







前言
search 我们经常使用,默认一次返回10条数据,并且可以通过 from 和 size 参数修改返回条数并执行分页操作。但是有时需要返回大量数据,就必须通过scan和scroll实现。两者一起使用来从Elasticsearch里高效地取回巨大数量的结果而不需要付出深分页的代价。
详情参考:https://es.xiaoleilu.com/060_Distributed_Search/20_Scan_and_scroll.html
与上文链接不同的是,本文是关于python实现的介绍和描述。
数据说明
索引hz中一共29999条数据,且内容如下。批量导入数据代码可见:
http://blog.csdn.net/xsdxs/article/details/72849796
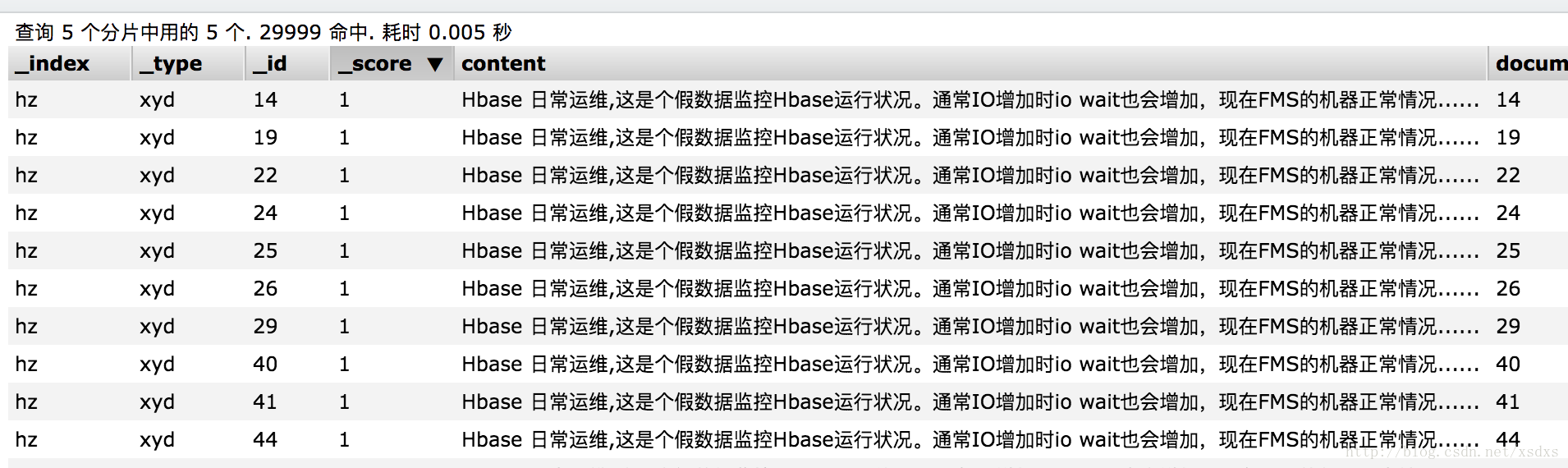
代码示例
ES客户端代码:
# -*- coding: utf-8 -*-
import elasticsearch
ES_SERVERS = [{
'host': 'localhost',
'port': 9200
}]
es_client = elasticsearch.Elasticsearch(
hosts=ES_SERVERS
)search接口搜索代码:
# -*- coding: utf-8 -*-
from es_client import es_client
def search(search_offset, search_size):
es_search_options = set_search_optional()
es_result = get_search_result(es_search_options, search_offset, search_size)
final_result = get_result_list(es_result)
return final_result
def get_result_list(es_result):
final_result = []
result_items = es_result['hits']['hits']
for item in result_items:
final_result.append(item['_source'])
return final_result
def get_search_result(es_search_options, search_offset, search_size, index='hz', doc_type='xyd'):
es_result = es_client.search(
index=index,
doc_type=doc_type,
body=es_search_options,
from_=search_offset,
size=search_size
)
return es_result
def set_search_optional():
# 检索选项
es_search_options = {
"query": {
"match_all": {}
}
}
return es_search_options
if __name__ == '__main__':
final_results = search(0, 1000)
print len(final_results)这样一切貌似ok,正常输出1000,但是现在改下需求,想搜索其中20000条数据。
if __name__ == '__main__':
final_results = search(0, 20000)输出如下错误:
elasticsearch.exceptions.TransportError: TransportError(500, u’search_phase_execution_exception’, u’Result window is too large, from + size must be less than or equal to: [10000] but was [20000]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level parameter.’)
说明:search接口最多返回1w条数据。所以这里会报错。
不废话,基于scan和scroll实现,直接给代码如下:
# -*- coding: utf-8 -*-
from es_client import es_client
from elasticsearch import helpers
def search():
es_search_options = set_search_optional()
es_result = get_search_result(es_search_options)
final_result = get_result_list(es_result)
return final_result
def get_result_list(es_result):
final_result = []
for item in es_result:
final_result.append(item['_source'])
return final_result
def get_search_result(es_search_options, scroll='5m', index='hz', doc_type='xyd', timeout="1m"):
es_result = helpers.scan(
client=es_client,
query=es_search_options,
scroll=scroll,
index=index,
doc_type=doc_type,
timeout=timeout
)
return es_result
def set_search_optional():
# 检索选项
es_search_options = {
"query": {
"match_all": {}
}
}
return es_search_options
if __name__ == '__main__':
final_results = search()
print len(final_results)输出如下:

把29999条数据全部取出来了。















 2183
2183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









