







在jdk1.6的时候,java默认使用的排序算法是mergesort。
public static <T> void sort(T[] a, Comparator<? super T> c) {
T[] aux = (T[])a.clone();
if (c==null)
mergeSort(aux, a, 0, a.length, 0);
else
mergeSort(aux, a, 0, a.length, 0, c);
}而自从jdk1.7之后,java默认使用的排序算法变为了TimSort,接下来看看TimSort在jdk中是如何实现的。
public static <T> void sort(T[] a, Comparator<? super T> c) {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, c);
else
TimSort.sort(a, c);
}其中LegacyMergeSort.userRequested用于兼容以前老的mergesort算法,当你设置了java.util.Arrays.useLegacyMergeSort之后,就可以使用老的算法了。
而在默认情况下会进入TimSort算法。
static <T> void sort(T[] a, int lo, int hi, Comparator<? super T> c) {
// 1 -- 当没有定义比较器的时候,会采用ComparableTimSort进行排序。当使用ComparableTimSort
// 进行排序的时候,待排序的数组中的元素需要实现Comparable接口。
if (c == null) {
Arrays.sort(a, lo, hi);
return;
}
// 2 -- 检查length low high 之间的关系,当关系不满足的时候直接抛出异常
// 1) IllegalArgumentException
// 2) ArrayIndexOutOfBoundsException
rangeCheck(a.length, lo, hi);
// 3 -- 对于大小为0或者1的时候,表示已经排序好,不需要继续进行了
int nRemaining = hi - lo;
if (nRemaining < 2)
return; // Arrays of size 0 and 1 are always sorted
// 4 -- 当数组的大小小于MIN_MERGE(32)的时候,会调用mini-TimSort进行排序
// If array is small, do a "mini-TimSort" with no merges
if (nRemaining < MIN_MERGE) {
int initRunLen = countRunAndMakeAscending(a, lo, hi, c);
binarySort(a, lo, hi, lo + initRunLen, c);
return;
}
// 5 -- 正式排序
/**
* March over the array once, left to right, finding natural runs,
* extending short natural runs to minRun elements, and merging runs
* to maintain stack invariant.
*/
TimSort<T> ts = new TimSort<>(a, c);
int minRun = minRunLength(nRemaining);
do {
// Identify next run
int runLen = countRunAndMakeAscending(a, lo, hi, c);
// If run is short, extend to min(minRun, nRemaining)
if (runLen < minRun) {
int force = nRemaining <= minRun ? nRemaining : minRun;
binarySort(a, lo, lo + force, lo + runLen, c);
runLen = force;
}
// Push run onto pending-run stack, and maybe merge
ts.pushRun(lo, runLen);
ts.mergeCollapse();
// Advance to find next run
lo += runLen;
nRemaining -= runLen;
} while (nRemaining != 0);
// Merge all remaining runs to complete sort
assert lo == hi;
ts.mergeForceCollapse();
assert ts.stackSize == 1;
}其中最要的部分都集中在第五步,下面重点分析这部分。
在进入正题之前先要介绍一个概念:什么是run? 看看维基百科是如何解释的,
*A natural run is a sub-array that is already ordered. Natural runs in real-world data may be of varied lengths. Timsort chooses a sorting technique depending on the length of the run. For example, if the run length is smaller than a certain value, insertion sort is used. Thus Timsort is an adaptive sort.[5]
The size of the run is checked against the minimum run size. The minimum run size (minrun) depends on the size of the array. For an array of fewer than 64 elements, minrun is the size of the array, reducing Timsort to an insertion sort. For larger arrays, minrun is chosen from the range 32 to 64 inclusive, such that the size of the array, divided by minrun, is equal to, or slightly smaller than, a power of two. The final algorithm takes the six most significant bits of the size of the array, adds one if any of the remaining bits are set, and uses that result as the minrun. This algorithm works for all arrays, including those smaller than 64.[5] *
上面的这段话的意思就是一个run就是一个数组的子数组,并且这个子数组(连续的)是已经排序好的。
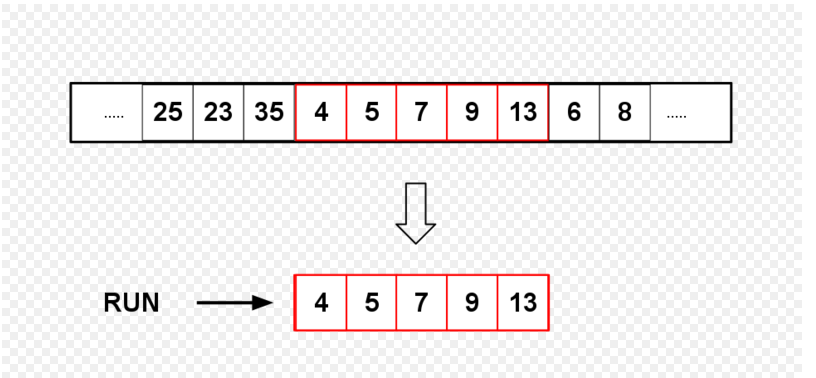
好了,可以进入正题了~~
1、调用minRunLength获取最小的run的大小
private static int minRunLength(int n) {
assert n >= 0;
int r = 0; // Becomes 1 if any 1 bits are shifted off
while (n >= MIN_MERGE) {
// 只要当前n的最后一位为1,那么r就是1
r |= (n & 1);
// 右移1位
n >>= 1;
}
return n + r;
}当n小于32的时候,返回值为n
当n大于等于32,并且当n为2的倍数的时候,在循环结束的时候r都为0,因为在此期间n的末尾都是0。同时循环结束的时候n为16,因此返回值为16
当n大于等于32,并且n不为2的倍数的时候,假设在极端的情况下最后一次循环的时候n为63(二进制位111111),此时r为1,n右移1位后变为31,返回值为32。另一种极端情况下最后一次循环的时候n为32(二进制10000)的时候,由于这里的约束条件为n不为2的倍数,因此之前r肯定已经为1了,所以此时返回值为17。因此此时返回值在[17,32]之间。
注:在jdk对于最后一种情况的解释为,
Else return an int k, MIN_MERGE/2 <= k <= MIN_MERGE, such that n/k is close to, but strictly less than, an exact power of 2.
似乎K不可能为MIN_MERGE/2,为了验证这个结论可以使用如下程序
public static int minRunLength(int n) {
assert n >= 0;
int r = 0;
while (n >= 32) {
r |= (n & 1);
n >>= 1;
}
return n + r;
}
public static void main(String[] args) {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
int l = minRunLength(i);
if (l == 16) {
System.out.println(i + " " + l);
}
}
}可以看到如下的结果,只有2的倍数才可能返回16(MIN_MERGE/2)。猜测可能是注释不严谨吧。。
16 16
32 16
64 16
128 16
256 16
512 16
1024 16
2048 16
4096 16
8192 16
16384 162、正式进入循环,计算run的大小
private static <T> int countRunAndMakeAscending(T[] a, int lo, int hi,
Comparator<? super T> c) {
assert lo < hi;
int runHi = lo + 1;
if (runHi == hi)
return 1;
// Find end of run, and reverse range if descending
if (c.compare(a[runHi++], a[lo]) < 0) { // Descending
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) < 0)
runHi++;
reverseRange(a, lo, runHi);
} else { // Ascending
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) >= 0)
runHi++;
}
return runHi - lo;
}
上面的代码的功能是从low位置开始,找出最长的run的长度。也就是说返回值为T的时候,需要满足如下条件
a[low] <= a[low + 1] <= a[low + 2] <= ...a[low + T - 1] 并且 a[low + T - 1] > a[low + T]或者
a[low] >= a[low + 1] >= a[low + 2] >= ...a[low + T - 1] 并且 a[low + T - 1] < a[low + T]
需要注意的是如果run是按照从小到大排序的,就需要进行reverse操作,将其变为从小到大排序。
3、当run的长度小于最小的minRun的时候,重置run长度
会将run的长度设置为minRun和带排序的数组长度中较小的那一个。
if (runLen < minRun) {
int force = nRemaining <= minRun ? nRemaining : minRun;
binarySort(a, lo, lo + force, lo + runLen, c);
runLen = force;
}同时会对从low到low+force的元素进行重排序,由于low到low+runLen之间已经排好序,所以针对low+runLen之后的元素进行插入排序。对于插入的位置使用二分查找的方法查找。。
@SuppressWarnings("fallthrough")
private static <T> void binarySort(T[] a, int lo, int hi, int start,
Comparator<? super T> c) {
assert lo <= start && start <= hi;
if (start == lo)
start++;
for ( ; start < hi; start++) {
T pivot = a[start];
// Set left (and right) to the index where a[start] (pivot) belongs
int left = lo;
int right = start;
assert left <= right;
/*
* Invariants:
* pivot >= all in [lo, left).
* pivot < all in [right, start).
*/
while (left < right) {
int mid = (left + right) >>> 1; // 这里使用位移操作!!!
if (c.compare(pivot, a[mid]) < 0)
right = mid;
else
left = mid + 1;
}
assert left == right;
/*
* The invariants still hold: pivot >= all in [lo, left) and
* pivot < all in [left, start), so pivot belongs at left. Note
* that if there are elements equal to pivot, left points to the
* first slot after them -- that's why this sort is stable.
* Slide elements over to make room for pivot.
*/
int n = start - left; // The number of elements to move
// Switch is just an optimization for arraycopy in default case
switch (n) {
case 2: a[left + 2] = a[left + 1];
case 1: a[left + 1] = a[left];
break;
default: System.arraycopy(a, left, a, left + 1, n);
}
a[left] = pivot;
}
}这中间有一点值得我们学习,对于mid的求值,使用移位操作。对于性能追求体现在点点滴滴。。
4、记录run的开始位置和length
private void pushRun(int runBase, int runLen) {
this.runBase[stackSize] = runBase;
this.runLen[stackSize] = runLen;
stackSize++;
}5、进行初步的合并
private void mergeCollapse() {
while (stackSize > 1) {
int n = stackSize - 2;
// 当run的个数大于2的时候,不断检查是否runLen[n-1] >= runLen[n] + runLen[n+1],
// 当不满足的时候需要进行合并。这时候有两种情况当runLen[n-1]<runLen[n+1]的时候对第n-1
// 个和第n个进行合并,否则对第n个和第n+1个进行合并。则合并的过程中会修改stackSize的值
// 该过程会不断继续,知道满足条件位置。
if (n > 0 && runLen[n-1] <= runLen[n] + runLen[n+1]) {
if (runLen[n - 1] < runLen[n + 1])
n--;
// 当且仅有两个run的时候,需要满足runLen[n] >= runLen[n + 1],否则就进行合并
} else if (runLen[n] <= runLen[n + 1]) {
mergeAt(n);
} else {
break; // Invariant is established
}
}
}上面的代码会不断将run进行合并,直到对于任意的i满足条件
- runLen[i - 3] > runLen[i - 2] + runLen[i - 1]
runLen[i - 2] > runLen[i - 1]
具体来看看mergeAt是如何实现的吧。
private void mergeAt(int i) {
assert stackSize >= 2;
assert i >= 0;
assert i == stackSize - 2 || i == stackSize - 3;
// 获取前一个run的起始位置
int base1 = runBase[i];
// 获取前一个run的长度
int len1 = runLen[i];
// 获得后一个run的起始位置
int base2 = runBase[i + 1];
// 获取后一个run的长度
int len2 = runLen[i + 1];
assert len1 > 0 && len2 > 0;
assert base1 + len1 == base2;
/*
* Record the length of the combined runs; if i is the 3rd-last
* run now, also slide over the last run (which isn't involved
* in this merge). The current run (i+1) goes away in any case.
*/
// 合并后新的run的长度为len1 + len2
runLen[i] = len1 + len2;
// 当stackSize >= 3的时候,i的runLen已经更新了。同时需要将i+1的起始位置和长度更新为i+2的
// 也就是i+2会前移
if (i == stackSize - 3) {
runBase[i + 1] = runBase[i + 2];
runLen[i + 1] = runLen[i + 2];
}
// stackSize缩减
stackSize--;
/*
* Find where the first element of run2 goes in run1. Prior elements
* in run1 can be ignored (because they're already in place).
*/
// 找到run2的第一个元素插入到run1中的位置
int k = gallopRight(a[base2], a, base1, len1, 0, c);
assert k >= 0;
// 更新base1和len1
base1 += k;
len1 -= k;
if (len1 == 0)
return;
/*
* Find where the last element of run1 goes in run2. Subsequent elements
* in run2 can be ignored (because they're already in place).
*/
// 找到run1的最后一个元素插入到run2中的位置
len2 = gallopLeft(a[base1 + len1 - 1], a, base2, len2, len2 - 1, c);
assert len2 >= 0;
if (len2 == 0)
return;
// Merge remaining runs, using tmp array with min(len1, len2) elements
if (len1 <= len2)
mergeLo(base1, len1, base2, len2);
else
mergeHi(base1, len1, base2, len2);
}在上面会找出两个位置,如下图所示,
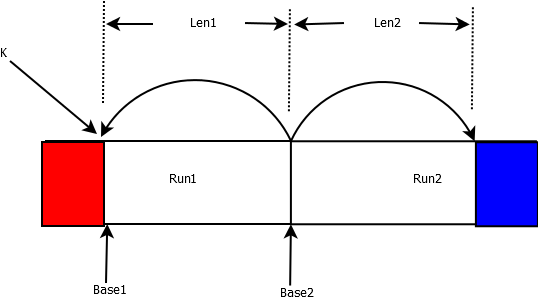
图1
Run1和Run2合并后红色部分一定在最前面,而蓝色部分一定在最后面,只有白色的部分是真正需要重新排序的。
之后会根据len1和len2的大小关系决定采用哪种合并方式,这里只介绍mergeLo的合并方式。
private void mergeLo(int base1, int len1, int base2, int len2) {
assert len1 > 0 && len2 > 0 && base1 + len1 == base2;
// Copy first run into temp array
T[] a = this.a; // For performance
T[] tmp = ensureCapacity(len1);
int cursor1 = tmpBase; // Indexes into tmp array
int cursor2 = base2; // Indexes int a
int dest = base1; // Indexes int a
// 将原数组从base1开始的len1个元素拷贝到tmp从cursor1开始的位置。
System.arraycopy(a, base1, tmp, cursor1, len1);
// Move first element of second run and deal with degenerate cases
// 这里没太看懂为什么要这么做~
a[dest++] = a[cursor2++];
if (--len2 == 0) {
System.arraycopy(tmp, cursor1, a, dest, len1);
return;
}
if (len1 == 1) {
System.arraycopy(a, cursor2, a, dest, len2);
a[dest + len2] = tmp[cursor1]; // Last elt of run 1 to end of merge
return;
}
Comparator<? super T> c = this.c; // Use local variable for performance
int minGallop = this.minGallop; // " " " " "
outer:
while (true) {
int count1 = 0; // Number of times in a row that first run won
int count2 = 0; // Number of times in a row that second run won
/*
* Do the straightforward thing until (if ever) one run starts
* winning consistently.
*/
do {
// 开始将run1和run2的元素进行比较并且进行更新。由于run1的元素已经备份到tmp中了,
// 因此可以直接使用run2或者tmp中的元素直接覆盖run1中的元素。
assert len1 > 1 && len2 > 0;
// 将比较的较小的元素逐渐放置原数组中,其中dst用于控制下标在原数组中的移动
// cursor1用于控制下标在tmp中的移动
// cursor2用于控制下标在run2中的移动
if (c.compare(a[cursor2], tmp[cursor1]) < 0) {
a[dest++] = a[cursor2++];
count2++;
count1 = 0;
if (--len2 == 0)
break outer;
} else {
a[dest++] = tmp[cursor1++];
count1++;
count2 = 0;
if (--len1 == 1)
break outer;
}
} while ((count1 | count2) < minGallop);
/*
* One run is winning so consistently that galloping may be a
* huge win. So try that, and continue galloping until (if ever)
* neither run appears to be winning consistently anymore.
*/
do {
assert len1 > 1 && len2 > 0;
// 将tmp剩余的部分当做run3,run2剩余的部分当做run4,继续针对run3和run4
// 使用跟之前相同的方法找到run4第一个元素在run3中插入的位置,找到run3最后一个元素
// 在run4插入的位置。原理与图1相同。
// 这里使用run3和run4是为了和run1和run2分开。
count1 = gallopRight(a[cursor2], tmp, cursor1, len1, 0, c);
if (count1 != 0) {
System.arraycopy(tmp, cursor1, a, dest, count1);
dest += count1;
cursor1 += count1;
len1 -= count1;
if (len1 <= 1) // len1 == 1 || len1 == 0
break outer;
}
a[dest++] = a[cursor2++];
if (--len2 == 0)
break outer;
count2 = gallopLeft(tmp[cursor1], a, cursor2, len2, 0, c);
if (count2 != 0) {
System.arraycopy(a, cursor2, a, dest, count2);
dest += count2;
cursor2 += count2;
len2 -= count2;
if (len2 == 0)
break outer;
}
a[dest++] = tmp[cursor1++];
if (--len1 == 1)
break outer;
minGallop--;
} while (count1 >= MIN_GALLOP | count2 >= MIN_GALLOP);
if (minGallop < 0)
minGallop = 0;
minGallop += 2; // Penalize for leaving gallop mode
} // End of "outer" loop
this.minGallop = minGallop < 1 ? 1 : minGallop; // Write back to field
if (len1 == 1) {
assert len2 > 0;
System.arraycopy(a, cursor2, a, dest, len2);
a[dest + len2] = tmp[cursor1]; // Last elt of run 1 to end of merge
} else if (len1 == 0) {
throw new IllegalArgumentException(
"Comparison method violates its general contract!");
} else {
assert len2 == 0;
assert len1 > 1;
System.arraycopy(tmp, cursor1, a, dest, len1);
}
}a) 从base1到base1+len1复制到tmp中
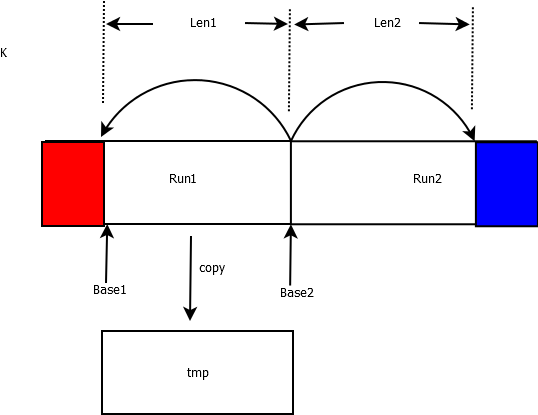
b) 指针初始化
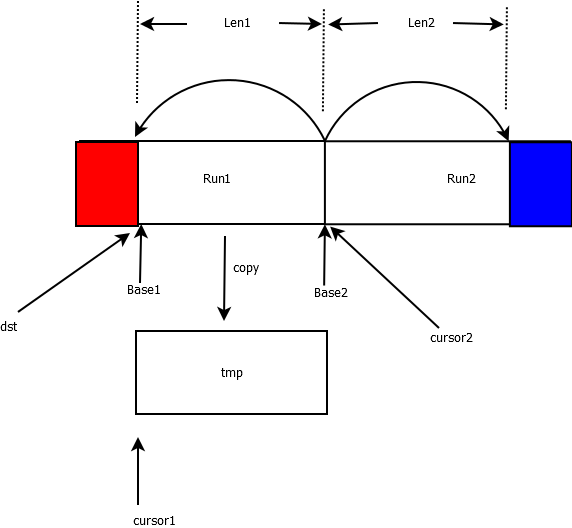
c) 第一次排序结束
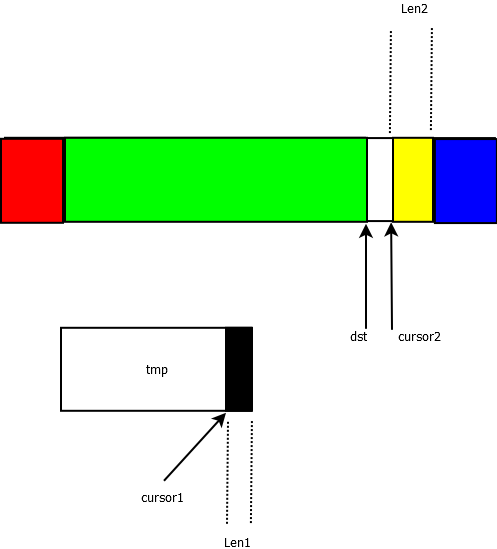
图2
其中绿色为已经排序结束的。可以根据上面的代码看到排序结束的条件之一是,while((count1 | count2) < minGallop),由于在同一时刻count1和count2必有一个为0,所以count1 | count2其实就是count1和count2中较大的数字,也就是说当任意一方连续将超过7个元素放置到原数组中。也就是源码中的注释所说的连续赢了7次
d) 将黄色和黑色部分按照图1的方式重新进行处理,然后进行进行拷贝更新到原数组中。。然后又会形成图2类似的样子,继续按照该步骤进行处理直到满足退出条件。
6、最终的合并
private void mergeForceCollapse() {
while (stackSize > 1) {
int n = stackSize - 2;
if (n > 0 && runLen[n - 1] < runLen[n + 1])
n--;
mergeAt(n);
}
}这里调用的也是mergeAt进行合并。注意这里的合并顺序是倒序的,也就是说每次合并都是针对后面两个run。如果从前面两个开始合并,每次合并都需要将之后的run的数据向前移,而倒序合并就避免了这种情况,从时间复杂度上讲更优。
小结:
上面大致介绍了jdk中是如何实现TimSort的。那么为什么jdk要从mergesort迁移到TimSort呢?先来看看各个排序算法的时间复杂度。

可以看到在最好的情况下Timsort的复杂度达到O(n),同时在平均和最坏的情况下时间复杂度都是O(nlogn),也优于其他的排序算法。为什么TimSort这么快呢?
On real-world data, Timsort often requires far fewer than O(nlogn) comparisons, because it takes advantage of the fact that sublists of the data may already be ordered.[7]维基百科里给出了较明确的答案,因为它充分利用了子列表已经排好序的特性,而不是忽略这个特性将所有元素当做无序的进行排序。















 7528
7528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









