







在第一章中作者使用的权重初始化方法是将权重以标准正态分布N~(0,1)进行初始化,本章作者介绍使网络更加高效的权重初始化方式。
作者假设网络有1000个输入,其中500个值为0,500个值为1,第一隐藏层的节点未激活输出为,那么其输出实际上就是501个独立正态分布变量之和,其中包括500个w和1个bias。独立的正态分布变量之和仍然是正态分布,则未激活输出仍然满足正态分布N~(0,501),即其方差为501,概率密度峰值为1/sqrt(1002*pi)=0.01782,其概率密度函数图像如下:
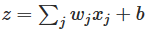
由此图可以看出 z 大概率是一个比较大的值,用作者的原话是:。可以看出这样第一隐藏层的节点的激活后输出大多会极其接近0或1。结点饱和会使得对权重做出微小的改变对整体产生的影响有限,造成学习速度缓慢。
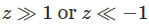
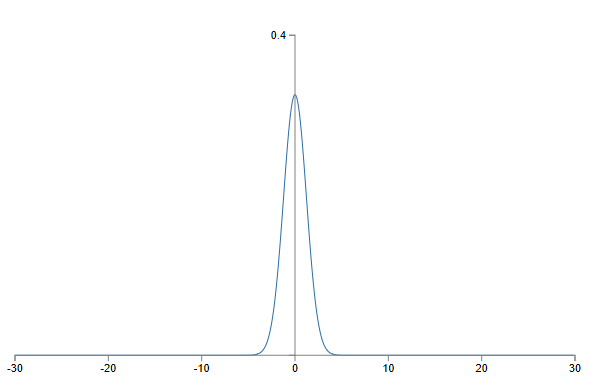
由以上的讨论可以看出只要我们能够使得 z 的概率密度函数图像是一个峰值高的正态分布,例如标准正态分布N~(0,1),那么就可以避免隐藏层结点的饱和。具体的做法就是将具有m个输入的结点的权重按照正态分布N~(0,1/m)来进行初始化,这样求和后的正态分布仍然可以有一个足够陡峭的概率密度函数。例如下图:















 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









