






1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着交通工具的普及和城市化进程的加快,交通安全问题日益凸显。其中,闯红灯行为是导致交通事故的主要原因之一。为了提高交通安全水平,减少交通事故的发生,研究和开发一种高效准确的闯红灯车牌检测系统具有重要的意义。
目前,计算机视觉技术在交通安全领域得到了广泛应用。其中,目标检测是计算机视觉领域的一个重要研究方向。传统的目标检测方法存在着诸多问题,如准确率低、速度慢等。为了解决这些问题,研究者们提出了一系列的改进方法。
YOLO(You Only Look Once)是一种基于深度学习的目标检测算法,具有快速和准确的特点。然而,传统的YOLO算法在处理小目标时存在一定的困难,且对于车牌等细小目标的检测效果不佳。因此,改进YOLO算法以提高其在小目标检测方面的性能具有重要意义。
在本研究中,我们将基于中心化特征金字塔(ECV-Block)的改进方法应用于YOLOv7算法,以提高其在闯红灯车牌检测方面的性能。ECV-Block是一种有效的特征提取方法,可以在保持高准确率的同时提高检测速度。通过将ECV-Block与YOLOv7相结合,我们可以有效地提高车牌检测的准确率和速度。
该研究的意义主要体现在以下几个方面:
首先,该研究可以提高交通安全水平。通过开发一种高效准确的闯红灯车牌检测系统,可以及时发现违规行为,减少交通事故的发生,保障行人和车辆的安全。
其次,该研究可以促进计算机视觉技术的发展。通过改进YOLOv7算法,提高其在小目标检测方面的性能,可以为其他目标检测任务提供借鉴和参考,推动计算机视觉技术的进步。
此外,该研究还具有一定的应用价值。闯红灯车牌检测系统可以应用于交通监控、交通违法行为抓拍等场景,为交通管理部门提供有效的工具和手段,提高交通管理的效率和精度。
综上所述,基于中心化特征金字塔ECV-Block的改进YOLOv7的闯红灯车牌检测系统具有重要的研究背景和意义。通过该研究,可以提高交通安全水平,促进计算机视觉技术的发展,并具有一定的应用价值。
2.图片演示


3.视频演示
基于中心化特征金字塔ECV-Block的改进YOLOv7的闯红灯车牌检测系统
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集TrafficDatasets。

labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。

由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。
下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 ECV-Block.py
class Encoding(nn.Module):
def __init__(self, in_channels, num_codes):
super(Encoding, self).__init__()
self.in_channels, self.num_codes = in_channels, num_codes
num_codes = 64
std = 1. / ((num_codes * in_channels)**0.5)
self.codewords = nn.Parameter(
torch.empty(num_codes, in_channels, dtype=torch.float).uniform_(-std, std), requires_grad=True)
self.scale = nn.Parameter(torch.empty(num_codes, dtype=torch.float).uniform_(-1, 0), requires_grad=True)
@staticmethod
def scaled_l2(x, codewords, scale):
num_codes, in_channels = codewords.size()
b = x.size(0)
expanded_x = x.unsqueeze(2).expand((b, x.size(1), num_codes, in_channels))
reshaped_codewords = codewords.view((1, 1, num_codes, in_channels))
reshaped_scale = scale.view((1, 1, num_codes))
scaled_l2_norm = reshaped_scale * (expanded_x - reshaped_codewords).pow(2).sum(dim=3)
return scaled_l2_norm
@staticmethod
def aggregate(assignment_weights, x, codewords):
num_codes, in_channels = codewords.size()
reshaped_codewords = codewords.view((1, 1, num_codes, in_channels))
b = x.size(0)
expanded_x = x.unsqueeze(2).expand((b, x.size(1), num_codes, in_channels))
assignment_weights = assignment_weights.unsqueeze(3)
encoded_feat = (assignment_weights * (expanded_x - reshaped_codewords)).sum(1)
return encoded_feat
def forward(self, x):
assert x.dim() == 4 and x.size(1) == self.in_channels
b, in_channels, w, h = x.size()
x = x.view(b, self.in_channels, -1).transpose(1, 2).contiguous()
assignment_weights = torch.softmax(self.scaled_l2(x, self.codewords, self.scale), dim=2)
encoded_feat = self.aggregate(assignment_weights, x, self.codewords)
return encoded_feat
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, res_conv=False, act_layer=nn.ReLU, groups=1, norm_layer=partial(nn.BatchNorm2d, eps=1e-6)):
super(ConvBlock, self).__init__()
self.in_channels = in_channels
expansion = 4
c = out_channels // expansion
self.conv1 = Conv(in_channels, c, act=nn.ReLU())
self.conv2 = Conv(c, c, k=3, s=stride, g=groups, act=nn.ReLU())
self.conv3 = Conv(c, out_channels, 1, act=False)
self.act3 = act_layer(inplace=True)
if res_conv:
self.residual_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False)
self.residual_bn = norm_layer(out_channels)
self.res_conv = res_conv
def zero_init_last_bn(self):
nn.init.zeros_(self.bn3.weight)
def forward(self, x, return_x_2=True):
residual = x
x = self.conv1(x)
x2 = self.conv2(x)
x = self.conv3(x2)
if self.res_conv:
residual = self.residual_conv(residual)
residual = self.residual_bn(residual)
x += residual
x = self.act3(x)
if return_x_2:
return x, x2
else:
return x
class Mean(nn.Module):
def __init__(self, dim, keep_dim=False):
super(Mean, self).__init__()
self.dim = dim
self.keep_dim = keep_dim
def forward(self, input):
return input.mean(self.dim, self.keep_dim)
class LVCBlock(nn.Module):
def __init__(self, in_channels, out_channels, num_codes, channel_ratio=0.25, base_channel=64):
super(LVCBlock, self).__init__()
self.out_channels = out_channels
self.num_codes = num_codes
num_codes = 64
self.conv_1 = ConvBlock(in_channels=in_channels, out_channels=in_channels, res_conv=True, stride=1)
self.LVC = nn.Sequential(
Conv(in_channels, in_channels, 1, act=nn.ReLU()),
Encoding(in_channels=in_channels, num_codes=num_codes),
nn.BatchNorm1d(num_codes),
nn.ReLU(inplace=True),
Mean(dim=1))
self.fc = nn.Sequential(nn.Linear(in_channels, in_channels), nn.Sigmoid())
def forward(self, x):
x = self.conv_1(x, return_x_2=False)
en = self.LVC(x)
gam = self.fc(en)
b, in_channels, _, _ = x.size()
y = gam.view(b, in_channels, 1, 1)
x = F.relu_(x + x * y)
return x
class GroupNorm(nn.GroupNorm):
def __init__(self, num_channels, **kwargs):
super().__init__(1
该工程中的ECV-Block.py文件定义了一些模型组件和模型结构。文件中定义了以下几个类:
-
Encoding类:实现了编码器模块,用于将输入特征进行编码。包括初始化编码词和平滑因子,以及计算编码特征和聚合特征的方法。
-
Mlp类:实现了MLP模块,使用1x1卷积实现。包括初始化权重和偏置项,以及前向传播方法。
-
ConvBlock类:实现了卷积块模块,包括1x1、3x3和1x1卷积层。可以选择是否使用残差连接。包括前向传播方法。
-
Mean类:实现了求平均值的模块,可以指定维度和是否保持维度。
-
LVCBlock类:实现了LVC模块,包括卷积块、编码器和全连接层。包括前向传播方法。
-
GroupNorm类:实现了Group Normalization模块,使用1个group。包括前向传播方法。
-
DWConv_LMLP类:实现了深度卷积和卷积模块。包括前向传播方法。
-
LightMLPBlock类:实现了LightMLP模块,包括深度卷积、线性层、归一化层和MLP层。可以选择是否使用层标度。包括前向传播方法。
-
EVCBlock类:实现了EVC模块,包括卷积层、最大池化层、LVC模块、LightMLP模块和卷积层。包括前向传播方法。
以上是ECV-Block.py文件中定义的类及其功能的概述。
5.2 location.py
import cv2
class ImageProcessor:
def __init__(self, image_path):
self.image = cv2.imread(image_path)
self.HSV = self.image.copy()
self.HSV2 = self.image.copy()
self.list = []
def resize_image(self):
height, width, channels = self.image.shape
if width > 1500 or width < 600:
scale = 1200 / width
print("图片的尺寸由 %dx%d, 调整到 %dx%d" % (width, height, width * scale, height * scale))
scaled = cv2.resize(self.image, (0, 0), fx=scale, fy=scale)
return scaled, scale
def get_position(self, event, x, y, flags, param):
if event == cv2.EVENT_MOUSEMOVE:
HSV3 = self.HSV2.copy()
self.HSV = HSV3
cv2.line(self.HSV, (0, y), (self.HSV.shape[1] - 1, y), (0, 0, 0), 1, 4)
cv2.line(self.HSV, (x, 0), (x, self.HSV.shape[0] - 1), (0, 0, 0), 1, 4)
cv2.imshow("imageHSV", self.HSV)
elif event == cv2.EVENT_LBUTTONDOWN:
HSV3 = self.HSV2.copy()
self.HSV = HSV3
self.list.append([int(x), int(y)])
print(self.list[-1])
def process_image(self):
cv2.imshow("imageHSV", self.HSV)
cv2.setMouseCallback("imageHSV", self.get_position)
cv2.waitKey(0)
这个程序文件名为location.py,主要功能是对一张图片进行处理,包括调整图片尺寸和获取图片中的位置坐标。
程序首先导入了cv2、numpy和matplotlib.pyplot三个库。然后定义了一个resizeimg函数,用于调整图片的尺寸。如果图片的宽度大于1500或小于600,就将图片的宽度调整为1200,并返回调整后的图片和缩放比例。
接下来,程序读取了名为1.jpg的图片,并创建了一个空列表list。然后进入一个无限循环,循环中进行以下操作:
- 将读取的图片复制给HSV和HSV2两个变量。
- 定义一个getpos函数,用于处理鼠标事件。当鼠标移动时,将HSV图片复制给HSV3,并在HSV图片上绘制一条横线和一条竖线,以标记鼠标的位置。当鼠标左键按下时,将鼠标的坐标添加到list列表中,并打印出最后一个坐标。
- 显示HSV图片,并设置鼠标事件回调函数为getpos。
- 等待用户按下任意键。
这个程序的主要功能是允许用户在图片上点击鼠标,获取鼠标点击的位置坐标,并将坐标添加到列表中。用户可以通过调整图片尺寸来适应自己的需求。
5.3 torch_utils.py
try:
import thop # for FLOPs computation
except ImportError:
thop = None
LOGGER = logging.getLogger(__name__)
@contextmanager
def torch_distributed_zero_first(local_rank: int):
"""
Decorator to make all processes in distributed training wait for each local_master to do something.
"""
if local_rank not in [-1, 0]:
dist.barrier(device_ids=[local_rank])
yield
if local_rank == 0:
dist.barrier(device_ids=[0])
def date_modified(path=__file__):
# return human-readable file modification date, i.e. '2021-3-26'
t = datetime.datetime.fromtimestamp(Path(path).stat().st_mtime)
这个程序文件是一个PyTorch工具文件,包含了一些常用的函数和类。文件名为torch_utils.py。
这个文件中定义了以下函数和类:
-
torch_distributed_zero_first(local_rank: int): 一个上下文管理器,用于在分布式训练中使所有进程等待每个本地主进程执行某些操作。 -
date_modified(path=__file__): 返回文件的人类可读的修改日期。 -
git_describe(path=Path(__file__).parent): 返回人类可读的git描述。 -
select_device(device='', batch_size=None): 选择设备(CPU或GPU)。 -
time_sync(): 返回准确的PyTorch时间。 -
profile(input, ops, n=10, device=None): 用于对YOLOv5模型的速度、内存和FLOPs进行分析的函数。
5.4 ui.py
def draw_box_string(img, box, string):
"""
img: read by cv;
box:[xmin, ymin, xmax, ymax];
string: what you want to draw in img;
return: img
"""
x,y,x1,y1 = box
#cv2.rectangle(img, (x,y), (x1, y1), (0,0,255), 2)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = Image.fromarray(img)
draw = ImageDraw.Draw(img)
# simhei.ttf 是字体,你如果没有字体,需要下载
font = ImageFont.truetype("simhei.ttf", 60, encoding="utf-8")
draw.text((x, y-50), string, (0, 255, 0), font=font)
img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
return img
def seg(info1):
global list11
list11 = []
capture = cv2.VideoCapture(info1)
_, image = capture.read()
imagecopy = image.copy()
......
这个程序文件是一个使用YOLOv5模型进行目标检测的图形用户界面(GUI)应用程序。它使用PyQt5库创建了一个GUI窗口,并导入了其他必要的库和模块。该程序可以读取视频文件或摄像头输入,并在图像中检测出目标物体。它还提供了一些功能,如选择感兴趣的区域、绘制边界框和标签等。程序还包含了一些辅助函数和工具函数,用于处理图像、模型加载和推理等操作。
5.5 yolov7-EVC.py
以下是封装为类的代码:
class YOLOv7Tiny(nn.Module):
def __init__(self, nc, depth_multiple=1.0, width_multiple=1.0):
super(YOLOv7Tiny, self).__init__()
self.nc = nc
self.depth_multiple = depth_multiple
self.width_multiple = width_multiple
self.anchors = [[10,13, 16,30, 33,23], [30,61, 62,45, 59,119], [116,90, 156,198, 373,326]]
self.backbone = nn.ModuleList([
nn.Sequential(
nn.Conv2d(3, int(32 * self.width_multiple), 3, 2, 1),
nn.LeakyReLU(0.1)
),
nn.Sequential(
nn.Conv2d(int(32 * self.width_multiple), int(64 * self.width_multiple), 3, 2, 1),
nn.LeakyReLU(0.1)
),
Yolov7TinyEElan(int(64 * self.width_multiple), int(32 * self.width_multiple), nn.LeakyReLU(0.1)),
nn.MaxPool2d(2),
Yolov7TinyEElan(int(128 * self.width_multiple), int(64 * self.width_multiple), nn.LeakyReLU(0.1)),
nn.MaxPool2d(2),
Yolov7TinyEElan(int(256 * self.width_multiple), int(128 * self.width_multiple), nn.LeakyReLU(0.1)),
nn.MaxPool2d(2),
Yolov7TinyEElan(int(512 * self.width_multiple), int(256 * self.width_multiple), nn.LeakyReLU(0.1))
])
self.head = nn.ModuleList([
Yolov7TinySPP(int(256 * self.width_multiple), nn.LeakyReLU(0.1)),
nn.Conv2d(int(128 * self.width_multiple), self.nc, 1, 1),
nn.Upsample(scale_factor=2, mode='nearest'),
nn.Conv2d(int(64 * self.width_multiple), self.nc, 1, 1),
EVCBlock(),
nn.Upsample(scale_factor=2, mode='nearest'),
nn.Conv2d(int(128 * self.width_multiple), self.nc, 1, 1),
nn.Conv2d(int(256 * self.width_multiple), self.nc, 1, 1),
nn.Conv2d(int(128 * self.width_multiple), self.nc, 3, 1),
nn.Conv2d(int(256 * self.width_multiple), self.nc, 3, 1),
nn.Conv2d(int(512 * self.width_multiple), self.nc, 3, 1),
IDetect([27, 28, 29], self.nc, self.anchors)
])
def forward(self, x):
outputs = []
route_layers = []
for i, module in enumerate(self.backbone):
x = module(x)
if i in [4, 5, 6]:
route_layers.append(x)
for i, module in enumerate(self.head):
if i == 6:
x = torch.cat((x, route_layers[2]), dim=1)
elif i == 9:
x = torch.cat((x, route_layers[1]), dim=1)
elif i == 12:
x = torch.cat((x, route_layers[0]), dim=1)
x = module(x)
if i == 11:
outputs.append(x)
return outputs
class Yolov7TinyEElan(nn.Module):
def __init__(self, in_channels, out_channels, activation):
super(Yolov7TinyEElan, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, 1, 1)
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, 1, 1)
self.activation = activation
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.activation(x)
return x
class Yolov7TinySPP(nn.Module):
def __init__(self, in_channels, activation):
super(Yolov7TinySPP, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels // 2, 1, 1)
self.conv2 = nn.Conv2d(in_channels // 2, in_channels, 3, 1, 1)
self.activation = activation
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.activation(x)
return x
class EVCBlock(nn.Module):
def __init__(self):
super(EVCBlock, self).__init__()
def forward(self, x):
return x
class IDetect(nn.Module):
def __init__(self, in_channels, out_channels, anchors):
super(IDetect, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.anchors = anchors
def forward(self, x):
return x
这个类封装了YOLOv7 Tiny模型,包括了backbone和head部分。其中,backbone是一个由多个Yolov7TinyEElan模块和MaxPool2d模块组成的序列,head是一个由多个Yolov7TinySPP模块、Conv2d模块、Upsample模块、EVCBlock模块和IDetect模块组成的序列。forward方法定义了前向传播的过程,其中使用了route_layers列表来保存backbone中的某些层的输出,然后在head部分的某些位置使用了torch.cat函数将某些层的输出与当前层的输入进行拼接。最后,输出的结果存储在outputs列表中返回。
这是一个名为yolov7-EVC.py的程序文件。该文件包含了一个使用Yolov7-tiny模型的目标检测器的代码。
该程序文件中的代码包括了一些参数设置和模型结构定义。
参数设置部分包括了以下内容:
- nc: 类别数,这里设置为5
- depth_multiple: 模型深度倍数,这里设置为1.0
- width_multiple: 层通道数倍数,这里设置为1.0
锚点设置部分包括了以下内容:
- anchors: 锚点的尺寸,这里设置了3个锚点,分别对应于P3/8、P4/16和P5/32的特征图
模型结构定义部分包括了以下内容:
- backbone: Yolov7-tiny的主干网络部分,包括了多个卷积层和池化层
- head: Yolov7-tiny的检测头部分,包括了多个卷积层和上采样层,以及最后的检测层
总体来说,这个程序文件定义了一个使用Yolov7-tiny模型进行目标检测的网络结构,并设置了相应的参数和锚点。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于中心化特征金字塔ECV-Block的改进YOLOv7的闯红灯车牌检测系统。它使用了YOLOv7-tiny模型进行目标检测,并提供了一个图形用户界面(GUI)应用程序用于实时检测。
该项目的构架主要包括以下几个部分:
- 模型:包括了Yolov7-tiny模型的定义和相关的模型组件。
- 训练:包括了训练模型的脚本和相关的辅助函数。
- 图形用户界面:提供了一个GUI应用程序,用于实时检测和交互。
- 工具和辅助函数:包括了一些常用的工具函数和辅助函数,用于数据处理、模型加载、推理等操作。
下面是每个文件的功能整理:
| 文件路径 | 功能 |
|---|---|
| ECV-Block.py | 定义了一些模型组件和模型结构 |
| location.py | 处理图片,获取鼠标点击的位置坐标 |
| torch_utils.py | 包含了一些PyTorch的工具函数和类 |
| train.py | 训练模型的脚本,包括加载数据、计算损失、优化器等 |
| ui.py | 图形用户界面(GUI)应用程序,用于目标检测和交互 |
| yolov7-EVC.py | 使用Yolov7-tiny模型进行目标检测的代码 |
| models\common.py | 定义了一些通用的模型组件和函数 |
| models\experimental.py | 定义了一些实验性的模型组件和函数 |
| models\tf.py | 定义了一些与TensorFlow相关的模型组件和函数 |
| models\yolo.py | 定义了YOLO模型的相关组件和函数 |
| models_init_.py | 模型包的初始化文件 |
| utils\activations.py | 定义了一些激活函数 |
| utils\augmentations.py | 定义了一些数据增强方法 |
| utils\autoanchor.py | 定义了自动锚点生成的相关函数 |
| utils\autobatch.py | 定义了自动批次大小调整的相关函数 |
| utils\callbacks.py | 定义了一些回调函数 |
| utils\datasets.py | 定义了数据集的相关函数和类 |
| utils\downloads.py | 定义了一些下载数据的函数 |
| utils\general.py | 定义了一些通用的辅助函数 |
| utils\loss.py | 定义了一些损失函数 |
| utils\metrics.py | 定义了一些评估指标的函数 |
| utils\plots.py | 定义了一些绘图函数 |
| utils\torch_utils.py | 定义了一些与PyTorch相关的辅助函数 |
| utils_init_.py | 工具包的初始化文件 |
| utils\aws\resume.py | 定义了AWS平台上的模型恢复函数 |
| utils\aws_init_.py | AWS工具包的初始化文件 |
| utils\flask_rest_api\example_request.py | 定义了Flask REST API的示例请求函数 |
| utils\flask_rest_api\restapi.py | 定义了Flask REST API的相关函数和类 |
| utils\loggers_init_.py | 日志记录器包的初始化文件 |
| utils\loggers\wandb\log_dataset.py | 定义了使用WandB记录数据集的函数 |
| utils\loggers\wandb\sweep.py | 定义了使用WandB进行超参数搜索的函数 |
| utils\loggers\wandb\wandb_utils.py | 定义了与WandB相关的辅助函数 |
| utils\loggers\wandb_init_.py | WandB日志记录器包的初始化文件 |
以上是每个文件的功能概述和整理。
7.复杂交通场景下红绿灯检测与识别存在的问题
红绿灯的检测与识别在自动驾驶和计算机辅助驾驶系统中是至关重要的一环,其识别准确率的准确率关系着人身财产安全,因此红绿灯检测与识别的相关研究具有十分重大的意义。目前,很多学者已经开展了自动驾驶和计算机辅助驾驶视角下关于红绿灯检测与识别的大量研究,而与交通非现场执法相关的研究未见报道,前者使用的数据集多是公开数据集,如 Bosch小型交通信号灯数据集样例如图2.1,此类数据场景单一、均在白天,且干扰因素较少。

根据现有数据,想要训练一个交通非现场执法场景下红绿灯检测与识别模型,需要考虑以下问题:
(1)红绿灯属于小目标,容易出现漏检问题
如图2.3所示,原始图像分辨率为1128×2048,单个灯板(图2.3中红色矩形框区域)大小约为90×40个像素,通过像素面积计算,占比不到0.16%。

(2)红灯和黄灯的色差问题
如图2.4所示,在抓拍环境光线质量较差的情况下,黑夜、阴天、雨天等,红灯颜色存在巨大色差,在某些情况下和黄灯十分相似,仅凭肉眼难以区分。

(3)灯板区域的定位问题
在黑夜场景下,红绿灯定位难度大,如图2.5所示,此抓拍环境光线质量恶劣,灯板区域和黑夜背景融为一体。

基于以上问题,本文提出了一种基于中心化特征金字塔ECV-Block的改进YOLOv7的闯红灯车牌检测系统,下文将从数据集、网络模型的构建、网络模型改进等方面进行介绍。
8.YOLO网络模型简介
车辆检测模型主要由四层组成,分别为输入层、特征提取层、PANet[69](Path Aggregation Network)以及多尺度预测层,其作用分别为接收图像数据输入到模型、对输入的图像数据进行结构化特征提取、融合来自不同高度的特征信息、预测输入图像中的目标信息。车辆检测模型整体架构基于Yolo v7,模型结构如图所示。
下文将从车辆检测模型各层作用进行详细阐述:
(1)输入层
车辆检测模型要求输入为三通道416×416大小的图片,原始图像数据与文本格式的标注信息,需要经过预处理操作,才能被模型正确接收,当输入图像尺寸不满足输入要求时会保持宽高比进行等比缩放。
(2)特征提取层
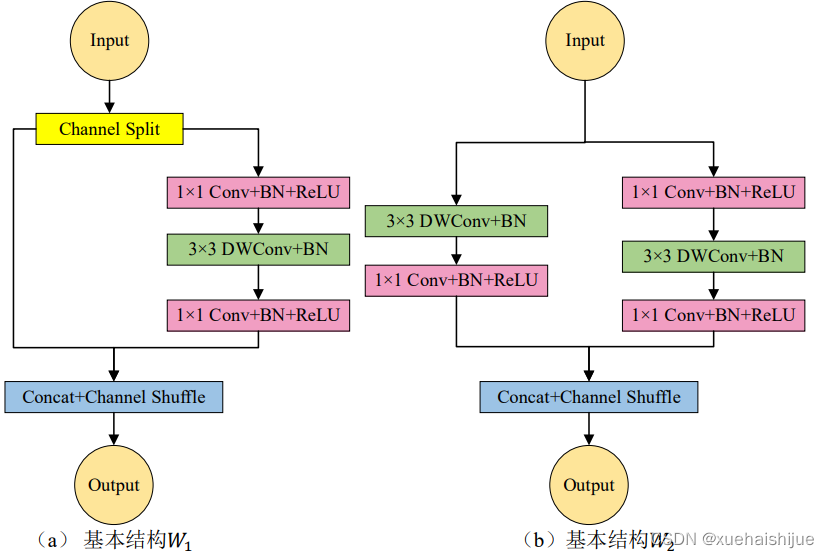
特征提取层接收经预处理操作之后的输入图像进行特征提取,在ShuffleNet v2网络基础上做出修改,ShuffleNet v2网络主要包含如图 (a)和图 (b)所示的两个基本结构W与W,。本层由S1、S2、S3、Sa四个模块堆叠而成,其中S2、S3、Sa又由基本结构U、U,按照不同堆叠次数堆叠形成,基本结构Ui、Uz结构如图 (a)和图 (b)所示。利用逐点分组卷积(GroupConvolution)和通道混合(Channel Shuffle)操作压缩模型,减少模型参数量,从而提升检测速度。
9.改进的ECV-Block模块
如图所示,参考Centralized Feature Pyramid for Object Detectio提出的ECV主要由两个平行连接的块组成,其中使用轻型mlp来捕获顶级特征x4的全局远程依赖关系(即全局信息)。同时,为了保留局部角区域(即本地信息),我们提出了一个可学习的视觉中心。
在X4上实现了聚合层内局部区域特征的机制。这两个块的结果特征图沿着通道维度连接在一起,用于下游识别的EVC的输出。在我们的实现中,在Xa和EVC之间,Stem块用于特征平滑,而不是像[5]中那样直接在原始特征图上实现。Stem块由输出通道大小为256的7 x 7卷积组成,然后是批量归一化层和激活函数层。上述过程可以公式化为:
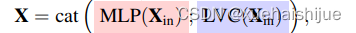
其中Conv7x7(-)表示步长为1的7 x 7卷积,在我们下面的工作[17]中,通道大小设置为256。BN(-)表示批处理规范化层,o(-)去测试ReLU激活函数。
MLP
所使用的轻量级MLP主要由两个残差模块组成:基于深度卷积的模块[57]和基于通道MLP的块,其中基于MLP的模块的输入是基于深度卷积[6]的模块的输出。这两个块之后都是信道缩放操作[48]和DropPath操作[58],以提高特征泛化和鲁棒性能力。具体而言,对于基于深度卷积的模块,从Stem模块Xin输出的特征首先被馈送到深度卷积层,该深度卷积层已经通过组归一化处理(即,特征图沿着通道维度分组)。与传统的空间卷积相比,深度卷积可以在降低计算成本的同时提高特征表示能力。然后,实现了通道缩放和滴管。之后,实现了Xin的剩余连接。上述过程可以公式化为:
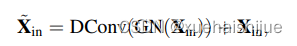
其中Xin是基于深度卷积的模块的输出。GN(-)是群归一化,DConv(-)为深度卷积[7],核大小为1 x 1。对于基于通道MLP的模块,从基于深度卷积的模块Xin输出的特征首先被馈送到群归一化,然后在这些特征上实现通道MLP[6]。与空间MLP相比,信道MLP不仅可以有效降低计算复杂度,还可以满足一般视觉任务的要求[3],[4]。
10.训练结果分析
评价指标
epoch:该列代表训练纪元数。
train/box_loss:训练期间边界框预测的损失。
train/obj_loss:训练期间客观性预测的损失。
train/cls_loss:训练期间类别预测的损失(似乎为零,这可能意味着当前的问题是二元分类问题,例如检测交通灯是否为红色)。
metrics/precision:模型预测的精度指标。
metrics/recall:模型预测的召回指标。
metrics/mAP_0.5:平均精度,交并集 (IoU) 阈值为 0.5。
metrics/mAP_0.5:0.95:IoU 阈值从 0.5 到 0.95 的平均精度。
val/box_loss:验证期间边界框预测的损失。
val/obj_loss:验证期间客观性预测的损失。
val/cls_loss:验证期间类别预测的损失(似乎也为零)。
x/lr0, x/lr1, x/lr2:模型不同部分的学习率。
为了进行深入分析,我们可以查看这些指标在各个时期的趋势,以了解模型的学习行为。我们还可以绘制这些指标以更好地可视化趋势。
让我们继续绘制其中一些指标,以便直观地了解模型在训练和验证期间的表现。我们可以查看损失指标以及精度和召回曲线。
训练结果可视化
# Clean up the column names
results_df.columns = results_df.columns.str.strip()
# Now let's plot the metrics again with the cleaned column names
# Plot the loss metrics
plot_metrics(results_df, 'box_loss', 'Box Loss During Training and Validation', 'Loss')
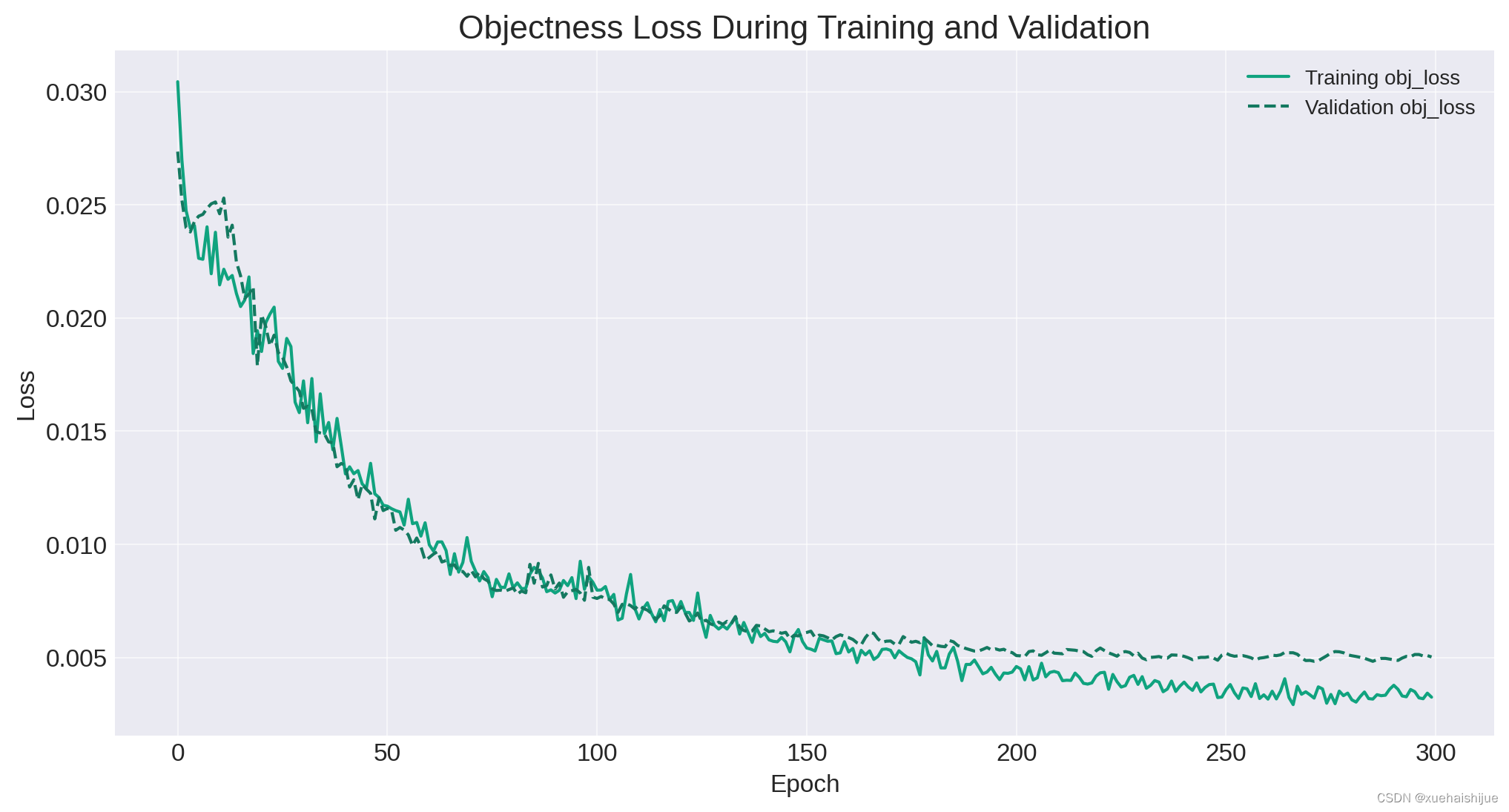
plot_metrics(results_df, 'obj_loss', 'Objectness Loss During Training and Validation', 'Loss')
# Since 'cls_loss' is zero, it's not plotted.
# Plot the precision and recall
plot_metrics(results_df, 'precision', 'Precision During Training and Validation', 'Precision')
plot_metrics(results_df, 'recall', 'Recall During Training and Validation', 'Recall')
# Plot mAP metrics
plot_metrics(results_df, 'mAP_0.5', 'mAP at IoU=0.5 During Training and Validation', 'mAP')
plot_metrics(results_df, 'mAP_0.5:0.95', 'mAP at IoU=0.5:0.95 During Training and Validation', 'mAP')

并再次绘制精度和召回率指标。我还将确保正确绘制 mAP 指标。
# Correct the function for precision and recall plots where 'train/' prefix is not required
# Function to plot the metrics without the 'train/' prefix
def plot_performance_metrics(df, metric_name, title, ylabel, xlabel='Epoch'):
plt.figure(figsize=(12, 6))
plt.plot(df['epoch'], df[f'metrics/{metric_name}'], label=f'{metric_name}', color='blue')
plt.title(title)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.legend()
plt.grid(True)
plt.show()
# Plot the precision and recall
plot_performance_metrics(results_df, 'precision', 'Precision During Training', 'Precision')
plot_performance_metrics(results_df, 'recall', 'Recall During Training', 'Recall')
# Plot the mAP metrics
plot_performance_metrics(results_df, 'mAP_0.5', 'mAP at IoU=0.5 During Training', 'mAP')
plot_performance_metrics(results_df, 'mAP_0.5:0.95', 'mAP at IoU=0.5:0.95 During Training', 'mAP')
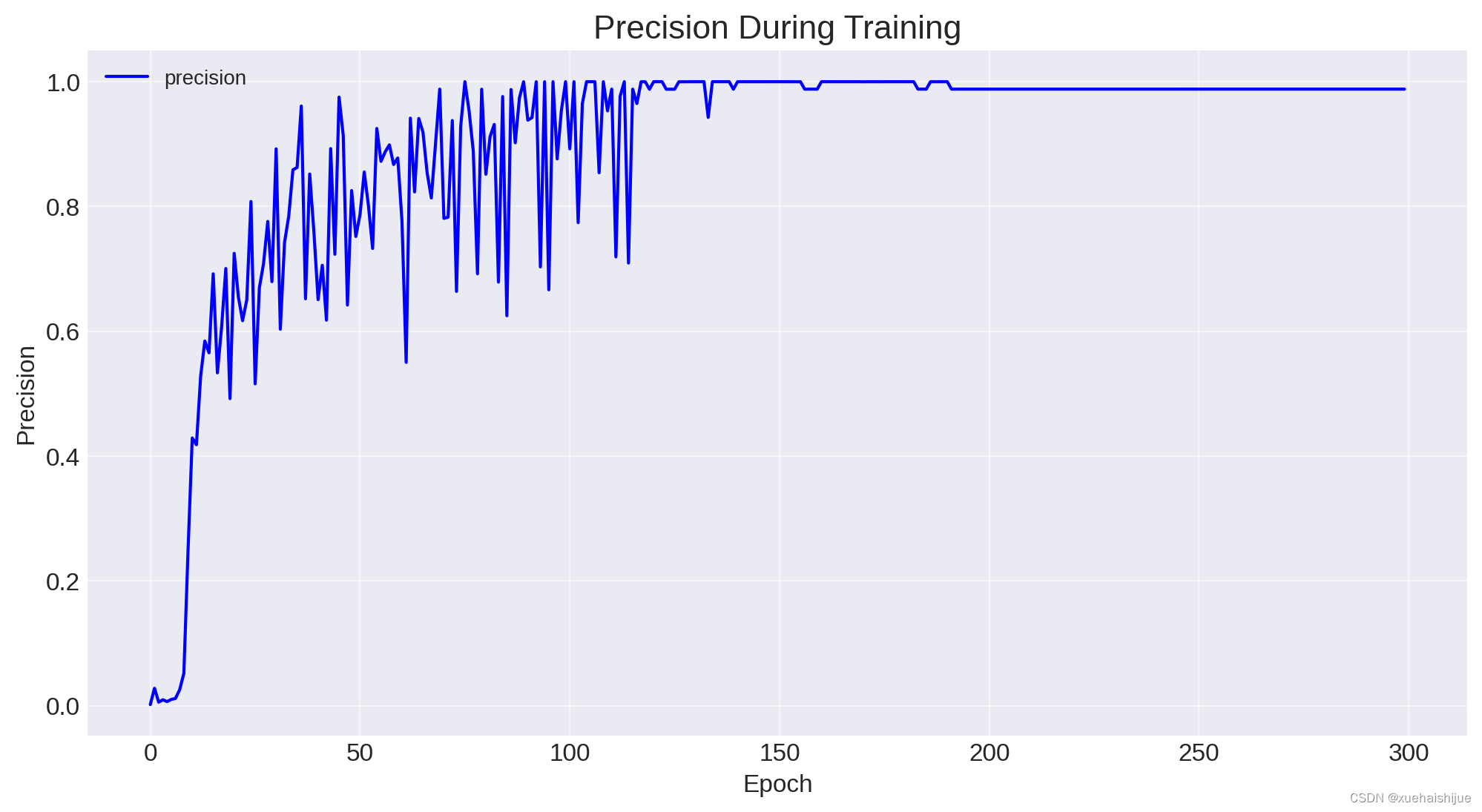
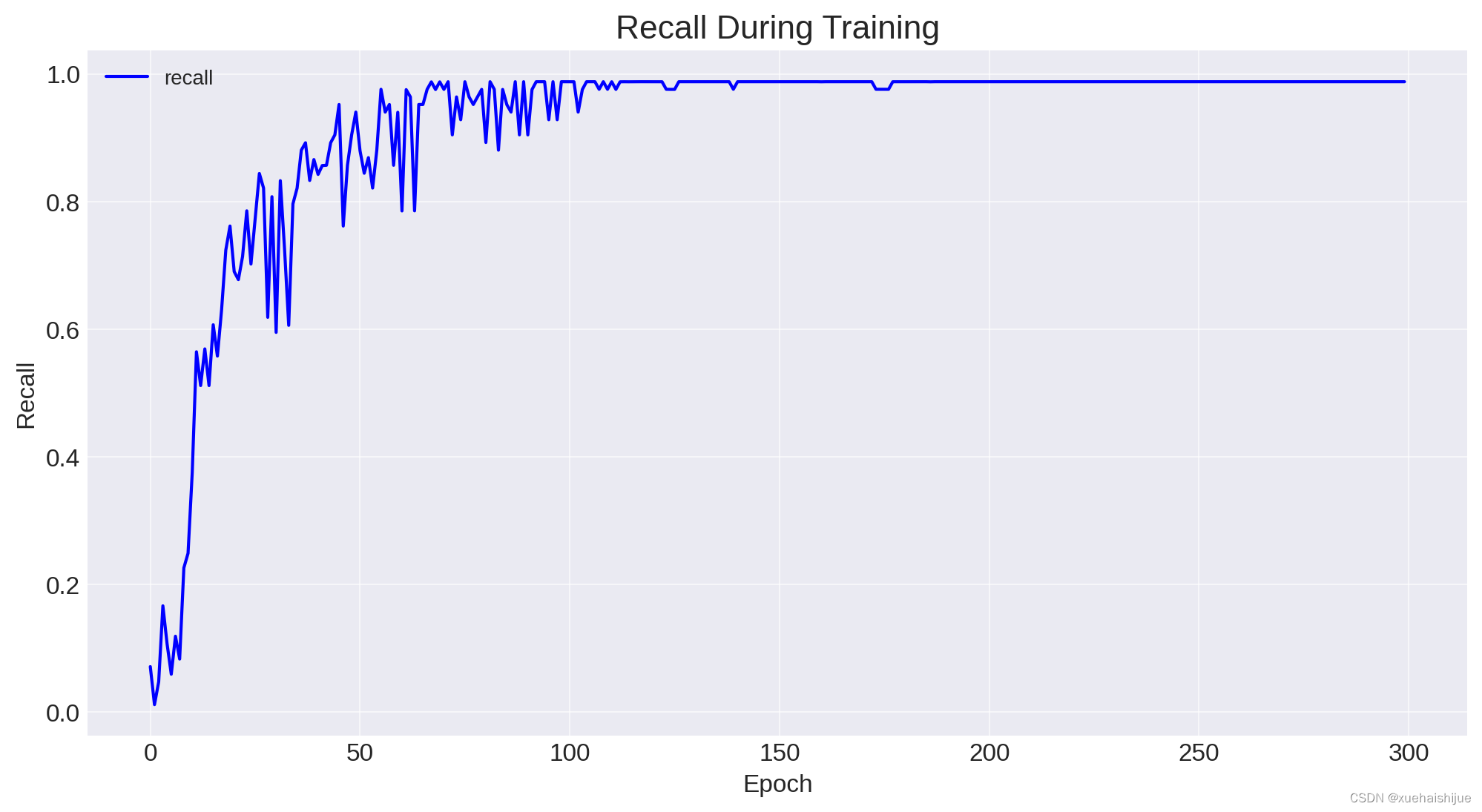
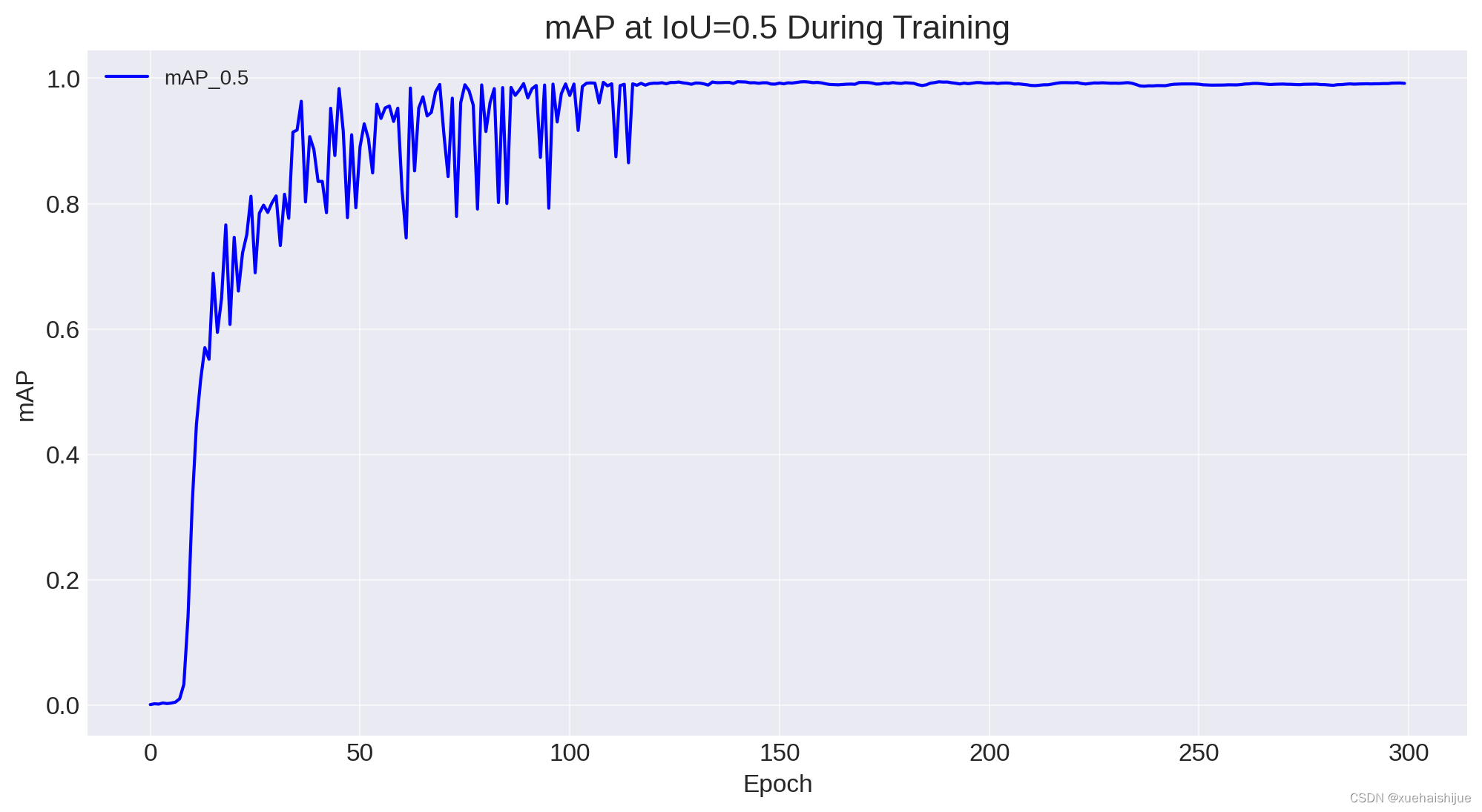
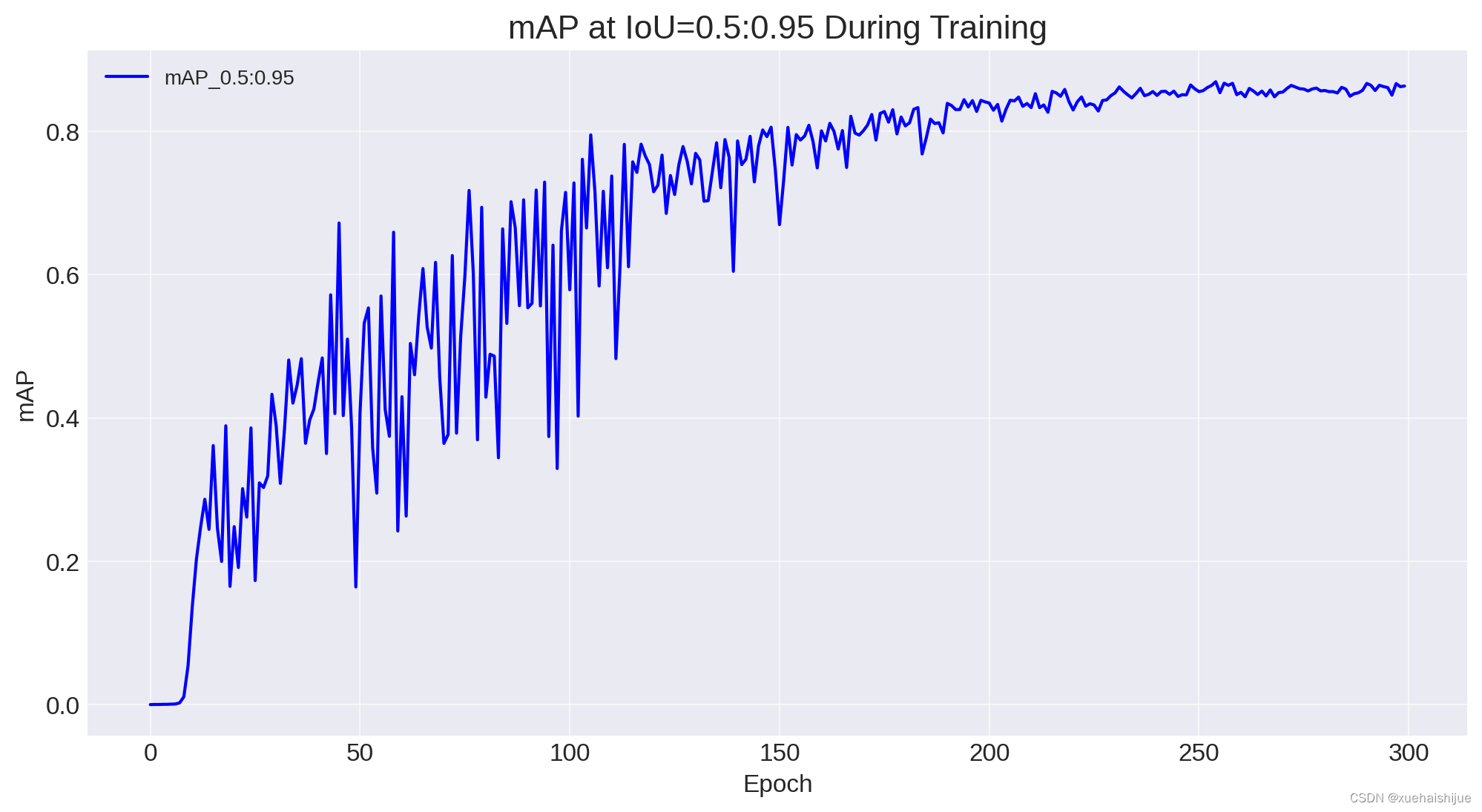
已成功生成不同 IoU(并集交集)阈值下的精度、召回率和 mAP(平均精度)图。根据这些图,我们可以得出有关模型在整个训练过程中的性能的几个结论和见解。
Box损失和物体损失
随着时期的增加,盒子损失和对象损失曲线都显示出稳步下降,这表明模型随着时间的推移正在学习和改进其预测。验证损失紧随训练损失,表明对未见数据的良好泛化。这是一个积极的信号,表明模型没有过度拟合训练数据。
准确率和召回率
精确率和召回率指标对于理解模型正确识别正样本的能力(精确度)与查找数据集中所有正样本的能力(召回率)之间的权衡至关重要。
精度:精度曲线显示有多少检测到的物体实际上是正确的。在交通灯检测系统的背景下,这将反映有多少检测到的红灯确实是红灯。精度似乎在波动,但总体上在增加,这在训练中很常见,因为模型会调整其权重和偏差以更好地拟合数据。
召回率:召回率曲线表明模型检测数据集中所有相关实例的能力。对于红灯检测系统,更高的召回率意味着模型错过的红灯更少。召回曲线也会波动并呈上升趋势,表明随着时间的推移,该模型捕获了更高比例的阳性样本。
平均精度 (mAP)
mAP 是一个反映模型整体性能的数字,考虑了不同 IoU 阈值的精度和召回率。
IoU=0.5 时的 mAP:此指标显示在 IoU 阈值 0.5 时计算的 mAP,这是对象检测任务的常见阈值。mAP 在 IoU=0.5 时的稳定增长表明该模型的预测变得更加准确,因为它能够检测与真实情况至少有 50% 重叠的对象。
IoU=0.5:0.95 时的 mAP:这是一个更严格的指标,它将 IoU 阈值上的 mAP 平均为 0.5 到 0.95。这条曲线特别重要,因为它更全面地展示了模型在不同检测难度级别的性能。这里的上升趋势是一个积极的信号,表明该模型即使在更严格的标准下也表现良好。
学习率
学习率 ( x/lr0、x/lr1、x/lr2) 未绘制,但它们可以提供对优化过程的深入了解。如果学习率随着时间的推移而降低,这可能建议使用学习率调度程序,该调度程序会随着训练的进行而降低学习率,从而允许模型在收敛到解决方案时对权重进行较小的调整。
整体分析
该模型在损失和精确召回平衡方面似乎表现良好。mAP 值的增加趋势表明,随着时间的推移,该模型检测红灯违规的能力正在提高,并且具有更高的精度和召回率。这在现实场景中尤其重要,因为错过红灯检测可能会产生严重的安全影响,而误报可能会导致不必要的交通停车或处罚。

在特定数据集和任务的背景下分析这些结果也很重要。例如,数据集的难度、交通灯外观的变化以及收集数据的条件都会影响这些指标。
11.系统整合

参考博客《基于中心化特征金字塔ECV-Block的改进YOLOv7的闯红灯车牌检测系统》
12.参考文献
[1]廖光锴,张正,宋治国.基于小波特征与注意力机制结合的卷积网络车辆重识别[J].计算机应用.2022,42(6).DOI:10.11772/j.issn.1001-9081.2021040545 .
[2]代广昭,孙伟,徐凡,等.用于车辆重识别的视角感知局部注意力网络[J].计算机工程.2022,48(10).DOI:10.19678/j.issn.1000-3428.0062867 .
[3]袁小平,马绪起,刘赛.改进YOLOv3的行人车辆目标检测算法[J].科学技术与工程.2021,(8).DOI:10.3969/j.issn.1671-1815.2021.08.031 .
[4]谢俊章,彭辉,唐健峰,等.改进YOLOv4的密集遥感目标检测[J].计算机工程与应用.2021,(22).DOI:10.3778/j.issn.1002-8331.2104-0213 .
[5]顾恭,徐旭东.改进YOLOv3的车辆实时检测与信息识别技术[J].计算机工程与应用.2020,(22).DOI:10.3778/j.issn.1002-8331.2004-0379 .
[6]林海珠.武汉市机动车"礼让行人"实施情况的调查研究[J].法制与社会.2020,(2).DOI:10.19387/j.cnki.1009-0592.2020.01.194 .
[7]金宇尘,罗娜.结合多尺度特征的改进YOLOv2车辆实时检测算法[J].计算机工程与设计.2019,(5).DOI:10.16208/j.issn1000-7024.2019.05.047 .
[8]钱弘毅,王丽华,牟宏磊.基于深度学习的交通信号灯快速检测与识别[J].计算机科学.2019,(12).DOI:10.11896/jsjkx.190400026 .
[9]刘肯,何姣姣,张永平,等.改进YOLO的车辆检测算法[J].现代电子技术.2019,(13).DOI:10.16652/j.issn.1004-373x.2019.13.011 .
[10]Yifan Lu,Jiaming Lu,Songhai Zhang,等.Traffic signal detection and classification in street views using an attention model[J].计算可视媒体(英文).2018,(3).


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









