







类别:监督学习---分类
原理:对未知类别属性的数据集中的每个点依次执行以下操作
def classify0(inX, dataSet, labels, k):
#1)计算已知类别数据集中的点与当前点之间的距离
dataSetSize=dataSet.shape[0];
testData=tile(inX,[dataSetSize,1])
diff=(testData-dataSet)**2
diffSum=diff.sum(axis=1)
distance=diffSum**0.5
#2)按照距离递增次序排列
sortDis=distance.argsort()
#3)选取与当前点距离最小的k个点 4)确定前k个点所在类别的出现频率
nearestK={}
for i in range(k):
item=labels[sortDis[i]]
nearestK[item]=nearestK.get(item,0)+1
#5)返回前k个点出现频率最高的类别作为当前点的预测分类
sortNearestK=sorted(nearestK.items(),key=itemgetter(1),reverse=True)
return sortNearestK[0][0]推荐一篇总结KNN算法的文章,很详细。
http://my.oschina.net/u/1412321/blog/194174
以下是我做的精简笔记:
1.KNN思想:寻找邻居。If it walks like a duck, quacks like a duck, then it is probably a duck.
2.如何度量邻居之间的相似度:
1)欧氏距离
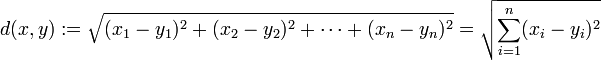
2)曼哈顿距离
(1)二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离
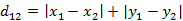
(2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的曼哈顿距离
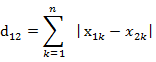
3)切比雪夫距离
(i)二维平面两点a(x1,y1)与b(x2,y2)间的切比雪夫距离
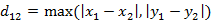
(ii)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的切比雪夫距离
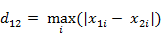
这个公式的另一种等价形式是
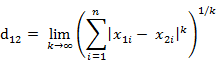
4)Minkowski距离
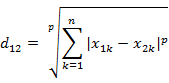
5)标准化距离(s为各维度的标准差)
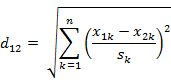 ,
,
3. 到底要找多少邻居(k值的选择)
其实完全靠经验或者交叉验证,就是使K值初始取一个比较小的数值,之后不段来调整K值的大小来时的分类最优,但是这个K值也只是对这个样本集是最优的。
4.怎么确定测试点属于邻居中的哪一类
1)一人一票制,少数服从多数的原则 (k个邻居中人数最多的类别)
2)为每个邻居赋予一定的投票权重,通过它们与测试对象距离的远近来相应的分配投票的权重,最简单的就是取两者距离之间的倒数1/d(y,z)(或1-归一化后的距离),距离越小,越相似,权重越大,将权重累加,最后选择累加值最高类别属性作为该待测样本点的类别。(k个邻居中和测试对象离的近的数量少,而离得远的数量多时,方法1可能就要出错)
5.错误概率

6.缺点
1)需要存储全部训练样本,以及繁重的距离计算量 。
改进
i)对样本集进行组织与整理,分群分层,尽可能将计算压缩到在接近测试样本邻域的小范围内,避免盲目地与训练样本集中每个样本进行距离计算。
eg. KD树 http://www.cnblogs.com/v-July-v/archive/2012/11/20/3125419.html
ii)在原有样本集中挑选出对分类计算有效的样说本,使样本总数合理地减少,以同时达到既减少计算量,又减少存储量的双重效果。
eg.压缩邻近法
2)无法给出数据的内在含义
实例操作:改进约会网站的配对效果
#dating_kNN.py
from numpy import *
from operator import itemgetter
import matplotlib
import matplotlib.pyplot as plt
#文本文件中解析数据
def file2matrix(filename,n):
f=open(filename)
lineOFile=f.readlines()
numOLine=len(lineOFile)
returnMat=zeros((numOLine,n-1))#特征矩阵
classLabelVec=[]
index=0
for line in lineOFile:
line=line.strip()
listFromLine=line.split('\t')
returnMat[index,:]=listFromLine[0:n-1]
classLabelVec.append(listFromLine[-1])
index+=1
return returnMat, classLabelVec
#使用Matplotlib创建散点图
def plotFig(dataMat,dataLabels):
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.scatter(dataMat[:,1],dataMat[:,2])
plt.show()
#归一化数值
def autoNorm(dataMat):
dataMin=dataMat.min(0)
dataMax=dataMat.max(0)
dataRange=dataMax-dataMin
n=dataMat.shape[0]
normData=dataMat-tile(dataMin,(n,1))
normData=normData/tile(dataRange,(n,1))
return normData,dataMin,dataRange
#kNN算法
def classify0(inX, dataSet, labels, k):
#1)计算已知类别数据集中的点与当前点之间的距离
dataSetSize=dataSet.shape[0];
testData=tile(inX,[dataSetSize,1])
diff=(testData-dataSet)**2
diffSum=diff.sum(axis=1)
distance=diffSum**0.5
#2)按照距离递增次序排列
sortDis=distance.argsort()
#3)选取与当前点距离最小的k个点 4)确定前k个点所在类别的出现频率
nearestK={}
for i in range(k):
item=labels[sortDis[i]]
nearestK[item]=nearestK.get(item,0)+1
#5)返回前k个点出现频率最高的类别作为当前点的预测分类
sortNearestK=sorted(nearestK.items(),key=itemgetter(1),reverse=True)
return sortNearestK[0][0]
#测试
def classTest():
ratio=0.1
dataMat,dataLabels=file2matrix\
('G:\\程序\\python\\1.kNN\\datingTestSet2.txt',4)
normMat,minVals,ranges=autoNorm(dataMat)
n=normMat.shape[0]
numOTest=int(n*ratio)
error=0.0
for i in range(numOTest):
classResult=classify0(normMat[i,:], normMat[numOTest:n,:],\
dataLabels[numOTest:n], 4)
print ('the predict result : {0}, and the real result: {1}'\
.format(classResult,dataLabels[i]))
if(classResult!=dataLabels[i]):error+=1.0
print ('the total error rate is: {0}'.format(error/float(numOTest)))
#使用算法
def classifyPerson():
resultList=['not at all', 'in small doses', 'in large doses']
percentT=float(input('percent of time spent playing video games?'))
ffMiles=float(input('frequent flier miles earned per year?'))
iceCream=float(input('liters of iceacream consumed per year?'))
dataMat,dataLabels=file2matrix\
('G:\\程序\\python\\1.kNN\\datingTestSet2.txt',4)
normMat,minVals,ranges=autoNorm(dataMat)
inArr=[ffMiles,iceCream,percentT]
result=classify0((inArr-minVals)/ranges, dataMat,\
dataLabels, 4)
print (result)
if __name__=='__main__':
import dating_kNN
dating_kNN.classifyPerson()















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









