







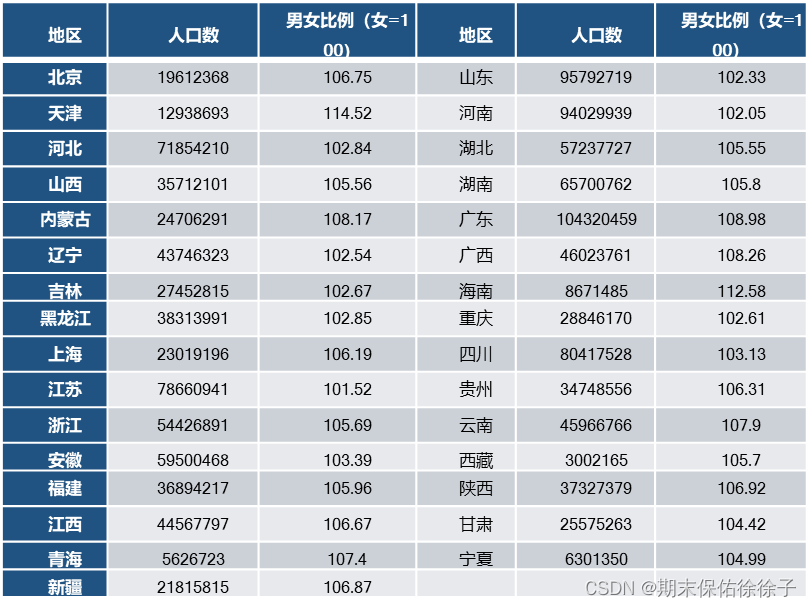
1、题目
选取中华人民共和国第六次人口普查的各地区人口数以及男女比例进行K-Means聚类分析。
2、 代码
# K取值2
print("step2.1:聚类")
k=2
centroids,clusterAssment=kmeans(dataSetKNN1,k)
print('数据类型:',dataSetKNN1.dtype)
print("step3.1:结果输出:见'图11.2.2.png'")
showCluster_2(dataSetKNN1,k,centroids,clusterAssment)
# K取值3
print("step2.2:聚类")
k=3
centroids,clusterAssment=kmeans(dataSetKNN1,k)
print('数据类型:',dataSetKNN1.dtype)
print("step3.2:结果输出:见'图11.2.3.png'")
showCluster_2(dataSetKNN1,k,centroids,clusterAssment)3、结果图
(1)我觉得这个图有问题,但没想出来怎么修改。等待后续修改一下,继续上传。
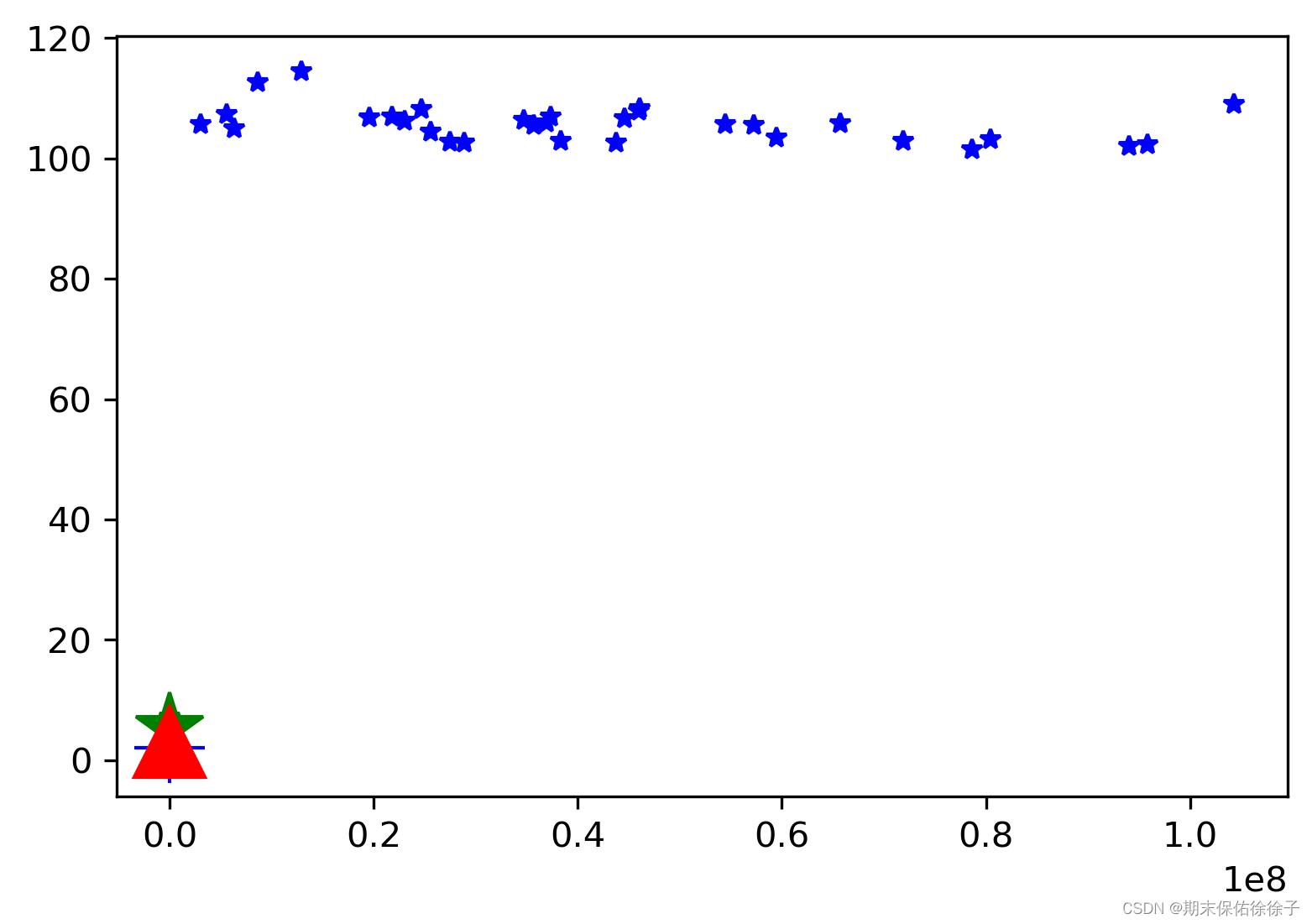
(2)

(3)
















 3831
3831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









