







PDFMiner介绍
PDFMiner是一个可以从PDF文档中提取信息的工具。与其他PDF相关的工具不同,它注重的完全是获取和分析文本数据。-
PDFMiner允许你获取某一页中文本的准确位置和一些诸如字体、行数的信息。它包括一个PDF转换器,可以把PDF文件转换成HTML等格式。它还有一个扩展的PDF解析器,可以用于除文本分析以外的其他用途。
PDFMiner内置两个好用的工具:pdf2txt.py和dumppdf.py
pdf2txt.py从PDF文件中提取所有文本内容。但不能识别画成图片的文本,这需要特征识别。对于加密的PDF你需要提供一个密码才能解析,对于没有提取权限的PDF文档你得不到任何文本。
dumppdf.py把PDF文件内容变成pseudo-XML格式。这个程序主要用于debug,但是它也可能用于提取一些有意义的内容(比如图片)。
pdfminer 安装
第一种安装:
- 上pdfminer的主页,将压缩包下载下来,然后解压到一定的文件中;
http://www.unixuser.org/~euske/python/pdfminer/index.html 打开cmd命令;
使用cd命令,设置为setup.py的当前目录下
设置目录完毕后,然后输入setup.py install 注意install是一个重要的参数,不可以缺失;另外如果直接使用pyhton解释器打开setup.py,然后直接运行的话,是会出问题的,所以必须通过命令行的方式进行。
第二种安装:
如果你的Python有安装pip模块,就可以通过命令“python pip install pdfminer”,自动安装pdfminer。
验证是否安装成功
将当前目录设置为tools文件夹下,里面有一个pdf2txt.py文件
在samples的文件下面有一个simple1.pdf的文件,将其拷贝到tools文件夹下,
在命令行中输入pdf2txt.py simple1.pdf,然后如果看到成功将pdf文件中的内容输出了就说明安装成功了。
pdfminer 的使用
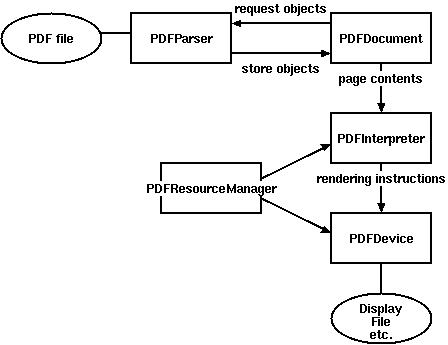
解析pdf文件用到的类:
- PDFParser:从一个文件中获取数据
- PDFDocument:保存获取的数据,和PDFParser是相互关联的
- PDFPageInterpreter处理页面内容
- PDFDevice将其翻译成你需要的格式
- PDFResourceManager用于存储共享资源,如字体或图像。
PDFMiner的类之间的关系图:
Layout布局分析返回的PDF文档中的每个页面LTPage对象。这个对象和页内包含的子对象,形成一个树结构。如图所示:
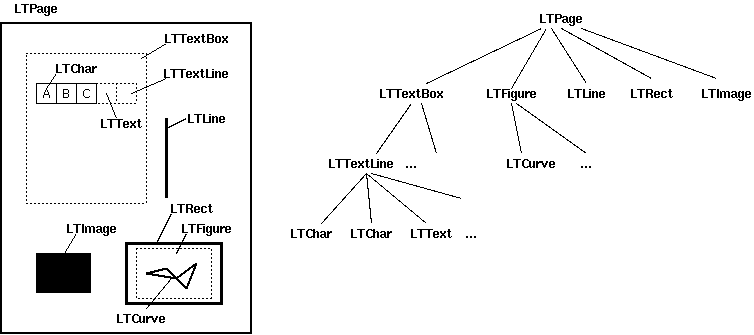
LTPage :表示整个页。可能会含有LTTextBox,LTFigure,LTImage,LTRect,LTCurve和LTLine子对象。
LTTextBox:表示一组文本块可能包含在一个矩形区域。注意此box是由几何分析中创建,并且不一定表示该文本的一个逻辑边界。它包含LTTextLine对象的列表。使用 get_text()方法返回文本内容。
LTTextLine :包含表示单个文本行LTChar对象的列表。字符对齐要么水平或垂直,取决于文本的写入模式。使用get_text()方法返回文本内容。
LTAnno:在文本中字母实际上被表示为Unicode字符串。需要注意的是,虽然一个LTChar对象具有实际边界,LTAnno对象没有,因为这些是“虚拟”的字符,根据两个字符间的关系(例如,一个空格)由布局分析后插入。
LTImage:表示一个图像对象。嵌入式图像可以是JPEG或其它格式,但是目前PDFMiner没有放置太多精力在图形对象。
LTLine:代表一条直线。可用于分离文本或附图。
LTRect:表示矩形。可用于框架的另一图片或数字。
LTCurve:表示一个通用的Bezier曲线
(1)获取PDF文档目录(纲要)
#!/usr/bin/python
#-*- coding: utf-8 -*-
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
#获得目录(纲要)
# 打开一个pdf文件
fp = open(u'F:\\pdf\\2013\\000608_阳光股份_2013年年度报告(更新后)_1.pdf', 'rb')
parser = PDFParser(fp)
document = PDFDocument(parser)
# .获得文档的目录(纲要)
outlines = document.get_outlines()
for (level,title,dest,a,se) in outlines:
print level, title(2)读取pdf文本内容
下面我们利用pdfminer读取一个pdf文档中的文本内容:
#!/usr/bin/python
#-*- coding: utf-8 -*-
from pdfminer.converter import PDFPageAggregator
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.layout import *
import re
#打开一个pdf文件
fp = open(u'F:\\pdf\\2013\\000001_平安银行_2013年年度报告_2562.pdf', 'rb')
#创建一个PDF文档解析器对象
parser = PDFParser(fp)
#创建一个PDF文档对象存储文档结构
#提供密码初始化,没有就不用传该参数
#document = PDFDocument(parser, password)
document = PDFDocument(parser)
#检查文件是否允许文本提取
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
#创建一个PDF资源管理器对象来存储共享资源
#caching = False不缓存
rsrcmgr = PDFResourceManager(caching = False)
# 创建一个PDF设备对象
laparams = LAParams()
# 创建一个PDF页面聚合对象
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
#创建一个PDF解析器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
#处理文档当中的每个页面
# doc.get_pages() 获取page列表
#for i, page in enumerate(document.get_pages()):
#PDFPage.create_pages(document) 获取page列表的另一种方式
replace=re.compile(r'\s+');
# 循环遍历列表,每次处理一个page的内容
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout=device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象
# 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等
for x in layout:
#如果x是水平文本对象的话
if(isinstance(x,LTTextBoxHorizontal)):
text=re.sub(replace,'',x.get_text())
if len(text)!=0:
print text(3)保存pdf文本内容
如果你想要把pdf文档文本保存为txt的话,可以参考下面的程序:
#!/usr/bin/python
#-*- coding: utf-8 -*-
import os
import re
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
#将一个pdf转换成txt
def pdfTotxt(filepath,outpath):
try:
fp = file(filepath, 'rb')
outfp=file(outpath,'w')
#创建一个PDF资源管理器对象来存储共享资源
#caching = False不缓存
rsrcmgr = PDFResourceManager(caching = False)
# 创建一个PDF设备对象
laparams = LAParams()
device = TextConverter(rsrcmgr, outfp, codec='utf-8', laparams=laparams,imagewriter=None)
#创建一个PDF解析器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
for page in PDFPage.get_pages(fp, pagenos = set(),maxpages=0,
password='',caching=False, check_extractable=True):
page.rotate = page.rotate % 360
interpreter.process_page(page)
#关闭输入流
fp.close()
#关闭输出流
device.close()
outfp.flush()
outfp.close()
except Exception, e:
print "Exception:%s",e
#pdfTotxt(u'F:\\pdf\\2013\\000001_平安银行_2013年年度报告_2562.pdf',u'test.txt')
#一个文件夹下的所有pdf文档转换成txt
def pdfTotxt(fileDir):
files=os.listdir(fileDir)
tarDir=fileDir+'txt'
if not os.path.exists(tarDir):
os.mkdir(tarDir)
replace=re.compile(r'\.pdf',re.I)
for file in files:
filePath=fileDir+'\\'+file
outPath=tarDir+'\\'+re.sub(replace,'',file)+'.txt'
pdfTotxt(filePath,outPath)
print "Saved "+outPath
pdfTotxt(u'F:\\pdf\\2013')














 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









