




 本文介绍了一种名为网络瘦身的CNN学习方案,通过在训练过程中引入信道级稀疏性,实现模型尺寸减小、运行内存降低及运算次数减少,而不影响精度。方法通过对BN层的γ系数施加L1正则化,识别并裁剪不重要的通道,适用于多种现代CNN架构。
本文介绍了一种名为网络瘦身的CNN学习方案,通过在训练过程中引入信道级稀疏性,实现模型尺寸减小、运行内存降低及运算次数减少,而不影响精度。方法通过对BN层的γ系数施加L1正则化,识别并裁剪不重要的通道,适用于多种现代CNN架构。
| Title | Venue | Type | Code |
|---|---|---|---|
| Learning Efficient Convolutional Networks Through Network Slimming | ICCV | F | pytorch |
Abstract
,我们提出一种新颖的CNNs学习方案,在不影响精度下:
- 同时减小模型尺寸;
- 减少运行时内存占用;
- 减少运算次数
这是通过以一种简单而有效的方式在网络中强制信道级稀疏来实现的。所提出的方法直接适用于现代的CNN体系结构,将训练过程的开销降至最低,并且对于生成的模型不需要特殊的软件/硬件加速器。我们称这种方法为网络瘦身,它以大型网络和大型网络为输入模型,但是在训练过程中,会自动识别并修剪不重要的渠道,从而产生具有可比精度的精简模型。
思路
- 在训练的过程中,对 Loss 函数加入稀疏诱导项(L1正则化),迫使模型训练的过程中,通道变得稀疏,这种稀疏是通过 BN 层的 γ \gamma γ 系数来实现的。随着训练的进行,BN 层的 γ \gamma γ 系数趋向于0,贡献度小的 γ \gamma γ 系数所对应的 filter 将会被裁剪掉。
一些关键词
- 通道剪枝(卷积核剪枝)
- 通道稀疏
- 全局阈值剪枝
- L1 正则化稀疏诱导
- 通道重要性评估剪枝
- 需要 finetuning
- BN层剪枝
超参数
- 稀疏化。 LOSS 函数稀疏正则项系数 γ \gamma γ
- 剪枝比例。全局剪枝比例超参数。
1 Introduction
目前问题
CNN在实际应用中的部署主要受到以下因素的限制
- 模型的大小
- 运行内存
- 计算操作数
方法操作对象
卷积核
总述
我们的方法在批量归一化(BN)层中对缩放因子施加 L1正则化,因此易于实现而无需对现有CNN架构进行任何更改。 使用 L1 正则化将 BN 缩放因子的值推近零,使我们能够识别无关紧要的通道(或神经元),因为每个缩放因子都对应于特定的卷积通道(或全连接层中的神经元)。
贡献
- 通道级稀疏性在灵活性和易于实现之间提供了很好的折衷。
2 Related Works
-
低阶分解
-
权重量化
这种激进的低位逼近方法通常会带来中等程度的精度损失 -
重量修剪/稀疏。
这些方法只能使用专用的稀疏矩阵运算库和/或硬件来实现加速。 运行时内存的节省也非常有限,因为大多数内存空间都被激活映射(仍然很密集)而不是权重占用了 -
结构化修剪/稀疏化。
3 Algorithm
相关图解
- 图1. 稀疏诱导与裁剪

- 图2. 剪枝流程

算法流程
【v】裁剪流程:
.----------------------------------------------------
1、对 LOSS 函数加入 L1 正则化
.-------------------
2、对没有 BN 层的模型加入BN层,有的则不用
.-------------------
3、稀疏化训练,设定稀疏化超参数
.-------------------
4、裁剪。设定全局裁剪比例超参数
.-------------------
5、剪掉贡献度低的通道,贡献度的高低通过
γ
\gamma
γ 系数来决定。
.-------------------
6、生成新的被裁剪过的模型
.-------------------
7、finetuning 网络
.-------------------
算法的数学实现
优化的 LOSS 函数
L = ∑ ( x , y ) l ( f ( x , W ) , y ) + λ ∑ γ ∈ Γ g ( γ ) L=\sum_{(x, y)} l(f(x, W), y)+\lambda \sum_{\gamma \in \Gamma} g(\gamma) L=(x,y)∑l(f(x,W),y)+λγ∈Γ∑g(γ)
g ( ⋅ ) g(·) g(⋅) 是稀疏性对比例因子的惩罚,而 λ λ λ 平衡了这两项
g ( s ) = ∣ s ∣ g(s)=|s| g(s)=∣s∣
g ( s ) g(s) g(s) 是 L1 正则化,广泛用于实现稀疏性。
- BN层操作
z ^ = z i n − μ B σ B 2 + ϵ ; z out = γ z ^ + β \hat{z}=\frac{z_{i n}-\mu_{\mathcal{B} } } {\sqrt{ {\sigma}_ {\mathcal{B}}^ {2}+\epsilon}} ; \quad z_{\text {out}}=\gamma \hat{z}+\beta z^=σB2+ϵzin−μB;zout=γz^+β
LOSS 的作用就是训练的过程中,迫使每一层的不同通道对应的
γ
\gamma
γ 稀疏化,接近甚至变成了 0
4 Experiments
实验对象
实验数据集
- CIFAR-10
- CIFAR-100
- SVHN
- MNIST
- ImageNet
实验模型
- VGG
- DenseNet
- ResNet
- 3个全连接层网络
实验结果
-
CIFAR-10, CIFAR-100, SVHN
-
VGG
-
DenseNet
-
ResNet

-
ImageNet,MNIST
-
VGG
-
3个全连接层网络
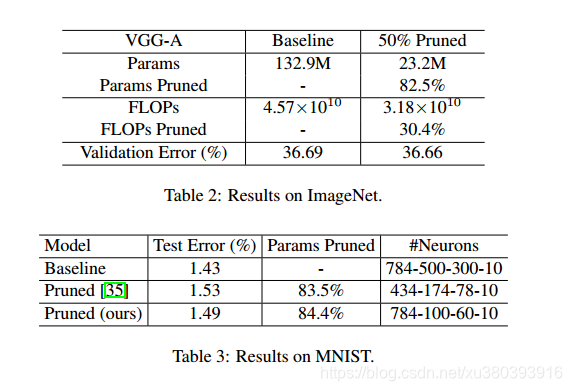
多次剪枝过程
- CIFAR-10,CIFAR-100
- VGGNet
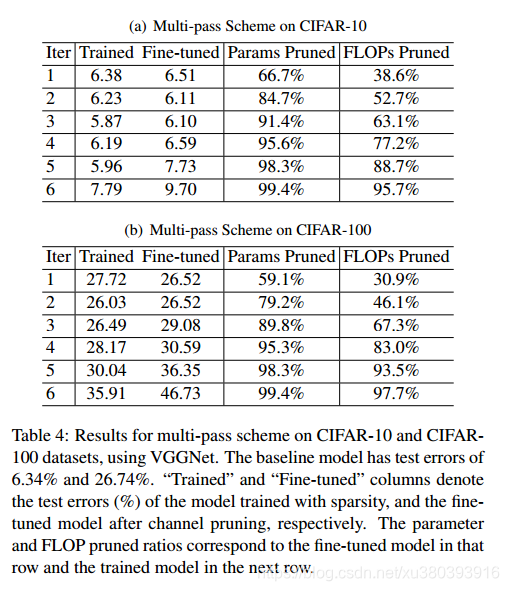
-
VGG 的剪枝细节
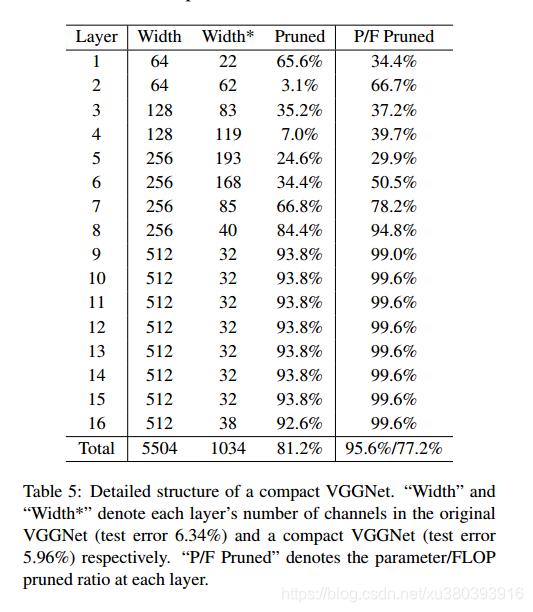
-
其他论文测定结果
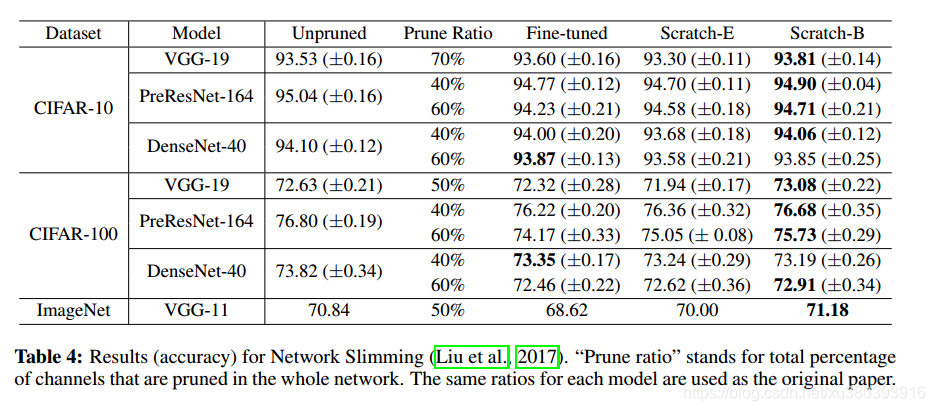
| Title | Venue | Type | Code |
|---|---|---|---|
| Rethinking the Value of Network Pruning | ICLR | F | github(pytorch) |
论文评价
-
优点
算法思路清晰,容易实现,效果好 -
缺点
- 对剪枝的程度没有先验知识的指导。剪枝的效果依靠人工经验,
即试 - 模型各个层的剪枝阈值是相同的,不过在后期的一个实现过程中,可以逐层进行,但是会很繁琐
- 总共 2 个超参数。
- 裁剪粒度过大的时候,可能导致某一层的卷积数量非常少甚至为0,从而该层的输出几乎0,从而失去推理能力。
比如,裁剪比例60%
黄色: 卷积层1(一共5个卷积核)
绿色: 卷积层2(一共5个卷积核)

裁剪结果:
黄色: 卷积层1(剩下1个卷积核)
绿色: 卷积层2(剩下3个卷积核)
其他文献
- 解读文献
模型压缩 | 结构性剪枝Data-Driven Sparse Structure Selection 以及实际剪枝实现流程_网络_HongYuSuiXinLang的博客-CSDN博客
https://blog.csdn.net/HongYuSuiXinLang/article/details/82592585
-
相似文献
[2018ECCV F] Data-Driven Sparse Structure Selection for Deep Neural Networks -
应用项目
【Pruning系列:一】Learning Efficient Convolutional Networks through Network Slimming_网络_鹿鹿的博客-CSDN博客
https://blog.csdn.net/qq_31622015/article/details/103825048?ops_request_misc=&request_id=&biz_id=102&utm_term=Learning%20Efficient%20Convolution&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-3-103825048


















 2029
2029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









