






书接上回,在之前发表的文章《在微服务世界度量DevOps,你准备好了吗?》一文中,我们介绍了如何以GRE理论评价DevOps的实施情况,以及度量驱动和评价企业从开发敏捷到业务敏捷转型。本篇文章会更加深入的介绍如何落实度量点,如何实现一个度量系统。以及商业智能领域的新发展。
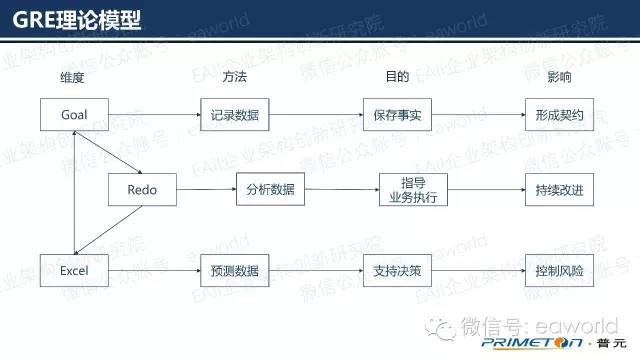
回顾一下,Goal维度,强调从业务目标出发,找到解决业务目标的问题。将问题中的人,事,物做为度量点放入度量体系中。Redo维度,强调不断跟踪这些度量点,从而确定业务目标的执行情况。Excel维度,强调通过数据积累,趋势分析控制风险。
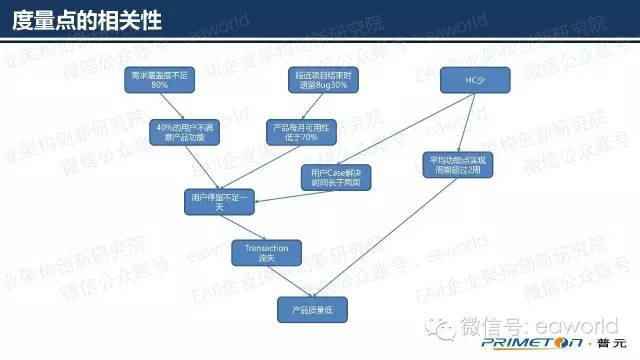
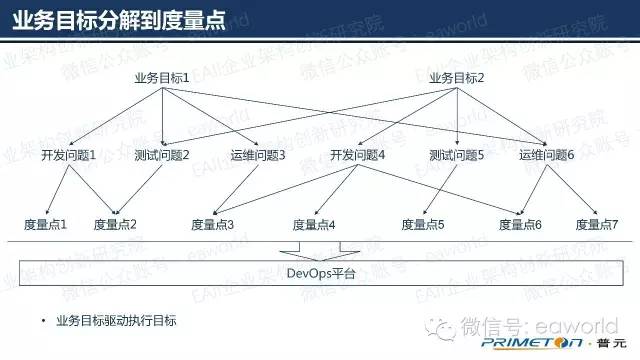
可以从上面的例子看出,度量点是一个层次结构的,不同的度量点之间息息相关。比如说“产品质量”这样的度量点也许会分解为一系列的子度量点。

相信大家在软件规格说明中经常会看到,可靠性,可用性等字眼,然后冠以高中低,或者百分数的解释对这些非功能性需求。但是这些指标背后隐藏的是什么,或者不同的标准之下不同的百分数会有不同的意义。所以仅仅用感性的评价去说明问题就会和事实相差比较大了。我们建议找到这些非功能性需求背后的理想度量点,来说明情况。到底如何表示一个度量点呢?

大家已经比较关心,是不是只有通过那些图标才能表示度量呢?到底有没有一个合适的标准来表示度量点呢?其实度量总结开来可以分为以下几类:
越多越好型:此类度量比较常见,比如说利润。
过犹不及型:比如说产品发布日期,过早会给研发团队产生压力,过晚会错过市场机会。
越少越好型:比如说构建失败率,如果是0那就更好了。
可以看到上图中,除了健康以及不健康还有一个颜色叫做:容忍。比如说有一些数值结果对比目标,虽然不理想,但是也可以接受。

度量除了状态以外,还会有变化。我们用以上图例来表明。正方型表示目前的状况。向上箭头表示与上次的数据相比,当前的数据产生了增长。圆型表示无变化。向下的箭头表示,数值产生了下降。当然不论是上相向下,都会有向更好的方向下降,或者向更差的方向增长的情况。

当然需要将度量的具体数值体现出来,比如说实际值,以及相对于目标来讲的完成度。

对于不同的度量点,度量的时效会有不同。比如说交易信息可能要求是实时的,但是项目总结等的汇总信息也许是以周报,月报等形式给出,我们可以用不同的图例表示度量的时效性。

将以上所说的所有概念连接到一起,我们就可以总结出一个度量点的可视化方法。比如说上面的度量点,目前的状态为健康,度量的时效是24小时,相对于上次的度量值,略有下降的趋势。

我们知道微服务下,每个微服务都会维护自己的数据。因此需要考虑通过ETL(Exaction,Transformation,Load)去将分散在不同系统中的业务信息抽取出来,形成有效的度量数据来源。
另外在商业智能领域中,大家经常会关心两种不同类型的报表,一个是实时报表(Live Report)这类报表要求实时的反应当前的真实数据,不会要求复杂的数据加工。另外一类是需要对历史数据进行分析总结的BI报表。以及,当数据丰富以后,如何将这些数据开放出去做更多的事情,这些都是一个好的度量系统需要考虑的问题。
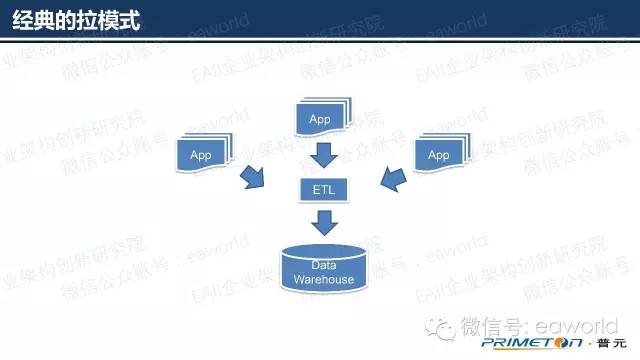
拉模式
经典模式
一般ETL运行在非业务时间
时效性差
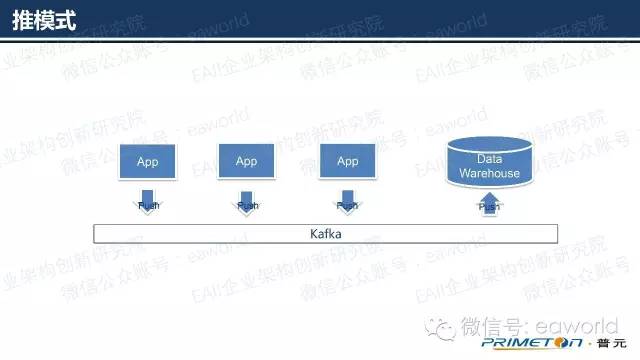
另外就是,适应于更实时的推模式
推模式
额外的消息总线,所有App遵循统一的消息发布模式
时效性强,成本高
ETL无需与程序直接对接
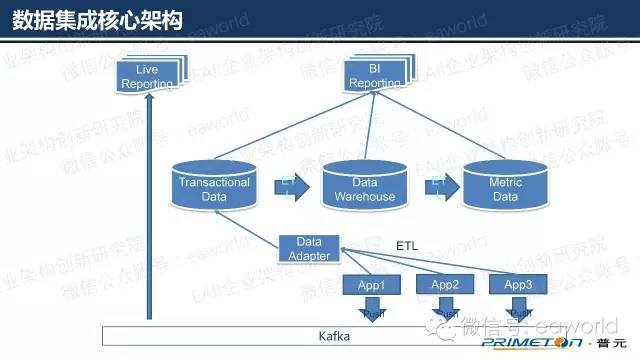
将以上两种模式结合起来就形成了我们的数据采集核心架构。事实上Kafka的使用不仅仅是为了度量数据采集。所有其他系统的信息松耦合交换都可以通过Kafka实现。
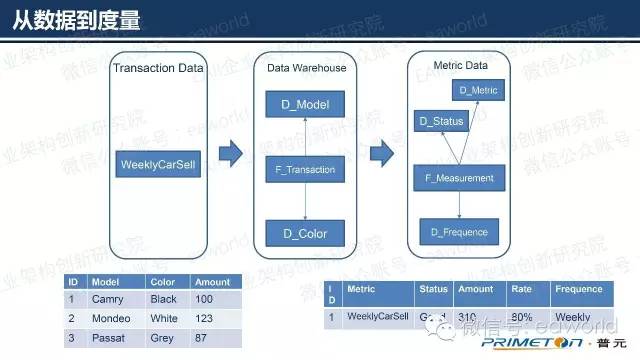
架构有了,大家一定很关心。数据如何通过不同的系统转化呢?举个例子,每周汽车的销售情况,如上面的表有车型,颜色,销量,编号这几个属性。经过ETL的数据转换,会将型号,颜色形成独立的维度表,而汽车销售情况形成事实表,也就是经典的星型架构。再经过一次ETL的转换,最终事实表中的记录会按照度量的标准转化为前面所表述的可视化的度量表示。
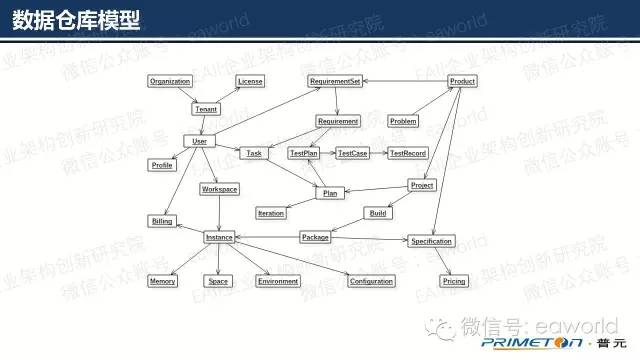
基于上面的方法,我们可以将DevOps生命周期内的所有领域模型汇集到一起形成一个数据仓库。
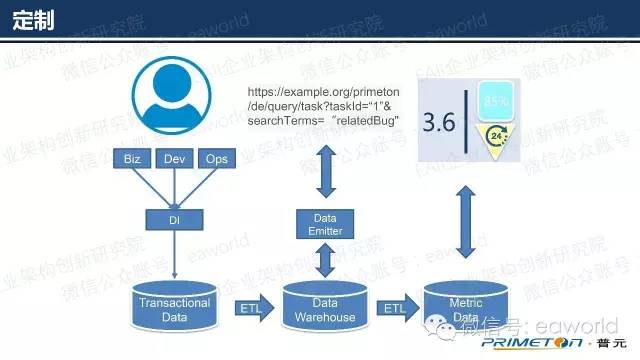
在我们拥有很多数据之后,就会有更多的定制需求。比如说用户想基于关于某Task的所有Defect做定制化的报表,甚至将这个信息推送到手机客户端等。利用简单的REST请求就可以查询数据仓库的内容。

朋友们可能会比较好奇,怎么讲完度量开始讲BI了?实际上整个软件度量实现无法脱离开商业智能技术的新发展,或者说软件度量实际上是BI在特定领域的一个应用。所以接下来我们会分享一下BI领域最近都有哪些新的变化。
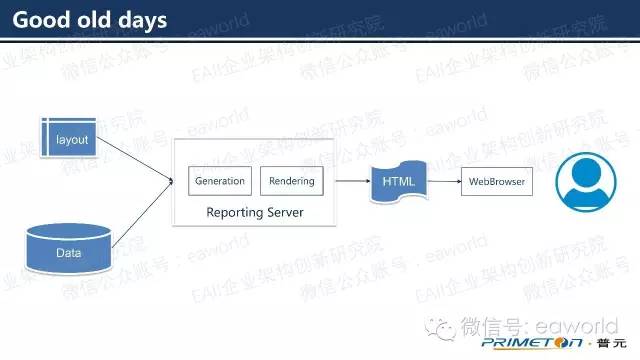
什么是报表呢?报表=样式+数据。随着前端技术的发展,数据可视化的结构产生了微妙的变化。
以前服务器端需要承担的很多工作,比如传统的报表服务器一般会做这样的工作,在Generation阶段:根据用户设计的样式,报表服务器需要将数据填充到报表模型中,在Rendering阶段,根据用户的需求,将填充数据后的报表模型转化成可见的格式:HTML,pdf,Excel等。
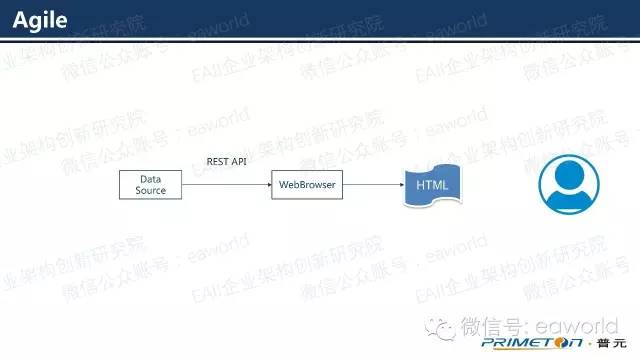
但是随着可视化技术的发展,前端框架复杂度增加,现在很多后台服务器需要完成的工作交给了前端进行。拿开源图表库D3举例,在浏览器端,可以利用JS向数据源发送REST请求,浏览器可以根据返回的JSON数据动态的生成所需的图表。对于传统的BI工具来讲,这种Live Reporting的需求可能是一件很难完成的任务。
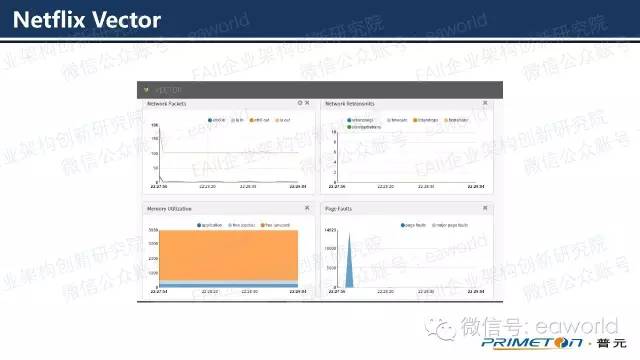
Netflix 的Vector就是运用D3做LiveReporting可视化的良好范例
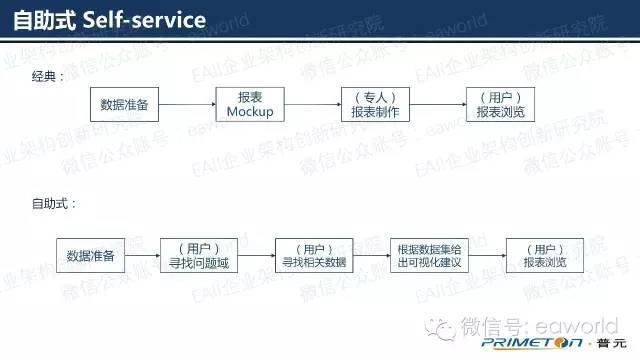
熟悉BI开发的朋友们都清楚,以前很多时间都会花在费时费力的去实现一个报表样式上。但是目前的潮流是一个报表的设计尽可能的简单化,主题化,复杂的报表交由仪表盘的形式代替。这样报表的制作方由专业的开发者,变成了普通用户。用户可以根据系统的引导,用很简单的步骤,方便的展现想要的数据。这不仅降低了报表制作的门槛,也加快了开发速度。我们前面讲的以DevOps为主题的数据仓库,就非常适合自助式的BI系统设计。

IBM的沃森分析以及Tableau都是引领自助式分析的典范
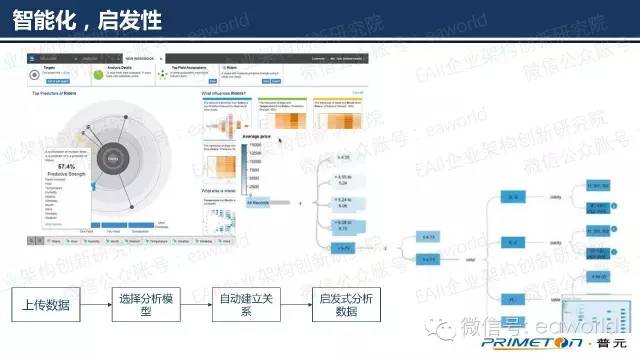
在报表设计之前,数据的准备始终是一个很头痛的问题。而且以前数据准备是由专门的IT人员来做。报表开发人员需要花时间熟悉数据模型,甚至有时数据模型无法满足展示的需要。目前在数据准备阶段的趋势就是,智能化,以及启发性的关系分析。用户可以将需要展示的数据集DataSet直接上传到数据分析终端上,服务器可以智能的分析出数据集中不同属性之间的关联关系,相关性,血缘关系等。
根据这些关系再进行下一步的报表展示。但是所谓的智能受限于各种条件,还需要很多人工参与,或者相关性不准确的情况。相信随着时间的推进,这些问题会逐步的改善。
普元云计算专区:http://primeton.csdn.net/m/zone/primeton/index#
普元公众号:
















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









