







神经网络Neural Networks
机器学习初学者,原本是写来自己看的,写的比较随意。难免有错误,还请大家批评指正!对其中不清楚的地方可以留言,我会及时更正修改
神经网络模型的输入是特征
(x1,x2,⋯,xn)
,输出是我们的假设函数,在我们的模型中,
x0
总是等于1,被称作偏置单元。这里仍旧使用逻辑函数
11+e−θTx
进行分类,在神经网络中,它常被称作激励函数(sigmoid(logistic) activation function),参数
θ
常被称作权重weight。
直观的,一个简单的神经网络模型可以表示为
第一层通常称作输入层,最后一层称作输出层,给出了假设函数输出的结果。中间层直接被称作隐藏层,称作驱动单元。定义:
a(j)i= 第j层的第i个驱动单元
Θ(j)= 控制第j层到第j+1层映射的权重矩阵
模型表示1
如果中间层只有一层,神经网络模型可以表示为:
每个驱动单元的值通过以下方式获得:
向量化之后可是表示成(当然,还需要增加偏置单元)
在神经网络中,每层都被分配一个权重矩阵 Θ(j) ,假设第 j 层有
模型表示2
我们定义新的变量
z(j)k
作为逻辑回归函数的参数,则前面的例子可是表示为
换句话说,对第 j=2 层的第 k 个节点,变量
设 x=a(1) ,我们可以重写等式为:
Θ(j−1) 的维度为 sj∗(n+1) , sj 为驱动节点的个数。此时,我们可以得到下一层驱动节点的值
在 a(j) 中添加偏置单元,其值为1,要得到最后假设函数,必须先计算另一个 z(j)
最后一个矩阵 Θ(j) 是一个行向量,我们的假设函数输出结果是一个实数,所以有最终结果
多类别分类
为了实现多类别分类,我们让假设函数返回一个向量,其中只有一个元素为1,表示其类别,如
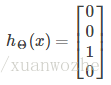
同样的,我们定义输出类集合
y
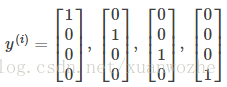
代价函数
首先定义一些要使用的变量:
sl=
第
l
层驱动单元的个数
hΘ(x)k=
假设函数的第k个输出
和逻辑回归的代价函数类似,神经网络的代价函数表示为:
反向传播算法
注:反向传播算法其实就是梯度下降与链式求导法的组合
和梯度下降类似,我们的目标是计算
minΘJ(Θ)
,我们依旧关注
J(Θ)
的偏导数
∂∂Θli,jJ(Θ)
在反向传播算法中,我们计算每个节点的误差
δlj
,表示第
l
层第
得到其他层的
δ
,可用下面的方程式从右向左进行演算
其中的偏导数项也可以写作 g′(z(l))=a(l).∗(1−a(l)) 。因为 g′(z)=g(z)(1−g(z)) 。
则最终 J(Θ) 的偏导数表示为:(其中的证明和计算十分复杂,可以不考虑)
注:这里忽略了正则化, 直观的理解公式就是第l层第i个结点的残差等于第l+1层与其连接的所有结点的权值和残差的加权和再乘以该点对z的导数值。
至此,反相传播算法可以描述为
实际上,上述算法中的 D(l)i,j 就是我们要找的 ∂∂Θli,jJ(Θ) ,即
直观上, δ(l)j 就是 a(l)j 的偏差,可以描述成代价函数的偏导数: δ(l)j=∂∂z(l)jcost(t)
参数展开
在神经网络中,我们需要计算很多参数,如
Θ1,Θ2,Θ3⋯
D1,D2,D3⋯
为了使用”fminnuc”这样的优化函数,这里将参数展开成列向量的形式进行传参
thetaVector = [Theta1(:); Theta2(:); Theta3(:) ]
deltaVector = [D1(:); D2(:); D3(:) ]在函数内部,再将其还原成正确的形式
Theta1 = reshape(thetaVector(1:101), 10, 11)
Theta2 = reshape(thetaVector(102:220), 10, 11)
Theta3 = reshape(thetaVector(221:231), 1, 11)梯度检查Gradient Checking
进行梯度检查可以保证我们的反向传播算法能够像按照我们的意愿进行工作,近似的我们可以将代价函数表示近似为:
∂∂ΘJ(Θ)≈J(Θ+ϵ)−J(Θ−ϵ)2ϵ
对于有多个
Θ
矩阵,代价函数的倒数可以表示为:
∂∂ΘjJ(Θ)≈J(Θ1,...,Θj+ϵ,...,Θn)−J(Θ1,...,Θj−ϵ,...,Θn)2ϵ
通常情况下,
ϵ=10−4
,对应的matlab代码如下:
epsilon = 1e-4;
for i = 1:n,
thetaPlus = theta;
thetaPlus(i) += epsilon;
thetaMinus = theta;
thetaMinus(i) -= epsilon;
gradApprox(i) = (J(thetaPlus) - J(thetaMinus))/(2*epsilon)
end;最后,我们检查 gradApprox≈deltaVector
随机初始化Random Initialization
如果我们将所有的权重初始化为0,当我们进行反向传播计算时,所有的节点都会重复更新到同样的值,因此,对权重进行随记初始化,将其值控制在 [−ϵ,ϵ] 范围内:
%If the dimensions of Theta1 is 10x11, Theta2 is 10x11 and Theta3 is 1x11.
Theta1 = rand(10,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
Theta2 = rand(10,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
Theta3 = rand(1,11) * (2 * INIT_EPSILON) - INIT_EPSILON;总结
默认情况下,如果隐藏层超过一层,则每个隐藏层的单元个数应相同
-训练神经网络-
1. 随机初始化权重
2. 执行正向传播得到
hθ(x(i))
3. 计算代价函数
4. 执行反向传播计算偏导
5. 使用梯度检查确定偏导计算无误,然后关闭梯度检查
6. 使用梯度下降方法或内置优化函数计算权重
执行正项传播算法过程如下:
for i = 1:m,
Perform forward propagation and backpropagation using example (x(i),y(i))
(Get activations a(l) and delta terms d(l) for l = 2,...,L














 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









