






(二)机器学习面临的挑战
1 训练数据集和输入数据集不一致
机器学习适合解决图像识别,语音识别等方面的问题,但它也存在一些不足。训练数据集和输入数据集不同是机器学习面临的一大挑战,深度学习也有同样的问题。例如,使用一个人的手写体字迹作为训练集,让这个模型去识别其他人的手写体,识别成功的概率很小。

所以机器学习能够成功建立合适的模型的一个前提就是尽可能的使用和实际输入数据集相同的训练数据集。
2 过拟合
在训练数据过程中,会出现一种过度拟合的情况,导致模型在实际使用时候鲁棒性变差。
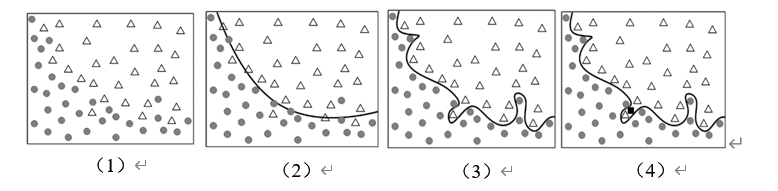
如图2-2所示,(1)代表了两组不同的数据,现在我们要把它们的位置进行分类,图(1)中的数据就是训练数据集,训练的结果是确定了一条区分两组不同点的曲线,如图(2)所示,可以看到在边界附近有一些点的分类不太正确,有的圆点被分到了三角形点的组里。这样的结果不是十分的精确,于是重新调整训练结果,得到图(3)的曲线,对于训练集的数据来说,这一结果非常完美,圆点和三角形点被完全的分开。将这一结果拿到实际的输入数据集中,如图(4)所示,实际输入中增加了正方形点这种分类,图三的曲线将这个正方形点分到了三角形点的类中,但实际上,正方形点的形状更适合于圆点的分类。可以看到训练集得到的完美的结果在实际中使用会产生更大的误差,这就是过度拟合。
实际上,这些边界处的异常值就是噪声,机器学习无法区分这一点,当考虑所有的数据时,得到一个完全符合训练集的完美模型,那么在实际使用中反而可能会产生较大的偏差,即其鲁棒性较低。但问题在于我们也不应该为了减小实际中的误差,而在训练时减小精度,这违背了机器学习的初衷。那么有没有两全其美的方法呢?
3 过拟合的解决方法
克服过拟合有两种典型的方法,正则化与验证。
正则化是一种数值化的方法,建立模型的结构尽量简单。简化后的模型可以避免过拟合,需要付出的代价较小。例如上一节中的点的分类就是一个很好的例子,使用简单的曲线反而会得到较好的效果。具体的细节会在第三章中“成本函数和学习规则”中讨论。
对于上一节中的点的分类问题,因为数据比较简单直观,我们可以画出模型来直观的评价过度拟合的情况,但是对于实际中的许多情形,数据有更高的维度,无法直观的评价过度拟合情况。因此,我们需要通过验证来判断是否处于过拟合。验证法是在使用输入数据集时,保留部分训练数据来监视模型的表现。这部分数据不参与训练,叫做验证集。因为训练数据的建模误差不能反映过拟合,所以使用一部分训练数据来检验模型是否过拟合。当训练好的模型使用之前保留的验证集作为输入时,如果模型表现出来的性能比较低,那么该模型是过拟合的。这时,需要对模型进行调整修改。
引入验证集后,机器学习的训练过程有如下步骤,
1)将训练数据分为两组,一组用来训练,另一组用来验证,根据经验,训练集和验证集的比例是8:2;
2)使用训练集训练数据;
3)使用验证集检验模型的性能,如果对模型的性能比较满意,结束训练,如果性能不好,修改模型后重复步骤2和3。
在验证过程中也可以使用交叉验证,同样是将训练数据分为训练集和验证集,但是不断更改数据集。交叉验证不保留最初划分的集合,而是不断进行新的数据划分。这样做的原因是,在固定验证集验证时,模型表现很好,但此时仍有可能是过拟合的。由于交叉验证保证了验证数据集的随机性,可以更好的检测模型是否过拟合。















 2983
2983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









