




 本文提出了一种新的文本图像增强方法,通过学习适当的增强来提高文本识别器的性能。这种方法利用代理网络预测移动状态,生成更具挑战性的训练样本,同时通过联合学习将数据增强与网络训练相结合。实验表明,该方法在场景文本和手写文本识别任务上显著提高了识别网络的性能,特别是在小规模训练数据集上。
本文提出了一种新的文本图像增强方法,通过学习适当的增强来提高文本识别器的性能。这种方法利用代理网络预测移动状态,生成更具挑战性的训练样本,同时通过联合学习将数据增强与网络训练相结合。实验表明,该方法在场景文本和手写文本识别任务上显著提高了识别网络的性能,特别是在小规模训练数据集上。
论文翻译-Learn to Augment: Joint Data Augmentation and Network Optimization for Text Recognition
- 原文地址:https://arxiv.org/pdf/2003.06606v1.pdf
- 【推荐】相关阅读资料下载:
链接:https://pan.baidu.com/s/1w6vtq4C8UtATSyoibOWRGA
提取码:2big- 【注】:翻译仅供参考,准确含义和表达参考英文原文
Learn to Augment: Joint Data Augmentation and Network Optimization for Text Recognition
摘要
手写文本和场景文本存在各种形状和扭曲的模式。因此,训练一个强大的识别模型需要大量的数据来尽可能地覆盖多样性。与数据收集和注解相比,数据增强是一种低成本的方式。在本文中,我们提出了一种新的文本图像扩增方法。与传统的增强方法如旋转、缩放和透视变换不同,我们提出的增强方法旨在学习适当和有效的数据增强,这对于训练一个健壮的识别器来说更加有效和具体。通过使用一组定制的靶标点,我们提出的增强方法是灵活和可控的。此外,我们通过联合学习弥补了数据增强和网络优化这两个孤立过程之间的差距。代理网络从识别网络的输出中学习,并控制靶标点,为识别网络产生更合适的训练样本。在各种基准上进行的大量实验,包括常规场景文本、不规则场景文本和手写文本,表明所提出的增强和联合学习方法显著提高了识别网络的性能。一个用于几何增强的通用工具箱已经问世(https://github.com/Canjie-Luo/Text-Image-Augmentation)。
1.绪论
过去十年见证了深度神经网络在计算机视觉界带来的巨大进步[3, 11, 14, 21]。有限的数据不足以训练出一个强大的深度神经网络,因为网络可能会过度适应训练数据,并在测试集上产生糟糕的泛化效果[5]。然而,数据收集和注释需要大量的资源。与单一对象分类任务[21]不同,文本串的注释工作更加艰难,因为在一个文本图像中存在多个字符。这也是为什么大多数先进的场景文本识别方法[23, 28, 38]只使用合成样本[13, 17]进行训练的原因。数据限制也影响了手写文本识别。存在着各种各样的书写方式。收集大规模的有注释的手写文本图像的成本很高,而且不能覆盖所有的多样性[47]。产生手写文本的合成数据也很有挑战性,因为很难模仿各种书写风格。
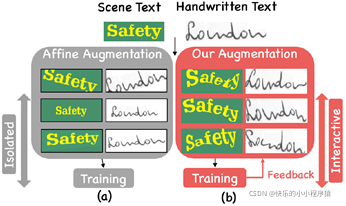
图1.(a) 现有的几何增强,包括旋转、缩放和透视变换;(b) 我们提出的灵活增强。此外,一种联合学习方法将数据增强和网络训练这两个孤立的过程连接起来。
为了获得更多的训练样本,可以对现有数据进行随机增强[9]。具有不同书写方式的手写文本,以及具有不同形状的场景文本,如透视和弯曲的文本,在识别上仍有很大的挑战性[5, 28, 38]。因此,几何增强是获得识别方法鲁棒性的一个重要途径。如图1(a)所示,常见的几何变换是旋转、缩放和透视变换。一个图像中的多个字符被视为一个实体,并对图像进行全局增强。然而,每个字符的多样性应该被考虑在内。给定一个文本图像,扩增的目标是增加文本字符串中每个字符的多样性。因此,现有的增强被限制在过于简单的转换上,这对训练来说是低效的。
此外,由于长尾分布[31],对网络鲁棒性有贡献的有效训练样本可能仍然很少,这也是导致训练效率低下的另一个原因。随机扩增的策略对每个训练样本都是一样的,忽略了样本之间的差异和网络的优化程序。在人工控制的静态分布下,扩增可能会产生许多 "容易 "的样本,而这些样本对训练是无用的。因此,静态分布下的随机扩增很难满足动态优化的要求。同时,在一个数据集上手工设计的最佳增强策略,通常不能像预期的那样转移到另一个数据集。我们的目标是研究一种可学习的增强方法,它可以自动适应其他任务,而不需要任何人工修改。
在本文中,我们提出了一种用于文本识别的新的数据增强方法,该方法是为序列类字符[36]增强而设计的。我们的增强方法着重于图像的空间转换。我们首先在图像上初始化一组基准点,然后移动这些点来生成一个新的图像。移动状态代表着点的移动以创造 "更难 "的训练样本,它从代理网络的预测分布中取样。然后,增强模块将移动状态和图像作为输入,并生成一个新的图像。我们采用基于移动最小二乘法的相似性变换[35]来生成图像。此外,一个随机的移动状态也被送入增强模块,以生成一个随机增强的图像。最后,代理从移动状态中学习,增加识别难度。难度是根据编辑距离的指标来衡量的,这与识别性能高度相关。
总而言之,我们的贡献如下。
- 我们提出了一种针对包含多个字符的文本图像的数据增强方法。据我们所知,这可能是第一个专门为序列类字符设计的增强方法。
- 我们提出了一个共同优化数据增强和识别模型的框架。增强的样本是通过自动学习过程产生的,因此对模型的训练更加有效和有用。所提出的框架是可以端到端训练的,无需任何微调。
- 在包括场景
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









