







History
encoder-decoder
2014年Kyunghyun Cho[1]提出了RNN Encoder-Decoder的网络结构,主要用在翻译上面。
encoder将变长的输入序列映射到一个固定长度的向量,decoder将该向量进一步映射到另外一个变长的输出序列,网络结构如下图:
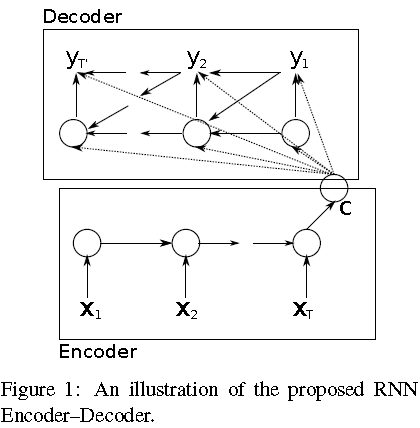
encoder:
h
⟨
t
⟩
=
f
(
h
⟨
t
−
1
⟩
,
x
t
)
\boldsymbol h_{\langle t \rangle}=f(\boldsymbol h_{\langle t-1 \rangle}, x_t)
h⟨t⟩=f(h⟨t−1⟩,xt)
decoder:
h
⟨
t
⟩
=
f
(
h
⟨
t
−
1
⟩
,
y
t
−
1
,
c
)
\boldsymbol h_{\langle t \rangle}=f(\boldsymbol h_{\langle t-1 \rangle}, y_{t-1}, c)
h⟨t⟩=f(h⟨t−1⟩,yt−1,c)
P
(
y
t
∣
y
t
−
1
,
.
.
.
,
y
1
,
c
)
=
g
(
h
⟨
t
⟩
,
y
t
−
1
,
c
)
P(y_t|y_{t-1},...,y_1,c)=g(\boldsymbol h_{\langle t \rangle}, y_{t-1}, c)
P(yt∣yt−1,...,y1,c)=g(h⟨t⟩,yt−1,c)
其中
c
c
c是encoder最后时刻的
h
h
h,
f
(
)
f()
f()是类似于简化版的LSTM单元,具有reset gate和update gate,以实现捕捉short-term和long-term的依赖性。
sequence to sequence
2014年google的Ilya Sutskever[2]等人提出了sequence to sequence的学习方法来解决英文到法文的翻译问题,整体框架如下
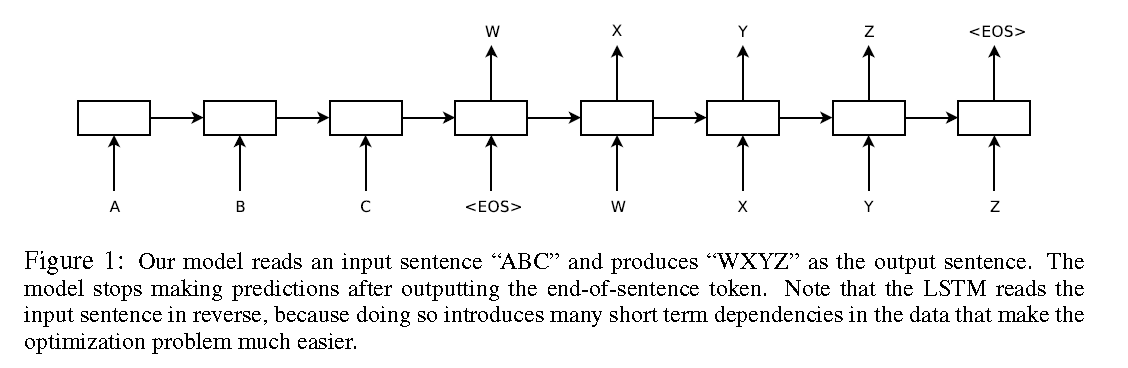
相比于[1],主要是网络使用LSTM,并且将输入序列进行翻转,解决了长序列性能下降的问题。
attention
Graves[3]在2013首先在handwriting synthesis中引入attention的机制,和简单的sequence generation不同,在预测的时候,还通过soft window使用了额外的输入信息。在动态产生预测的同时,也确定了text和pen locations之间的对齐关系。
Dzmitry Bahdanau[4]将[1]中的decoder的
c
c
c替换为了
c
i
c_i
ci,即不同时刻i的输出概率的计算不再使用相同的
c
c
c。
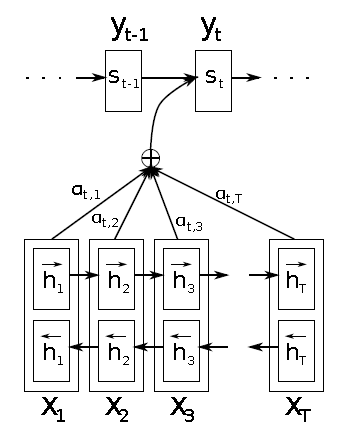
其中
c
i
c_i
ci的计算依赖于输入的annotations
(
h
1
,
.
.
.
,
h
T
x
)
(h_1, ..., h_{T_x})
(h1,...,hTx),计算公式如下:
c
i
=
∑
j
=
1
T
x
α
i
j
h
j
c_i=\sum_{j=1}^{T_x}\alpha_{ij}h_j
ci=j=1∑Txαijhj
α
i
j
=
e
x
p
(
e
i
j
)
∑
k
=
1
T
x
e
x
p
(
e
i
k
)
\alpha_{ij}=\frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})}
αij=∑k=1Txexp(eik)exp(eij)
e
i
j
=
a
(
s
i
−
1
,
h
j
)
e_{ij}=a(s_{i-1}, h_j)
eij=a(si−1,hj)
其中
a
(
)
a()
a()使用前向神经网络来表示,和encoder-decoder一起训练,也就是在学习translate的同时还需要学习alignment。
α
i
j
\alpha_{ij}
αij表示输出
y
i
y_i
yi对齐到
x
j
x_j
xj的概率,相当于引入了attention的机制,这在一定程度上减轻了encoder的压力,因为之前encoder需要把所有的输入信息映射到一个固定的向量
c
c
c。
Speech Application
phoneme recognition
2014年.Jan Chorowski[5]将encoder-decoder和attention的网络结构应用到语音中的phoneme识别上面。[3]中的attention在权重分布的时候有可能将较大的权重分配到比较远的输入上面,从而达到long-distance word reordering的效果。文中对attention的分布进行了一定的限制,保证输出附近对应的输入的权重比较大,而且权重的分布随着时间往后移动,即单调性。主要有两点改进:
1.修改attention的计算方法,引入
d
(
)
d()
d()来学习权重的向后移动过程
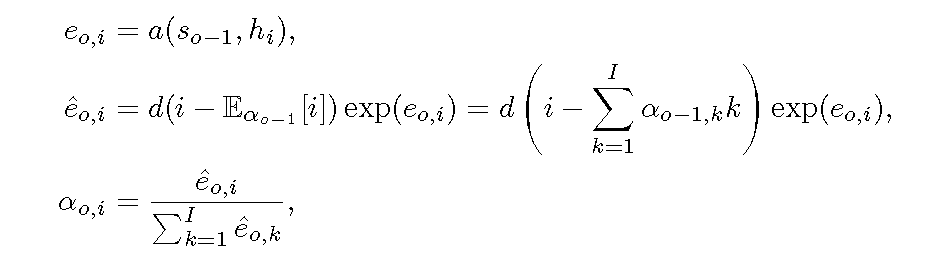
2.在loss里面增加惩罚项,We penalize any alignment that maps to inputs which were already considered for output emission
2015年.Jan Chorowski[6]在[5]的基础上进行了改进,在使用上一时刻的alignment的时候直接进行Convolution,修改softmax函数突出重点帧的影响,同时不再使用整个序列的 h h h,只采用特定窗口范围内的 h h h。
speech recognition
[5][6]主要将attention和encoder-decoder的网络用在了phoneme的识别上面,2016年Dzmitry Bahdanau[7]进一步将其应用到LVCSR,输出为character,然后结合语言模型进行解码。文中提出了pooling的方法为了解决输入长度过长带来的计算复杂的问题。
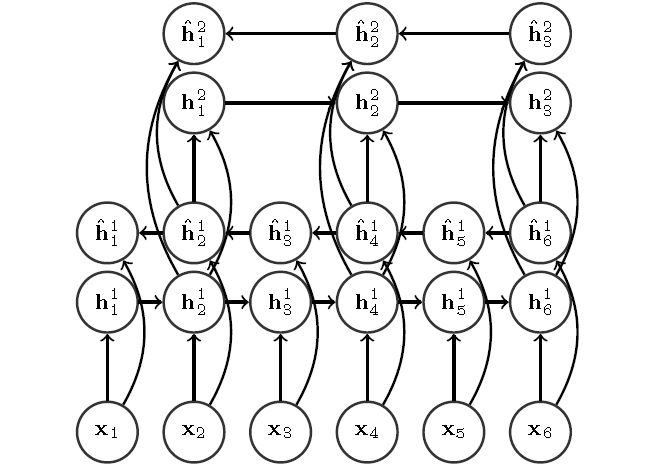
在不使用外部语言模型的情况下,比ctc方法性能有较大提升,主要得益于encoder-decoder的框架隐式的学习character之间的关系,而CTC当前时刻的输出跟上一时刻的输出是独立的,因此无法刻画输出character之间的关系
[8]和[7]类似,也是输出到character,使用了pooling的思想使用了pyramid BLSTM网络结构来来解决输入序列过长训练困难的问题。
Reference
[1]. Cho, K., van Merrienboer, B., Gulcehre, C., Bougares, F., Schwenk, H., and Bengio, Y. (2014a). Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014).
[2].Sutskever, I., Vinyals, O., and Le, Q. (2014). Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems (NIPS 2014).
[3].Graves, A. (2013). Generating sequences with recurrent neural networks. arXiv:1308.0850 [cs].
[4].D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” in ICLR, 2015.
[5].Jan Chorowski, Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. End-to-end continuous speech recognition using attention-based recurrent NN: First results. arXiv:1412.1602 [cs, stat], December 2014.
[6].Chorowski, Jan K, Bahdanau, Dzmitry, Serdyuk, Dmitriy, Cho, Kyunghyun, and Bengio, Yoshua. Attention-based models for speech recognition. In Advances in Neural Information Processing Systems, pp. 577–585, 2015.
[7].D. Bahdanau, J. Chorowski, D. Serdyuk, P. Brakel, and Y. Bengio. End-to-end attention-based large vocabulary speech recognition. In 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 4945–4949, March 2016. doi: 10.1109/ICASSP.2016.7472618.
[8].William Chan, Navdeep Jaitly, Quoc V Le, and Oriol Vinyals. Listen, attend and spell. arXiv preprint arXiv:1508.01211, 2015.
后面的技术分享转移到微信公众号上面更新了,【欢迎扫码关注交流】
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









