










Gearman工作流程细解
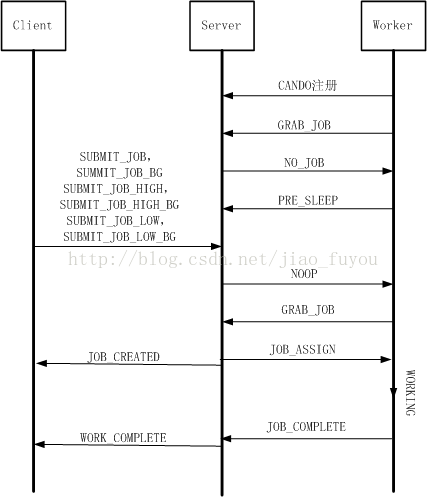
- worker向Gearman Server注册自身可以执行的功能
- worker尝试获取一个任务
- server通告worker暂无任务
- worker通告server:“我先睡会,有活干时再叫醒我”
- client向server发起任务请求
- server唤醒可以完成这项工作的worker(可能会唤醒多个woker)
- worker向server发起“饥饿”请求,尝试获得一个任务
- server选定一个worker,将该任务分配下去
- 通告client:“我安排别人处理你的请求了,耐心等待吧”
- worker辛苦工作一段时间后,向server通告“干完了”
- server将结果反馈给用户
值得说明的几点
1. 任务分类:
按优先级分:普通(SUBMIT_JOB),高(SUBMIT_JOB_HIGH),低(SUBMIT_JOB_LOW)
按执行方式分:普通(_JOB_HIGH,_JOB_LOW),后台(_JOB_HIGH_BG,_JOB_LOW_BG)
最大区别在于,client可以跟踪前台任务的工作状态,而不能跟踪BG任务
2. 任务工作状态的通告(worker-->server-->client):
WORK_DATA
WORK_WARNING
WORK_STATUS
对于长任务,worker应该每隔一段时间通告任务状态
WORK_COMPLETE
WORK_FAIL
WORK_EXCEPTION
3. Server监控
该功能详见《Gearman使用》
问题分析与研究
Job Server 的单点问题
实际上 Job Server 是存在单点问题的,我们只能通过增加冗余 Job Server 的方式来解决这个问题。
我们可以通过配置域名、多个服务器配置列表等方法,在遇到其中一个 Job Server 失败时,将 Client 的请求转向另外的 Job Server。
这种情况下,Job Server 中原来存在的任务会发生丢失,除非使用了数据库或其他类似的持久化方法。
如果遇到正在连接的那个故障,由client、worker切换到好用的gearmand服务器,这样来完成high-avliable。
可以看出这里实现的并不完善,需要客户端程序自己判断,而且也可以看出并不支持几个Job Server的负载均衡调用。
Job Server 重启
Job Server重启后,worker会自动重新注册。通过 gearmand -vvvvvvv 分析发现,如果 gearmand 关闭并重新启动后,原来的 worker 会马上与 Job Server 建立连接,并询问是否有任务。
但是客户端client程序是不会自动重连的,这个要靠客户端程序中来判断重连。
使用持久队列避免任务的丢失
因为 Gearmand 的队列是放在内存中的,所以宕机或重启事件会导致队列的丢失。为了避免这种情况,可以使用持久队列,将队列存储在一个相对中立的位置。注意,持久队列只对于后台任务有效。
Gearman Worker 的无缝重启
我在实现Worker的过程中,采用了PHP脚本,脚本调用外部的配置文件。如果外部的配置文件修改后,需要重新启动脚本才能够使配置文件中修改的变量生效,所以想要坐到无缝的重启。即脚本Stop、Start的过程不会影响正在进行的业务。
对于无缝重启的问题,我总结了如下几个思路进行处理,解决的方法:
1、每次修改完代码后,Worker需要手工重启(先杀死然后启动)。
2、在Worker中设置,单次任务循环完成后,就对Worker进行重启。
3、在Worker中添加一个退出函数,如果需要Worker退出的时候,在Client端发送一个优先级比较高的退出调用。
4、在Worker中检查文件是否发生变化,如果发生了变化,退出并重启自身。
5、为Worker编写信号控制,接受重启指令,类似于 http restart graceful 指令
多台Job Server客户端重连接问题
Gearman在多个Job Server服务器之间并不通讯,而是运行多个Job Server服务器,通过client、worker连接多个服务器。
客户端连接Job Server时,通过addJobServer或addJobServers的方式,为客户端增加多台Job Server服务器,客户端程序初始执行时不会真正的去连接所有的Job Server,只是打开连接符放到一个服务器连接列表中,当run_task时,才会真正的去连接服务器,首先向最后一台服务器发送,如果失败,客户端程序针对这笔当前的task不会自动切到另一台服务器,下一个task连接时发现这台服务器有问题就会自动切换到下个服务器,这样也是对的,因为当前这笔task的状态是不确定的,也许worker执行了返回没收到。这种情况只能是客户端程序自己判断。
为验证这种情况,自己试验一下:
在一台机上起两个gearmand(端口分别为4730和4830),在客户端把这2个gearmand都加到GearmanClient中,通过addJobServer或addJobServers的方式。
正常的,GearmanClient会将任务发送到最后添加的JobServer(4830),把job发送过去。
kill掉4830这个进程,log中报:
PHP Warning: GearmanClient::do(): gearman_connection_read:lost connection to server
当执行下一个任务时然后自动的采用第二个JobServer,任务发送到第二个JobServer上了。
但是如果一个连接已经存在,要重复这个连接的使用,在发送Job的时候,不断的报错,不会自动切换到另一个好的JobServer上。
还有一个问题就是,这时如果前面出错那台机器又恢复使用了,客户端程序可以继续向这台机器发task,但是首次的发送会收不到应答直到超时,然后下一笔就正常了,原因需要进一步验证。
这种情况下客户端无法知道这笔task有没有被处理,这在业务上客户端必须加判断,不然一个任何有可能会被执行多次。
对background_job的异步处理的返回
待完善。。。
Gearman 性能调优
线程模型
在大规模使用的时候,需要针对应用类型进行参数设置,以使Gearman的性能达到最优,这首先应该了解Gearman的线程模型。
为确保具备对海量任务调度的支持能力,Gearman毫无悬念的选择libevent作为网络操作支撑库。因此Gearman的服务器Gearmand提供了三类线程角色:
端口监听和管理线程,接受新连接请求并将之交给IO线程,1个 IO线程,完成实际的任务处理,包括命令解析,队列操作等,n个 处理线程,完成内部数据结构的管理,无系统调用尽可能简单,1个
其中第1, 3种线程对全局处理性能没有直接影响,虽然处理线程有可能成为瓶颈,但他的工作足够简单消耗可忽略不计,因此我们的性能调优主要目标是在IO线程的数量。
对每个IO线程来说,它都会有一个libevent的实例;所有Gearman的操作会以异步任务方式提交到处理线程,并由IO线程获取完成实际操作,因此IO线程的数量是与可并行处理任务数成正比。Gearmand 提供 -t 参数调整总IO线程数,需要使用 libevent 1.4 以上版本提供多线程支持。
进程句柄数
另外一个影响大规模部署的是进程句柄数,Gearman会为每一个注册的Worker分配一个fd(文件描述符),而这个fd的总数是受用户限制的,可以使用 ulimit -n 命令查看当前限制
flier@debian:~$ ulimit -n
1024
flier@debian:~$ ulimit -HSn 4096 // 设置进程句柄数的最大软硬限制
4096
也就是说gearman缺省配置下,最多允许同时有小于1024个worker注册上来,fd用完之后的Worker和Client会出现连接超时或无响应等异常情况。因此,发生类似情况时,我们应首先检查 /proc/[PID]/fd/ 目录下的数量,是否已经超过 ulimit -n 的限制,并根据需要进行调整。而全系统的打开文件设置,可以参考 /proc/sys/fs/file-max 文件,并通过 sysctl -w fs.file-max=[NUM] 进行修改。
flier@debian:~$ cat /proc/sys/fs/file-max
24372
flier@debian:~# sysctl -w fs.file-max=100000
100000
Gearmand 本身也提供了调整句柄数量限制的功能,启动时则可以通过 –file-descriptors 参数指定,但非特权进程不能设置超过soft limit的数额。
-f [ --file-descriptors ] arg
Number of file descriptors to allow for the process (total connections will be slightly less). Default is max allowed for user.
轮询调度
此外,Gearmand 还提供了一些增强任务调度公平性的参数,例如 0.13 里面新增的 round-robin 模式,允许将任务公平的调度到多个 Worker,而不是用缺省按 Worker 注册函数的顺序进行调度,避免工作过于集中在少数设备上。
-R, –round-robin Assign work in round-robin order per
workerconnection. The default is to assign work in
the order of functions added by the worker.
Gearmand 内部通过一个 Worker 队列,在 RR 模式下动态调整 Worker 的调度次序。
受限唤醒
而通过 –worker-wakeup 参数,则可以指定收到任务时,需要唤醒多少个 Worker 进行处理,避免在 Worker 数量非常大时,发送大量不必要的 NOOP 报文,试图唤醒所有的 Worker。
-w, –worker-wakeup=WORKERS Number of workers to wakeup for each job received.
The default is to wakeup all available workers.
根据 Gearman 协议设计, Worker 如果发现队列中没有任务需要处理,是可以通过发送 PRE_SLEEP 命令给服务器,告知说自己将进入睡眠状态。在这个状态下,Worker 不会再去主动抓取任务,只有服务器发送 NOOP 命令唤醒后,才会恢复正常的任务抓取和处理流程。因此 Gearmand 在收到任务时,会去尝试唤醒足够的 Worker 来抓取任务;此时如果 Worker 的总数超过可能的任务数,则有可能产生惊群效应。
除此之外,针对应用特点合理使用持久化队列,在大并发任务量的情况下对性能也会有直接影响。
归根结底,需要根据自己的应用场景,合理设计一些测试用例和自动化脚本,通过实际的运行状态进行参数调整。















 1903
1903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









