







参考:
Microsoft Learning - System Collections
C#高级--常用数据结构、使用C#实现数据结构堆、平衡二叉树、硬核图解面试最怕的红黑树
从B树、B+树、B*树谈到R 树、【数据结构】B树(B-树)和B+树
图论入门及基础概念(图篇)、图论(一)基本概念、C#实现图(Graph)、排序算法——拓扑排序
1、基本概念
数据结构分类:
| 集合 | 无序、一对一 |
| 线性 | 有序、一对一 |
| 树 | 有序、一对多 |
| 图 | 有序、多对多 |
常见的数据结构:
| 数组 | 有序地存储同一类型的多个变量,内存地址也是连续的。 |
| 链表 | 有序地存储同一类型的多个变量,内存地址不必连续。 |
| 队列 | 特殊的线性表,只允许在表的一端进行插入操作,而在另一端进行删除操作。 |
| 栈 | 特殊的线性表,只能在一个表的一个固定端进行数据结点的插入和删除操作。 |
| 树 | 一种递归的数据结构,n个结点的有限集,有一个特定的根结点。 |
| 堆 | 可以看作是一个完全二叉树的数组对象,子节点总不大于/不小于其父节点。 |
| 哈希表 | 又称散列表,对存储的数据进行散列函数计算后分类,便于查找。 |
| 图 | 一系列结点以及连接这些节点的边组成。 |
注:C#运行不安全代码,在项目->XXX属性->生成->勾选“允许使用unsafe{}关键字编译的代码”。在unsafe{ ... }中可是使用指针。

int[] arr = new int[10];
for(int i=0; i<10; i++) { arr[i] = i; }
foreach(int i in arr) {
unsafe {
int* ptr = &i;
IntPtr add = (IntPtr)ptr;
Console.WriteLine(add.ToString("x")); // 打印内存地址
}
}2、数组
优点:连续的内存地址使之可以随机访问。
缺点:插入数据效率低,每次插入需要分配新的内存。
2.1、普通数组、Array
int[] arr = new int[5] {0, 1, 2, 3, 4};
foreach(int i in arr) {
unsafe {
int* ptr = &i;
IntPtr add = (IntPtr)ptr;
Console.WriteLine("{0}: {1}", i, add.ToString("x")); // 打印内存地址
}
}Array类提供了数组的创建、处理、搜索数组并对数组进行排序的方法,是所有数组的基类。
Array实现ICollection、IEnumerable、IList、IStructuralComparable、IStructuralEquatable、ICloneable。
using System.Collections;
Array array = Array.CreateInstance(typeof(int), 3, 4); // 创建一个3行4列int的数组
for (int i = array.GetLowerBound(0); i <= array.GetUpperBound(0); i++) // 下边界索引、上边界索引
{
for (int j = array.GetLowerBound(1); j <= array.GetUpperBound(1); j++)
{
array.SetValue((int)Math.Pow(10, i) + j, i, j);
}
}
Console.WriteLine("Dimension: {0}", array.Rank);
Console.WriteLine("Length: {0}", array.Length);
void Print(Array myArray) { // 按行输出数组
IEnumerator myEnumerator = myArray.GetEnumerator(); // 返回一个枚举
int i = 0;
int cols = myArray.GetLength(myArray.Rank - 1);
while (myEnumerator.MoveNext()) {
if (i < cols) { i++; }
else { Console.WriteLine(); i = 1; }
Console.Write("\t{0}", myEnumerator.Current);
}
Console.WriteLine();
}
Print(array);2.2、ArrayList
优点:大小根据需求会动态增加。
不建议使用 ArrayList 类进行新类的开发,建议改用泛型 List<T> 类。类 ArrayList 旨在保存对象的异类集合,任何对象都是object类型,值类型会进行装箱。
ArrayList实现ICollection、IEnumerable、IList、ICloneable。
using System.Collections;
ArrayList arrayList = new ArrayList(); // 实例化
for(int i = 0; i < 5; i++) { arrayList.Add(i); }
Console.Write("长度:{0}\t容量: {1}\t", arrayList.Count, arrayList.Capacity);
void Print(IEnumerable arrList)
{
foreach (object obj in arrList)
{
Console.Write("{0} ", obj);
}
}
Print(arrayList);2.3、List<T>
是类 ArrayList 的泛型等效项,可通过索引访问对象的强类型列表,提供对列表进行搜索、排序和操作的方法。List<T>在大多数情况下性能更好,并且类型安全。但是,如果值类型用于类型 T,则需要考虑实现和装箱问题。
实现ICollection<T>、IEnumerable<T>、IList<T> IReadOnlyCollection<T>、IReadOnlyList<T>、ICollection、IEnumerable、IList。
using System.Collections;
public class Person {
public string Name { set; get; }
public int Age { set; get; }
public override string ToString()
{ // 用于WriteLine,输出前调用对象的ToString()
return "Name: " + Name + "; Age: " + Age;
}
public override bool Equals(object obj)
{ // 用于Remove时比较对象是否相等
if (obj == null) return false; // object对象为空
Person objAsPerson = obj as Person; // 转换为Person为空,即非Person对象
if (objAsPerson == null) return false;
else return Equals(objAsPerson);
}
public bool Equals(Person other) {
if (other == null) return false;
return (this.Name.Equals(other.Name)); // 只比较Name属性
}
}
public class Pragram
{
public static void Main()
{
IList<Person> persons = new List<Person>(); // List
persons.Add(new Person() { Name = "Tom", Age = 19 });
persons.Add(new Person() { Name = "Jerry", Age = 18 });
persons.Add(new Person() { Name = "Buly", Age = 20 });
persons.Insert(2, new Person() { Name = "aaa", Age= 21 });
persons.Remove(new Person() { Name = "aaa" });
Console.WriteLine(persons.Contains(new Person() { Name = "aaa" }));
foreach (Person person in persons) { Console.WriteLine(person); }
}
}3、链表、队列、栈
3.1、LinkedList<T>
优点:插入、删除效率高,复杂度O(1)。
缺点:随机访问效率低,需要遍历链表,复杂度O(n)。
双重链表,增删节点时不会在堆上分配分配其他对象。
对象中的每个 LinkedList<T> 节点的类型为 LinkedListNode<T>。 由于LinkedList<T>是双向的,因此每个节点都指向前一个节点,Next向后指向后一个节点。
同时创建节点及其值时,包含引用类型的列表性能更好。 LinkedList<T> 接受 null 作为引用类型的有效 Value 属性,并允许重复值。如果 LinkedList<T>为空,则 First 和 Last 属性包含 null。
LinkedList<T>仅支持多线程读。
LinkedList实现ICollection<T>、IEnumerable<T>、IReadOnlyCollection<T>、ICollection、IEnumerable、IDeserializationCallback、ISerializable。
using System.Collections;
public class Pragram
{
public static void Main()
{
string[] words = { "Hello", "World", "!", "C", "sharp", "!"};
LinkedList<string> sentence = new LinkedList<string>(words); // 双链表
sentence.AddLast("Four-lettle Words!");
sentence.AddFirst("Welcome!");
sentence.RemoveLast();
foreach (string word in sentence) { Console.Write("{0} ", word); }
Console.WriteLine(sentence.Last); // 最后一个节点
LinkedListNode<string> currentNode = sentence.Find("Welcome!");
Console.WriteLine(currentNode.Value); // 节点的值
}
}3.2、Queue(队列)
对象先进先出(FIFO)的集合,容量动态扩展。
一般用于存放临时信息,在检索元素值后,可能需要放弃该元素。按照存储顺序访问时,使用Queue。与存储顺序相反时,使用Stack。
Queue 接受 null 为有效值,并允许重复元素。
如果需要同时从多个线程访问集合,使用 ConcurrentQueue<T>。
实现ICollection、IEnumerable、ICloneable。
using System.Collections;
public class Pragram
{
public static void Main()
{
Queue queue = new Queue(); // 队列
queue.Enqueue("Hello");
queue.Enqueue("World");
queue.Enqueue("!");
queue.Dequeue(); // 移除队首,并返回
Console.WriteLine(queue.Contains("Hello"));
foreach (var item in queue) { Console.Write($"{item} "); }
Console.WriteLine(queue.Peek()); // 查询队首
}
}3.3、Stack(栈)
简单的对象后进先出 (LIFO) 的非泛型集合,容量动态扩展。
Stack 接受 null 为有效值并允许重复元素。
实现ICollection、IEnumerable、ICloneable。
using System.Collections;
public class Pragram
{
public static void Main()
{
Stack stack = new(); // 堆栈
stack.Push("Hello");
stack.Push("World");
stack.Push("!");
stack.Pop(); // 移除堆顶,并返回
Console.WriteLine(stack.Contains("Hello"));
foreach (var item in stack) { Console.Write($"{item} "); }
Console.WriteLine(stack.Peek()); // 查询堆顶
}
}4、集合
4.1、HashSet
集是不包含重复元素且其元素没有特定顺序的集合。
HashSet<T> 类提供高性能集合操作。动态容量扩展。
HashSet<T> 提供了集合运算,例如UnionWith(并集)、IntersectWith(交集)、ExceptWith(差集)、SymmetricExceptWith(补集)。
实现ICollection<T>、IEnumerable<T>、IReadOnlyCollection<T>、ISet<T>、IEnumerable、IReadOnlySet<T>、IDeserializationCallback、ISerializable。
using System.Collections;
public class Pragram
{
public static void Main()
{
HashSet<int> nums = new HashSet<int> { 1, 2, 3, 4, 5, 6 };
HashSet<int> evens = new HashSet<int>();
for (int i = 1; i <= 6; i++) { evens.Add( 2 * i ); }
// 并集
HashSet<int> unions = new HashSet<int>(nums);
unions.UnionWith(evens);
// 交集
HashSet<int> intersects = new HashSet<int>(nums);
intersects.IntersectWith(evens);
// 差集
HashSet<int> excepts = new HashSet<int>(nums);
excepts.ExceptWith(evens);
// 补集
HashSet<int> symmExcepts = new HashSet<int>(nums);
symmExcepts.SymmetricExceptWith(evens);
HashSet<int>[] result = { nums, evens, unions, intersects, excepts, symmExcepts };
foreach(var i in result) { Display(i); }
void Display(HashSet<int> hs) {
Console.Write($"{{");
foreach (int i in hs) { Console.Write($" {i}"); }
Console.WriteLine(" }");
}
}
}4.2、SortedSet(有序集合)
不包含重复元素且其元素有一定顺序的集合。
SortedSet<T> 对象在插入和删除元素时维护排序顺序,而不会影响性能。同样可以使用HashSet中的并交叉补的集合运算方法。
通过实现IComparer<T>中的Compare(T x, T y)方法,完成比较器的定义。
实现ICollection<T>、IEnumerable<T>、IReadOnlyCollection<T>、ISet<T>、ICollection、IEnumerable、IReadOnlySet<T>、IDeserializationCallback、ISerializable。
public class Pragram
{
public static void Main()
{
SortedSet<int> defaultOrder = new SortedSet<int>();
SortedSet<int> descendOrder = new SortedSet<int>(new ByDescend());
Random random = new Random();
for (int i = 0; i < 10; i++) {
int t = random.Next(0, 1000);
defaultOrder.Add(t);
descendOrder.Add(t);
}
foreach (int s in defaultOrder) { Console.Write($"{s} "); }
Console.WriteLine();
foreach (int s in descendOrder) { Console.Write($"{s} "); }
}
public class ByDescend: IComparer<int> { // 比较器,定义类型为比较两个对象而实现的方法
public int Compare(int x, int y)
{ // 比较两个对象,并返回一个int来表明相对大小;<0表示x小于y,0表示相等,>0表示x大于y
if (x > y) { return -1; } // 降序
else if (x < y) { return 1; }
else { return 0; }
}
}
}自定义类型的比较器。
using System.Collections;
public class Pragram
{
public static void Main()
{
SortedSet<Person> persons = new SortedSet<Person>(new ByNameAge()) {
new Person("Tom", 21),
new Person("Tom's Master", 55),
new Person("Jerry", 18),
new Person("Jerry's Cousin", 35),
new Person("Jerry's Cousin", 32),
new Person("Buly", 20) };
foreach (Person person in persons) {
Console.WriteLine($"name: {person.Name}; age: {person.Age}");
}
}
public class Person {
private string name;
private int age;
public string Name { get { return name; } }
public int Age { get { return age; } }
public Person(string name, int age) { this.name = name; this.age = age; }
}
public class ByNameAge: IComparer<Person>
{ // 比较器
public int Compare(Person x, Person y)
{ // 比较两个对象,并返回一个int来表明相对大小;<0表示x小于y,0表示相等,>0表示x大于y
if (x.Name.CompareTo(y.Name) !=0 ) { return -x.Name.CompareTo(y.Name); } // 降序
else if (x.Age.CompareTo(y.Age) != 0 ) { return x.Age.CompareTo(y.Age); } // 默认升序
else { return 0; }
}
}
}5、哈希表
5.1、Dictionary(字典)
表示键和值的集合,值是无序的,键是唯一的。动态容量扩展。
使用键检索值的速度非常快,接近O(1) ,因为 Dictionary<TKey,TValue> 类是作为哈希表实现的。
如果键的类型TValue为引用类型,则键不能为null,但值可以为null 。
实现ICollection<KeyValuePair<TKey,TValue>>、IDictionary<TKey,TValue>、IEnumerable<KeyValuePair<TKey,TValue>>、IEnumerable<T>、IReadOnlyCollection<KeyValuePair<TKey,TValue>>、IReadOnlyDictionary<TKey,TValue>、ICollection、IDictionary、IEnumerable、IDeserializationCallback、ISerializable。
using System.Collections;
public class Pragram
{
public static void Main()
{
Dictionary<string, int> dic = new Dictionary<string, int>();
dic.Add("Tom", 19);
dic.Add("Jerry", 18);
dic.Add("Buly", 20);
// 增加相同key的异常处理
try { dic.Add("Tom", 20); }
catch (ArgumentException) { Console.WriteLine("Key Alreadly Exists!"); }
// 赋值不存在的key的异常处理
try { dic["aaa"] = 20; }
catch (KeyNotFoundException) { Console.WriteLine("Key is not found"); }
// 若经常获取/访问不存在的键,使用TryGetValue()方法
int valueAge;
if (dic.TryGetValue("Tom", out valueAge)) {
Console.WriteLine($"Key[Tom]'s value is {valueAge}");
} else {
Console.WriteLine("Key[Tom]'s value is not found");
}
// ContainsKey()方法来检查Key
if (!dic.ContainsKey("bbb")) {
dic.Add("bbb", 222);
}
// 在foreach中字典的枚举元素类型是KeyValuePair键值对
foreach(KeyValuePair<string, int> kvp in dic) {
Console.WriteLine($"Key is {kvp.Key}; Value is {kvp.Value}");
}
// Values属性可以只获取值,是强类型的
Dictionary<string, int>.ValueCollection dicValue = dic.Values;
}
}
5.2、HashTable(哈希表)
根据键的哈希代码进行组织的键/值对的集合,动态容量扩展。
Hashtable 中任何元素都被当做object处理,存在装修、拆箱。
重写方法Object.Equals(或IHashCodeProvider接口)和方法Object.GetHashCode (或IComparer接口) 需要Hashtable用作键的对象。 方法和接口的实现必须以相同的方式处理区分大小写。
Hashtable 中的每个键对象都必须提供自己的哈希函数,可通过调用 GetHash来访问该函数。
将元素添加到 Hashtable时,该元素将基于键的哈希代码放入存储桶中。随后的键查找使用键的哈希代码在一个特定存储桶中搜索,从而大大减少了查找元素所需的键的比较数。元素与存储桶的最大比率决定了Hashtable 的负载因子。 较小的负载因子的查找更快,但是内存消耗更多。 默认负载系数 1.0 通常提供速度和内存大小之间的最佳平衡。 创建 Hashtable 时还可以指定不同的负载因子。
实现ICollection、IDictionary、IEnumerable、ICloneable、IDeserializationCallback、ISerializable。
using System.Collections;
public class Pragram
{
public static void Main()
{
Hashtable ht = new Hashtable();
ht.Add("Tom", 19);
ht.Add("Jerry", 18);
ht.Add("Buly", 20);
try { ht.Add("Tom", 20); }
catch { ht["Tom"] = 20; }
// 默认的Item属性
ht["aaa"] = 30;
// 判断是否包含某个键
if (!ht.ContainsKey("bbb")) { ht.Add("bbb", 40); }
// 遍历哈希表的键值对
foreach (DictionaryEntry kv in ht) { Console.WriteLine($"Key is {kv.Key}; Value is {kv.Value}"); }
// 删除键
ht.Remove("bbb");
// 遍历哈希表的键
ICollection htKeys = ht.Keys;
foreach (string key in htKeys) { Console.WriteLine($"Key is {key}"); }
}
}5.3、SortedDictionary
根据键进行排序的键/值对的集合。
SortedDictionary<TKey,TValue> 泛型类是具有 O(logn) 检索的二进制搜索树,与 SortedList<TKey,TValue> 泛型类类似,但是,SortedList使用的内存少于 SortedDictionary,SortedDictionary具有更快的未排序数据的插入和删除操作。如果一次性从已排序的数据填充列表, SortedList 比 SortedDictionary快。
每个键/值对都可以作为 KeyValuePair<TKey,TValue> 结构或通过 DictionaryEntry 非泛型 IDictionary 接口检索。
SortedDictionary<TKey,TValue> 需要比较器实现来执行键比较,使用泛型接口IComparer<T>实现。如果不指定实现,则使用默认的 genericcomparerComparer<T>.Default。 如果类型 TKey 实现 IComparable<T> 泛型接口,则默认比较器使用该实现。
实现ICollection<KeyValuePair<TKey,TValue>>、IDictionary<TKey,TValue>、IEnumerable<KeyValuePair<TKey,TValue>>、IEnumerable<T>、IReadOnlyCollection<KeyValuePair<TKey,TValue>>、IReadOnlyDictionary<TKey,TValue>、ICollection、IDictionary、IEnumerable。
public class Pragram
{
public static void Main()
{ // 有序字典
SortedDictionary<string, int> persons = new SortedDictionary<string, int>(new ByName()) {
{ "Tom", 20 } , {"Jerry", 18}, { "Buly", 21 }, { "Jerry' Big Cousin", 35 }
};
foreach(KeyValuePair<string, int> kvp in persons)
{
Console.WriteLine($"Key: {kvp.Key}; Value: {kvp.Value}");
}
} // 其他方法与Dictionary类似
public class ByName: IComparer<string>
{ // 比较器(只比较键)
public int Compare(string x, string y) {
return x.CompareTo(y);
}
}
}5.4、SortedList
基于 IComparer<T> 实现的按键进行排序的键/值对的集合。动态容量扩展。
SortedList<TKey,TValue>支持通过Values 和Keys属性返回的集合来对键和值的高效索引检索。(string v = mySortedList.Values[3]; ) 访问属性时无需重新生成列表,因为这些列表只是键和值的内部数组的包装器。
SortedList<TKey, TValue>需要比较器实现来排序。 默认比较器 Comparer<T>.Default 检查键类型 TKey 是否实现 System.IComparable<T> 并使用该实现(若可用)。否则, Comparer<T>.Default 检查键类型 TKey 是否实现 System.IComparable。 如果键类型 TKey 未实现任一 System.Collections.Generic.IComparer<T> 接口,则可以在接受comparer参数的构造函数重载中指定实现 。
实现ICollection<KeyValuePair<TKey,TValue>>、IDictionary<TKey,TValue>、IEnumerable<KeyValuePair<TKey,TValue>>、IEnumerable<T>、IReadOnlyCollection<KeyValuePair<TKey,TValue>>、IReadOnlyDictionary<TKey,TValue>、ICollection、IDictionary、IEnumerable。
public class Pragram
{
public static void Main()
{
SortedList<string, int> persons = new SortedList<string, int>(new ByName()) {
{ "Tom", 20 } , {"Jerry", 18}, { "Buly", 21 }, { "Jerry' Big Cousin", 35 }
};
foreach(KeyValuePair<string, int> kvp in persons)
{
Console.WriteLine($"Key: {kvp.Key}; Value: {kvp.Value}");
}
// 通过Keys合Values属性进行高效索引
Console.WriteLine($"The 3rd person is {persons.Keys[2]}");
// 获取键,并存储在列表中
IList<string> list = persons.Keys;
foreach(string key in list) {
Console.WriteLine(key);
}
} // 方法与List类似,其中元素可用KeyValuePair迭代
public class ByName: IComparer<string>
{ // 比较器
public int Compare(string x, string y)
{
return x.CompareTo(y);
}
}
}6、堆
堆通常是一个可以被看做一棵完全二叉树的数组对象。堆中某个节点的值总是不大于或不小于其父节点的值。堆总是一棵完全二叉树。
堆通常用于动态分配和释放程序所使用的对象。操作一次的时间复杂度在 O(1)~O(logn) 之间。
二叉堆是一颗完全二叉树,且堆中某个节点的值总是不大于(不小于)其父节点的值,该完全二叉树的深度为 k,除第 k 层外,其它各层 (1~k-1) 的结点数都达到最大个数,第k 层所有的结点都连续集中在最左边。堆的根节点最大称为最大堆。
堆的插入:最大堆的插入的关键操作是上移,通过将插入的节点与父节点比较,若大于父节点则上移,即与父节点交换,保证父节点最大的性质。
类似使用数组存储二叉堆。当前索引i的父节点索引为i/2取整,左子节点为2i,右子节点为2i+1。
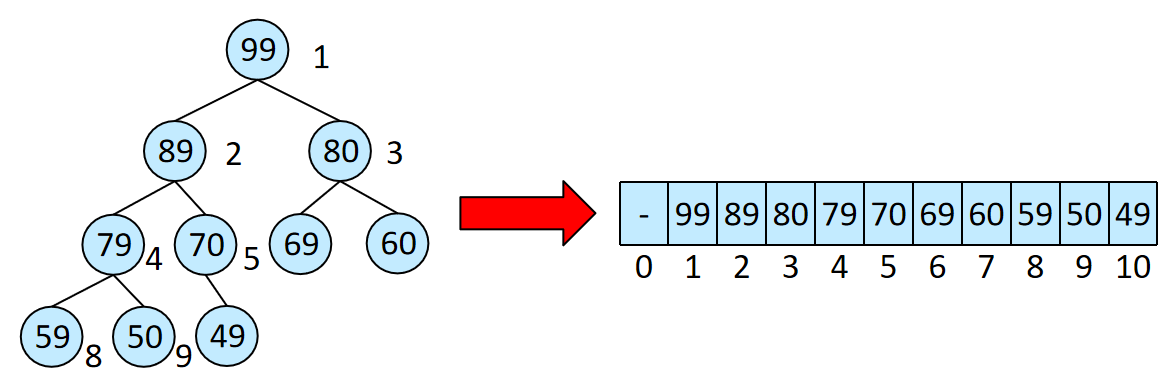
下例是用C#实现的泛型堆,包括构造、插入、容量扩展、层序遍历,包括元素上移、下移。
using System.Collections;
class Program
{
public class MaxHeap<T>: IEnumerable<T> // 最大堆
{
private T[] data; // 存储数据
private int count; // 大小
private int capacity; // 容量
private const int defaultCapacity = 4; // 默认容量
private const int growFactor = 2; // 扩容因子
private IComparer<T> comparer; // 比较器,用于比较父节点、子节点
public int Count { get { return count; } }
public int Capacity { get { return capacity - 1; } }
private void Init(int _capacity, IComparer<T> _comparer) { // 初始化,用于构造
count = 0;
if (_capacity < 0) { throw new IndexOutOfRangeException(nameof(_capacity)); }
else if (_capacity < defaultCapacity) { this.capacity = defaultCapacity + 1; }
else this.capacity = _capacity + 1;// 索引0不存储数据,实际容量=设置容量+1
data = new T[this.capacity];
comparer = _comparer ?? Comparer<T>.Default;// 若空,则使用默认比较器
}
public MaxHeap(int _capacity, IComparer<T> _comparer) { // 构造
Init(_capacity, _comparer);
}
public MaxHeap() : this(defaultCapacity, null) { } // 构造
public MaxHeap(int _capacity) : this(_capacity, null) { } // 构造
public MaxHeap(IEnumerable<T> _collection, IComparer<T> _comparer) { // 构造,根据可迭代对象创建堆
if (_collection == null) { Init(defaultCapacity, null); }
Init(_collection.Count(), _comparer);
using (IEnumerator<T> _enum = _collection.GetEnumerator()) {
while (_enum.MoveNext()) {
this.Insert(_enum.Current); }// 将可迭代集合中的数据插入
}
}
public bool IsEmpty() { return count == 0; } // 是否为空
public T this[int index] { get { return data[index]; } } // 索引器
private int pos;
public IEnumerator<T> GetEnumerator() // 迭代器
{
for(int i = 1; i <= this.count; i++) { yield return data[i]; }
}
IEnumerator IEnumerable.GetEnumerator()
{
throw new NotImplementedException();
}
//public object Current { get { return data[pos]; } }
//public bool MoveNext() { pos++; if (pos < this.count) { return true; } return false; }
//public void Reset() { this.pos = -1; }
public void Insert(T item) // 插入
{
if(count + 1 >= capacity - 1) {
this.capacity = (capacity - 1) * growFactor + 1;
T[] newdata = new T[capacity];// 容量扩展
Array.Copy(data, newdata, count + 1);// 实际长度是元素个数+1(要包含索引0)
data = newdata;
}
count++;
data[count] = item;
ShiftUp(count);// 上移
}
private void ShiftUp(int k) // 上移
{
while(k > 1 && comparer.Compare(data[k], data[k / 2]) > 0) {// 若非根节点,且大于父节点
Swap(k, k / 2);// 交换两个索引的元素
k /= 2;
}
}
public T ExtractMax() // 提取最大值
{
if(count <= 0) { throw new IndexOutOfRangeException(); }
T temp = data[1];
Swap(1, count);// 根节点
count -= 1;
ShiftDown(1);// 根节点下移
return temp;
}
public T GetMax() // 访问最大值
{
if (count <= 0) { throw new IndexOutOfRangeException(); }
return data[1];
}
private void ShiftDown(int k) // 下移
{
while(2*k < this.count)// 存在子节点
{
int j = 2 * k;// 左子节点
if(j + 1 <= count && comparer.Compare(data[j + 1], data[j]) > 0) { j += 1; }// 右子节点中较大
if (comparer.Compare(data[k], data[j]) > 0) { break; }// 父节点最大,break
Swap(k, j);
k = j;
}
}
private void Swap(int i, int j)
{ // 交换
T temp = data[i];
data[i] = data[j];
data[j] = temp;
}
public override string ToString()
{ // 重写Write、WriteLine的转字符串方法
string result1 = "{ ";
for (int i = 1; i <= this.count; i++)
{// 层序遍历,即按二叉堆数组的索引进行遍历
result1 += $"{data[i]} ";
}
result1 += "}\n";
int col = (int)Math.Ceiling(Math.Log2(this.count + 1)) - 1;
int row = 0;
int all = (int)Math.Pow(2, row);
string result2 = "";
for (int i = 1; i <= this.count; i++)// 二叉堆的数组从索引1开始存储
{
for (int j = 0; j < col; j++) { result2 += " "; }
result2 += $"{data[i]} ";
if (i >= all) { result2 += "\n"; row += 1; all += (int)Math.Pow(2, row); col -= 1; }
}
return result1 + result2;
}
}
public static void Main()
{
MaxHeap<int> heap = new MaxHeap<int>(); // 构造容量为10的堆
Console.WriteLine($"Heap's capacity is {heap.Capacity}");
Random rnd = new Random();
for (int i = 0; i < 15; i++) { heap.Insert(rnd.Next(1, 1000)); } // 插入
Console.WriteLine($"Heap's capacity is {heap.Capacity}");
Console.WriteLine(heap);
Console.WriteLine($"Heap's Maximum: {heap.ExtractMax()}"); // 提取最大值
foreach (int i in heap) { Console.Write($"{i} "); } // 遍历
Console.WriteLine();
MaxHeap<int> heap2 = new MaxHeap<int>(heap, null); // 使用堆构造
foreach (int i in heap2) { Console.Write($"{i} "); }
Console.WriteLine();
string[] strings = { "Tom", "Jerry", "Buly", "Tom's Master", "Jerry's big Cousin", "Jerry's 2nd Cousin" };
MaxHeap<string> heap3 = new MaxHeap<string>(strings, null); // 使用字符串数组构造
Console.WriteLine(heap3);
}
}7、树
树是有n≥0个节点的有限集。当n=0时称为空树。在非空树中,有且仅有一个根节点。根节点没有前驱,其余节点有且只有一个前驱。所有节点可以有零或多个后继。当n>1时,其余非根节点可以分为m个互不相交的子集,称为子树。
节点的度:该节点的子节点个数。
叶节点:度=0(子节点数为0)的节点。
树的度:所有节点的度的最大值。
节点的层:根节点到该节点的路径长度。
树的高度:所有节点的最大层数。
森林:k个不相交的树的集合。
若一颗树的高度为H,树的度为m。节点数是所有节点的度之和+1。该树最多有(m^H-1)/(m-1)个节点(等比数列求和)。树的第i层上最多有m^(i-1)个节点。
具有n个节点的度为m的树,其最小高度Hmin = lg(n(m-1)+1)/lgm。
7.1、二叉树
二叉树即度为2的树,树中不存在子节点数大于2的节点。二叉树有左右之分,顺序不能颠倒。
满二叉树:叶节点都在最底层,其余节点的度都是2的树。
完全二叉树:一个树的节点要么是叶节点,要么度为2,且优先底层、左子节点排列。
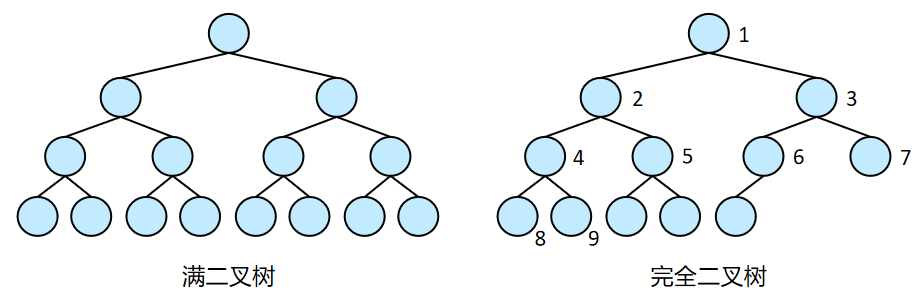
二叉树的构建分为顺序存储、链式存储。(顺序存储即用数组存储二叉树,见6、堆。)
下例是C#实现的链式存储的二叉树,包括节点类、树类、插入、删除、遍历。
class Program
{
class TreeNode<T> { // 节点类
private T data; // 数据
private TreeNode<T> lchild; // 左子节点
private TreeNode<T> rchild; // 右子节点
public T Data { get => data; set => data = value; }
public TreeNode<T> Lchild { get => lchild; set => lchild = value; }
public TreeNode<T> Rchild { get => rchild; set => rchild = value; }
public TreeNode(T _data, TreeNode<T> _lchild, TreeNode<T> _rchild) // 构造
{
data = _data;
lchild = _lchild;
rchild = _rchild;
}
public TreeNode(): this(default, null, null) {}
public TreeNode(T _data): this(_data, null, null) {}
}
class BinaryTree<T> { // 二叉树类(链式存储)
private TreeNode<T> root;
public TreeNode<T> Root { get => root; set => root = value; }
public BinaryTree(T _input, TreeNode<T> _lchild, TreeNode<T> _rchild) { // 构造
TreeNode<T> temp = new TreeNode<T>(_input, _lchild, _rchild);
root = temp;
}
public BinaryTree() { } // 构造
public BinaryTree(T _input): this(_input, null, null) { } // 构造
public void InsertLeft(TreeNode<T> p, T data) { // 插入左子树
TreeNode<T> temp = new TreeNode<T>(data);
temp.Lchild = p.Lchild;// 原节点的左子树变为其左子树的左子树
p.Lchild = temp;
}
public TreeNode<T> RemoveLeft(TreeNode<T> _node) { // 删除左子树
if (_node == null || _node.Lchild == null) { return null; }
TreeNode<T> temp = _node.Lchild;
_node.Lchild = null;
return temp;// 返回删除的左子树
}
public TreeNode<T> Search(TreeNode<T> _node, T _value) { // 查找
TreeNode<T> node = _node;
if (node == null) return null;
if (node.Data.Equals(_value)) { return node; }
if (node.Lchild != null) { return Search(node.Lchild, _value); }
if (node.Rchild != null) { return Search(node.Rchild, _value); }
return null;
}
public void PreTraversal(TreeNode<T> _node) { // 前序遍历,根左右
if (_node != null) {
Console.Write($"{_node.Data} ");
PreTraversal(_node.Lchild);
PreTraversal(_node.Rchild);
}
}
public void InTraversal(TreeNode<T> _node) { // 中序遍历,左根右
if (_node != null)
{
InTraversal(_node.Lchild);
Console.Write($"{_node.Data} ");
InTraversal(_node.Rchild);
}
}
public void PostTraversal(TreeNode<T> _node) { // 后序遍历,左右根
if (_node != null)
{
PostTraversal(_node.Lchild);
PostTraversal(_node.Rchild);
Console.Write($"{_node.Data} ");
}
}
public void LevelTraversal(TreeNode<T> _node) { // 层次遍历
if (_node != null)
{
Queue<TreeNode<T>> q = new Queue<TreeNode<T>>(50);
q.Enqueue(_node);
while (q.Count != 0) {
TreeNode<T> temp = q.Dequeue(); // 当前节点出队
Console.WriteLine(temp.Data);
if (temp.Lchild != null) { q.Enqueue(temp.Lchild); } // 子节点入队
if (temp.Rchild != null) { q.Enqueue(temp.Rchild); }
}
}
}
}
}7.2、线索二叉树
链表二叉树仅能体现节点的父子关系,不能直接得到结点在遍历中的前驱或后继。同时,会产生大量的空指针,有n个节点的二叉树有2n个指针,其中只有n-1个指针有效(父节点指向子节点),即有n+1个空指针。
线索二叉树:具有指向前驱、后继元素的指针(线索)的链表二叉树。
通过中序遍历二叉树,空的左指针指向前驱元素,空的右指针指向后继元素,相当于把二叉树转换为近似的双链表。部分节点间的连接并不是依靠指针,而是通过父子关系。
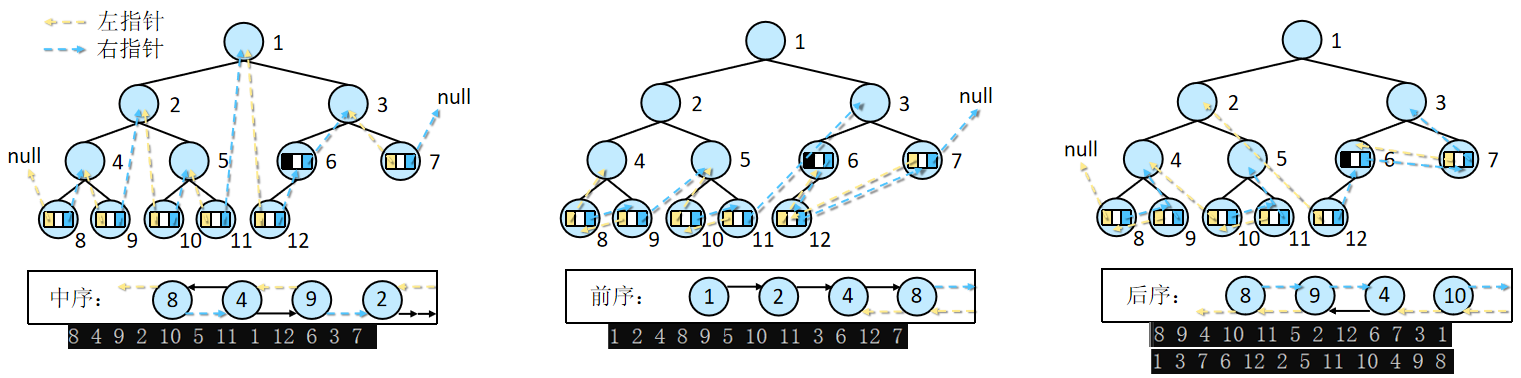
下例是C#实现的线索二叉树,包括节点类、二叉树类、线索化及对应的遍历方法(前中后序)。
class Program
{
class TreeNode<T>
{
private T data;
public TreeNode<T> Lchild;
public TreeNode<T> Rchild;
private bool ltag = false; // true为线索,false为父子关系
private bool rtag = false;
public T Data { get => data; set => data = value; }
public bool Ltag { get => ltag; set => ltag = value; }
public bool Rtag { get => rtag; set => rtag = value; }
public TreeNode(T _data, TreeNode<T> _lchild, TreeNode<T> _rchild) // 构造
{
data = _data; Lchild = _lchild; Rchild = _rchild;
}
public TreeNode() : this(default, null, null) { }
public TreeNode(T _data) : this(_data, null, null) { }
}
class BinaryTree<T>
{
private TreeNode<T> preNode; // 前驱节点
public TreeNode<T> CreateBiTree(T[] _data, int index) // 数组创建二叉树,从第index个元素开始
{ // TreeNode<T> root = new TreeNode<T>(); 会多出2^k个叶节点
TreeNode<T> root = null;
if (index < _data.Length)
{
root = new TreeNode<T>(_data[index]);
root.Lchild = CreateBiTree(_data, 2 * index + 1);
root.Rchild = CreateBiTree(_data, 2 * index + 2);
}
return root;
}
public void InThreading(TreeNode<T> root) // 中序线索化,左根右
{
if (root == null) return;
// 左子树
InThreading(root.Lchild);
// 根,同时为当前节点的左子树、前一节点的右子树(指后)进行线索化
if (root.Lchild == null)// 左子树为空
{
root.Lchild = preNode;// 左指针指向前驱,第一个节点的前驱节点为null
root.Ltag = true;
}
if (preNode != null && preNode.Rchild == null)// 前一节点的右指针指向当前节点
{
preNode.Rchild = root;
preNode.Rtag = true;
}
preNode = root;// 当前节点遍历完成,当作前一节点
// 右子树
InThreading(root.Rchild);
}
public void InTraversal(TreeNode<T> root) // 中序线索化的遍历
{ // 1、向左下找到中序遍历的起始节点
while (root != null && root.Ltag == false)
{
root = root.Lchild;
}
// 2、从起始节点开始,按后继节点(右指针、右子树)遍历
while (root != null)// 右子树和右指针分别处理
{
Console.Write($"{root.Data} ");
if (root.Rtag)// 右指针
{
root = root.Rchild;// 右指针所指即后续节点
}
else// 右子树
{
root = root.Rchild;
while (root != null && root.Ltag == false) {// 右子树的后续节点是其最左下的左子树(类似1)
root = root.Lchild; }// 右子树无后续节点(存在左指针),则输出该右子树
}
}
}
public void PreThreading(TreeNode<T> root) // 前序线索化,根左右
{
if (root == null) return;
if (root.Lchild == null)// 左子树为空
{
root.Lchild = preNode;// 左指针指向前驱,第一个节点的前驱节点为null
root.Ltag = true;
}
if (preNode != null && preNode.Rchild == null)// 前一节点的右指针指向当前节点
{
preNode.Rchild = root;
preNode.Rtag = true;
}
preNode = root;// 前一节点
if (!root.Ltag) PreThreading(root.Lchild); // 判断是子树还是指针,避免死递归!!!
if (!root.Rtag) PreThreading(root.Rchild);
}
public void PreTraversal(TreeNode<T> root) // 前序线索化的遍历
{ // 遍历节点及其左子树,最左下的左子树的右子树是下一个节点
if (root == null) return;
while (root != null)
{
Console.Write($"{root.Data} ");
if(root.Lchild != null && root.Ltag == false) {// 遍历左子树
root = root.Lchild;
} else {// 从最左下的左子树的右指针继续
root = root.Rchild;
}
}
}
public void PostThreading(TreeNode<T> root) // 后序线索化,左右根
{
if (root == null) return;
if (root.Ltag == false) PostThreading(root.Lchild);// 迭代
if (root.Rtag == false) PostThreading(root.Rchild);
if (root.Lchild == null)// 左子树为空
{
root.Lchild = preNode;// 左指针指向前驱
root.Ltag = true;
}
if (preNode != null && preNode.Rchild == null)// 前一节点的右指针指向后继节点(当前节点)
{
preNode.Rchild = root;
preNode.Rtag = true;
}
preNode = root;
}
public void PostTraversal(TreeNode<T> root) // 后序线索化的遍历
{ // 根据后序遍历的特点,对后序线索化进行逆向遍历
if (root == null) return;
while (root != null)
{
Console.Write($"{root.Data} ");
if (root.Rchild != null && root.Rtag == false) {// 右子树
root = root.Rchild;
} else {// 左子树
root = root.Lchild;
}
}
}
}
public static void Main(string[] args)
{
int[] nums = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 }; // , 13, 14, 15
BinaryTree<int> tree = new BinaryTree<int>();
TreeNode<int> binaryTree = tree.CreateBiTree(nums, 0);
//tree.InThreading(binaryTree);
//tree.InTraversal(binaryTree);
//tree.PreThreading(binaryTree);
//tree.PreTraversal(binaryTree);
tree.PostThreading(binaryTree);
tree.PostTraversal(binaryTree);
}
}7.3、二叉搜索树
对于二叉搜索树(二叉查找树)的所有子树,左子树都小于根节点,右子树都大于根节点。即所有的子树也都是二叉搜索树。左子树<根<右子树,对二叉搜索树进行中序遍历可以得到一个递增序列。
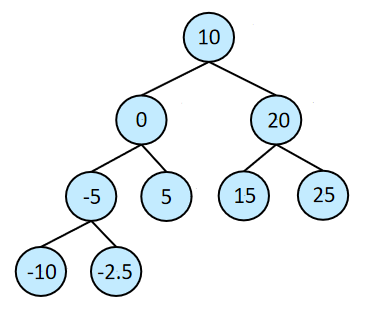
插入:大于当前节点,插入右子树;小于当前节点,插入左子树。
删除:利用被删除节点的前驱/后继元素将其代替,最终删除的位置是前驱/后继的位置。
二叉查找树的插入和查找的时间复杂度均为O(logn),最差情况为 O(n)(即变成一根树枝)。
下例是一个二叉搜索树,包括节点类、树类、插入、查找、删除等。
class Program
{
class TreeNode<T>
{ // 节点
private T data;
public TreeNode<T> Lchild;
public TreeNode<T> Rchild;
public T Data { get => data; set => data = value; }
public TreeNode(T _data, TreeNode<T> _lchild, TreeNode<T> _rchild) // 构造
{
data = _data; Lchild = _lchild; Rchild = _rchild;
}
public TreeNode() : this(default, null, null) { }
public TreeNode(T _data) : this(_data, null, null) { }
}
class BinarySearchTree<T>
{ // 二叉搜索树
private TreeNode<T> root;// 根节点
private TreeNode<T> preNode;// 前驱节点
private IComparer<T> comparer;// 比较器
public TreeNode<T> CreateTree(T[] _data, IComparer<T> _comparer)
{ // 构造
TreeNode<T> tree = new TreeNode<T>();
comparer = _comparer ?? Comparer<T>.Default;
foreach(T item in _data) {
Insert(tree, item); }
return tree;
}
public TreeNode<T> CreateTree(T[] _data) { return CreateTree(_data, null); }
public bool Insert(TreeNode<T> _node, T _data)
{ // 插入
if (_node == null)
{ // 创建新节点
TreeNode<T> temp = new TreeNode<T>(_data);
if (preNode == null)
{ // 创建根节点
root = temp;
return true;
}
if (comparer.Compare(preNode.Data, _data) > 0)
{ // 创建子节点
preNode.Lchild = temp;
} else {
preNode.Rchild = temp; }
return true;
}
preNode = _node;
if (comparer.Compare(_node.Data, _data) == 0) { return false; }// 若已经存在,返回false
else if (comparer.Compare(_node.Data, _data) > 0) { return Insert(_node.Lchild, _data); }// 比根节点小
else { return Insert(_node.Rchild, _data); }// 比根节点大
}
public TreeNode<T> Search(TreeNode<T> _node, T _data)
{ // 查找
if (_node == null) { return null; }
if (comparer.Compare(_node.Data, _data) == 0) { return _node; }// 找到,返回
else if (comparer.Compare(_node.Data, _data) > 0) { return Search(_node.Lchild, _data); }// 比根节点小,在左子树找
else { return Search(_node.Rchild, _data); }
}
public bool Delete(TreeNode<T> _node, T _data)
{ // 删除
if (_node == null) { return false; }
if (comparer.Compare(_node.Data, _data) == 0)
{ // 删除该节点
if (_node.Lchild == null) { _node = _node.Rchild; return true; } // 某一个子树为空,用另一边的子树代替原节点
else if (_node.Rchild == null) { _node = _node.Lchild; return true; }
else { // 原节点的左子树的最右子节点是原节点的前驱,可以代替原节点
TreeNode<T> tempNode = _node.Lchild; // 当前节点(原节点的左子树)
TreeNode<T> tempPreNode = null; // 当前节点的父节点
while (tempNode.Rchild != null) { // 找到当前节点的最右子节点
tempPreNode = tempNode;
tempNode = tempNode.Rchild;
}
_node.Data = tempNode.Data;
tempPreNode.Rchild = tempNode.Lchild; // 删除用于替换的节点(用其左节点简单替换)
return true;
}
} else if (comparer.Compare(_node.Data, _data) > 0) { return Delete(_node.Lchild, _data); }
else { return Delete(_node.Rchild, _data);}
}
public void InTraversal(TreeNode<T> _node)
{ // 中序遍历
if (_node == null) return;
InTraversal(_node.Lchild);
Console.Write($"{_node.Data} ");
InTraversal(_node.Rchild);
}
public void LevelTraversal(TreeNode<T> _node)
{ // 层次遍历
if (_node != null)
{
Queue<TreeNode<T>> q = new Queue<TreeNode<T>>(50);
q.Enqueue(_node);
int numOfSun = 0;
while (q.Count != 0)
{
TreeNode<T> temp = q.Dequeue(); // 当前节点出队
Console.Write($"{temp.Data} ");
if (temp.Lchild != null) { q.Enqueue(temp.Lchild); numOfSun += 1; } // 子节点入队
if (temp.Rchild != null) { q.Enqueue(temp.Rchild); numOfSun += 1; }
if(q.Count == numOfSun) {// 每行结尾换行
Console.WriteLine();// 队列长度等于下一层的子节点总数时换行(父节点全部出队,子节点全部入队)
numOfSun = 0;
}
}
}
}
}
public static void Main(string[] args)
{
double[] nums = { 0, -5, 5, -7, 7, 1, 2, 3, 4, 6, -1, -2, -3, -4, -6, -6.5, -6.8, -6.3};
BinarySearchTree<double> bst = new BinarySearchTree<double>();
TreeNode<double> tree = bst.CreateTree(nums);
bst.Insert(tree, -11);
bst.InTraversal(tree);
bst.LevelTraversal(tree);
bst.LevelTraversal(bst.Search(tree, -5));
if (bst.Delete(tree, -5)) {
bst.InTraversal(tree);
Console.WriteLine();
bst.LevelTraversal(tree); }
}
}7.4、平衡二叉搜索树
为了防止线索二叉树在某种情况下,从树状退化成树枝较少的链,需要提高二叉树的平衡性,从而有了二叉树的平衡操作。
平衡二叉树:一颗空树,或者左右子树的高度差不超过1,并且左右子树的子树高度差也不超过1的二叉树。在每次插入或删除后,平衡二叉树会通过旋转重新回到平衡的状态。平衡二叉树的插入、删除都在O(logn),但是每次旋转需要额外的O(logn)。
平衡因子:BF,左子树的深度减去右子树的深度,可以为-1、0、1,绝对值大于1则需要平衡。
失衡节点:导致二叉树失去平衡的最小节点。失衡节点分为4种类型,4种失衡节点的平衡方式不同,但目的都是将之调整为平衡的二叉搜索树。
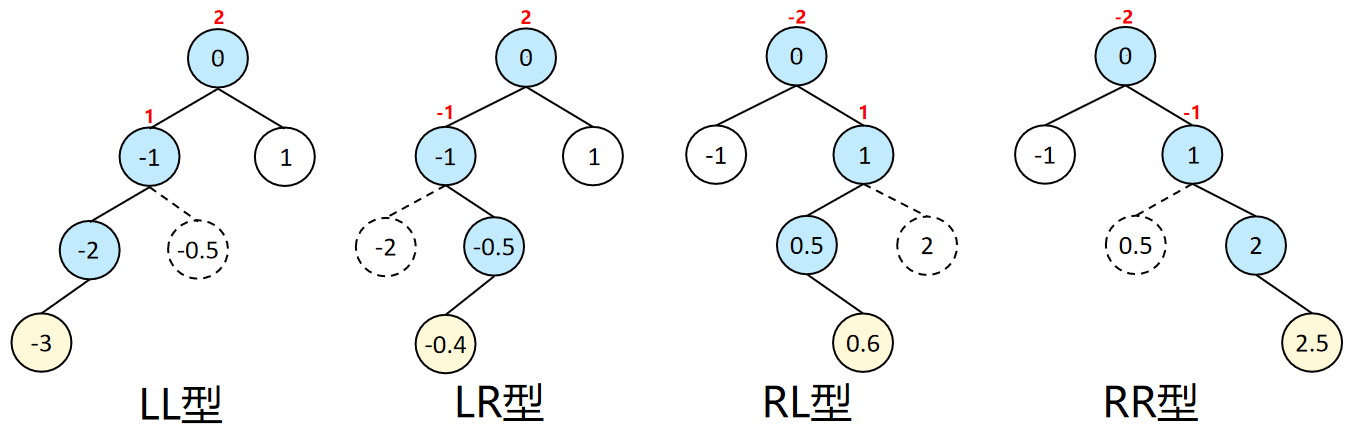
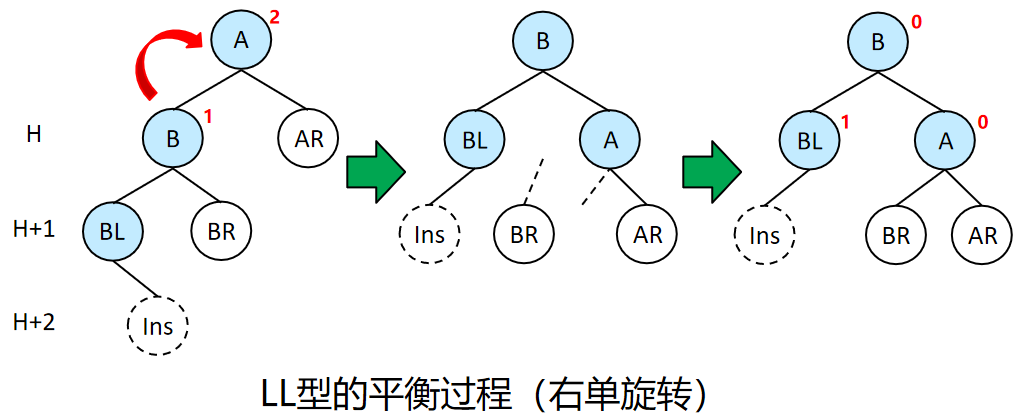
LL型、RR型可以通过单次旋转来恢复平衡。以LL型为例,根节点A的左节点B的左子树BL插入新节点导致树不平衡。此时,B节点的左子树的高度与A节点的高度一致,将整个树右旋,B节点作为新的根节点,原根节点A作为B的右子树。B的右子树BR中的全部节点的大小都介于B和A之间,因此用子树BR填补原根节点A的左子树空缺。RR型平衡过程类似,左右镜像对称。(A、B的高度为1,AR、BL、BR的高度为H。)
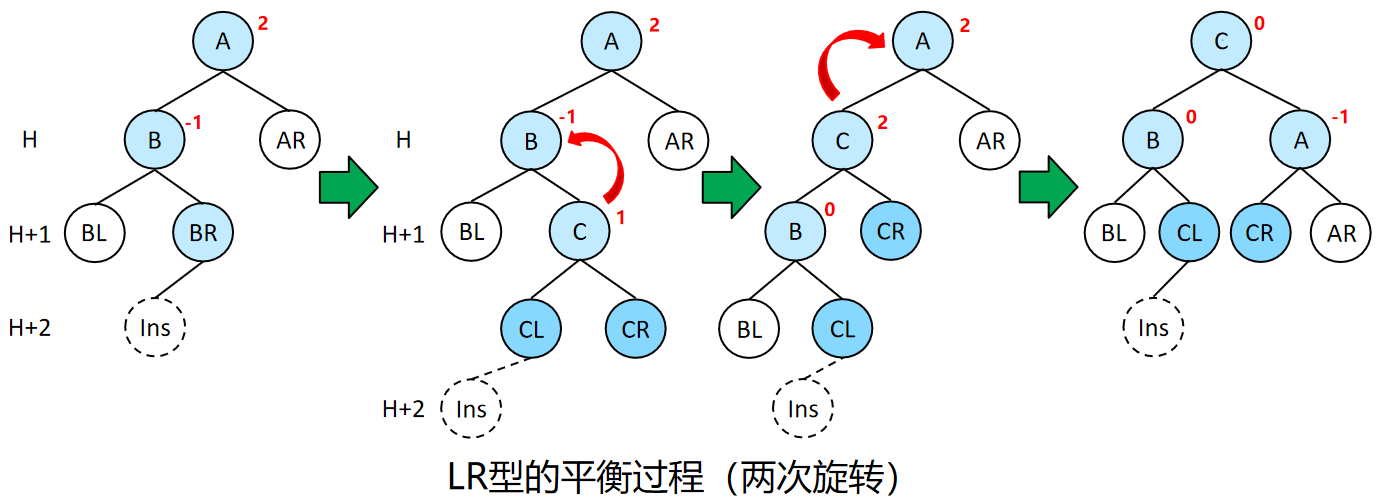
LR型、RL型需要两次旋转来恢复平衡。以LR型为例,根节点A的左节点B的右子树BR插入新节点导致树不平衡。此时,A-AR、B-BL、C-CL-Ins的高度都为H+1,而C-CL为B的左子树,大小都介于B和A,可以将C作为根节点。首先将C进行左旋,替换到B的位置,CL填充为B的右子树。LR型经过左旋后将变为类似LL型。再将C进行右旋,代替A作为新的根节点,CR填充为A的左子树。RL型平衡过程类似。(A、B的高度为1,AR、BL、BR的高度为H,CL、CR的高度为H-1。)
7.4.1、AVL树
AVL树:自平衡的二叉搜索树。
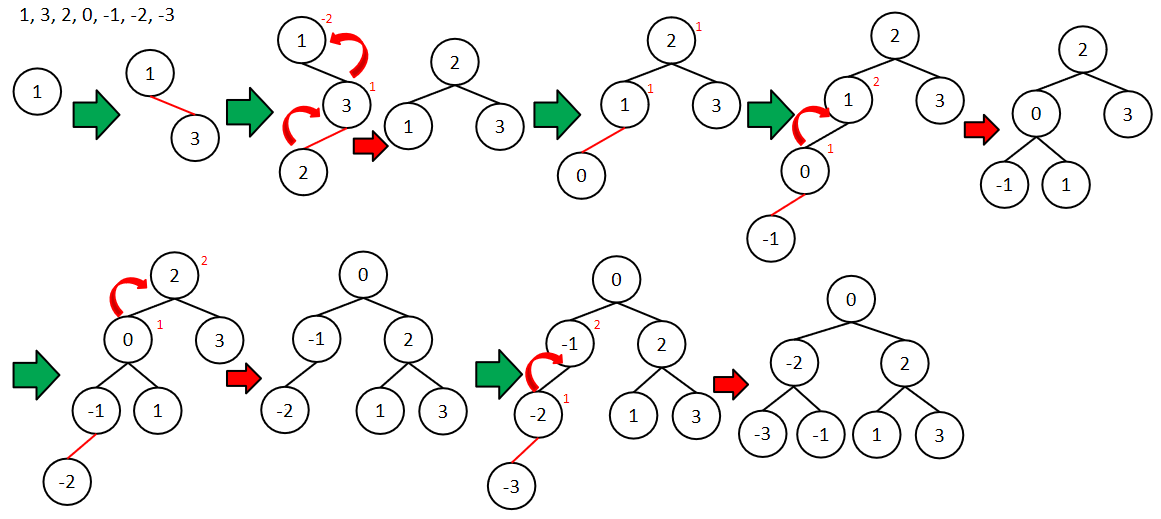
插入:根据二叉搜索树的规则插入元素,但在插入元素后,若当前节点的平衡因子绝对值>1,进行旋转,使之保持平衡,即平衡因子绝对值≤1。
AVL树的调整过程:(每插入一个新节点,都简单遍历到根节点,通过左旋/右旋来调整平衡因子绝对值>1的节点。)
下例是一个C#的AVL树,包括节点、树、左旋、右旋、插入。
class Program
{
class AVLTreeNode<T>
{ // 平衡二叉树的节点
private T data;
public int Height;// 高度
public AVLTreeNode<T> Parent;// 父节点
public AVLTreeNode<T> Lchild;
public AVLTreeNode<T> Rchild;
public T Data { get => data; set => data = value; }
public AVLTreeNode(T _data, AVLTreeNode<T> _parent, AVLTreeNode<T> _lchild, AVLTreeNode<T> _rchild) // 构造
{
data = _data; Height = 1; Parent = _parent; Lchild = _lchild; Rchild = _rchild;
}
public AVLTreeNode() : this(default, null, null, null) { }
public AVLTreeNode(T _data) : this(_data, null, null, null) { }
public AVLTreeNode(T _data, AVLTreeNode<T> _parent) : this(_data, _parent, null, null) { }
}
class AVLTree<T>
{
private AVLTreeNode<T> tree;
public AVLTreeNode<T> Tree { get => tree; set => tree = value; }
private IComparer<T> comparer;// 比较器
public void CreateTree(T[] _data, IComparer<T> _comparer) { // 构造
comparer = _comparer ?? Comparer<T>.Default;// null则使用默认比较器
foreach (T item in _data) {
Insert(item);
}
}
public void CreateTree(T[] _data) { CreateTree(_data, null); }
private static int GetHeight(AVLTreeNode<T> _node)
{ // 高度,最高的子树高度+1
if (_node.Lchild == null && _node.Rchild == null) { return 1; }
else if (_node.Lchild == null) { return _node.Rchild.Height + 1; }
else if (_node.Rchild == null) { return _node.Lchild.Height + 1; }
else { return _node.Rchild.Height > _node.Lchild.Height ? _node.Rchild.Height + 1 : _node.Lchild.Height + 1; }
}
private int GetBalanceFactor(AVLTreeNode<T> _node)
{ // 平衡因子,左子树 - 右子树
if(_node == null) { return 0; }
else if(_node.Lchild == null && _node.Rchild == null) { return 0; }
else if(_node.Lchild == null) { return 0 - _node.Rchild.Height; }
else if(_node.Rchild == null) { return _node.Lchild.Height - 0; }
else { return _node.Lchild.Height - _node.Rchild.Height; }
}
private AVLTreeNode<T> RightRotate(AVLTreeNode<T> _node)
{ // 右旋
if(_node == null) { return null; }
AVLTreeNode<T> nodeA = _node; // 失衡节点
AVLTreeNode<T> nodeB = _node.Lchild;
AVLTreeNode<T> parent = _node.Parent;
if(parent != null)
{ // 节点B右旋到节点A的位置
if (comparer.Compare(parent.Data, nodeA.Data) > 0)
{ // 若nodeA不是根节点,判断nodeA是左子树还是右子树
parent.Lchild = nodeB;
} else {
parent.Rchild = nodeB; }
}
nodeB.Parent = parent;
// 原根节点nodeA的左子树用nodeB的右子树填充
nodeA.Lchild = nodeB.Rchild;
if (nodeB.Rchild != null) { nodeB.Rchild.Parent = nodeA; }
// 新根节点nodeB的右子树为原根节点nodeA
nodeB.Rchild = nodeA;
nodeA.Parent = nodeB;
// 新的树高
nodeA.Height = GetHeight(nodeA);
nodeB.Height = GetHeight(nodeB);
return nodeB;
}
private AVLTreeNode<T> LeftRotate(AVLTreeNode<T> _node)
{ // 左旋
if(_node == null) { return null; }
AVLTreeNode<T> nodeA = _node; // 失衡节点
AVLTreeNode<T> nodeB = _node.Rchild;
AVLTreeNode<T> parent = _node.Parent;
if (parent != null)
{ // nodeB上位
if (comparer.Compare(parent.Data, nodeA.Data) > 0) {
parent.Lchild = nodeB;
} else { parent.Rchild = nodeB; }
}
nodeB.Parent = parent;
nodeA.Rchild = nodeB.Lchild;
if (nodeB.Lchild != null) { nodeB.Lchild.Parent = nodeA; }
nodeB.Lchild = nodeA;
nodeA.Parent = nodeB;
nodeA.Height = GetHeight(nodeA);
nodeB.Height = GetHeight(nodeB);
return nodeB;
}
public void Insert(T _data)
{
if (this.tree == null) { // 创建根节点
this.tree = new AVLTreeNode<T>(_data);
return; }
this.tree = Insert(this.tree, _data); // tree指向最终的根节点,而非最初建立的节点!!!
}
public AVLTreeNode<T> Insert(AVLTreeNode<T> _node, T _data)
{ // 插入
if (comparer.Compare(_node.Data, _data) > 0)
{ // 插入左子树
if(_node.Lchild == null) {
_node.Lchild = new AVLTreeNode<T>(_data);
_node.Lchild.Parent = _node;
} else {
Insert(_node.Lchild, _data);
}
} else
{ // 插入右子树
if(_node.Rchild == null) {
_node.Rchild = new AVLTreeNode<T>(_data);
_node.Rchild.Parent = _node;
} else {
Insert(_node.Rchild, _data);
}
}
// 刷新高度
_node.Height = GetHeight(_node);
// 旋转,旋转的是平衡因子绝对值大于1的节点,由下向上判断
if (GetBalanceFactor(_node) > 1)
{ // LL型
if (GetBalanceFactor(_node.Lchild) == -1) {// LR型
_node.Lchild = LeftRotate(_node.Lchild);
}
_node = RightRotate(_node);
}
if (GetBalanceFactor(_node) < -1)
{ // RR型
if (GetBalanceFactor(_node.Rchild) == 1) {// RL型
_node.Rchild = RightRotate(_node.Rchild);
}
_node = LeftRotate(_node);
}
return _node; // 返回最终的根节点
}
public void InTraversal(AVLTreeNode<T> _node)
{ // 中序遍历
if (_node == null) return;
InTraversal(_node.Lchild);
Console.Write($"{_node.Data} ");
InTraversal(_node.Rchild);
}
public void LevelTraversal(AVLTreeNode<T> _node)
{ // 层次遍历
if (_node != null)
{
Queue<AVLTreeNode<T>> q = new Queue<AVLTreeNode<T>>(50);
q.Enqueue(_node);
int numOfSun = 0;
while (q.Count != 0)
{
AVLTreeNode<T> temp = q.Dequeue(); // 当前节点出队
Console.Write($"{temp.Data} ");
if (temp.Lchild != null) { q.Enqueue(temp.Lchild); numOfSun += 1; } // 子节点入队
if (temp.Rchild != null) { q.Enqueue(temp.Rchild); numOfSun += 1; }
if (q.Count == numOfSun)
{// 每行结尾换行
Console.WriteLine();// 队列长度等于下一层的子节点总数时换行(此时父节点全部出队,子节点全部入队)
numOfSun = 0;
}
}
}
}
}
public static void Main()
{
int[] nums = { 1, 3, 2, 0, -1, -2, -3 };
AVLTree<int> avlTree = new AVLTree<int>();
avlTree.CreateTree(nums);
Console.WriteLine($"Height: {avlTree.Tree.Height}\nInTraversal: ");
avlTree.InTraversal(avlTree.Tree);
Console.WriteLine("\nLevelTraversal: ");
avlTree.LevelTraversal(avlTree.Tree);
}
}7.4.2、红黑树
红黑树:节点带有颜色标签(红色、黑色)的二叉搜索树。
红黑树的性质:① 节点只能是红色或黑色;② 根节点是黑色的;③ 所有叶子都是黑色的NIL节点,不存储数据;④ 红色节点的子节点都是黑色的(即红节点不能连续);⑤ 从任一节点到其可达叶子的所有路径,都包含相同数目的黑色节点。
红黑树的性质确保,从根到叶子的最长路径不多于最短路径的两倍(根据性质④⑤,最短路径全是黑节点,最长路径红黑相间),因此红黑树是近似平衡的。即使在最坏的情况下,仍能保持较好的性能。
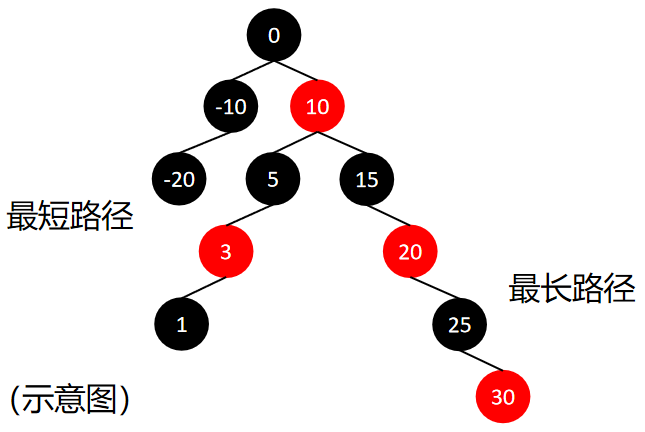
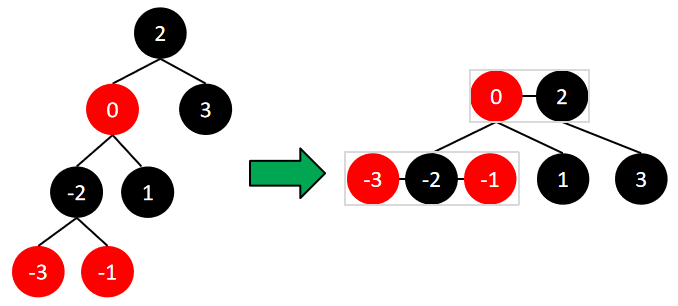
红黑树的等价形式:如果将红黑树的红节点上升到其父节点的高度,将会形成一颗4阶B树。红黑树的黑节点的数量就是4阶B树中的节点数量,因此红黑树不能有连续的红节点。由于等价的4阶B树是平衡的,因此每条简单路径上的黑节点数量相同。
与AVL树的区别:
① 平衡方式不同:红黑树用红黑节点限制其最长路径不超过最短路径的2倍,AVL树用平衡因子。
② 子树高度差不同:红黑树的左右子树高度差可能大于1。AVL树得平衡因子必须小于等于1。
③ 性能不同:红黑树通过牺牲平衡性来提高插入/删除的性能,插入/删除多的情况用红黑树,搜索比较多的情况用AVL树。平均性能,红黑树优于AVL树。
红黑树的查找:与二叉搜索树一致。
红黑树的插入:红黑树节点的颜色默认为红色,减少插入的影响。当插入红节点时,有可能会违背性质④,但不会破坏黑节点的平衡,只需要染色和旋转来调整。当插入黑节点时,一定会违背性质⑤,调整操作量大。红黑树的插入按照二叉搜索树的规则进行插入,插入后检测红黑树的性质是否被破坏。
情况0:当前树是空树,插入节点,并将根节点染为黑色。
情况1:父节点为黑色,新插入节点为默认为红色,性质没有被破坏,无需调整。
情况2:父节点为红色,新插入节点为默认为红色,违背性质④,需要调整。
情况2可以分为两类,父节点、叔节点可以是同为红色、一红一黑/空。父节点和叔节点同为红色类似于4阶B树的上溢,即4阶B树节点已经存储3个数据,再插入一个红节点相当于多了一个数据。父节点、新插入节点可能是左/右子树,因此一共是2x2x2=8种情况。
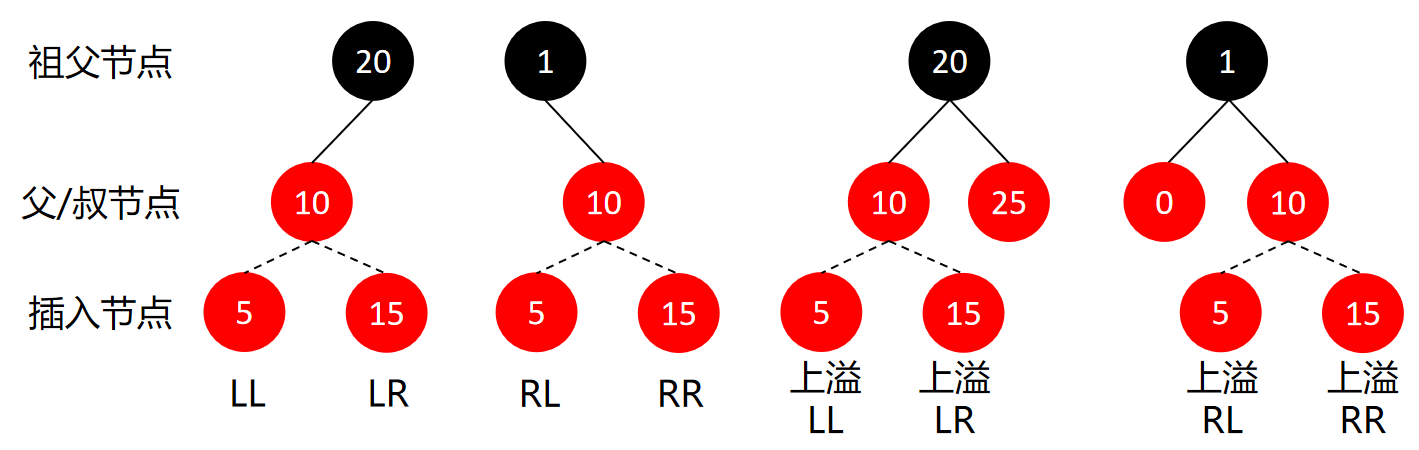
为了方便旋转,情况2的类型判断根据祖父节点,旋转操作也是对祖父节点。
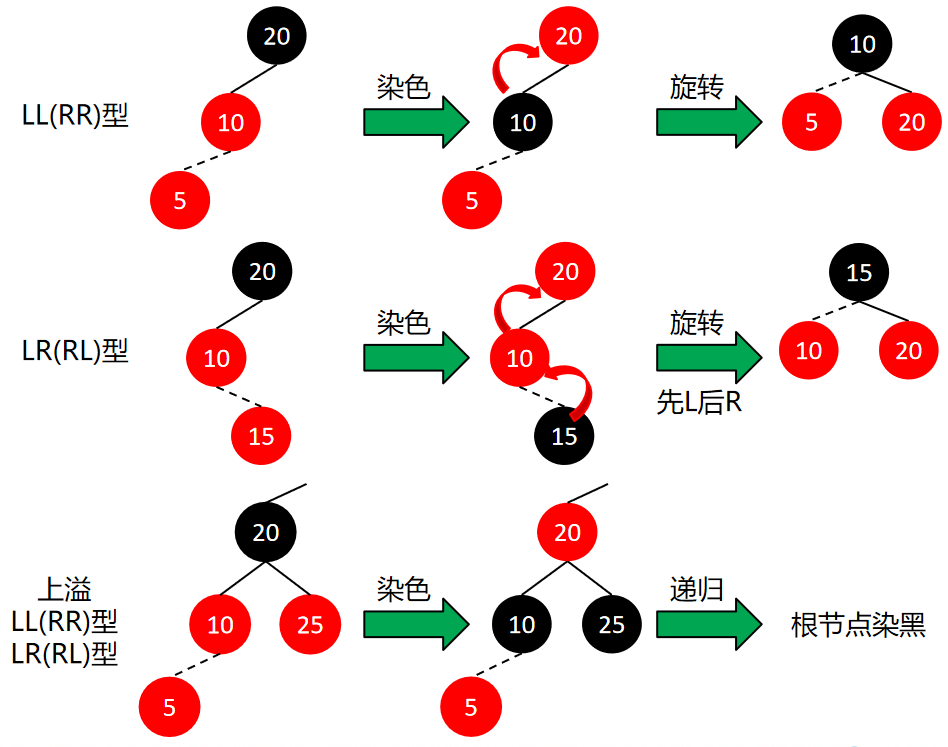
LL、RR:判断:叔节点不是红节点。调整:祖父节点染为红色,父节点染为黑色,祖父节点按AVL树的方式进行旋转,LL型右旋,RR型左旋。
LR、RL:判断:叔节点不是红节点。调整:祖父节点染为红色,插入节点染为黑色,祖父节点按AVL树的方式进行旋转,LR型先左后右,RL型先右后左。
(LL、RR、LR、RL型调整是将插入节点调整成符合4阶B树的规则(数值居中的节点位置也居中),即将祖父节点、父节点、插入节点中数值居中的节点染黑,另外两个染红,再通过旋转将新的黑节点调整为新的父节点。)
上溢LL、上溢RR、上溢LR、上溢RL:判断:叔节点是红节点。调整祖父节点染为红色,父节点、叔节点染为黑色,对该操作进行递归,直至根节点染为黑色。
(上溢LL、RR、LR、RL型调整是将插入节点导致4阶B树节点的溢出(超过3个数值)调整成符合4阶B树的规则。通过将4数值中居中的某一个上升(染红),与上一个4阶B树节点组成新的节点,剩下的3个数值组成两个新的4阶B树节点(染黑)。上升的节点可能会导致新的溢出,需要进行递归,直至根节点染为黑色。)
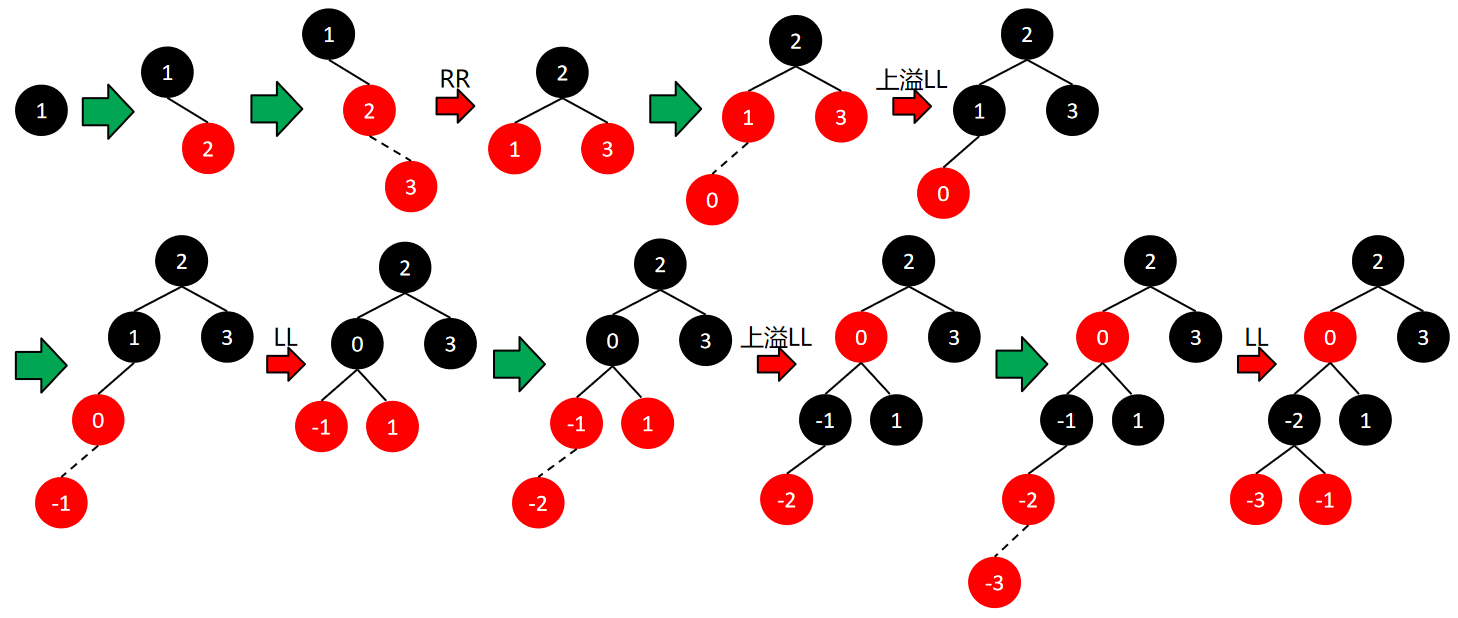
通过插入操作将数组{1, 2, 3, 0, -1, -2, -3}转化为红黑树的过程:
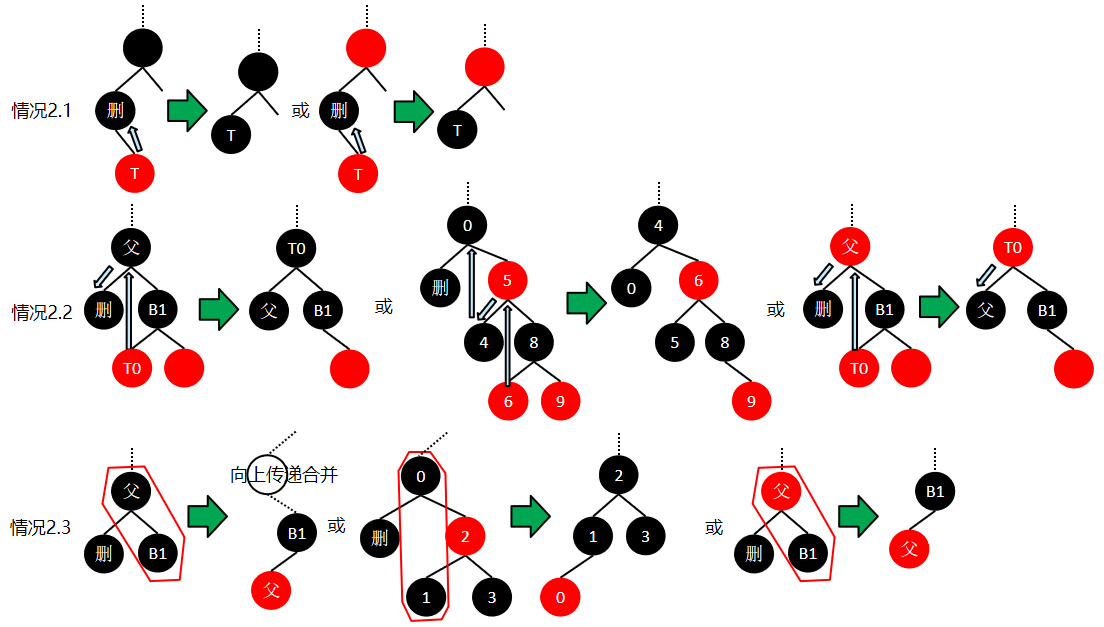
红黑树的删除:参考4阶B树的删除,用删除节点的后继节点替换,由于是简单的值替换,不会影响红黑树的性质。此时,红黑树的节点删除就转化为删除一个没有左子树的节点,并且根据4阶B树的性质,被删除的节点一定是在最底层。
情况1:被删除的是红节点,其父节点一定是黑,直接删除不会破坏红黑树的性质。
情况2:被删除的是黑节点,参考B树删除的借元素/父子换位/父子合并:
2.1:若右子树存在(且一定为红),对应于B树的元素个数>=最小度,用右子树替换、删除;
2.2:若右子树不存在,但兄弟黑节点有红子节点/兄弟红节点有红孙节点,对应于B树的元素个数不足,但兄弟节点的元素足够借(B树中的兄弟节点在红黑树中是兄弟黑节点或兄弟红节点的黑子节点),用兄弟节点的多余元素补充;
2.3:若右子树不存在,且兄弟黑节点没有红子节点/兄弟红节点没有红孙节点,对应于B树的元素不足,并且兄弟节点不够借,需要父子合并,并传递到根节点;
下例是一个C#的红黑树,包括节点类、红黑树类、构建、查找、插入、删除。(需要优化)
class Program
{
class RBTreeNode<T>
{
private T data;
public T Data { get => data; set => data = value; }
public RBTreeNode<T> Lchild;
public RBTreeNode<T> Rchild;
public RBTreeNode<T> Parent;
public enum NodeColor { RED, BLACK };
private NodeColor color; // 节点颜色,枚举类型(红、黑)
public NodeColor Color { get => color; set => color = value; }
public RBTreeNode(T data, RBTreeNode<T> lchild, RBTreeNode<T> rchild, RBTreeNode<T> parent, NodeColor color)
{
this.data = data; Lchild = lchild; Rchild = rchild; Parent = parent; this.color = color;
}
public RBTreeNode(T data):this(data, null, null, null, NodeColor.RED) { } // 节点默认为红色
public RBTreeNode():this(default, null, null, null, NodeColor.RED) { }
}
class RedBlackTree<T>
{
private RBTreeNode<T> tree;
private IComparer<T> comparer;// 比较器
public RBTreeNode<T> Tree { get => tree; set => tree = value; }
public RBTreeNode<T> CreateTree(T[] _data, IComparer<T> _comparer)
{
tree = null;
comparer = _comparer ?? Comparer<T>.Default;
foreach (T item in _data) {
Insert(item);
}
return tree;
}
public RBTreeNode<T> CreateTree(T[] _data) { return CreateTree(_data, null); }
public RBTreeNode<T> Search(RBTreeNode<T> _node, T _data)
{
if (_node == null) { return null; }
if (comparer.Compare(_node.Data, _data) == 0) { return _node; }
else if (comparer.Compare(_node.Data, _data) > 0) { return Search(_node.Lchild, _data); }
else { return Search (_node.Rchild, _data); }
}
public void Insert(T _data)
{ // 插入,根节点
if (this.tree == null) {
this.tree = new RBTreeNode<T>(_data);
this.tree.Color = RBTreeNode<T>.NodeColor.BLACK; // 空树,把根节点染为黑色
return;
}
this.tree = Insert(this.tree, _data);
}
public RBTreeNode<T> Insert(RBTreeNode<T> _node, T _data)
{ // 插入,子节点
if (comparer.Compare(_node.Data, _data) > 0) {// 插入左子树
if (_node.Lchild == null) {
_node.Lchild = new RBTreeNode<T>(_data);
_node.Lchild.Parent = _node;
} else {
Insert(_node.Lchild, _data);
}
} else {// 插入右子树
if (_node.Rchild == null) {
_node.Rchild = new RBTreeNode<T>(_data);
_node.Rchild.Parent = _node;
} else {
Insert(_node.Rchild, _data);
}
}
// 上溢
if (_node.Parent == null)
{ // 根节点直接染黑
_node.Color = RBTreeNode<T>.NodeColor.BLACK;
}
else
{ // 非根节点
if (_node.Color == RBTreeNode<T>.NodeColor.RED &&
((_node.Lchild != null && _node.Lchild.Color == RBTreeNode<T>.NodeColor.RED) ||
(_node.Rchild != null && _node.Rchild.Color == RBTreeNode<T>.NodeColor.RED)))
{ // 父节点为红,插入节点为红
if (_node.Parent.Lchild != null &&
_node.Parent.Rchild != null &&
_node.Parent.Lchild.Color == RBTreeNode<T>.NodeColor.RED &&
_node.Parent.Rchild.Color == RBTreeNode<T>.NodeColor.RED)
{ // 父节点、叔节点全红
_node.Parent.Lchild.Color = RBTreeNode<T>.NodeColor.BLACK; // 父节点、叔节点染黑
_node.Parent.Rchild.Color = RBTreeNode<T>.NodeColor.BLACK;
_node.Parent.Color = RBTreeNode<T>.NodeColor.RED; // 祖父节点染红
}
}
}
// 非上溢
// 父节点、叔节点为一红一黑/空(从祖父节点进行判断,方便旋转)
if (_node.Lchild != null && _node.Lchild.Color == RBTreeNode<T>.NodeColor.RED &&
_node.Lchild.Lchild != null && _node.Lchild.Lchild.Color == RBTreeNode<T>.NodeColor.RED)
{ // LL
_node.Color = RBTreeNode<T>.NodeColor.RED;
_node.Lchild.Color = RBTreeNode<T>.NodeColor.BLACK;
_node = RightRotate(_node);
}
else if (_node.Lchild != null && _node.Lchild.Color == RBTreeNode<T>.NodeColor.RED &&
_node.Lchild.Rchild != null && _node.Lchild.Rchild.Color == RBTreeNode<T>.NodeColor.RED)
{ // LR
_node.Color = RBTreeNode<T>.NodeColor.RED;
_node.Lchild.Rchild.Color = RBTreeNode<T>.NodeColor.BLACK;
_node.Lchild = LeftRotate(_node.Lchild);
_node = RightRotate(_node);
}
else if (_node.Rchild != null && _node.Rchild.Color == RBTreeNode<T>.NodeColor.RED &&
_node.Rchild.Rchild != null && _node.Rchild.Rchild.Color == RBTreeNode<T>.NodeColor.RED)
{ // RR
_node.Color = RBTreeNode<T>.NodeColor.RED;
_node.Rchild.Color = RBTreeNode<T>.NodeColor.BLACK;
_node = LeftRotate(_node);
}
else if (_node.Rchild != null && _node.Rchild.Color == RBTreeNode<T>.NodeColor.RED &&
_node.Rchild.Lchild != null && _node.Rchild.Lchild.Color == RBTreeNode<T>.NodeColor.RED)
{ // RL
_node.Color = RBTreeNode<T>.NodeColor.RED;
_node.Rchild.Lchild.Color = RBTreeNode<T>.NodeColor.BLACK;
_node.Rchild = RightRotate(_node.Rchild);
_node = LeftRotate(_node);
}
return _node; // 返回最终的根节点
}
public RBTreeNode<T> Delete(RBTreeNode<T> _node, T _data)
{ // 删除
if (_node == null) { return null; }
if (comparer.Compare(_node.Data, _data) == 0)
{ // 用右子树的最左节点替换
if (_node.Rchild == null)
{ // 右子树为空
if (comparer.Compare(_node.Parent.Data, _node.Data) > 0)
{ // 直接用左子树替换
_node.Parent.Lchild = _node.Lchild;
} else {
_node.Parent.Rchild = _node.Lchild;
}
return _node;
}
// 右子树不为空,替换后删除用于替换的节点
RBTreeNode<T> temp = _node.Rchild;
while(temp.Lchild != null) { temp = temp.Lchild; }
_node.Data = temp.Data; // 替换
if (temp.Color == RBTreeNode<T>.NodeColor.RED)
{ // 删除红节点
temp.Parent.Lchild = temp.Rchild; // 用该红节点的右子树直接替换,该右子树一定是黑的
}
else
{ // 删除黑节点(根据性质5,黑色的非根节点一定有兄弟节点)
if (temp.Rchild == null)
{ // 若右子树为空,直接替换
temp.Parent.Lchild = temp.Rchild;
}
else if (temp.Rchild.Color == RBTreeNode<T>.NodeColor.RED)
{ // 若右子树为红,染黑后替换
temp.Rchild.Color = RBTreeNode<T>.NodeColor.BLACK;
temp.Parent.Lchild = temp.Rchild;
}
else
{ // 若右子树为黑,
}
}
return _node;
}
else if (comparer.Compare(_node.Data, _data) > 0)
{ // 查找左子树
if (_node.Lchild != null) { return Delete(_node.Lchild, _data); }
else return null;
}
else
{ // 查找右子树
if (_node.Rchild != null) { return Delete(_node.Rchild, _data); }
else return null;
}
}
private RBTreeNode<T> RightRotate(RBTreeNode<T> _node)
{ // 右旋
if (_node == null) { return null; }
RBTreeNode<T> nodeA = _node; // 失衡节点
RBTreeNode<T> nodeB = _node.Lchild;
RBTreeNode<T> parent = _node.Parent;
if (parent != null)
{ // 节点B右旋到节点A的位置
if (comparer.Compare(parent.Data, nodeA.Data) > 0)
{ // 若nodeA不是根节点,判断nodeA是左子树还是右子树
parent.Lchild = nodeB;
} else { parent.Rchild = nodeB; }
}
nodeB.Parent = parent;
// 原根节点nodeA的左子树用nodeB的右子树填充
nodeA.Lchild = nodeB.Rchild;
if (nodeB.Rchild != null) { nodeB.Rchild.Parent = nodeA; }
// 新根节点nodeB的右子树为原根节点nodeA
nodeB.Rchild = nodeA;
nodeA.Parent = nodeB;
return nodeB;
}
private RBTreeNode<T> LeftRotate(RBTreeNode<T> _node)
{ // 左旋,_node的平衡因子为-2
if (_node == null) { return null; }
RBTreeNode<T> nodeA = _node;
RBTreeNode<T> nodeB = _node.Rchild;
RBTreeNode<T> parent = _node.Parent;
if (parent != null)
{ // nodeB上位
if (comparer.Compare(parent.Data, nodeA.Data) > 0)
{
parent.Lchild = nodeB;
}
else { parent.Rchild = nodeB; }
}
nodeB.Parent = parent;
nodeA.Rchild = nodeB.Lchild;
if (nodeB.Lchild != null) { nodeB.Lchild.Parent = nodeA; }
nodeB.Lchild = nodeA;
nodeA.Parent = nodeB;
return nodeB;
}
public void InTraversal(RBTreeNode<T> _node)
{ // 中序遍历
if (_node == null) return;
InTraversal(_node.Lchild);
Console.Write($"{_node.Data} ");
InTraversal(_node.Rchild);
}
public void LevelTraversal(RBTreeNode<T> _node)
{ // 层次遍历
if (_node != null)
{
Queue<RBTreeNode<T>> q = new Queue<RBTreeNode<T>>(50);
q.Enqueue(_node);
int numOfSun = 0;
while (q.Count != 0)
{
RBTreeNode<T> temp = q.Dequeue(); // 当前节点出队
Console.Write($"{temp.Data}_{temp.Color} ");
if (temp.Lchild != null) { q.Enqueue(temp.Lchild); numOfSun += 1; } // 子节点入队
if (temp.Rchild != null) { q.Enqueue(temp.Rchild); numOfSun += 1; }
if (q.Count == numOfSun)
{// 每行结尾换行
Console.WriteLine();// 队列长度等于下一层的子节点总数时换行(此时父节点全部出队,子节点全部入队)
numOfSun = 0;
}
}
}
}
}
public static void Main(string[] args)
{// 1, 2, 3, 4, 5, 6, 7, 0, -1, -2, -3, -4, -5, -6, -7
RedBlackTree<int> tree = new RedBlackTree<int>();
tree.LevelTraversal(tree.CreateTree(new int[] { 1, 2, 3, 4, 5, 6, 7, 0, -1, -2, -3, -4, -5, -6, -7, 1, 2, 3, 4, 5, 6, 7, 0, -1, -2, -3, -4, -5, -6, -7 }));
Console.WriteLine("\n");
tree.InTraversal(tree.Tree);
Console.WriteLine("\n");
tree.LevelTraversal(tree.Search(tree.Tree, 0));
}
}7.5、多路平衡查找树
7.5.1、B树
B树:一种多路平衡查找树。B树的最大子节点个数称为B树的阶。
m阶B树的性质:
① 一个节点最多有m个子节点(m≥2);
② 一个非根、非叶节点至少有ceil(m/2)个子节点,即至少有ceil(m/2)-1个关键字;
③ 若根节点不是叶节点,则至少有两个子节点;
④ 一个有k个子节点的非叶节点有k-1个关键字;
⑤ 所有的叶节点在同一层,内部不包含任何信息。
(根据①②④得,每个非根/叶子节点含有[ceil(m/2) - 1, m - 1]个关键字。)
B树的度:度即B树中非根/叶节点数量的界限。最小度数即B树中非根/叶节点的子节点树的最小值。例如,一个4阶B树的最小度数为2,即ceil(4/2)。
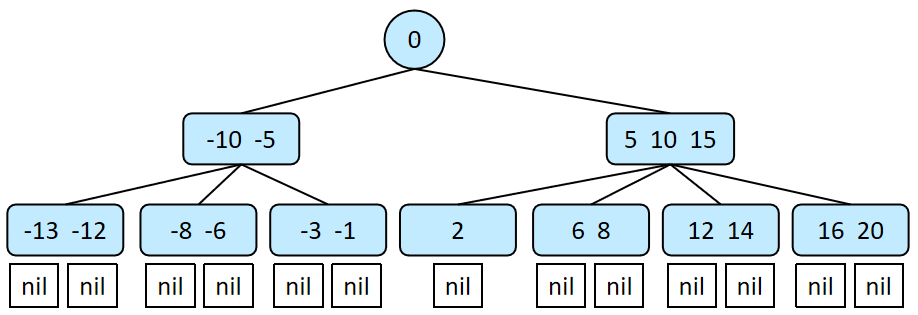
B树的高度:一个有n≥1个关键字的m阶B树,最小度数为t,则其高度h ≤ logt ( (n+1)/2 ) +2。(根节点的高度为1。)
一个m阶最小度数为t的B树,第1层有1个根节点,第2层至少有2个节点,第3层至少有2t个节点,第h层至少有2*t^(h-2)个节点,而每层的非根/叶子节点至少有t-1个键,则高为h的B树至少有1+∑2t^k (k=0,...,h-2)个节点,至少有1+(t-1)∑2t^k (k=0,...,h-2)个键,即h ≤ logt ( (n+1)/2 ) +2。
查找:类似于二叉搜索树。
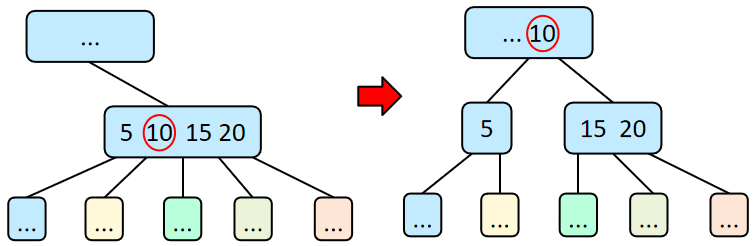
插入:对于一个m阶B树,使用搜索树的方式进行插入,插入后检查关键字的个数是否大于m-1。若关键字的个数大于m-1,分裂该节点。节点的分裂,是将关键字个数大于m-1的节点,以第ceil(m/2)个为分割位置,分割成3个节点,第ceil(m/2)个节点上升与父节点合并,另外两个节点成为新的子节点。若父节点的关键字也大于m-1,继续分割父节点,直至分割根节点。(B树的子节点都是通过分裂产生的。)

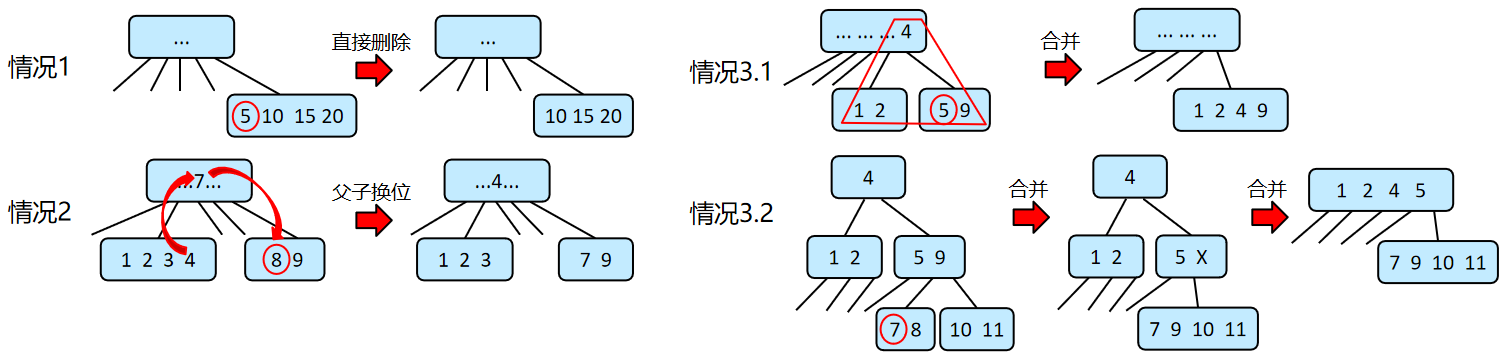
删除:B树的删除与二叉搜索树的删除类似,用被删除元素的前驱/后继元素代替,最终删除的位置是终端节点(叶节点的父节点/末端非叶节点)。而在删除终端节点时,有三种情况:
① 删除后该节点的关键字个数满足>=ceil(m/2),不需要调整;
② 删除后该节点的关键字个数不满足>=ceil(m/2),并且某个兄弟节点的关键字个数满足>=ceil(m/2),需要从兄弟节点借。调整方式为兄弟节点的前驱/后继元素给父节点,父节点中的前驱/后继元素给下一个兄弟节点,直至传递到删除元素的节点;
③ 删除后该节点的关键字个数不满足>=ceil(m/2),并且兄弟节点的关键字个数也不满足,兄弟节点的关键字不够借。此时需要将父节点的关键字向下合并。调整方式为:
(1) 当父节点的关键字个数满足>=ceil(m/2),直接将删除元素的节点、与之相邻的兄弟节点、父节点中索引位置相邻的元素进行合并;
(2) 当父节点的关键字个数不满足>=ceil(m/2),按照(1)的方式进行合并,直至根节点。注意的是,根节点作为父节点的元素进行合并后形成的新节点将作为新的父节点。若根节点的关键字个数 > m-1,则将根节点进行分裂。若根节点+兄弟节点+删除节点的关键字个数 > ceil(m/2) + m - 1个,那么还需要检查新的右子节点的关键字个数是否 > m-1,若是则继续分裂,直至根节点、新的右子节点都满足条件。
下例是一个C#的B树,包括B树节点类、B树类、构建、搜索、插入、删除、遍历。
class Program
{
public class BTreeNode<T>
{
private List<T>? keys;// 关键字
public List<T> Keys { get => keys; set => keys = value; }
private List<BTreeNode<T>>? children;// 子节点指针
public List<BTreeNode<T>> Children { get => children; set => children = value; }
private BTreeNode<T>? parent;// 父节点
public BTreeNode<T>? Parent { get => parent; set => parent = value; }
public BTreeNode() { }
public BTreeNode(T _data) { keys = new List<T>() { _data }; }
public BTreeNode(int _order) { // 构造
keys = new List<T>();
children = new List<BTreeNode<T>>();
}
public BTreeNode(BTreeNode<T> _node) { // 拷贝构造,深拷贝
keys = new List<T>(_node.Keys);
children = new List<BTreeNode<T>>(_node.Children);
parent = _node.Parent;
}
}
public class BTree<T>
{
private int order;// B树的阶
public int t;// 最小度
private IComparer<T> comparer;// 比较器
private BTreeNode<T> root;
public BTreeNode<T> Root { get => root; set => root = value; }
public BTree(int _order, IComparer<T> _comparer)
{ // 构造,B树
root = new BTreeNode<T>();
order = _order; t = order / 2 + order % 2;
comparer = _comparer ?? Comparer<T>.Default;
}
public BTree(int _order) : this(_order, null) { }
public BTreeNode<T> CreateTree(T[] _data)
{
root = null;
foreach (T item in _data) { Insert(item); }
return root;
}
public BTreeNode<T> CreateTree(ICollection<T> _data)
{
root = null;
foreach (T item in _data) { Insert(item); }
return root;
}
public BTreeNode<T> Search(BTreeNode<T> _node, T _data)
{ // 搜索
if (_node == null) return null;
for (int i = 0; i < _node.Keys.Count; i++)
{
if (comparer.Compare(_node.Keys[i], _data) == 0) return _node;
else if (_node.Children.Count != 0)
{
if (comparer.Compare(_node.Keys[i], _data) > 0) return Search(_node.Children[i], _data);
else if (i >= _node.Keys.Count - 1) return Search(_node.Children[i + 1], _data);
}
}
return null;
}
public void Insert(T _data)
{ // 根节点
if (root == null)
{
root = new BTreeNode<T>(order);
root.Keys.Add(_data);
root.Keys.Sort(comparer);
return;
}
root = Insert(root, _data);
}
public BTreeNode<T> Insert(BTreeNode<T> _node, T _data)
{ // 非根节点
if (_node.Children.Count == 0)
{ // 没有子节点,直接插入、排序
_node.Keys.Add(_data);
_node.Keys.Sort(comparer);
}
else
{ // 插入子节点
int is_insert = 0;
for (int i = 0; i < _node.Keys.Count; i++)
{
if (comparer.Compare(_node.Keys[i], _data) > 0)
{ // key是递增的,顺序比较,比哪个key小,就插在哪处
Insert(_node.Children[i], _data);
is_insert = 1;
break;
}
}
if (is_insert == 0)
{
Insert(_node.Children[_node.Keys.Count], _data);
}
}
if (_node.Keys.Count > order - 1)
{ // 分裂
return Split(_node);
}
return _node;
}
public BTreeNode<T> Split(BTreeNode<T> _node)
{ // 分裂
int is_return_parent = 0; // 若分裂的节点是根节点,则返回根节点的父节点
if (_node.Parent == null) { _node.Parent = new BTreeNode<T>(order); is_return_parent = 1; }
// 父节点处理
_node.Parent.Keys.Add(_node.Keys[t - 1]);
_node.Parent.Keys.Sort(comparer);
int pos = _node.Parent.Keys.IndexOf(_node.Keys[t - 1]);
_node.Parent.Children.Remove(_node); // 删除需要分裂的子节点
// 新的左子树
BTreeNode<T> broLeft = new BTreeNode<T>(_node); // 从原节点拷贝,并删除ceil(order/2)之后的元素
broLeft.Keys.RemoveRange(t - 1, broLeft.Keys.Count - t + 1);
if (broLeft.Children.Count != 0) {
broLeft.Children.RemoveRange(t, broLeft.Children.Count - t); }
foreach(BTreeNode<T> node in broLeft.Children) {
node.Parent = broLeft; } // 将新的左子树的子节点的父节点指向其,而不是分裂前的节点
// 新的右子树
_node.Keys.RemoveRange(0, t); // 将原节点中多余的元素删除
if (_node.Children.Count != 0) {
_node.Children.RemoveRange(0, t); }
// 在父节点的子节点列表中插入新的节点
_node.Parent.Children.Insert(pos, broLeft);
_node.Parent.Children.Insert(pos + 1, _node);
if (is_return_parent == 0) { return _node; } else { return _node.Parent; }
}
public void Delete(BTreeNode<T> _node, T _data)
{ // 删除(删除找到的第一个)
BTreeNode<T> delNode = Search(_node, _data);
BTreeNode<T> temp;
if (delNode == null) return;
int pos = delNode.Keys.IndexOf(_data); // 要删除的元素的索引
if (delNode.Children.Count == 0)
{
if (delNode.Parent == null) { delNode.Keys.Remove(_data); return; } // 只有父节点
else { temp = delNode; }
}
else
{ // 查找后继元素(后继元素必是终端元素)
temp = delNode.Children[pos + 1]; // 后继元素所在节点(需要被删除的元素所在节点)
_data = temp.Keys[0]; // 后继元素(临时)
while (temp.Children.Count != 0)
{
temp = temp.Children[0];
_data = temp.Keys[0];
}
}
delNode.Keys[pos] = _data; // 后继元素替代
temp.Keys.Remove(_data); // 删除后继元素
// 调整
if (temp.Keys.Count >= t - 1)
{ // 若(删除前)终端节点的关键字个数 >= 最小度数(直接删除)
return;
} else
{
int bro_pos = -1; // 兄弟节点的索引,关键字个数>=最小度数的兄弟节点
int del_pos = temp.Parent.Children.IndexOf(temp); // 删除元素的节点的索引
for (int i = 0; i < temp.Parent.Children.Count; i++)
{ // 兄弟节点及其索引
if (temp.Parent.Children[i].Keys.Count >= t) { bro_pos = i; break; }
}
if (bro_pos >= 0)
{ // 存在兄弟节点的关键字个数 >= 最小度数(父子换位)
if (bro_pos < del_pos)
{ // 兄弟节点在右边
for (int j = del_pos; j > bro_pos; j--)
{ // 兄弟节点的最后一个元素向左
temp.Parent.Children[j].Keys.Insert(0, temp.Parent.Keys[j - 1]);
temp.Parent.Keys.RemoveAt(j - 1);
T last = temp.Parent.Children[j - 1].Keys.Last();
temp.Parent.Keys.Insert(j - 1, last);
temp.Parent.Children[j - 1].Keys.Remove(last);
}
}
else
{ // 兄弟节点在左边
for (int j = del_pos; j < bro_pos; j++)
{ // 兄弟节点的第一个元素向右
temp.Parent.Children[j].Keys.Add(temp.Parent.Keys[j]);
temp.Parent.Keys.RemoveAt(j);
temp.Parent.Keys.Insert(j, temp.Parent.Children[j + 1].Keys[0]);
temp.Parent.Children[j + 1].Keys.RemoveAt(0);
}
}
return;
}
else
{ // 不存在兄弟节点的关键字个数>=最小度数(父子合并)
do {
Merge(temp);
temp = temp.Parent;
} while (temp.Keys.Count < t - 1);
return;
}
}
}
private void Merge(BTreeNode<T> _node)
{ // 合并(删除的节点、兄弟节点、父节点中元素)
if(_node.Parent.Parent == null)
{ // 根节点
List<T> newKey = new();
List<BTreeNode<T>> newChildren = new();
for (int i = 0; i < _node.Parent.Children.Count; i++)
{ // 合并关键字
for (int j = 0; j < _node.Parent.Children[i].Keys.Count; j++)
{
newKey.Add(_node.Parent.Children[i].Keys[j]);
}
if (i < _node.Parent.Keys.Count) newKey.Add(_node.Parent.Keys[i]);
// 合并子节点
newChildren.AddRange(_node.Parent.Children[i].Children);
}
foreach (BTreeNode<T> node in newChildren) { node.Parent = _node.Parent; } // 指向新的父节点
_node.Parent.Keys = newKey;
_node.Parent.Children = newChildren;
if (root.Keys.Count > order - 1)
{ // 根节点的关键字个数大于order-1,则分裂
do
{
root = Split(root);
if (root.Children.Last().Keys.Count > order - 1) { Split(root.Children.Last()); }
} while (root.Keys.Count > order - 1);
}
return;
}
else
{ // 非根节点
int del_pos = _node.Parent.Children.IndexOf(_node); // 删除元素的节点的索引
int parent_pos; // 用于合并的父节点的元素的索引
int merge_pos; // 用于合并的子节点的索引
if (del_pos >= _node.Parent.Keys.Count) { parent_pos = del_pos - 1; merge_pos = del_pos - 1; }
else { parent_pos = del_pos; merge_pos = del_pos; }
_node.Parent.Children[merge_pos].Keys.Add(_node.Parent.Keys[parent_pos]); // 父节点的元素向下合并
_node.Parent.Keys.RemoveAt(parent_pos);
_node.Parent.Children[merge_pos].Keys.AddRange(_node.Parent.Children[merge_pos + 1].Keys); // 合并兄弟节点的元素
_node.Parent.Children.RemoveAt(merge_pos + 1); // 删除合并后的兄弟元素
return;
}
}
public void LevelTraversal(BTreeNode<T> _node)
{ // 层次遍历
if (_node != null)
{
Queue<BTreeNode<T>> q = new Queue<BTreeNode<T>>();
q.Enqueue(_node);
int numOfSun = 0;
List<int> numOfChildren = new(); // 每个父节点的子节点个数
int numOfWrite = 0; // 打印子节点次数
while (q.Count != 0)
{
BTreeNode<T> temp = q.Dequeue(); // 当前节点出队
for (int i = 0; i < temp.Children.Count; i++) { Console.Write($" "); }
foreach(T item in temp.Keys) { Console.Write($"{item} "); }
Console.Write("| ");
if (temp.Children != null)
{ // 子节点入队
foreach(BTreeNode<T> item in temp.Children)
{
q.Enqueue(item); numOfSun++;
}
}
numOfChildren.Add(temp.Children.Count);
if (numOfWrite == numOfChildren[0]) // 打印次数 = 子节点个数
{ // 每个父节点的所有子节点打印完后,打印分隔符
Console.Write("▊| ");
numOfWrite = 0;
numOfChildren.RemoveAt(0);
}
numOfWrite++;
if (q.Count == numOfSun)
{ // 每行结尾换行
Console.Write("\n");// 队列长度等于下一层的子节点总数时换行(此时父节点全部出队,子节点全部入队)
numOfSun = 0;
}
}
}
}
public void InTraversal(BTreeNode<T> _node)
{ // 中序遍历
if (_node == null) return;
for (int i = 0; i < _node.Keys.Count; i++)
{
if (_node.Children.Count != 0) InTraversal(_node.Children[i]);
Console.Write($"{_node.Keys[i]} ");
if (_node.Children.Count != 0 && i >= _node.Keys.Count - 1) InTraversal(_node.Children[i + 1]); // 最后一个key时,遍历最后一个child
}
return;
}
}
public static void Main()
{// 1, 2, 3, 4, 5, 6, 7, 0, -1, -2, -3, -4, -5, -6, -7
BTree<int> tree = new BTree<int>(4);
tree.CreateTree(new int[] { 1, 2, 3, 4, 5, 6, 7, 0, -1, -2, -3, -4, -5, -6, -7 });
tree.LevelTraversal(tree.Root);
Console.WriteLine("\n");
int[] nums = { 8, 9, -1, 0, -8, -9, -10, -11 };
foreach (int i in nums) { tree.Insert(tree.Root, i); }
tree.LevelTraversal(tree.Root);
tree.InTraversal(tree.Root);
Console.WriteLine("\n");
tree.LevelTraversal(tree.Search(tree.Root, 4));
Console.WriteLine("\n");
int[] dels = { 5, 6, 3, 0, 2, 4 };
foreach(int i in dels)
{
Console.WriteLine($"Delete: {i}");
tree.Delete(tree.Root, i);
tree.LevelTraversal(tree.Root);
tree.InTraversal(tree.Root);
Console.WriteLine("\n");
}
}
}7.5.2、B+树
B+树:B树变体,多路平衡查找树。
m阶B+树的性质:① 一个节点最多有m个子节点(m≥2);② 一个非根/非叶节点至少有ceil(m/2)个子节点;③ 根节点至少有2个子节点;④ B+树中的非叶子节点只存储索引,只存储下级子节点的关键字的最值;⑤ 叶节点存储数据,并通过链表连接起来,便于查找;⑥ 非叶节点的子节点数与关键字数相同。
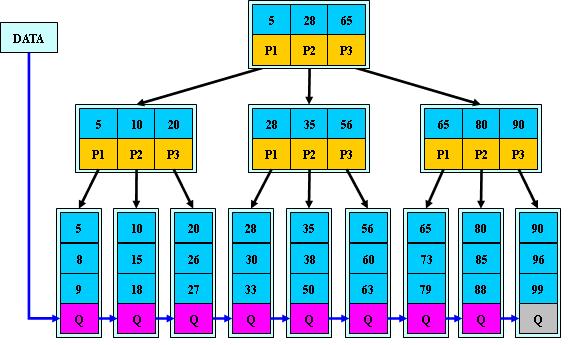
B+树与B树的区别:① 子节点树与关键字树相同;② 叶节点存储全部数据,并通过链表连接;③ 非叶节点只存储索引、子节点中关键字的最值。
B+树的优势:B+树的内部结点不存储数据,因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
查找:与二叉搜索树类似。
插入:与B树类似。分裂:将ceil(m/2)-1个元素分配到一个新子节点,在父节点中增加指针,指向新子节点。
删除:与B树类似。从节点中删除该元素,若该节点不合法,则需要调整。情况1:兄弟节点有多余的元素,则进行父子替换。情况2:兄弟节点没有多余的元素,则父子合并,直至根节点。
7.5.3、B*树
B*树:B+树变体,多路平衡查找树。
m阶B*树的性质:① 非根/非叶节点中增加了指向兄弟节点的指针;② 一个非根/非叶节点至少有ceil(2m/3)个子节点。
B*树的优势:节点的最低空间使用率为2/3,分配新结点的概率比B+树要低。
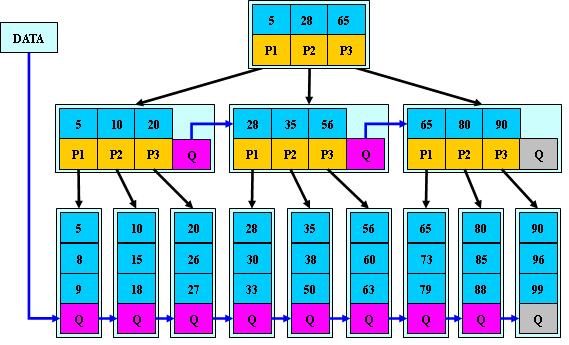
插入:与B树类似。分裂:若兄弟节点未满,则将多余的元素转移到兄弟节点中,再修改父节点中兄弟节点的关键字。若兄弟节点已满,则在原节点与兄弟节点之间新增节点,将原节点、兄弟节点中的ceil(m/3)个元素转移到新节点中,再在父节点中新增关键字、指针。
7.6、空间搜索树 R树
R-trees: a dynamic index structure for spatial searching:https://dl.acm.org/doi/pdf/10.1145/971697.602266
在处理多维的空间数据对象(非0面积)时,利用精确的值匹配的结构(哈希表)是不适用的,因为需要范围搜索;利用键进行一维排序的结构也是不适用(B树)的,因为搜索空间是多维的。而在设计用于处理多为问题的结构中,Cell方法不适用于动态结构,因为cell边界要提前定义;Quad树、k-d树未考虑到辅助内存分页;K-D-B树考虑了内存分页,但只用于点数据;Comer stitching可用于2维非0面积对象 搜索,但是需要同质主存储器,并且大容量下随机搜索性能差;Grid files将非点数据映射为高维空间的一个点。
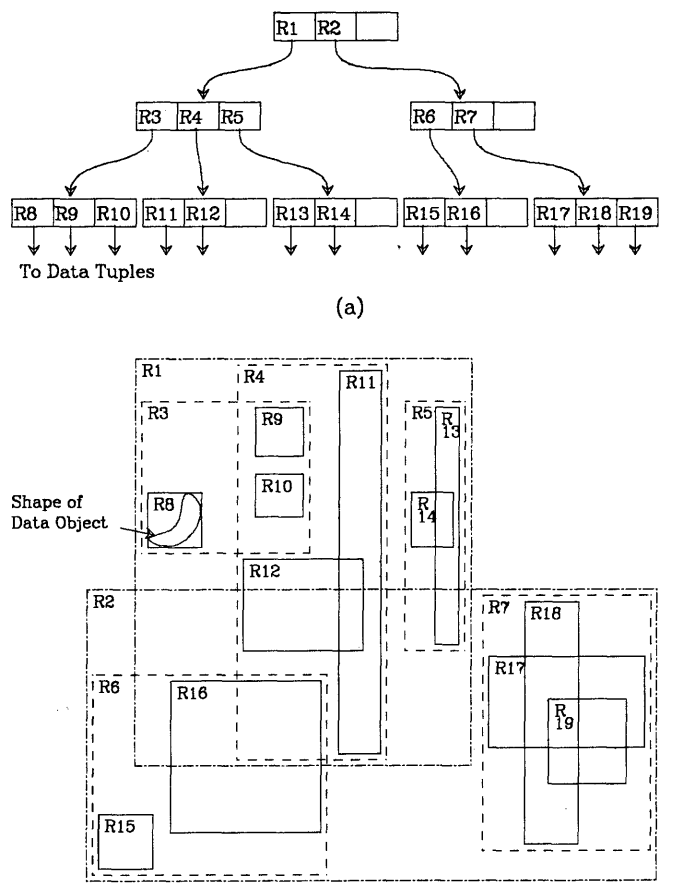
R树:用于空间搜索的动态索引结构,是B树在高维空间的扩展,是一棵高度平衡树。索引是动态的,可以搜索的同时插入、删除,并且没有周期性的重组织。空间数据是以数组形式存储的,并包含一个指针。
叶节点:(I, 数组标识)。其中,数组标识指向数据库中的数组;I是n维矩形,是被索引对象的空间边界框。I =(I0, I1, ..., In-1),其中n是维度,Ii是维度i的闭区间[a, b]范围。例如当n=2时,l0是长的坐标范围[a, b],l1是宽的坐标范围[A, B]。

非叶节点:(I, 子指针)。其中,子指针就是R树中低一级的节点;I覆盖了低一级节点中的所有矩形。以地图为例,有一个节点是上海,子指针就是指向每个区的指针,I就是可以覆盖整个上海市的最小矩形(必然覆盖子节点中每个区)。由于真实空间不太可能是一个矩形,而且存在不规则边界,因此覆盖这些对象的矩形I存在重叠。(overlapping relationships that can exist between its rectangles. )

阶数:一个节点最大条目数M。
最小度数:一个节点最小条目数m ≤ M/2。m=floor(M/2)。
一个含有N个元素的R树至多有ceil(logm(N))-1层,因为分支因子是m。最大的节点个数是ceil(N/m)+ceil(N/M^2)+...+1。空间利用率最差时,节点的空间率用来是m/M。
如果节点含有3或4个以上元素,那么树会很广,大部分空间会被用于存储索引。
R树的性质:
① 每个非根的叶节点包含m~M个元素;
② 对于叶节点中的每一条索引(I, 数组标识),I是包含了特定数组的n维空间数据的最小矩形;
③ 每个非根的非叶节点包含m~M个元素;
④ 对于非叶节点中的每一条索引(I, 子指针),I是包含了子节点中所有矩形的最小矩形;
⑤ 根节点至少包含2个节点,除非没有子节点;
⑥ 所有的叶节点在同一层。
搜索:
R树的搜索与B树相似,但是可能会搜索一个节点下的多个子节点。给定一个搜索矩形S,在R树的根节点T中搜索所有覆盖S的索引。
① 搜索子树:T不是叶节点,检查每个子节点的I是否覆盖S。继续搜索所有的覆盖S的子树。
② 搜索叶节点:检查所有的元素是否与S重叠,若是则该元素符合。
插入:
R树的插入与B树相似,新元素E加入叶节点,叶节点满了则分裂,分裂在整个树中传递。
(1) 选择叶节点:用于决定插入位置。
① 若是叶节点,直接返回;
② 若非叶节点,选择需要最小的放大就能包括新元素E并且面积最小的子节点;迭代该过程。
(2) 插入:若叶节点有剩余空间(元素个数小于M),则直接插入,否则分裂节点。
(3) 调整树:从叶节点上升到根节点,调整矩形I,并进行必要的分裂。
① 若当前节点是根节点,结束;
② 调整当前节点在父节点中的矩形I,使之可以正好覆盖当前节点中的所有矩形;
③ 若在当前节点有一个新分裂的兄弟节点,则需要将其加入到父节点的索引中。若父节点有空间,则直接接入;否则,对父节点执行分裂;迭代该过程。
(4) 调整树高:若分裂传递到根节点,则新建一个根节点,其子节点是分裂后产生的两个节点。
节点分裂:
节点分裂应该减少新节点在后续搜索中被检查的可能性。由于节点是否被检查取决于矩形I是否与搜索区域有重叠,因此,分裂后的两个节点的总面积应该最小。
二次分割:该方法不保证找到最小的总面积,消耗是M的平方、维度的线性。首先在M+1个元素中找到两个元素作为两个新节点的第一个元素,这两个元素放在一个节点里的话最耗费资源,即覆盖这两个元素的矩形面积减去这两个元素的面积是最大的。一次分配一个剩余元素给一个集合。每次分配时,都要计算剩余的每个元素分配到两个集合所需扩展的面积,将使得这两个集合差异最大的那一个元素分配给对应集合。
(1) 获取每组的第一个元素:PickSeed:① 计算将两个元素分为一组的低效率:得到覆盖某两个元素E1和E2的最小矩形J,计算空白面积d = J-E1-E2;② 选择最浪费的一对:空白面积d最大的一对最浪费。
(2) 结束判断:若所有元素被分配,则停止;若某一组元素数量过少,其元素个数+未分配的个数=m,则将剩余元素全部分配,停止;
(3) 选择分配的元素:被分配的元素要满足分配到某一组时,该组所需扩展的面积最小。若扩展面积一样,优先分配给面积小的,其次是元素个数少的。PickNext:① 计算剩余的待分配元素所需的扩展面积,分别是d1和d2;② 选择d1和d2差值最大元素,分配给d值较小的那一组。
线性分割:消耗是M的线性、维度的线性。线性分割与二次分割完全一致,区别在于PickSeed。
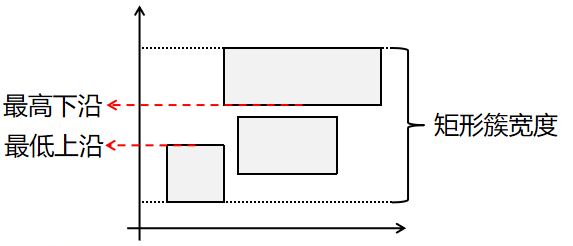
LinearPickSeed:① 找到每个维度上最极端的矩形:对于每个维度,找到最高下沿的矩形和最低上沿的矩形,记录差值;② 调整矩形簇形状:将差值除以矩形簇在对应维度上的宽度来均一化;③ 选择最极端的一对:选择每个维度上均一化差值最大的一对,作为两组的第一个元素。
删除:
(1) 找到包含某元素E的节点:若未找到,则停止。
① 当前节点非叶节点,遍历其子节点找到覆盖E.I的子节点。对子节点继续执行查找;
② 当前节点是叶节点,遍历该叶节点找到匹配E的元素并返回该节点。
(2) 从找到的节点中,删除元素E。
(3) 压缩树:当前节点被删除一个元素后,若元素个数过少,需要将其中的元素迁移,并缩小相应的矩形I。该过程必要时,须传递到根节点。
① 当前节点非根节点,若元素个数小于m,则从父节点中删除该节点的索引,并将该节点加入一个空集合Q;
② 若当前节点没有被删除,缩小矩形I,使之紧凑包含各子节点;向上迭代过程①②;
③ 当前节点是根节点,重新插入集合Q中各个节点的元素,若叶节点中的元素则插入叶节点,高层节点中的元素(比叶节点高的),则插入对应的高层。
更新:
若一个数据数组被修改了,需要删除该元素,并重新插入。
8、图
8.1、基本概念
图论是离散数学的一个分支,通过对象和对象间的关系来描述事物,即顶点和边。图论中只有顶点、边,图是这些顶点和边组成的一个抽象网格。图中可以没有边,但必须有顶点。图中的边可以有方向,称为有向图;也可以没有方向,称为无向图。
边的权重:每条边对应的一个度量,例如距离、长度。
自环边:起点和终点是同一个顶点的边。平行边:起点和终点相同的一组边。
图的同构:若图的顶点的意义不变,边代表的逻辑关系也没变,改变顶点的位置或边的粗细,都无法改变图的本质,都是同一张图。
图的连通性:无向图中,若两个顶点之间有边相连,则是连通的。有向图中,若两个顶点之间有边相连,且都是双向的,则是连通的。
简单图:没有自环边和平行边的图。
完全图:简单的无向图,任意两个顶点之间都有边相连。
通路:若两个顶点通过一系列顶点、边可以相连,那么这两个顶点是连通的。这一系列顶点、边的集合称为通路。
路径:没有重复顶点的通路。迹:没有重复边的通路。
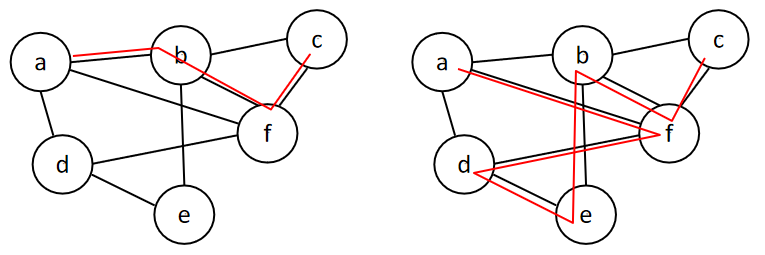
连通图:图中的任意两点都是连通的。连通分量:图中的最大的、连通的子图。
8.2、图的表示
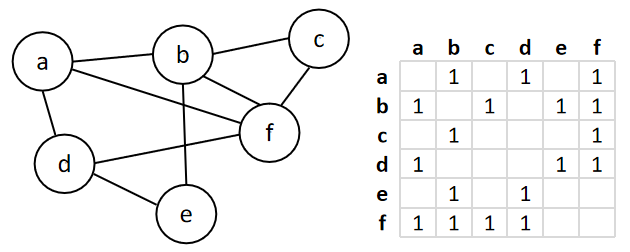
邻接矩阵:在矩阵中以元素索引位置表示连接关系,0或1表示是否连通,行/列表示方向。适用于稠密图(Dense Graph)。
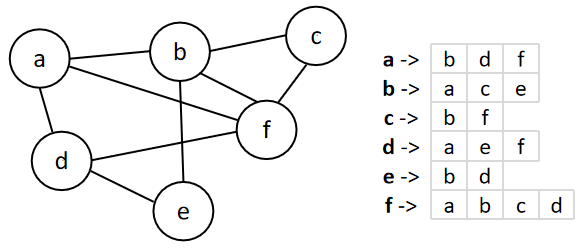
邻接表:表示顶点以及与之相连通的顶点的列表。适用于稀疏图(Sparse Graph)。
8.3、图的操作
图的操作包括:增加顶点、增加边、遍历邻边、遍历、拓扑排序。
图遍历的可视化:图的遍历(深度/广度优先搜索) - VisuAlgo
遍历邻边:邻接矩阵通过遍历顶点所在行;邻接表可直接获得。
遍历:分为深度优先搜索(Depth First Search)和广度优先搜索(Breadth First Search)。
深度优先遍历:DFS,从图的某一顶点开始,访问其某一邻接顶点,重复该过程,直至没有未访问的顶点。返回上一顶点,若有未访问的其他邻接顶点,则重复上一步骤,否则再返回上一顶点,直至图中的所有顶点都被访问。
广度优先遍历:BFS,从图的某一顶点开始,访问其全部邻接顶点,再从某一邻接顶点开始,重复上一步骤,直至图中的所有顶点都被访问。
入度:In-degree,有向图中某个顶点作为边的终点的次数,即可以由相邻顶点进入的次数。
拓扑排序:Top-Sort,对一个有向无环图(DAG)中的顶点进行排序,使得对于任意u->v的边,顶点u在v之前。当有多个深度为0的顶点时,可任选一个顶点,因此拓扑排序的结果不唯一。
拓扑排序-卡恩算法:找到一个入度为0的顶点并输出,删除该顶点及相应的边,即相邻顶点的入度减1,若还有剩余的顶点则重复上述步骤。
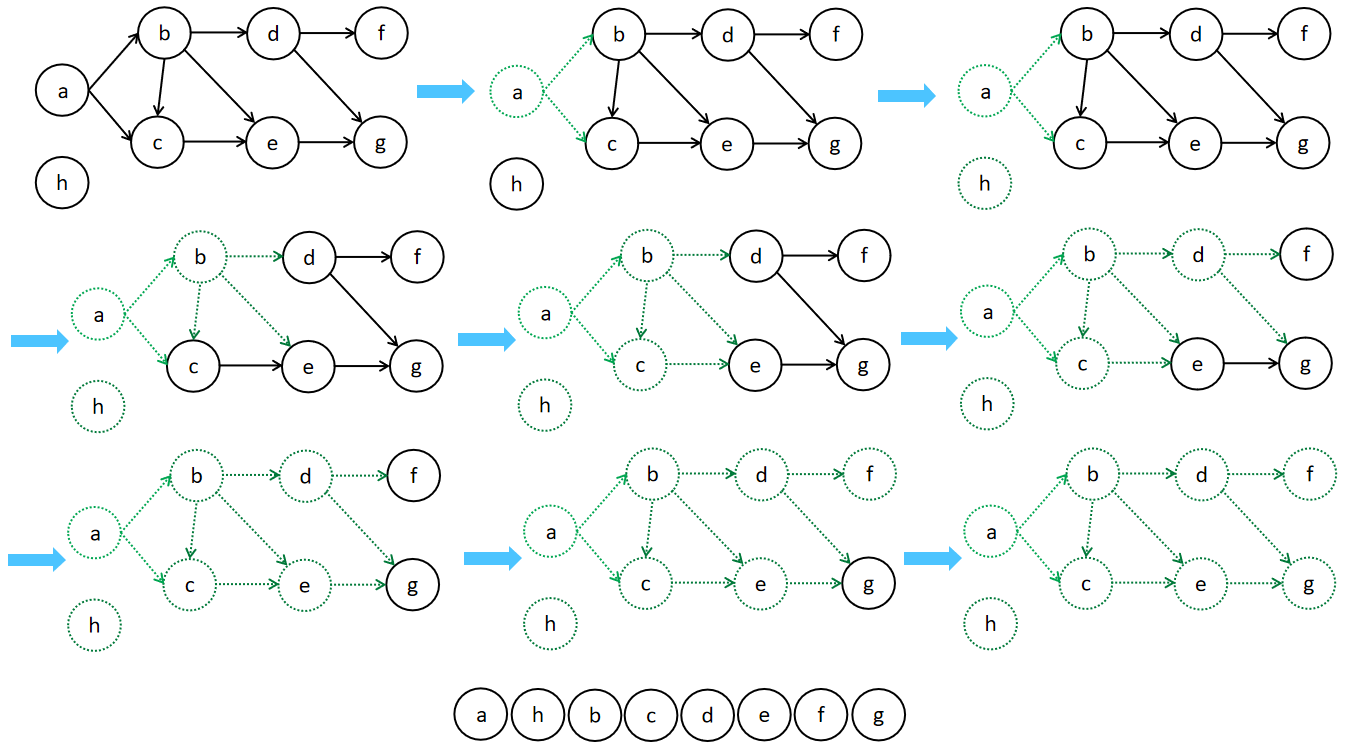
以下分布是用邻接矩阵、邻接表表示的图,以及对无向图(邻接矩阵)的遍历、有向图DAG(邻接表)的拓扑排序。
class program
{
public class Vertex<T>
{ // 顶点
private T data;
public T Data { get => data; set => data = value; }
public Vertex(T v) { data = v; }
public override string ToString()
{
return Data.ToString();
}
}
public class DenseGrapg<T>
{ // 稠密图(邻接矩阵)
private List<Vertex<T>> vertexes; // 顶点
public List<Vertex<T>> Vertexes { get => vertexes; }
public int VertexCount { get => vertexes.Count; } // 顶点个数
private List<List<int>> matrix; // 邻接矩阵(二维数组表示)
public List<List<int>> Matrix { get => matrix; }
public DenseGrapg(List<Vertex<T>> v, List<List<int>> m) { // 构造
vertexes = v;
matrix = m;
}
public DenseGrapg():this(new List<Vertex<T>>(), new List<List<int>>()) { }
public void AddVertex(Vertex<T> vertex)
{ // 添加顶点
vertexes.Add(vertex);
}
public void AddEdge(int start, int end)
{ // 添加边
if (start < 0 || start >= vertexes.Count) { throw new ArgumentOutOfRangeException($"{start} out of range"); }
if (end < 0 || end >= vertexes.Count) { throw new ArgumentOutOfRangeException($"{end} out of range"); }
matrix[start][end] = 1;
}
public List<Vertex<T>> TraversalAdj(Vertex<T> vertex)
{ // 遍历邻边(返回所有的相邻顶点)
List<Vertex<T>> adj = new List<Vertex<T>>();
int index = vertexes.IndexOf(vertex);
for (int i = 0; i < VertexCount; i++) {
if (1 == Matrix[index][i]) { adj.Add(vertexes[i]); }
}
return adj;
}
public List<Vertex<T>> DFS(Vertex<T> vertex)
{ // 深度优先搜索
List<Vertex<T>> result = new List<Vertex<T>>();
Stack<Vertex<T>> stack = new Stack<Vertex<T>>();
List<int> visited = new List<int>(VertexCount) { };
for (int i = 0; i < VertexCount; i++) { visited.Add(0); }
stack.Push(vertex);
while(stack.Count > 0)
{
//Console.WriteLine(String.Join(", ", stack));
vertex = stack.Pop(); // 出栈
if (visited[Vertexes.IndexOf(vertex)] == 0)
{
result.Add(vertex);
visited[Vertexes.IndexOf(vertex)] = 1; // 已访问
foreach (Vertex<T> v in TraversalAdj(vertex))
{ // 入栈,未被访问过的邻接顶点全部入栈(Vertexes的逆序)
if (visited[Vertexes.IndexOf(v)] == 0 && !stack.Contains(v)) { stack.Push(v); }
}
}
}
return result;
}
public List<Vertex<T>> BFS(Vertex<T> vertex)
{ // 广度优先搜索
List<Vertex<T>> result = new List<Vertex<T>>();
Queue<Vertex<T>> queue = new Queue<Vertex<T>>();
List<int> visited = new List<int>(VertexCount) { };
for (int i = 0; i < VertexCount; i++) { visited.Add(0); }
queue.Enqueue(vertex);
while(queue.Count > 0)
{ // 出队
vertex = queue.Dequeue();
if (visited[Vertexes.IndexOf(vertex)] == 0)
{
result.Add(vertex);
visited[Vertexes.IndexOf(vertex)] = 1; // 已访问
foreach (Vertex<T> v in TraversalAdj(vertex))
{ // 入队
if (visited[Vertexes.IndexOf(v)] == 0 && !queue.Contains(v)) { queue.Enqueue(v); }
}
}
}
return result;
}
}
public class SparseGraph<T>
{ // 稀疏图(邻接表)
private List<Vertex<T>> vertexes; // 顶点
public List<Vertex<T>> Vertexes { get => vertexes; }
public int VertexCount { get => vertexes.Count; } // 顶点个数
private Dictionary<Vertex<T>, List<Vertex<T>>> adjList; // 邻接表(字典表示{顶点: List[邻接顶点]})
public Dictionary<Vertex<T>, List<Vertex<T>>> AdjList { get => adjList; }
public SparseGraph(List<Vertex<T>> vertexes, Dictionary<Vertex<T>, List<Vertex<T>>> adjList)
{ // 构造
this.vertexes = vertexes;
this.adjList = adjList;
}
public SparseGraph(): this(new List<Vertex<T>>(), new Dictionary<Vertex<T>, List<Vertex<T>>>()) { }
public void AddVertex(Vertex<T> vertex)
{ // 添加顶点
vertexes.Add(vertex);
}
public void AddEdge(Vertex<T> start, Vertex<T> end)
{ // 添加边
if (-1 == vertexes.IndexOf(start) || -1 == vertexes.IndexOf(end)) { throw new ArgumentException(); }
if (!adjList.ContainsKey(start)) { adjList.Add(start, new List<Vertex<T>>()); }
if (!adjList[start].Contains(end)) { adjList[start].Add(end); }
else { throw new Exception("Edge Already Exists"); }
}
public Dictionary<Vertex<T>, int> GetIndegree()
{ // 获取顶点的入度
Dictionary<Vertex<T>, int> InDegree = new Dictionary<Vertex<T>, int>();
foreach(Vertex<T> vertex in Vertexes)
{
try { InDegree.Add(vertex, 0); } catch (ArgumentException) { }
try
{
foreach (Vertex<T> adjvertex in this.AdjList[vertex])
{
try { InDegree[adjvertex]++; }
catch (KeyNotFoundException) { InDegree.Add(adjvertex, 1); }
}
} catch (KeyNotFoundException) { }
}
return InDegree;
}
public List<Vertex<T>> TopSort()
{ // 拓扑排序,卡恩算法(有向无环图DAG)
List<Vertex<T>> result = new List<Vertex<T>>();
Queue<Vertex<T>> q = new Queue<Vertex<T>>(AdjList.Count);
Dictionary<Vertex<T>, int> inDegree = this.GetIndegree(); // 获取顶点的入度
int num = inDegree.Count;
while (num > 0) // 判断完所有顶点则退出循环
{
foreach (KeyValuePair<Vertex<T>, int> vertexInfo in inDegree)
{
if (0 != vertexInfo.Value) { continue; }
q.Enqueue(vertexInfo.Key);
num--;
}
if (q.Count == 0) { throw new Exception("Not a DAG!"); } // 有环则抛出异常
while(q.Count > 0)
{
Vertex<T> vertex = q.Dequeue();
result.Add(vertex); // 输出入度为0的顶点
inDegree[vertex] = -1; // 已输出的顶点的入度标记为-1
if (AdjList.ContainsKey(vertex))
{ // 删除顶点,该顶点的所有邻边顶点的入度减1
foreach (Vertex<T> v in AdjList[vertex])
{
inDegree[v]--;
}
}
}
Console.WriteLine(String.Join(", ", result));
Console.WriteLine(String.Join(", ", inDegree));
}
return result;
}
}
public static void Main(string[] args)
{
Vertex<string> a = new Vertex<string>("a");
Vertex<string> b = new Vertex<string>("b");
Vertex<string> c = new Vertex<string>("c");
Vertex<string> d = new Vertex<string>("d");
Vertex<string> e = new Vertex<string>("e");
Vertex<string> f = new Vertex<string>("f");
Vertex<string> g = new Vertex<string>("g");
Vertex<string> h = new Vertex<string>("h");
// dense graph
DenseGrapg<string> densegraph = new DenseGrapg<string>(
new List<Vertex<string>> { a, b, c, d, e, f, g, h },
new List<List<int>>
{
new List<int>{ 0, 1, 1, 1, 0, 0, 0, 0 },
new List<int>{ 1, 0, 1, 1, 0, 0, 0, 0 },
new List<int>{ 1, 1, 0, 1, 1, 1, 0, 0 },
new List<int>{ 1, 1, 1, 0, 1, 1, 0, 0 },
new List<int>{ 0, 0, 1, 1, 0, 1, 1, 1 },
new List<int>{ 0, 0, 1, 1, 1, 0, 1, 1 },
new List<int>{ 0, 0, 0, 0, 1, 1, 0, 1 },
new List<int>{ 0, 0, 0, 0, 1, 1, 1, 0 }
});
List<Vertex<string>> resultDFS = densegraph.DFS(a);
foreach (Vertex<string> v in resultDFS) { Console.Write($"{v} "); }
Console.WriteLine();
List<Vertex<string>> resultBFS = densegraph.BFS(a);
foreach (Vertex<string> v in resultBFS) { Console.Write($"{v} "); }
// sparse graph
SparseGraph<string> sparsegraph = new SparseGraph<string>(
new List<Vertex<string>> { a, b, c, d, e, f, g, },
new Dictionary<Vertex<string>, List<Vertex<string>>>
{
{ a, new List<Vertex<string>> { b, c, } },
{ b, new List<Vertex<string>> { c, d, e, } },
{ c, new List<Vertex<string>> { e,} },
{ d, new List<Vertex<string>> { f, g} },
}
);
sparsegraph.AddVertex(h);
sparsegraph.AddEdge(e, g);
//foreach (KeyValuePair<Vertex<string>, List<Vertex<string>>> v in sparsegraph.AdjList)
//{ // 打印邻接表
// Console.WriteLine($"{v.Key}: {String.Join(", ", v.Value)}");
//}
//foreach ( KeyValuePair<Vertex<string>, int> v in sparsegraph.GetIndegree())
//{ // 打印入度
// Console.WriteLine($"{v.Key} {v.Value}");
//}
//List<Vertex<string>> res = sparsegraph.TopSort();
//foreach ( Vertex<string> v in res )
//{ // 打印拓扑排序的结果
// Console.Write($"{v} ");
//}
}
}














 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









