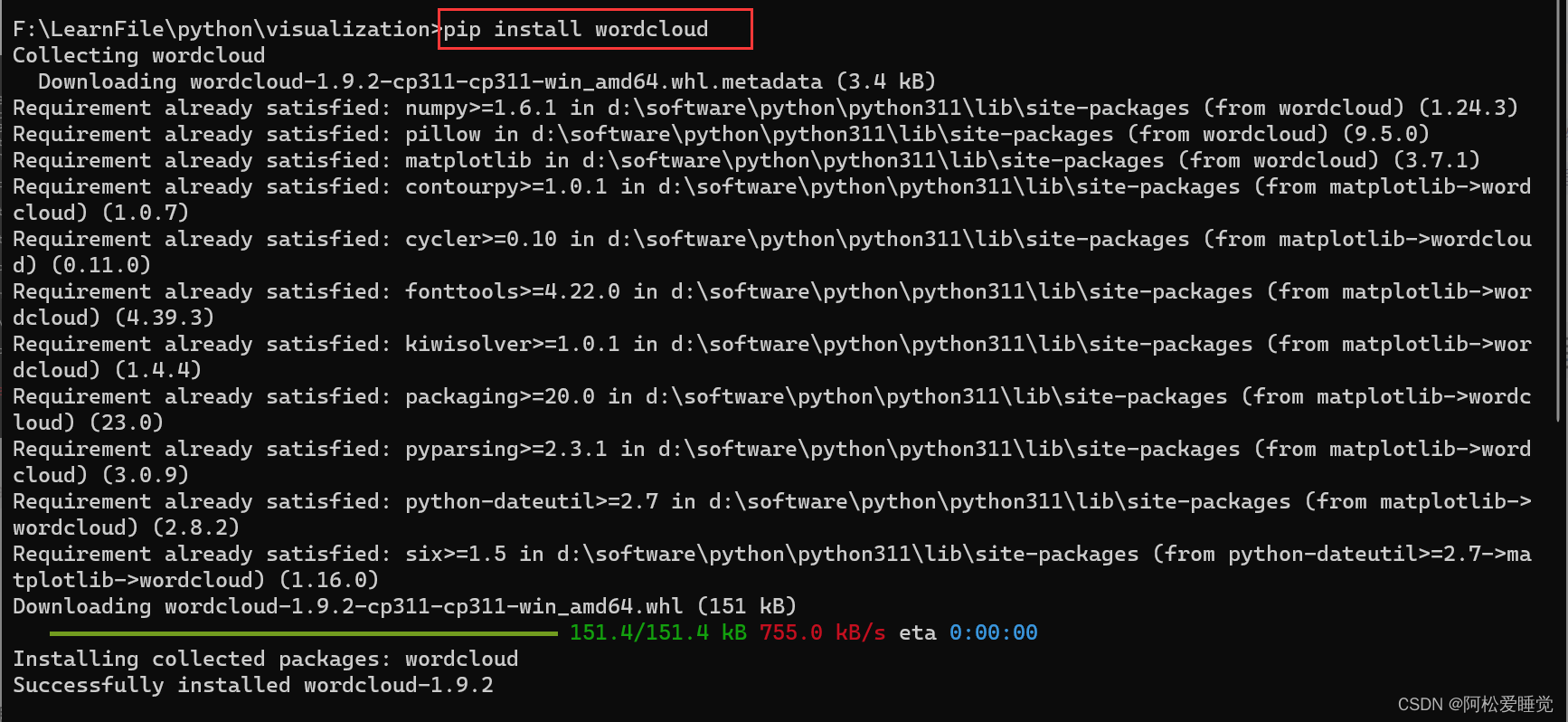
绘制词云安装两个包,WordCloud包和jieba包。
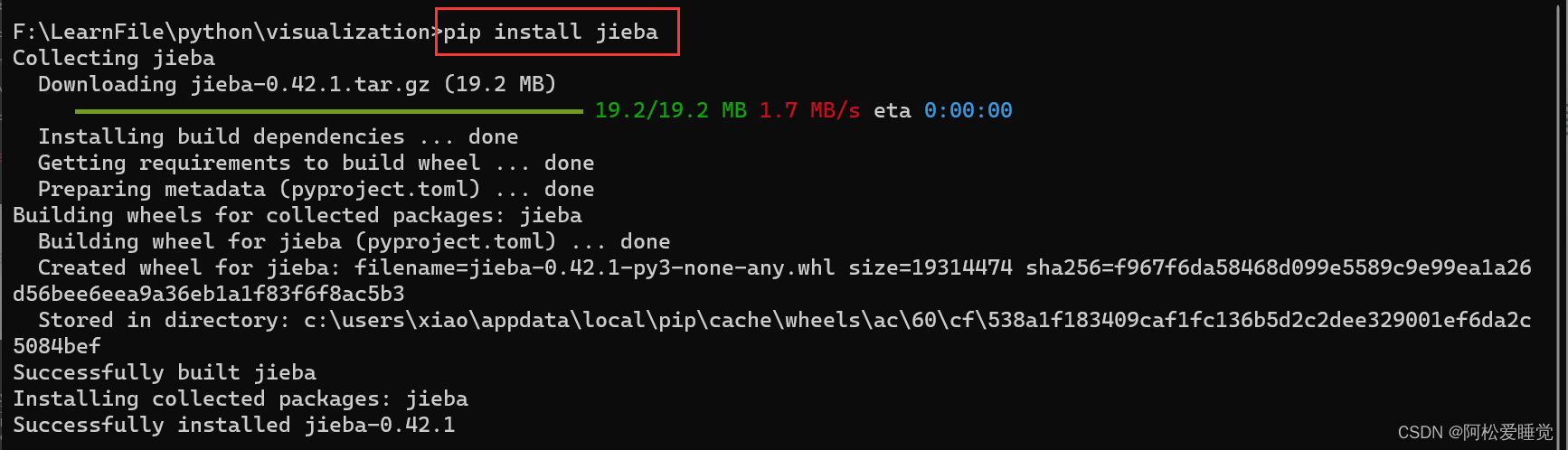
jieba包的作用是从句子中分割词汇。
pip install wordcloud
pip install jieba
词云生成过程
一般生成词云的过程为:
- 首先使用pandas读取数据并将需要分析的数据转化为列表;
- 对获得的列表数据利用分词工具jieba进行遍历分词;
- 使用WordCloud设置词云图片的属性、掩码和停用词,并生成词云图像。
示例
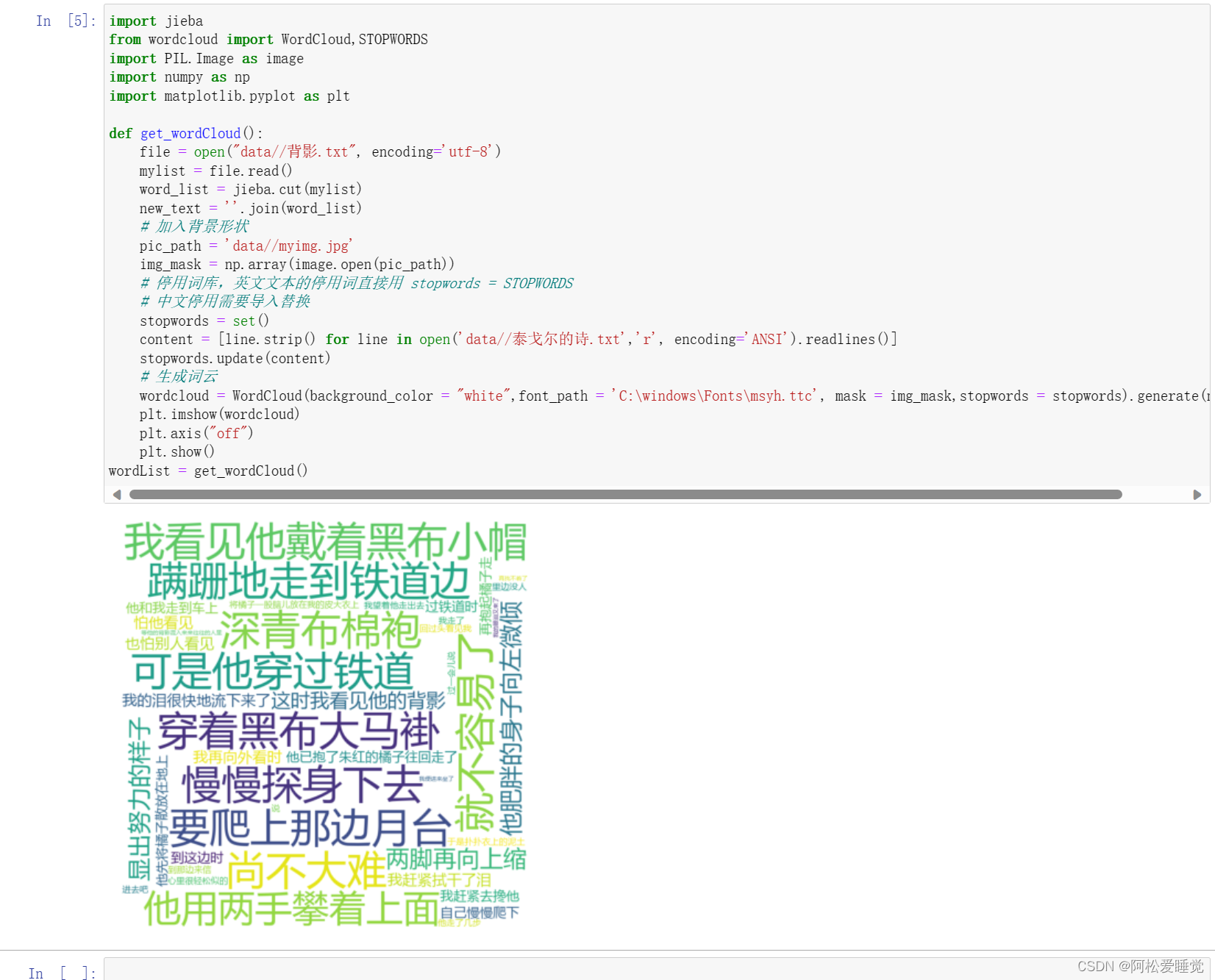
import jieba
from wordcloud import WordCloud,STOPWORDS
import PIL.Image as image
import numpy as np
import matplotlib.pyplot as plt
def get_wordCloud():
# 读取文件的时候记得查看文件的编码方式,在记事本的右下角(具体位置见文末图)
file = open("data//背影.txt", encoding='utf-8')
mylist = file.read()
word_list = jieba.cut(mylist)
new_text = ''.join(word_list)
# 加入背景形状
pic_path = 'data//myimg.jpg'
img_mask = np.array(image.open(pic_path))
# 停用词库,英文文本的停用词直接用 stopwords = STOPWORDS
# 中文停用需要导入替换
stopwords = set()
# 读取文件的时候记得查看文件的编码方式,在记事本的右下角(具体位置见文末图)
content = [line.strip() for line in open('data//泰戈尔的诗.txt','r', encoding='ANSI').readlines()]
stopwords.update(content)
# 生成词云
wordcloud = WordCloud(background_color = "white",font_path = 'C:\windows\Fonts\msyh.ttc', mask = img_mask,stopwords = stopwords).generate(new_text)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
wordList = get_wordCloud()

全部:
文件编码:

















 453
453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











