







 本文深入探讨浮点数的表示形式,包括浮点数的结构、非规格化和规格化数、IEEE754标准、浮点数的范围、精度和溢出处理。讲解了浮点数的阶码和尾数如何影响其表示范围,以及定点数与浮点数的区别。此外,还讨论了C语言中浮点数类型的转换和精度问题。
本文深入探讨浮点数的表示形式,包括浮点数的结构、非规格化和规格化数、IEEE754标准、浮点数的范围、精度和溢出处理。讲解了浮点数的阶码和尾数如何影响其表示范围,以及定点数与浮点数的区别。此外,还讨论了C语言中浮点数类型的转换和精度问题。
小数的计算机表示
abstract
小数在计算机中有“定点数”和“浮点数”两种表示方法。
本文主要介绍浮点数的表示以及相关标准IEEE754浮点数,以及浮点数的重要特点和内容,包括表示范围,表示精度,规格化以及溢出等问题
并且结合实际的编程语言,查看浮点数的IEEE754二进制位串
- IEEE Floating-Point Representation | Microsoft Learn
- IEEE 浮点表示形式 | Microsoft Learn
- IEEE 754 - Wikipedia
定点数表示法
“定点数”就是规定好了整数部分的位数和小数部分的位数,相当于小数点的位置是固定好的。例如,用一个32位的二进制定点数表示小数,可以事先规定整数部分是左边的16位(高16位),小数部分是右边的16位(低16位)。那么这个二进制数里面就不用包含小数点位置的信息。用定点数表示小数,由于总位数有限,如果要保证整数部分能表示很大范围(如规定整数部分占30位),那么小数部分的精度(即小数点后面的有效数字位数)就会不足;如果希望小数部分的精度很高(如规定小数部分占30位),那么又会导致整数部分能表示的数值范围太小。
定点数使用不便,因此大多数计算机系统中都是用“浮点数”来表示小数。浮点数中包含了小数点位置的信息,小数点的位置是可变的,所以称为“浮点数”。
浮点数表示法
R进制数的科学计数法
我们知道有十进制中的“科学计数法”,即把数表示为 M × 1 0 E M \times 10^E M×10E 形式(规范化(标准化)情况下: − R < M ⩽ − 1 , 1 ⩽ M < R -R<{M}\leqslant -1,1\leqslant M<R −R<M⩽−1,1⩽M<R,借助绝对值不等式可以表示为 1 ⩽ ∣ M ∣ < R 1\leqslant|M|<R 1⩽∣M∣<R。显然,如果是二进制的话,尾数(mantissa)就是 1 ⩽ ∣ M ∣ < 2 1\leqslant|M|<2 1⩽∣M∣<2
然而计算机中的浮点数一般遵循一个共同的标准:尾数使用定点数原码来表示,定点小数的最高位是符号位,那么第一位有效位(数值位)是非0(即1)时,称此时的浮点数是规格化的;这种情况下定点小数的小数点前不能作为数值有效位,而仅表示尾数的正负,结合定点数第一位数值位是1的情况下,可以知道 1 2 ⩽ ∣ M ∣ < 1 \frac{1}{2}\leqslant |M|<1 21⩽∣M∣<1,如果尾数的数值位为 n n n位,那么规格化数的尾数范围为 1 2 ⩽ ∣ M ∣ ⩽ ( 1 − 2 − n ) \frac{1}{2}\leqslant |M|\leqslant(1−2^{-n}) 21⩽∣M∣⩽(1−2−n)
对于一般进制,科学计数法可以表示为 M × R E M\times{R^{E}} M×RE,其中 M , E M,E M,E都是可能是正数,也可能是负数或0,其中 E E E是整数,基数 R R R在一定语境下可以不强调,给定一个默认值,因为它不需要变动,在计算机中 R = 2 R=2 R=2,这是共识而无需强调(任何一个计算机二进制浮点数的基数都是2),最重要的是 M , E M,E M,E
- 例如,1553 可以表示为 1.553 × 1 0 3 1.553 \times 10^3 1.553×103 或 15.53 × 1 0 2 15.53 \times 10^2 15.53×102 ,-0.03 可以表示成 − 3 × 1 0 − 2 -3 \times 10^{-2} −3×10−2 。
由于计算机用二进制表示信息,因此将数表示为 M × 2 E M \times 2^E M×2E 的形式,用计算机处理更加方便。
实际上,计算机中的浮点数就是 M × 2 E M \times 2^E M×2E 形式的数,其中 M 称为尾数,E 称为阶码其中基数 R = 2 R=2 R=2是隐含的(可以事先约定,一般是 R = 2 R=2 R=2,或者约定位其他值),可以省略不强调,可以节约空间
在一合计算机中,尾数 M 和阶码 E 的位数都是规定好的
- M 代表了浮点数的有效数字,其位数越多,浮点数的精度就越高;
- E 确定了浮点数的小数点的位置,E 的位数越多,浮点数能表示的数的范围就越大。
计算机中的一个浮点数,其比特数是固定的,例如一共只有64比特,那么显然该浮点数能表示的数的个数就是有限的。
浮点数所能表示的数的范围是由其所能表示的最大值和最小值决定的,但并不是在此范围内的每个数都能被表示出来。
由于尾数和阶码都可能为负数,因此,浮点数中还应当包含尾数和阶码的符号,即尾符和阶符。
例如,一个64位的浮点数,便可规定其尾数为51位,阶码为11位,剩余两位为尾符和阶符(这个规定会因CPU厂家、型号的不同而不同)。
IEEE 754标准浮点数类型
-
float - 单精度浮点数类型。通常是 IEEE-754 binary32 格式。
-

-
由给定的符号
sign、偏移指数e(8位无符号整数)和23位小数部分fraction组成的32位binary32数据所表示的实数值为:
( − 1 ) b 31 × 2 ( b 30 b 29 … b 23 ) 2 − 127 × ( 1. b 22 b 21 … b 0 ) 2 , (-1)^{b_{31}}\times 2^{(b_{30}b_{29}\dots b_{23})_2 - 127}\times (1.b_{22}b_{21}\dots b_{0})_2, (−1)b31×2(b30b29…b23)2−127×(1.b22b21…b0)2,
或者
v a l u e = ( − 1 ) s i g n × 2 ( E − 127 ) × ( 1 + ∑ i = 1 23 b 23 − i 2 − i ) . \rm value = (-1)^{sign}\times 2^{(E-127)}\times \left(1+\sum_{i=1}^{23}b_{23-i}2^{-i}\right). value=(−1)sign×2(E−127)×(1+i=1∑23b23−i2−i).在这个例子中:
sign= b 31 b_{31} b31 = 0,- ( − 1 ) s i g n (-1)^{sign} (−1)sign = ( − 1 ) 0 (-1)^0 (−1)0 = +1 ∈ { − 1 , + 1 } \in \{-1,+1\} ∈{−1,+1},
- E = ( b 30 b 29 … b 23 ) 2 E=(b_{30}b_{29}\dots b_{23})_2 E=(b30b29…b23)2 = ∑ i = 0 7 b 23 + i 2 i \sum_{i=0}^{7}b_{23+i}2^i ∑i=07b23+i2i =127-3= 124 ∈ { 1 , 2 , ⋯ , 254 } \in\set{1,2,\cdots,254} ∈{1,2,⋯,254},
- 2 ( E − 127 ) 2^{(E-127)} 2(E−127) = 2 124 − 127 2^{124-127} 2124−127 = 2 − 3 2^{-3} 2−3 ∈ { 2 − 126 , … , 2 127 } \in \{2^{-126},\dots,2^{127}\} ∈{2−126,…,2127},
- ( 1. b 22 b 21 … b 0 ) 2 (1.b_{22}b_{21}\dots b_{0})_2 (1.b22b21…b0)2 = 1 + ∑ i = 1 23 b 23 − i 2 − i 1+\sum_{i=1}^{23}b_{23-i}2^{-i} 1+∑i=123b23−i2−i = 1 + 1 ⋅ 2 − 2 1+1\cdot 2^{-2} 1+1⋅2−2 = 1.25 ∈ { 1 , 1 + 2 − 23 , … , 2 − 2 − 23 } \in \{1,1+2^{-23},\dots,2-2^{-23}\} ∈{1,1+2−23,…,2−2−23}.
因此:
- value = (+1) × \times × 2 − 3 2^{-3} 2−3 × \times × 1.25 = +0.15625
-
-
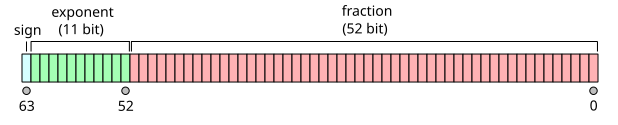
double - 双精度浮点数类型。通常是 IEEE-754 binary64 格式。
-
-
给定具有给定偏移指数 e e e 和52位分数的64位双精度数据所假设的实际值是:
( − 1 ) sign ( 1. b 51 b 50 … b 0 ) 2 × 2 e − 1023 (-1)^{\text{sign}} (1.b_{51} b_{50} \ldots b_0)_2 \times 2^{e-1023} (−1)sign(1.b51b50…b0)2×2e−1023
或
( − 1 ) sign ( 1 + ∑ i = 1 52 b 52 − i 2 − i ) × 2 e − 1023 (-1)^{\text{sign}} \left(1 + \sum_{i=1}^{52} b_{52-i} 2^{-i}\right) \times 2^{e-1023} (−1)sign(1+i=1∑52b52−i2−i)×2e−1023
在 2 52 = 4 , 503 , 599 , 627 , 370 , 496 2^{52}=4,503,599,627,370,496 252=4,503,599,627,370,496 到 2 53 = 9 , 007 , 199 , 254 , 740 , 992 2^{53}=9,007,199,254,740,992 253=9,007,199,254,740,992 之间,可表示的数字正好是整数。对于下一个范围,从 2 53 2^{53} 253 到 2 54 2^{54} 254,所有东西都被乘以2,因此可表示的数字是偶数等。相反地,在前一个范围内,从 2 51 2^{51} 251 到 2 52 2^{52} 252,间距是0.5等。
作为从 2 n 2^n 2n 到 2 n + 1 2^{n+1} 2n+1 范围内数字的分数,间距是 2 n − 52 2^{n-52} 2n−52。当舍入到最接近的可表示的一个数字时(机器误差),最大相对舍入误差是 2 − 53 2^{-53} 2−53。
指数的11位宽度允许表示介于 1 0 − 308 10^{-308} 10−308 和 1 0 308 10^{308} 10308 之间的数字
-
-
long double - 扩展精度浮点数类型。不必映射到 IEEE-754 规定的类型。
一些 HP-UX、SPARC、MIPS、ARM64 和 z/OS 实现使用 IEEE-754 binary128 格式。
最知名的 IEEE-754 binary64 扩展格式是 80 位 x87 扩展精度格式。许多 x86 和 x86-64 实现使用它(一个典型的例外是 MSVC,它将 long double 实现为与 double 相同的格式,即 binary64)。
在 PowerPC 上可以使用 double-double。
The following three types and their cv-qualified versions are collectively called standard floating-point types.
float — single precision floating-point type. Usually IEEE-754 binary32 format.
double — double precision floating-point type. Usually IEEE-754 binary64 format.
long double — extended precision floating-point type. Does not necessarily map to types mandated by IEEE-754.
§ IEEE-754 binary128 format is used by some HP-UX, SPARC, MIPS, ARM64, and z/OS implementations.
§ The most well known IEEE-754 binary64-extended format is x87 80-bit extended precision format. It is used by many x86 and x86-64 implementations (a notable exception is MSVC, which implements long double in the same format as double, i.e. binary64).
§ On PowerPC double-double can be used.
计算机中定点数和浮点数的编码
-
根据小数点的位置是否固定,分为定点数和浮点数
-
定点数采用不同机器数编码(原码/补码/移码)的情况
-
定点数
- 定点补码整数表示整数
-
浮点数
- 浮点数不再使用补码来表示,而是用原码和移码组合表示
- 定点原码小数表示浮点数的尾数(原码小数)
- 移码表示浮点数阶码部分(移码整数)
- 浮点数的常用标准参考IEEE 754标准
- 浮点数不再使用补码来表示,而是用原码和移码组合表示
-
有效位|有效数字
- 有效数字(significant figures,significant digits,简写 sig figs),其代表一个数是由若干位数字组成,其中影响其测量精度的数字被称作有效数字,也称有效数位。
- 有效数字是科学计算中用以表示一定长度浮点数精度的那些数字,一般指一个用小数形式表示的浮点数中,从第一个非零的数字算起的所有数字;
- 例如:1.24和0.00124的有效数字都有3位。并且在取有效数字时一般会遵循四舍五入的进位规则[2]。例如取1.23456789为三位有效数字后的数值将会是1.23,而取四位有效数字后的数值将会是1.235
科学计数法中的尾数和有效数
大多数情况下,使用科学记数法的数也可以使用上述规则判别有效数字。
不过正规化形式的科学记数法没有前缀和后缀的零,所有数字都是有效的。
比如 0.00012 0.00012 0.00012(两位有效数字)会被记作 1.2 × 1 0 − 4 1.2 \times 10^{-4} 1.2×10−4, 0.00122300 0.00122300 0.00122300(六位有效数字)会被记作 1.22300 × 1 0 − 3 1.22300 \times 10^{-3} 1.22300×10−3。后缀零都是有效的,没有歧义。例如 1300 1300 1300 在有四位有效数字时,会被记作 1.300 × 1 0 3 1.300 \times 10^{3} 1.300×103,而如果只有两位有效数字,则会被记作 1.3 × 1 0 3 1.3 \times 10^{3} 1.3×103。
因此,科学记数法中,尾数也被称作有效数。
浮点数表示
- 浮点数表示法是指以适当的形式将比例因子表示在数据中,让小数点的位置根据需要而浮动。
- 这样,在位数有限的情况下,既
扩大了数的表示范围,又保持了数的有效精度。
虽然省略掉基数后,浮点数可以仅由包含符号位的尾数和包含符号的阶码两大部分组成,但是参考IEEE标准,浮点数结构表示为三部分(将尾数的符号位(决定整个浮点数的正负性符号)放到第一位;后面分别跟的是阶码和尾数(浮点数的符号和尾数没有相邻!):
N = ( − 1 ) S × M × R E N = (-1)^S \times M \times R^E N=(−1)S×M×RE
- 式中, S S S 取值 0 或 1,用来决定浮点数的符号;
- M M M 是一个二进制定点小数,称为尾数,一般用定点原码小数表示;
- E E E 是一个二进制定点整数,称为阶码或指数,用移码表示。
- R R R 是基数(隐含),可以约定为 2、4、16 等。
- 可见(IEEE 754标准下)计算机中的浮点数由符号、尾数和阶码共三部分组成。
- 事实上,这种安排也可以理解为尾数的符号位(数符)和阶码的符号(阶符)位放到整个二进制浮点数的头两位,然后接着放阶码的数值部分和尾数的数值部分
浮点数形式小结
- 正如摘要中介绍的那样,一个浮点数可以分为两大部分:阶码;尾数,而基数虽然对于浮点数很重要,但是计算机中一般约定为2,因此可以省略不表达,这样就将注意力放到阶码和尾数上
- 在认识IEEE 754标准前,我们可能会将浮点数分为两大部分:阶码和尾数
- 学习IEEE 754标准后,联系实际应用,浮点数被分成3部分
浮点数三要素
- 浮点数的重点内容:小数点位置,表示范围,精度,这三个要素分别由阶码取值,阶码位数,尾数位数决定
- 对于一个确定的机器,浮点数的精度和表示范围是确定的,而指定的一个数的小数点是有该数的阶码来决定的
- 一般我们希望浮点数的精度高,而且表示范围广,但是在机器字长位数有限的情况下,两个指标是此消彼长的
计算机中二进制规格化浮点数
-
为了进一步规范浮点数(保证尽可能高的精度)提出规格化数(浮点数)
-
尾数数值位最高位是1的浮点数就是规格化数
-
对于基数不同的浮点数,其规格化数的标准有所不同,规格化的过程也有所不同
非标准形式讨论浮点数
-
如果不考虑IEEE 754标准,机器中的浮点数可以直观地描述为如下结构(更符合直觉)
- F = j f ⏟ 阶符 , j 1 ⋯ j m ⏟ 阶码数值部分 ⏞ 阶码 S f ⏟ 数符 . S 1 ⋯ S n ⏟ 尾数的数值部分 ⏞ 尾数 F=\overbrace{ \underbrace{j_f}_{阶符},\underbrace{j_1\cdots{j_m}}_{阶码数值部分} }^{阶码} \overbrace{ \underbrace{S_f}_{数符}.\underbrace{S_1\cdots{S_n}}_{尾数的数值部分} }^{尾数} F=阶符 jf,阶码数值部分 j1⋯jm 阶码数符 Sf.尾数的数值部分 S1⋯Sn 尾数
-
该形式可以看做两大部分:
- 阶码(指数)
j
=
j
f
j
1
⋯
j
m
j=j_fj_1\cdots{j_m}
j=jfj1⋯jm
- j f 是阶符 j_f是阶符 jf是阶符
- 阶码是整数, j f , m j_{f},m jf,m两个数共同反映了浮点数的表示范围和小数点的位置
- 尾数
S
=
S
f
S
1
⋯
S
n
S=S_fS_1\cdots{S_n}
S=SfS1⋯Sn
- S f S_f Sf是数符
- 尾数是纯小数,反映了浮点数的精度,尾数的符号 S f S_f Sf代表了浮点数的正负
- 小数点:
- 尾数是纯小数,其小数点位于 S j S_j Sj和 S 1 S_1 S1之间
- 阶码(指数)
j
=
j
f
j
1
⋯
j
m
j=j_fj_1\cdots{j_m}
j=jfj1⋯jm
IEEE标准中的结构
- 和非标准结构大致类似,但是数符 S f S_f Sf被提前了到浮点数结构的第一部分(参看文末部分)
F = S f ⏟ 数符 j f ⏟ 阶符 , j 1 ⋯ j m ⏟ 阶码数值部分 ⏞ 阶码 S 1 ⋯ S n ⏟ 尾数的数值部分 F= \underbrace{S_f}_{数符} \overbrace { \underbrace{j_f}_{阶符},\underbrace{j_1\cdots{j_m}}_{阶码数值部分} }^{阶码} \underbrace{S_1\cdots{S_n}}_{尾数的数值部分} F=数符 Sf阶符 jf,阶码数值部分 j1⋯jm 阶码尾数的数值部分 S1⋯Sn
一般格式的浮点数的表示范围👺
-
设浮点数
阶码的数值位取m位,尾数的数值位取n位,当浮点数为非规格化数时,它在数轴上的表示范围做如下讨论(这里的范围和IEEE 754的范围不同,同样的位数安排,这里表示的范围更广,但是无法处理一些特殊情况) -
先讨论正数部分的最值(取值范围)
- 其中’ × \times ×’号左边是 2 E 2^{E} 2E,其中阶码 E E E是移码表示法, m m m位数值位的移码最小值( m m m个0)和最大值( n n n个1)对应的真值分别为 − 2 m -2^{m} −2m, 2 m − 1 2^{m}-1 2m−1
- 其中’ × \times ×’号右边的是尾数,它是一个定点原码小数(纯小数),而最小和最大纯小数分别为 2 − n 2^{-n} 2−n, 1 − 2 − n 1-2^{-n} 1−2−n
- 此外,由于尾数是用定点原码表示的,它的范围关于0对称,所以负数区域的取值范围和正数的范围是对称的
-
正数部分取值范围: [ 2 − n × 2 − 2 m , ( 1 − 2 − n ) × 2 2 m − 1 ] [2^{-n}\times{2^{-2^{m}}},(1-2^{-n})\times{2^{2^{m}-1}}] [2−n×2−2m,(1−2−n)×22m−1]
-
负数部分取值范围: [ − ( 1 − 2 − n ) × 2 2 m − 1 , − 2 − n × 2 − 2 m ] [-(1-2^{-n})\times{2^{2^{m}-1}},-2^{-n}\times{2^{-2^{m}}}] [−(1−2−n)×22m−1,−2−n×2−2m]
n位数值位的小数和整数最值
-
下面的讨论是基于真值
-
整数:
- m m m位补码和移码可以表示的真值范围相同,都是 − 2 m ⩽ x ⩽ 2 m − 1 -2^{m}\leqslant{x}\leqslant 2^{m}-1 −2m⩽x⩽2m−1
- 这个范围对应于浮点数阶码的取值范围
-
纯小数 p p p:
-
设 p p p的数值位有 n n n位
-
∣ p ∣ ∈ ( 0 , 1 ) ∣ p ∣ ∈ [ 2 − n , 1 − 2 − n ] − ∣ p ∣ ∈ [ 2 − n − 1 , − 2 − n ] 2 − n = 0. 0 ⋯ 01 ⏟ n − 1 个 0 , 末尾 1 1 − 2 − n = ( 0. 1 ⋯ 11 ⏟ n 个 1 ) 2 = ∑ i = 1 n 2 − i |p|\in(0,1) \\ |p|\in[2^{-n},1-2^{-n}] \\-|p|\in[2^{-n}-1,-2^{-n}] \\\\ \\2^{-n}=0.\underbrace{0\cdots{01}}_{n-1个0,末尾1} \\1-2^{-n}=(0.\underbrace{1\cdots{11}}_{n个1})_2=\sum\limits_{i=1}^{n}2^{-i} ∣p∣∈(0,1)∣p∣∈[2−n,1−2−n]−∣p∣∈[2−n−1,−2−n]2−n=0.n−1个0,末尾1 0⋯011−2−n=(0.n个1 1⋯11)2=i=1∑n2−i
-
浮点数的尾数是用原码纯小数表示的
-
浮点数溢出👺
-
判断浮点数溢出,是通过比较阶码来进行
-
上溢:
- 当浮点数的阶码大于最大阶码时,就是发生上溢,这种情况下机器停止运行,进行中断溢出处理
- 正上溢和负上溢,绝对值都是向无穷大方向发展而发生的
-
下溢:
- 当浮点数阶码小于最小阶码时,称为下溢
- 正下溢和负下溢的绝对值都是向0靠近而发生的
- 虽然浮点数可以取到0,但是,由于精度的限制(尾数位数有限),很接近0但不等于0的数是表示不了的(存在一个类似于盲区的区域)
- 即,在真值落在0的小邻域时,可能发生下溢
- 此时的数绝对值十分小,通常的,将尾数各位强制置为0,按照机器零处理
IEEE 754浮点数的溢出
- 在尾数规格化和尾数舍入时,可能会对结果的阶码执行加减运算。因此,必须考虑指数溢出问题。
- 若一个正指数超过了最大允许值(127或1023),则发生指数上溢,产生异常。
- 若一个负指数超过了最小允许值(-149或-1074),则发生指数下溢,通常把结果按机器零处理。对于非规格化数的情况,当尾数 f f f为0.00…01时,指数的最小允许值为 − 126 − 23 = − 149 -126-23=-149 −126−23=−149(单精度)或 − 1022 − 52 = − 1074 -1022-52=-1074 −1022−52=−1074(双精度)
- 1)右规和尾数舍入。
- 数值很大的尾数舍入时,可能因为末位加1而发生尾数溢出,此时需要通过右规来调整尾数和阶码。
- 右规时阶码加1,导致阶码增大,因此需要判断是否发生了指数上溢。
- 当调整前的阶码为11…10时,加1后,会变成11…11**(阶码全1)而发生指数上溢**。
- 2)左规。
- 左规时阶码减1,导致阶码减小,因此需要判断是否发生了指数下溢。
- 其判断规则与指数上溢类似,左规一次,阶码减1,然后判断阶码是否为全0来确定指数是否下溢。
由此可见,浮点数的溢出并不是以尾数溢出来判断的,尾数溢出可以通过右规操作得到纠正。
运算结果是否溢出主要看结果的指数是否发生了上溢(严重错误),因此是由指数上溢来判断的。(下溢是丢失精度)
规格化数👺
浮点数的规格化
为了在浮点数运算过程中尽可能多地保留有效数字的位数,使有效数字尽量占满尾数位数,必须在运算过程中对浮点数进行规规格化操作。
所谓规格化操作,是指通过调整一个非规范化浮点数的尾数和阶码的大小,使非零浮点数在尾数的最高数位上保证是一个有效值(即1)。
注意,即使两个规格化数进行运算后,结果不一定仍然规格化
为进行规格化操作,必须会判断定的数(补码)是哪一种情况:
- 绝对值太小:需要进行左归(尾数倍增基数,阶码减小)
- 绝对值太大,(伪)溢出:需要进行右归(尾数)
左规(尾数左移)
- 左规:尾数的最高数位不是有效位,即出现±0.0…0×…(x表示非0值,二进制就是1)的形式时,需要进行左规。
- 左规时,尾数每左移一位、阶码减1(基数为2时)。
- 左规可能要进行多次。
- 左规相当于尾数左移,或小数点右移
右归(尾数右移)
- 右规:尾数的有效位进到小数点前面时(例如两个浮点数相加结果尾数产生了进位),需要进行右规
- 将尾数右移一位、阶码加1(基数为2时)。
- 右规只需进行一次。
- 右规时,阶码增加可能导致溢出。
- 右归相当于尾数右移,或小数点左移
基数为2的原码规格化尾数M应满足 1 2 ⩽ ∣ M ∣ < 1 \frac{1}{2}\leqslant|M|<1 21⩽∣M∣<1,形式如下:
- 正数为0.1×…的形式,最大值为0.11…1,最小值为0.100…0,表示范围为 1 2 ⩽ M ⩽ ( 1 − 2 − n ) \frac{1}{2}\leqslant M\leqslant(1−2^{-n}) 21⩽M⩽(1−2−n)
- 负数为1.1×…的形式,最大值为1.10…0,最小值为1.11…1,表示范围为 − ( 1 − 2 − n ) ⩽ M ⩽ − 1 2 -(1-2^{-n})\leqslant M\leqslant-\frac{1}{2} −(1−2−n)⩽M⩽−21。
不同基数规格化👺
-
当基数为2时,
尾数最高位为1的数为规格化数。- 设被规格化的数为 F r = 2 F_{r=2} Fr=2
- 即,规格化数的尾数的绝对值不小于 1 2 \frac{1}{2} 21
- 规格化时分为左归和右归
-
尾数左移1位( F 2 F_2 F2总大小相当于被乘以2,那么为了保持大小不变,必须再除以2,- 这可以通过将阶码减1(这种规格化称为向左规格化,简称
左规); - 根据需要,反复执行上述操作
- 比如对 F 2 = 2 3 ⋅ 0.001 F_2=2^{3}\cdot0.001 F2=23⋅0.001执行2次左归操作,得到 F 2 = 2 1 ⋅ 0.1 F_2=2^{1}\cdot{0.1} F2=21⋅0.1
- 这可以通过将阶码减1(这种规格化称为向左规格化,简称
-
尾数右移1位,阶码加1(这种规格化称为向右规格化,简称右规)。- 和左归是相反的操作
- 比如对 F 2 = 2 3 ⋅ 111.01 F_2=2^{3}\cdot111.01 F2=23⋅111.01执行2次右归操作,得到 F 2 = 2 5 ⋅ 0.1101 F_2=2^{5}\cdot{0.1101} F2=25⋅0.1101
-
-
当基数为4= 2 2 2^2 22时,尾数的
最高两位不全为零的数为规格化数。- 设被规格化的数为 F = F r = 4 = 4 j ⋅ S f S 1 S 2 ⋯ S n F=F_{r=4}=4^j\cdot{S_fS_1S_2\cdots{S_n}} F=Fr=4=4j⋅SfS1S2⋯Sn
- 规格化时,尾数左移2位,阶码减1 ;
- 尾数右移2位,阶码加1。
- 因此,如果尾数的最高位两位 S 1 S 2 = 01 S_1S_2=01 S1S2=01,那么是无法仅仅将二进制串左移一位来消掉尾数 S 1 = 0 S_1=0 S1=0的,因为阶码变化1,整个值会变化4倍,导致操作前后的值不相等,因此,只能够认为, S 1 S 2 = 01 S_1S_2=01 S1S2=01也是属于基数r=4下的规格化数
-
当基数为8= 2 3 2^3 23时,尾数的最高三位不全为零的数为规格化数。
- 规格化时,尾数左移三位,阶码减1;
- 尾数右移三位,阶码加1。
小结
基数不同,浮点数的规格化形式也不同。
当浮点数尾数的基数为2时,原码规格化的尾数最高位一定是1。
当基数为4时,原码规格化的尾数最高两位不全为0。
…
以此类推,基数为 2 k 2^{k} 2k时,原码规格化的尾数最高 k k k位不全位0即可
如 r = 2 4 = 16 r=2^{4}=16 r=24=16的浮点数,因其规格化数的尾数最高三位可能出现零,故与其尾数位数相同的r =2的浮点数相比,后者可能比前者多三位精度。
规格化浮点数尾数表示范围
- 基数为
R
R
R的规格化浮点数尾数绝对值
∣
S
∣
∈
[
1
R
,
1
)
|S|\in{[\frac{1}{R},1)}
∣S∣∈[R1,1),设一般
R
=
2
k
,
k
∈
Z
+
R=2^k,k\in\mathbb{Z_{+}}
R=2k,k∈Z+
- 比如, R = 2 R=2 R=2,规格化后的 ∣ S ∣ ∈ [ 1 2 , 1 ) |S|\in[\frac{1}{2},1) ∣S∣∈[21,1)
IEEE 754标准的浮点数格式
IEEE 754标准浮点数格式
- 前面我们说非标准的浮点数格式更加符合直觉,但是标准之所以是标准有其道理
- 事实上标准(IEEE 754)对浮点数的考虑比较深入,对精度有进一步提高,还考虑了溢出和无穷的表示,规则会比非标准更加复杂一些
- 为了和前面的非标准结构的符号做区别,阶码用 e e e而不用 j j j;尾数用 s s s而不用 m m m
S f E 1 ∼ m S 1 ∼ n 数符 阶码部分 ( 移码表示 ) 尾数数值位 ( 用定点小数原码 ) S f ( 数符 ) 阶码(含阶符) 尾数 \\ \begin{array}{|l|l|l|} \hline S_f & E_{1\sim{m}} & S_{1\sim{n}} \\ \hline 数符&阶码部分(移码表示)&尾数数值位(用定点小数原码) \\\hline \end{array} \\ \begin{array}{|l|c|c|} \hline S_f(数符) & \text { 阶码(含阶符) } & \text { 尾数 } \\ \hline \end{array} Sf数符E1∼m阶码部分(移码表示)S1∼n尾数数值位(用定点小数原码)Sf(数符) 阶码(含阶符) 尾数
该表格列出了不同类型的浮点数的位分布情况,包括短实数、长实数和临时实数,具体细节如下:
| 类型 | 符号位 S | 阶码位数 | 尾数位数 | 总位数 |
|---|---|---|---|---|
| 短实数 | 1 | 8 | 23 | 32 |
| 长实数 | 1 | 11 | 52 | 64 |
| 临时实数 | 1 | 15 | 64 | 80 |
字节展开浮点的表示格式如下所示
| 格式 | 字节 1 | 字节 2 | 字节 3 | 字节 4 | … | 字节 n |
|---|---|---|---|---|---|---|
| 单精度 (single-precision) | SXXXXXXX | XMMMMMMM | MMMMMMMM | MMMMMMMM | ||
| 双精度 | SXXXXXXX | XXXXMMMM | MMMMMMMM | MMMMMMMM | … | MMMMMMMM |
S 表示符号位,X 是偏置(偏差)的指数位,M 是有效数位。 最左边的位假定采用单精度和双精度格式。
若要正确移动二进制小数点,首先要取消指数偏置,然后将二进制小数点向右或向左移动适当的位数。
这个表格通常与IEEE 754浮点数标准相关联,其中短实数通常对应于单精度浮点数(32位),长实数对应于双精度浮点数(64位),而临时实数可能用于更高精度的计算场合,如80位的扩展精度(Extended Precision)格式(临时实数)。
单精度格式中包含 1 1 1 位符号 s s s、 8 8 8 位阶码 e e e 和 23 23 23 位尾数 f f f;
双精度格式包含 1 1 1 位符号 s s s, 11 11 11 位阶码 e e e 和 52 52 52 位尾数 f f f。
基数隐含为 2 2 2;尾数用原码表示。
其中,S为数符,它表示浮点数的正负,但与其有效位(尾数)是分开的。
浮点数结构中英文对照👺
-
数符:the sign bit
-
阶码:the biased exponent bits
-
尾数:the significand bits/mantissa
隐藏位 IEEE754规格化
- 尾数部分通常都是规格化表示,即非“0”的有效位最高位总是“1”,在实际表示中,对短实数和长实数,这个整数位的1省略,称隐藏位;
- 对于规格化的二进制浮点数,尾数的最高位总是 1 1 1,为了能使尾数多表示一位有效位,将这个 1 1 1 隐藏,称为隐藏位,因此 23 23 23 位尾数实际表示了 24 24 24 位有效数字。
- IEEE 754 规定隐藏位 1 1 1 的位置在小数点之前
- 单精度与双精度浮点数都采用隐藏尾数最高位的方法,因而使浮点数的精度更高。
- 这种情况下,非标准化中提到的规格化数并不能满足IEEE 754标准的需要,我们还要进一步将其小数点做调整(做一次左规,小数点右移回1位,让尾数的最高有效位1移到小数点前面,此时阶码相应地要减1回去)
- 在实际操作是,对于将一个数(真值二进制形式)转换为IEEE 754浮点数时,调整尾数和阶码做左规时,小数点左移到最高位1的后面即可,如果此时小数点移动了 m m m位,那么对应的阶码真值就是 m m m
- 这种形式的规格化数落在 [ 1 , 2 ) [1,2) [1,2)区间内
- 例如, ( 12 ) 10 = ( 1100 ) 2 (12)_{10} = (1100)_2 (12)10=(1100)2,将其规格化后结果为 1.1 × 2 3 1.1 \times 2^3 1.1×23,其中整数部分的“ 1 1 1”将不存储在 23 23 23 位尾数内。(这里的1不是符号位,不表示负数,符号有最高位表示)
- 对于临时实数不采用隐藏位方案
偏移量/偏置量/偏差
阶码用移码表示,阶码的真值都被加上一个常数(偏移量)
- 如短实数,长实数和临时实数的偏移量用十六进制数表示分别为7FH,3FFH和3FFFH(它们分别对应于 2 7 − 1 , 2 10 − 1 , 2 14 − 1 2^{7}-1,2^{10}-1,2^{14}-1 27−1,210−1,214−1。
- 这里的偏移量和一般的移码定义中的偏移量不同, m m m位移码的偏移量通常位 2 m 2^{m} 2m,但是IEEE754标准下,偏移量位 2 m − 1 2^{m}-1 2m−1
- 如果用十进制表示偏移量,单精度和双精度浮点数的偏置值分别为 127 127 127 和 1023 1023 1023。
- 在存储浮点数阶码之前,偏置值要先加到阶码真值上。
- 例如 1.1 × 2 3 1.1 \times 2^3 1.1×23,阶码值为 3 3 3,因此在单精度浮点数中,移码表示的阶码为 127 + 3 = 130 ( 82 H ) 127+3=130(82H) 127+3=130(82H);在双精度浮点数中,阶码为 1023 + 3 = 1026 ( 402 H ) 1023 + 3 = 1026(402H) 1023+3=1026(402H)。
例
- 下表列出了十进制数178.125的实数表示,考虑隐藏位
-
实数表示 数值 十进制数 178.125 二进制数(真值二进制) 10110010.001 二进制浮点数表示 1.0110010001 × 2 111 1.0110010001\times{2^{111}} 1.0110010001×2111 -
短实数(32位)表示
-
符号(1位) 阶码(8位) 尾数(有效位)(23位) 0 00000111+01111111=10000110 01100100010000000000000 -
尾数第一位的 1 1 1隐藏了
-
-
反之,我们可以利用IEEE754标准从上述结果换源出真值(分为三部分)
-
符号(正负) 阶码 尾数 + 10000110-01111111=111=7 1.0110010001 -
这里尾数将被隐藏的1补回去,并且小数点的位置在这个补回的1之后
-
因此``0 10000110 01100100010000000000000`转换为十进制真值位178.125
-
将IEEE 754浮点数还原真值公式👺
若要正确移动二进制小数点,首先要取消指数偏差,然后将二进制小数点向右或向左移动适当的位数。
设 s , f , e s,f,e s,f,e分被是IEEE 754浮点数的数符(1位),尾数有效位(23/52/64位),阶码(8/11/15位)
IEEE 754 标准中,规格化单精度浮点数的真值为
( − 1 ) s × 1. f × 2 e − 127 (-1)^{s} \times 1.f \times 2^{e-127} (−1)s×1.f×2e−127
规格化双精度浮点数的真值为
( − 1 ) s × 1. f × 2 e − 1023 (-1)^{s} \times 1.f \times 2^{e-1023} (−1)s×1.f×2e−1023
阶码取值范围
式中,规格化单精度浮点数的阶码 e e e 的取值范围为 1 ∼ 254 1 \sim 254 1∼254(8位);0和255展开为8位二进制分别是全0和全1它们在IEEE 754中有别的含义和用途(表示 + ∞ , − ∞ +\infin,-\infin +∞,−∞,也就是说,如果假设浮点数的阶码有 n n n位(包括阶符),那么阶码(移码)的取值范围原本应该是 0 ∼ 2 n − 1 0\sim{2^{n}-1} 0∼2n−1,但是由于保留全0和全1的情况,剩下的范围是 1 ∼ 2 n − 2 1\sim{2^{n}-2} 1∼2n−2;
如果取移码偏置量为最大移码的一般,也就是 2 n − 2 2^{n}-2 2n−2的一半,就是 2 n − 1 − 1 2^{n-1}-1 2n−1−1,这种情况下,移码真值的范围就是 [ 2 − 2 n − 1 , 2 n − 1 − 1 ] [2-2^{n-1},2^{n-1}-1] [2−2n−1,2n−1−1],例如 n = 8 n=8 n=8,则有效阶码真值的范围是 [ − 126 , 127 ] [-126,127] [−126,127]
单从 n n n位机器数可以表示的最大范围是 [ − 2 n − 1 , 2 n − 1 − 1 ] [-2^{n-1},2^{n-1}-1] [−2n−1,2n−1−1],这时候结合移码的范围 [ 1 , 2 n − 2 ] [1,2^{n}-2] [1,2n−2],两个边界分别做差取绝对值得到 l 1 = 1 + 2 n − 1 l_{1}=1+2^{n-1} l1=1+2n−1,而 l 2 = 2 n − 1 − 1 l_{2}=2^{n-1}-1 l2=2n−1−1,显然 l 1 > l 2 l_{1}>l_{2} l1>l2,如果偏置值取 l 1 l_{1} l1,会导致阶码真值取 2 n − 1 − 1 2^{n-1}-1 2n−1−1时移码超过了允许的最大值;类似的,如果取 l 1 l_{1} l1作为偏置量,那么当阶码真值取 2 n − 1 − 1 2^{n-1}-1 2n−1−1时,移码会小于允许的最小值 1 1 1;总之 l 1 , l 2 l_{1},l_{2} l1,l2作为偏置值的时候,总有一些真值是不可取的,要对 [ − 2 n − 1 , 2 n − 1 − 1 ] [-2^{n-1},2^{n-1}-1] [−2n−1,2n−1−1]做范围缩小;IEEE 754选择修改作边界为 − 2 n − 1 + 2 -2^{n-1}+2 −2n−1+2,偏置值使用 2 n − 1 − 1 2^{n-1}-1 2n−1−1
规格化双精度浮点数的阶码 e e e 的取值范围为 1 ∼ 2046 1 \sim 2046 1∼2046( 11 11 11 位),这里同样保留全0和全1的取值
IEEE 754浮点数的表示范围👺👺
IEEE浮点数的精度和范围
一旦浮点数的位数确定后,合理分配阶码和尾数的位数,直接影响浮点数的表示范围和精度。
- 通常对于短实数(总位数为32位),阶码取8位(含阶符1位) ,尾数取24位(含数符1位);
- 对于长实数(总位数为64位),阶码取11位(含阶符1位) ,尾数取53位(含数符1位);
- 对于临时实数(总位数为80位),阶码取15位(含阶符1位) ,尾数取65位(含数符1位)。
阶码不为全0也不为全1的情况
这种情况不需要做特殊解释,属于常规情况
IEEE 754 规格化浮点数的表示范围(正数范围,符号位 s = 0 s=0 s=0)
| 格式 | 最小值 | 最大值 | 备注 |
|---|---|---|---|
| 单精度 | e = 1 , f = 0 e=1,f=0 e=1,f=0 | e = 254 , f = . 11 ⋯ e=254,f=.11\cdots e=254,f=.11⋯ | 单精度偏置量为127,尾数23位,实际精度24位 |
| 1.0 × 2 1 − 127 = 2 − 126 1.0\times2^{1-127}=2^{-126} 1.0×21−127=2−126 | 2 127 × ( 2 − 2 − 23 ) 2^{127}\times(2-2^{-23}) 2127×(2−2−23) | 1. f × 2 e − 127 1.f\times2^{e-127} 1.f×2e−127= ( 2 − 2 − 23 ) × 2 254 − 127 (2-2^{-23})\times2^{254-127} (2−2−23)×2254−127 | |
| 双精度 | e = 1 , f = 0 e=1,f=0 e=1,f=0 | e = 2046 , f = . 11 ⋯ e=2046,f=.11\cdots e=2046,f=.11⋯ | 双精度偏置量位1023,尾数52位,实际精度53位 |
| 1.0 × 2 − 1023 = 2 − 1022 1.0\times2^{-1023}=2^{-1022} 1.0×2−1023=2−1022 | 2 1023 × ( 2 − 2 − 52 ) 2^{1023}\times(2-2^{-52}) 21023×(2−2−52) | 1. f × 2 e − 1023 1.f\times2^{e-1023} 1.f×2e−1023= ( 2 − 2 − 52 ) × 2 2046 − 1023 (2-2^{-52})\times2^{2046-1023} (2−2−52)×22046−1023 |
注意IEEE 754的尾数部分的隐藏位,可以使用还原真值公式 1. f × 2 e i − B i 1.f\times2^{e_{i}-B_{i}} 1.f×2ei−Bi, ( i = 1 , 2 ) (i=1,2) (i=1,2), i = 1 i=1 i=1时表示单精度, i = 2 i=2 i=2时表示双精度;
其中 B 1 = 127 , B 2 = 1023 B_{1}=127,B_{2}=1023 B1=127,B2=1023; e 1 , e 2 e_{1},e_{2} e1,e2的最大值分别是 254 , 2046 254,2046 254,2046,也就是分被位 2 B 1 , 2 B 2 2B_{1},2B_{2} 2B1,2B2
负数范围和正数对称
对于 IEEE 754 格式的浮点数,阶码全为 0 或全为 1 时,有其特别的解释
阶码全为0/1的情况
-
全 0 阶码全 0 尾数: + 0 / − 0 +0/-0 +0/−0。零的符号取决于符号 s,一般情况下 +0 和 -0 是等效的。
-
全 1 阶码全 0 尾数: + ∞ / − ∞ +\infin/-\infin +∞/−∞。 + ∞ +\infin +∞ 在数值上大于所有有限数, − ∞ -\infin −∞ 则小于所有有限数。
- 引入无穷大数的目的是,在计算过程中出现异常的情况下使得程序能继续进行下去。
-
全 1 阶码非 0 尾数: NaN(Not a Number)。表示一个没有定义的数,称为非数。
-
全 0 阶码非 0 尾数:非规格化数(次正规数)。
次正规数
-
非规格化数的特点是阶码为全 0,尾数非0(高位有一个或几个连续的 0,但不全为 0)
- 虽然我们有规格化方法来让尾数的最高位有效位取1,但是这依赖于阶码,如果尾数十分的小,比如某个真值 2 − n 2^{-n} 2−n要表示为浮点数,而 n n n很大,比如达到 2 7 2^{7} 27以上,也就是要求精确到 2 − 128 2^{-128} 2−128甚至更高;这对于一个32位单精度浮点数是难以规格化的,尾数小数点从开始的位置要往右移动128位以上,这就要求阶码能够表示-128,而在IEEE标准下,阶码最多允许表示 − 126 -126 −126即便不考虑预留的全0,也就只能表示到 − 127 -127 −127,因此无法把尾数的最高位调整位1,尾数的小数点前的隐藏位(前导)只能是0;
-
因此,非规格化数的隐藏位为 0,单精度和双精度浮点数的指数分别为 −126 或 −1022(这和常规情况的允许表示的最小值时的指数是一样的,没有特殊化)。
-
非规格化数可以用于处理阶码下溢。
-
可以用规范化形式表示比最小的数更小的数量级。 这些数字称为次规范数或非规范数。
-
如果指数为全零且有效数不为零,则有效数的隐式前导位被视为 0,而不是 1。 次正规数的精度随有效数中前导零数量的增加而下降。
机器零
- 当一个浮点数
尾数为0时(不论其阶码为何值)或阶码等于或小于它所能表示的最小数时(不管其尾数为何值)机器都把该浮点数作为零看待,并称之为“机器零”。 - 如果浮点数的阶码用移码表示,尾数用补码表示
IEEE 754浮点数字节查看工具
联系实际:C++程序打印浮点数变量的各位值👺
#include <iostream>
#include <bitset>
#include <iomanip>
#include <cassert>
using namespace std;
// Function to print the bits of a float number
/**
* 打印浮点数的二进制表示(IEEE 754 单精度/双精度浮点数)
*
* 本函数旨在展示浮点数在内存中的存储方式,通过将其内存内容解释为整数并转换为二进制字符串来实现
* 此外,还展示了浮点数的十六进制表示,以便更好地理解其内存布局
*
* @param number 浮点数,其二进制和十六进制表示将被打印
*/
void printFloatBits(float number)
{
// 将浮点数的内存视图转换为整数类型
uint32_t bits = *reinterpret_cast<uint32_t *>(&number);
// 双精度
// uint64_t bits64 = *reinterpret_cast<uint64_t *>(&number);
// 使用 bitset 将整数转换为二进制字符串
bitset<32> binary(bits);
// 打印浮点数的值
cout << "Float value: " << number << endl;
// 打印二进制表示
cout << "Binary representation: " << binary << endl;
// 打印十六进制表示
cout << "Hexadecimal representation: 0x" << hex << setw(8) << setfill('0') << bits << endl
<< endl;
}
int main()
{
//testPrintFloatBits();
float number = -8.25;
printFloatBits(number);
return 0;
}
reinterpret_cast<uint32_t*>(&number)将float类型的指针转换为uint32_t类型的指针,然后解引用以获取其位模式。std::bitset<32>用来将 32 位的无符号整数转换为二进制格式的字符串。std::hex将输出格式设置为十六进制。std::setw(8)设置输出宽度为8位,以确保输出时前面自动补零。std::setfill('0')设置填充字符为0。
测试函数
// Unit test for the printFloatBits function
// This function tests various float values to ensure correct bit representation
void testPrintFloatBits()
{
// Test case: normal float number
float normalFloat = 3.14f; // A typical float value
cout << "Testing with normal float value: " << normalFloat << endl;
printFloatBits(normalFloat);
// Test case: zero float number
float zeroFloat = 0.0f; // The float representation of zero
cout << "Testing with zero float value: " << zeroFloat << endl;
printFloatBits(zeroFloat);
// Test case: negative float number
float negativeFloat = -3.14f; // A negative float value
cout << "Testing with negative float value: " << negativeFloat << endl;
printFloatBits(negativeFloat);
// Test case: smallest positive normal float number
float smallestPositiveFloat = 1.175494351e-38f; // Smallest positive normal float, approximately 1.0 / (2^126)
cout << "Testing with smallest positive normal float value: " << smallestPositiveFloat << endl;
printFloatBits(smallestPositiveFloat);
// Test case: largest positive normal float number
float largestPositiveFloat = 3.402823466e+38f; // Largest positive normal float, approximately (1.0 - 2^-23) * 2^127
cout << "Testing with largest positive normal float value: " << largestPositiveFloat << endl;
printFloatBits(largestPositiveFloat);
}
int main()
{
testPrintFloatBits();
//float number = -8.25;
//printFloatBits(number);
return 0;
}
效果
Testing with normal float value: 3.14
Float value: 3.14
Binary representation: 01000000010010001111010111000011
Hexadecimal representation: 0x4048f5c3
...
Float value: -8.25
Binary representation: 11000001000001000000000000000000
Hexadecimal representation: 0xc1040000
其中比较有意思的有
Testing with zero float value: 0
Float value: 0
Binary representation: 00000000000000000000000000000000
Hexadecimal representation: 0x00000000
Testing with smallest positive normal float value: 1.17549e-38
Float value: 1.17549e-38
Binary representation: 00000000100000000000000000000000
Hexadecimal representation: 0x00800000
Testing with largest positive normal float value: 3.40282e+38
Float value: 3.40282e+38
Binary representation: 01111111011111111111111111111111
Hexadecimal representation: 0x7f7fffff
对于单精度(32)位IEEE 754浮点数,最小值为 − 2 − 126 -2^{-126} −2−126,对应的32位二进制串为
0 00000001 00000000000000000000000- 第一位是符号位0,表示正数
- 第 2 ∼ 9 2\sim{9} 2∼9是移码,对应的真值为 − 126 -126 −126,偏置量位127
- 第 10 ∼ 32 10\sim{32} 10∼32位是尾数,是全部为0的,还原为真值时,要将隐藏的1补在小数点前,尾数的真值为 1.0 1.0 1.0
最大为 2 127 × ( 2 − 2 − 23 ) 2^{127}\times{(2-2^{-23})} 2127×(2−2−23),对应的二进制串:
0 11111110 11111111111111111111111- 第一位是符号位0,表示正数
- 第 2 ∼ 9 2\sim{9} 2∼9是移码,对应的真值为 127 ( = 254 − 127 ) 127(=254-127) 127(=254−127),最大移码为 254 254 254,偏置量位127
- 第 10 ∼ 32 10\sim{32} 10∼32位是尾数,是全部为1的,还原为真值时,要将隐藏的1补在小数点前,尾数的真值为 2 − 2 − 23 2-2^{-23} 2−2−23
注意,移码的符号位1是正数,0才是负数
舍入Rounding rules
Rounding rules | wikipedia舍入规则
在对阶和尾数右规时,可能会对尾数进行右移,为保证运算精度,一般将移出的部分低位保留下来,参加中间过程的运算,最后再将运算结果进行舍入,还原表示成 IEEE 754 格式。
IEEE 754 提供了以下 4 种可选的舍入模式:
- 就近舍入:舍入为最近的可表示数。
- 当运算结果正好在两个可表示数的中间时,则选择结果为偶数。
- 当运算结果是一个两个可表示数的非中间值时,是“0 舍 1 入”方式(类似于十进制的“四舍五入法”)
- 正向舍入:朝数轴 + ∞ +\infty +∞ 方向舍入,即取右边最近的可表示数。
- 负向舍入:朝数轴 − ∞ -\infty −∞ 方向舍入,即取左边最近的可表示数。
- 截断法:直接截取所需位数,丢弃后面的所有位,这种舍入处理最简单。对正数或负数来说,都是取更接近原点的那个可表示数,是一种趋向原点的舍入。
| Mode\Example values | +11.5 | +12.5 | -11.5 | -12.5 | 解释 |
|---|---|---|---|---|---|
| to nearest, ties to even | +12.0 | +12.0 | -12.0 | -12.0 | 向最接近的整数舍入,如果正好位于两个整数之间,则舍入到偶数。例如,+12.5 会变为 +12.0,而不是 +13.0。 |
| to nearest, ties away from zero | +12.0 | +13.0 | -12.0 | -13.0 | 向最接近的整数舍入,如果正好位于两个整数之间,则舍入到远离零的方向。例如,+12.5 会变为 +13.0。 |
| toward 0 | +11.0 | +12.0 | -11.0 | -12.0 | 舍入到零方向(截断)。例如,+11.5 向零舍入会变为 +11.0,而 -11.5 会变为 -11.0。 |
| toward +∞ | +12.0 | +13.0 | -11.0 | -12.0 | 向正无穷大舍入。例如,+11.5 会舍入到 +12.0,而 -11.5 会向上舍入到 -11.0。 |
| toward -∞ | +11.0 | +12.0 | -12.0 | -13.0 | 向负无穷大舍入。例如,+11.5 会舍入到 +11.0,而 -11.5 会向下舍入到 -12.0。 |
浮点数补码表示
如果指定尾数或阶码采用补码表示,通常可以采用双符号位
当尾数求和结果溢出(如尾数为10.×××或01.×××)时,需右规一次;
当结果出现00.0×××或11.1×××时,需要左规,直到尾数变为00.1××…×或11.0×××.
定点数vs浮点数
定点表示和浮点表示对比总结
主要从4个方面对比
浮点数在数的表示范围、数的精度、溢出处理和程序编程方面(不取比例因子)均优于定点数。但在运算规则、运算速度及硬件成本方面又不如定点数。
因此,究竟选用定点数还是浮点数,应根据具体应用综合考虑。一般来说,通用的大型计算机大多采用浮点数,或同时采用定、浮点数;小型、微型及某些专用机、控制机则大多采用定点数。当需要做浮点运算时,可通过软件实现,也可外加浮点扩展硬件(如协处理器)来实现。
数值的表示范围
若定点数和浮点数的字长相同,则浮点表示法所能表示的数值范围远大于定点表示法。
精度
对于字长相同的定点数和浮点数来说,何者精度更高要分情况讨论
从结构上看,定点数除了符号位外,其余位都可以用来描述小数部分,对于字长为 n n n的情况下,数值位有 n − 1 n-1 n−1位,小数精确到 2 − ( n − 1 ) 2^{-(n-1)} 2−(n−1);而浮点数的精度则取决于尾数,并且尾数通常要小于 n − 1 n-1 n−1位,导致精度不足,但是浮点数有一个强大的特点是可以进行规范化,可以在某些情况下大幅度提高精度,例如十分小的数(绝对值接近于0的情况);以32位浮点数(IEEE 754标准)为例,次浮点数格式可以精确表达 2 − 100 2^{-100} 2−100这样的小数,这个精度非常高,32位浮点数的尾数部分虽然只有23位,但是通过规格化,我们将小数点向右移动100位,尾数部分就变成了1,而阶码部分(真值)就是-100,对于单精度浮点数,阶码取值范围是 − 126 ∼ 127 -126\sim{127} −126∼127,所以是不会发生溢出的,从这个角度来将,浮点数的精度潜力是远远高于定点数;
另一方面,如果是要表示 1 − 2 − 31 1-2^{-31} 1−2−31这种数,那么定点数就有优势,浮点数无法通过规格化来像表示很接近0的数时那样显著提高精度,这种情况下定点数就可以精确表示这个小数
数的运算效率
浮点数包括阶码和尾数两部分,运算时不仅要做尾数的运算,还要做阶码的运算,而且运算结果要求规格化,所以浮点运算比定点运算复杂。
溢出问题
在定点运算中,当运算结果超出数的表示范围时,发生溢出:在浮点运算中,运算结果超出数表示范围却不一定溢出,只有规格化后阶码超出所能表示的范围时,才发生溢出。
在溢出的判断方法上,浮点数是对规格化数的阶码进行判断,而定点数是对数值本身进行判断。
例如,小数定点机中的数,其绝对值必须小于1,否则“溢出”,此时要求机器停止运算,进行处理。为了防止溢出,上机前必须选择比例因子,这个工作比较麻烦,给编程带来不便。
而浮点数的表示范围远比定点数大,仅当“上溢”时机器才停止运算,故一般不必考虑比例因子的选择。
C/C++语言和浮点数类型
C语言中的float和double类型分别对应于IEEE 754单精度浮点数(32bit)和双精度浮点数(64bit)。long double类型对应于扩展双精度浮点数,但long double的长度和格式随编译器和处理器类型的不同而有所不同
在C程序中等式的赋值和判断中会出现强制类型转换
-
以char> int>long> double和float>double最为常见,
-
从前到后范围和精度都从小到大,转换过程没有损失。
-
int型转换为float型时,虽然不会发生溢出,但float型尾数连隐藏位也只有共24位,以正数为例,当int型数的数值位(31位)都为1,那么第 24 ∼ 31 24\sim{31} 24∼31位(共8位)会丢失,将无法精确转换成24位浮点数的尾数,需舍入处理,影响精度。因此,如果可以用整形表示的数尽量用整形,不仅可以保证精度也可以保证运算效率(int转float不会溢出但是可能会丢失精度)
-
int型或float型转换为double型时,因double型的有效位数更多,因此能保留精确值
-
double型转换为float型时,因float型的表示范围更小,因此大数转换时可能会发生溢出。此外,由于尾数有效位数变少,因此高精度数转换时会发生舍入。
-
long到double与int到float类似都可能会损失精度(但是不总是损失,以被转换的数据小数情况共同考虑)
-
从double 转换为float 时,因为float 表示范围更小,因此可能发生溢出。此外,由于有效位数变少,因此可能被舍入。
-
从float或double转换为int时,因为int没有小数部分
-
所以数据可能会向0方向被截断(仅保留整数部分),影响精度。
-
由于int的表示范围更小,因此可能发生溢出。
-
31位数值位的上限 2 31 − 1 2^{31}-1 231−1
-
float的最大值为 2 127 × ( 2 − 2 23 ) 2^{127}\times{(2-2^{23})} 2127×(2−223)
-
双精度的范围就更大了,达到 2 1023 × ( 2 − 2 − 52 ) 2^{1023}\times{(2-2^{-52})} 21023×(2−2−52)
-
-



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











