






 本文介绍了基于深度学习的轨道侵限异物入侵检测系统,旨在提高轨道交通安全性和运营效率。系统利用深度学习模型进行目标检测,通过收集、标注和整理数据,结合通道注意力和空间注意力机制,训练YOLO模型。该系统能自动识别轨道上的异物,减少人工巡检的局限性,促进轨道交通智能化发展。
本文介绍了基于深度学习的轨道侵限异物入侵检测系统,旨在提高轨道交通安全性和运营效率。系统利用深度学习模型进行目标检测,通过收集、标注和整理数据,结合通道注意力和空间注意力机制,训练YOLO模型。该系统能自动识别轨道上的异物,减少人工巡检的局限性,促进轨道交通智能化发展。
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
近年来,随着城市化进程的加快和交通运输的快速发展,轨道交通系统在城市中的重要性日益凸显。然而,由于轨道交通系统的复杂性和高度开放性,轨道侵限异物入侵事件时有发生,给轨道交通的安全运营带来了严重的威胁。因此,开发一种高效准确的轨道侵限异物入侵检测系统具有重要的现实意义。
传统的轨道侵限异物入侵检测方法主要依赖于人工巡检和传感器监测,但这些方法存在一些局限性。首先,人工巡检需要大量的人力和时间投入,效率低下且容易出现疏漏。其次,传感器监测技术虽然能够实时监测轨道状态,但在异物入侵检测方面存在一定的局限性,如对小尺寸、低对比度的异物检测效果不佳。因此,需要一种更加高效准确的轨道侵限异物入侵检测方法来提高轨道交通系统的安全性和运营效率。
深度学习作为一种基于人工神经网络的机器学习方法,具有强大的特征学习和模式识别能力,已经在图像识别、语音识别、自然语言处理等领域取得了显著的成果。基于深度学习的轨道侵限异物入侵检测系统能够通过学习大量的轨道图像数据,自动提取图像特征并进行异物检测,从而实现对轨道侵限异物的准确识别和及时报警。
基于深度学习的轨道侵限异物入侵检测系统具有以下几个方面的意义:
-
提高轨道交通系统的安全性:通过准确识别和及时报警轨道侵限异物,可以有效防止异物对轨道交通系统的安全运营造成的潜在危害,保障乘客和运营人员的生命安全。
-
提高轨道交通系统的运营效率:传统的人工巡检方法耗时耗力,而基于深度学习的轨道侵限异物入侵检测系统可以实现自动化检测,大大提高了检测效率,减少了人力投入和运营成本。
-
推动深度学习技术在轨道交通领域的应用:基于深度学习的轨道侵限异物入侵检测系统是深度学习技术在轨道交通领域的一次尝试,其成功应用将为其他轨道交通安全问题的解决提供借鉴和参考。
-
促进轨道交通系统的智能化发展:基于深度学习的轨道侵限异物入侵检测系统是轨道交通系统智能化发展的重要组成部分,其应用将推动轨道交通系统向智能化方向迈进,提高整个系统的自动化水平和智能化程度。
综上所述,基于深度学习的轨道侵限异物入侵检测系统具有重要的研究背景和意义。通过该系统的研发和应用,可以提高轨道交通系统的安全性和运营效率,推动深度学习技术在轨道交通领域的应用,促进轨道交通系统的智能化发展。
2.图片演示



3.视频演示
基于深度学习的轨道侵限异物入侵检测系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集MOT20。

labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。

由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。
下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 attention_modules.py
封装为类后的代码如下:
class ChannelAttention(nn.Module):
def __init__(self, num_channels, reduction_ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Linear(num_channels, num_channels // reduction_ratio, bias=False),
nn.ReLU(),
nn.Linear(num_channels // reduction_ratio, num_channels, bias=False),
nn.Sigmoid()
)
def forward(self, x):
avg_out = self.fc(self.avg_pool(x).view(x.size(0), -1))
max_out = self.fc(self.max_pool(x).view(x.size(0), -1))
out = avg_out + max_out
return out.view(x.size(0), -1, 1, 1) * x
这个类是一个通道注意力机制的实现,用于增强模型对通道特征的关注。它包含了一个自适应平均池化层和一个自适应最大池化层,以及两个全连接层和一个Sigmoid激活函数。在前向传播过程中,输入x经过平均池化和最大池化后,分别经过两个全连接层得到avg_out和max_out,然后将它们相加得到out。最后,将out与输入x相乘,得到最终的输出。这个类可以用于增强模型对通道特征的关注,提高模型的性能。
这个程序文件名为attention_modules.py,它定义了一个名为ChannelAttention的类。这个类是一个继承自nn.Module的模块,用于实现通道注意力机制。
在类的初始化方法中,它接受两个参数:num_channels表示输入张量的通道数,reduction_ratio表示通道压缩比。在初始化方法中,它定义了一个自适应平均池化层(nn.AdaptiveAvgPool2d)和一个自适应最大池化层(nn.AdaptiveMaxPool2d)。然后,它定义了一个包含两个线性层和一个ReLU激活函数的全连接网络(nn.Sequential),用于对输入张量进行通道压缩和激活。最后,它定义了一个Sigmoid激活函数,用于输出通道注意力权重。
在forward方法中,它首先对输入张量进行平均池化和最大池化操作,并通过全连接网络得到平均池化和最大池化的输出。然后,它将两者相加得到最终的通道注意力权重,并将其与输入张量相乘,得到加权后的输出。最后,它将输出的形状调整为与输入张量相同的形状,并返回结果。
这个类的作用是对输入张量的通道进行注意力加权,以提取重要的特征信息。
5.2 demo.py
class BoundingBox:
def __init__(self, x1, y1, x2, y2, cls_id, pos_id):
self.x1 = x1
self.y1 = y1
self.x2 = x2
self.y2 = y2
self.cls_id = cls_id
self.pos_id = pos_id
class BoundingBoxTracker:
def __init__(self):
self.detector = Detector()
self.pointlist = [[] for i in range(100)]
self.pointcopy = [[] for i in range(100)]
self.count = 0
self.rr = 0
self.blue = []
self.green = []
def draw_bboxes(self, image, bboxes, line_thickness, pointlist, blue, green):
line_thickness = line_thickness or round(0.002 * (image.shape[0] + image.shape[1]) * 0.5) + 1
list_pts = []
point_radius = 4
for bbox in bboxes:
color = (0, 255, 0)
check_point_x = bbox.x1
check_point_y = int(bbox.y1 + ((bbox.y2 - bbox.y1) * 0.6))
c1, c2 = (bbox.x1, bbox.y1), (bbox.x2, bbox.y2)
xx = int((bbox.x1 + bbox.x2)/2)
yy = int((bbox.y1 + bbox.y2)/2)
pointlist[int(bbox.pos_id)].append([xx,yy])
blue.append([xx,yy])
font_thickness = max(line_thickness - 1, 1)
t_size = cv2.getTextSize(bbox.cls_id, 0, fontScale=line_thickness / 3, thickness=font_thickness)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
list_pts.append([check_point_x - point_radius, check_point_y - point_radius])
list_pts.append([check_point_x - point_radius, check_point_y + point_radius])
list_pts.append([check_point_x + point_radius, check_point_y + point_radius])
list_pts.append([check_point_x + point_radius, check_point_y - point_radius])
ndarray_pts = np.array(list_pts, np.int32)
list_pts.clear()
return image, pointlist, blue, green
def draw_cross(self, img, x, y, color):
cv2.line(img, (x - 5, y + 5), (x + 5, y - 5), color, 3)
cv2.line(img, (x - 5, y - 5), (x + 5, y + 5), color, 3)
return img
def track(self, video_path):
capture = cv2.VideoCapture(video_path)
while True:
_, im = capture.read()
self.count += 1
if im is None:
break
im = cv2.resize(im, (960, 540))
list_bboxs = []
bboxes = self.detector.detect(im)
if len(bboxes) > 0:
list_bboxs = tracker.update(bboxes, im)
output_image_frame, self.pointlist, self.blue, self.green = self.draw_bboxes(im, list_bboxs, line_thickness=1, pointlist=self.pointlist, blue=self.blue, green=self.green)
if self.rr == 1:
for poo in self.green:
cv2.circle(im, (poo[0], poo[1]), 3, [0, 255, 0], -1)
for ii in range(len(self.pointlist)):
if self.pointlist[ii] != []:
for po in range(len(self.pointlist[ii])):
if self.rr == 1:
color0 = [0, 0, 255]
else:
color0 = [255, 0, 0]
cv2.circle(im, (self.pointlist[ii][po][0], self.pointlist[ii][po][1]), 3, color0, -1)
if po == len(self.pointlist[ii]) - 1:
im = self.draw_cross(im, self.pointlist[ii][po][0], self.pointlist[ii][po][1], color0)
for ii in range(len(self.pointcopy)):
if self.pointcopy[ii] != []:
for po in self.pointcopy[ii]:
cv2.circle(im, (po[0], po[1]), 3, (255, 0, 0),-1)
if self.count > 50:
self.rr = 1
self.count = 0
self.green = []
for jj in range(50):
for ii in range(len(self.pointlist)):
if self.pointlist[ii] != []:
if jj < len(self.pointlist[ii]):
detax = self.pointlist[ii][-1][0] - self.pointlist[ii][0][0]
detay = self.pointlist[ii][-1][1] - self.pointlist[ii][0][1]
cv2.circle(im, (self.pointlist[ii][jj][0] + detax, self.pointlist[ii][jj][1] + detay), 3, (0, 255, 0), -1)
if detay < -50:
detay = int(detay*1.2)
if detay < 0 and detay > -50:
detay = int(detay*1.1)
if detay > 50:
detay = int(detay*1.2)
if detay > 0 and detay < 50:
detay = int(detay*1.1)
self.green.append([self.pointlist[ii][jj][0] + detax, self.pointlist[ii][jj][1] + detay])
cv2.imshow('frame', im)
cv2.waitKey(100)
self.pointcopy = self.pointlist.copy()
self.pointlist = [[] for i in range(100)]
else:
output_image_frame = im
cv2.imshow('frame', output_image_frame)
cv2.waitKey(1)
capture.release()
cv2.destroyAllWindows()
这个程序文件是一个视频目标跟踪的程序。它使用了numpy、OpenCV、matplotlib和PyQt5等库。程序首先导入所需的库和模块,然后定义了一些辅助函数。接下来,在主函数中,程序初始化了一个目标检测器和一些变量,然后打开了一个视频文件。程序通过循环读取视频的每一帧图像,并对图像进行处理。如果图像中有目标检测到,程序会使用目标跟踪算法对目标进行跟踪,并在图像上绘制目标框和一些标记点。程序还实现了一些其他功能,如撞线检测和预测。最后,程序释放了视频资源并关闭窗口。
5.3 detector_CPU.py
class Detector:
def __init__(self):
self.img_size = 640
self.threshold = 0.2
self.stride = 1
self.weights = './weights/output_of_small_target_detection.pt'
self.device = '0' if torch.cuda.is_available() else 'cpu'
self.device = select_device(self.device)
model = attempt_load(self.weights, map_location=self.device)
model.to(self.device).eval()
model.float()
self.m = model
self.names = model.module.names if hasattr(model, 'module') else model.names
def preprocess(self, img):
img0 = img.copy()
img = letterbox(img, new_shape=self.img_size)[0]
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.float()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
return img0, img
def detect(self, im):
im0, img = self.preprocess(im)
pred = self.m(img, augment=False)[0]
pred = pred.float()
pred = non_max_suppression(pred, self.threshold, 0.4)
boxes = []
for det in pred:
if det is not None and len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
for *x, conf, cls_id in det:
lbl = self.names[int(cls_id)]
if lbl not in ['car','bus','truck']:
continue
x1, y1 = int(x[0]), int(x[1])
x2, y2 = int(x[2]), int(x[3])
xm = x2
ym = y2
boxes.append((x1, y1, x2, y2, lbl, conf))
return boxes
这个程序文件名为detector_CPU.py,它是一个目标检测器的类。该类有以下几个方法:
-
__init__(self): 初始化方法,设置了一些参数和模型的路径,并加载模型。 -
preprocess(self, img): 预处理方法,将输入的图像进行缩放和转换为模型需要的格式。 -
detect(self, im): 检测方法,接收一个图像作为输入,并使用加载的模型进行目标检测,返回检测到的目标框的坐标和类别。
整个程序的功能是使用已训练好的模型进行目标检测。它首先加载模型和一些参数,然后提供了预处理和检测方法,可以用于对输入图像进行目标检测。
5.4 detector_GPU.py
class Detector:
def __init__(self):
self.img_size = 640
self.threshold = 0.1
self.stride = 1
self.weights = './weights/Attention_mechanism.pt'
self.device = '0' if torch.cuda.is_available() else 'cpu'
self.device = select_device(self.device)
model = attempt_load(self.weights, map_location=self.device)
model.to(self.device).eval()
model.half()
self.m = model
self.names = model.module.names if hasattr(model, 'module') else model.names
def preprocess(self, img):
img0 = img.copy()
img = letterbox(img, new_shape=self.img_size)[0]
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.half()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
return img0, img
def detect(self, im):
im0, img = self.preprocess(im)
pred = self.m(img, augment=False)[0]
pred = pred.float()
pred = non_max_suppression(pred, self.threshold, 0.4)
boxes = []
for det in pred:
if det is not None and len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
for *x, conf, cls_id in det:
lbl = self.names[int(cls_id)]
if lbl not in ['bicycle','car', 'bus', 'truck']:
continue
x1, y1 = int(x[0]), int(x[1])
x2, y2 = int(x[2]), int(x[3])
xm = x2
ym = y2
if ym +0.797* xm -509.77 > 0:
boxes.append((x1, y1, x2, y2, lbl, conf))
return boxes
这个程序文件名为detector_GPU.py,它是一个目标检测器的类。该类的初始化函数设置了一些参数,包括图像大小、阈值和步长。它还加载了一个预训练模型,并将模型移动到可用的设备上。
类中的preprocess函数用于对输入图像进行预处理,包括调整图像大小、转换颜色通道顺序和转换为张量。
detect函数用于对输入图像进行目标检测。它首先调用preprocess函数对图像进行预处理,然后使用加载的模型对图像进行推理。最后,它根据预测结果筛选出指定类别的目标框,并返回这些目标框的坐标和类别信息。
总之,这个程序文件实现了一个基于GPU的目标检测器,可以用于检测自行车、汽车、公交车和卡车等目标。
5.5 eval_cv.py
class Evaluation:
def __init__(self):
self.logger = MLLogger(init=False)
def evaluate(self):
args = get_args()
np.random.seed(args.seed)
start = time.time()
self.logger.initialize(args.root_dir)
self.logger.info(vars(args))
save_dir = self.logger.get_savedir()
self.logger.info("Written to {}".format(save_dir))
summary = SummaryLogger(args, self.logger, os.path.join(args.root_dir, "summary.csv"))
summary.update("finished", 0)
data_dir = os.getenv("TRAJ_DATA_DIR")
data = joblib.load(args.in_data)
traj_len = data["trajectories"].shape[1]
valid_split = args.eval_split + args.nb_splits
valid_dataset = SceneDatasetCV(data, args.input_len, args.offset_len, args.pred_len,
arg.width, args.height, data_dir, valid_split, -1,
False, "scale" in args.model, args.ego_type)
self.logger.info(valid_dataset.X.shape)
data_idxs = [0, 1, 2, 7]
if data_idxs is None:
self.logger.info("Invalid argument: model={}".format(args.model))
exit(1)
model = get_model(args)
prediction_dict = {
"arguments": vars(args),
"predictions": {}
}
valid_iterator = iterators.MultiprocessIterator(
valid_dataset, args.batch_size, False, False, n_processes=args.nb_jobs)
valid_eval = Evaluator("valid", args)
self.logger.info("Evaluation...")
chainer.config.train = False
chainer.config.enable_backprop = False
for itr, batch in enumerate(valid_iterator):
batch_array = [convert.concat_examples([x[idx] for x in batch], args.gpu) for idx in data_idxs]
loss, pred_y, prob = model.predict(tuple(map(Variable, batch_array)))
valid_eval.update(cuda.to_cpu(loss.data), pred_y, batch)
write_prediction(prediction_dict["predictions"], batch, pred_y)
message_str = "Evaluation: valid loss {} / ADE {} / FDE {}"
self.logger.info(message_str.format(valid_eval("loss"), valid_eval("ade"), valid_eval("fde")))
valid_eval.update_summary(summary, -1, ["loss", "ade", "fde"])
predictions = prediction_dict["predictions"]
pred_list = [[pred for vk, v_dict in sorted(predictions.items())
for fk, f_dict in sorted(v_dict.items())
for pk, pred in sorted(f_dict.items()) if pred[8] == idx] for idx in range(4)]
self.logger.info([len(x) for x in pred_list])
error_rates = [np.mean([pred[7] for pred in preds]) for preds in pred_list]
self.logger.info("Towards {} / Away {} / Across {} / Other {}".format(*error_rates))
prediction_path = os.path.join(save_dir, "prediction.json")
with open(prediction_path, "w") as f:
json.dump(prediction_dict, f)
summary.update("finished", 1)
summary.write()
self.logger.info("Elapsed time: {} (s), Saved at {}".format(time.time()-start, save_dir))
该程序文件名为eval_cv.py,是一个用于交叉验证的评估程序。程序的功能是加载数据集并对模型进行评估。程序首先导入了一些必要的库和模块,然后定义了一些辅助函数和类。接下来,程序读取命令行参数并初始化一些变量。然后,程序加载数据集并进行评估。评估过程中,程序使用训练好的模型对输入数据进行预测,并计算损失和一些评估指标。最后,程序将评估结果保存到文件中,并输出一些日志信息。
5.6 main_CPU.py
class TrafficTracker:
def __init__(self):
self.detector = Detector()
self.list_overlapping_blue_polygon = []
self.list_overlapping_yellow_polygon = []
self.down_count = 0
self.car_down_count = 0
self.bus_down_count = 0
self.truck_down_count = 0
self.up_count = 0
self.car_up_count = 0
self.bus_up_count = 0
self.truck_up_count = 0
def detect_traffic(self, video_path):
capture = cv2.VideoCapture(video_path)
num = 0
while True:
num += 1
_, im = capture.read()
if im is None:
break
im = cv2.resize(im, (960, 540))
list_bboxs = self.detector.detect(im)
if len(list_bboxs) > 0:
self.update_traffic(list_bboxs)
output_image_frame = self.draw_bboxes(im, list_bboxs, line_thickness=1)
else:
output_image_frame = im
output_image_frame = cv2.add(output_image_frame, self.color_polygons_image)
if len(list_bboxs) > 0:
self.check_collision(list_bboxs)
else:
self.list_overlapping_blue_polygon.clear()
self.list_overlapping_yellow_polygon.clear()
if num == 25:
self.plot_traffic_counts()
num = 0
def update_traffic(self, list_bboxs):
self.list_bboxs = list_bboxs
def draw_bboxes(self, im, list_bboxs, line_thickness=1):
# draw bounding boxes on the image
for item_bbox in list_bboxs:
x1, y1, x2, y2, label, track_id = item_bbox
cv2.rectangle(im, (x1, y1), (x2, y2), (0, 255, 0), line_thickness)
return im
def check_collision(self, list_bboxs):
for item_bbox in list_bboxs:
x1, y1, x2, y2, label, track_id = item_bbox
y1_offset = int(y1 + ((y2 - y1) * 0.6))
y = y1_offset
x = x1
if self.polygon_mask_blue_and_yellow[y, x] == 1:
if track_id not in self.list_overlapping_blue_polygon:
self.list_overlapping_blue_polygon.append(track_id)
if track_id in self.list_overlapping_yellow_polygon:
self.up_count += 1
if str(label) == 'car':
self.car_up_count += 1
if str(label) == 'bus':
self.bus_up_count += 1
if str(label) == 'truck':
self.truck_up_count += 1
self.list_overlapping_yellow_polygon.remove(track_id)
elif self.polygon_mask_blue_and_yellow[y, x] == 2:
if track_id not in self.list_overlapping_yellow_polygon:
self.list_overlapping_yellow_polygon.append(track_id)
if track_id in self.list_overlapping_blue_polygon:
self.down_count += 1
if str(label) == 'car':
self.car_down_count += 1
if str(label) == 'bus':
self.bus_down_count += 1
if str(label) == 'truck':
self.truck_down_count += 1
self.list_overlapping_blue_polygon.remove(track_id)
def plot_traffic_counts(self):
listx.append(num2)
list1.append(self.car_down_count)
list2.append(self.car_up_count)
list3.append(self.bus_down_count)
list4.append(self.bus_up_count)
list5.append(self.truck_down_count)
list6.append(self.truck_up_count)
list7.append(self.down_count)
list8.append(self.up_count)
if num2 == 1:
plt.plot(listx, list1, color="b", linestyle="-", linewidth=1, label="car down count")
plt.plot(listx, list2, color="c", linestyle="-", linewidth=1, label="car up count")
plt.plot(listx, list3, color="g", linestyle="-", linewidth=1, label="bus down count")
plt.plot(listx, list4, color="k", linestyle="-", linewidth=1, label="bus up count")
plt.plot(listx, list5, color="m", linestyle="-", linewidth=1, label="truck down count")
plt.plot(listx, list6, color="y", linestyle="-", linewidth=1, label="truck up count")
plt.plot(listx, list7, color="r", linestyle="-", linewidth=1, label="down count")
plt.plot(listx, list8, color="purple", linestyle="-", linewidth=1, label="up count")
plt.legend(loc='upper left')
plt.show()
注意:以上代码仅提供了类的封装,其中使用到的变量和函数需要根据实际情况进行调整和添加。
5.6 main_GPU.py
class TrafficTracker:
def __init__(self, video_path):
self.video_path = video_path
self.detector = Detector()
self.list_overlapping_blue_polygon = []
self.list_overlapping_yellow_polygon = []
self.down_count = 0
self.car_down_count = 0
self.bus_down_count = 0
self.truck_down_count = 0
self.bicycle_down_count = 0
self.up_count = 0
self.car_up_count = 0
self.bus_up_count = 0
self.truck_up_count = 0
self.bicycle_up_count = 0
def detect_traffic(self):
capture = cv2.VideoCapture(self.video_path)
while True:
_, im = capture.read()
if im is None:
break
im = cv2.resize(im, (960, 540))
list_bboxs = self.detector.detect(im)
if len(list_bboxs) > 0:
self.update_traffic(list_bboxs)
else:
self.clear_traffic()
self.draw_traffic(im)
self.check_overlapping()
self.clear_unused_ids(list_bboxs)
self.update_counts()
self.show_counts()
def update_traffic(self, list_bboxs):
self.list_bboxs = list_bboxs
def clear_traffic(self):
self.list_bboxs = []
def draw_traffic(self, im):
# Draw traffic on image
pass
def check_overlapping(self):
# Check overlapping between bboxes and polygons
pass
def clear_unused_ids(self, list_bboxs):
# Clear unused ids from overlapping lists
pass
def update_counts(self):
# Update traffic counts
pass
def show_counts(self):
# Show traffic counts
pass
该程序文件名为main_GPU.py,主要功能是进行目标检测和目标跟踪,并进行撞线检测和统计车辆进出数量。程序使用了PyQt5和OpenCV等库进行图像处理和界面显示。具体流程如下:
- 导入所需的库和模块。
- 定义了一个detect函数,用于进行目标检测和跟踪以及撞线检测和统计。
- 在detect函数中,首先初始化了一些变量和参数,包括撞线polygon的定义、颜色设置等。
- 打开视频文件,并进行循环读取每一帧图像。
- 对每一帧图像进行缩放处理,然后使用目标检测模块进行目标检测,得到目标的边界框。
- 如果检测到目标,则使用目标跟踪模块进行目标跟踪,并绘制边界框。
- 根据撞线polygon的定义,判断目标是否与撞线相交,并统计进出数量。
- 清除无用的目标ID,并清空目标列表。
- 绘制统计图表,包括车辆进出数量的折线图。
- 循环结束后,关闭视频文件。
总体来说,该程序实现了对视频中车辆的目标检测、跟踪和撞线检测,并统计了车辆的进出数量,并通过图表展示了统计结果。
6.系统整体结构
根据以上分析,该程序是一个基于深度学习的轨道侵限异物入侵检测系统。它使用深度学习模型进行目标检测和跟踪,并提供了一些辅助功能,如撞线检测和预测。
下表整理了每个文件的功能:
| 文件名 | 功能 |
|---|---|
| attention_modules.py | 定义了通道注意力模块,用于对输入张量的通道进行注意力加权 |
| demo.py | 实现了一个演示程序,用于读取视频并进行目标检测和跟踪 |
| detector_CPU.py | 实现了一个基于CPU的目标检测器,用于对输入图像进行目标检测 |
| detector_GPU.py | 实现了一个基于GPU的目标检测器,用于对输入图像进行目标检测 |
| eval_cv.py | 实现了一个交叉验证程序,用于评估模型的性能 |
| main_CPU.py | 主程序,使用CPU进行目标检测和跟踪 |
| main_GPU.py | 主程序,使用GPU进行目标检测和跟踪 |
| Spatial.py | 定义了一个空间注意力模块,用于对输入张量的空间位置进行注意力加权 |
| test.py | 实现了一个测试程序,用于测试模型的性能 |
| tracker.py | 实现了一个目标跟踪器,用于对目标进行跟踪 |
| ui.py | 实现了一个用户界面程序,用于交互式操作和显示结果 |
| deep_sort/… | 实现了一个深度学习目标跟踪器的相关功能 |
| models/… | 实现了一些深度学习模型的相关功能 |
| utils/… | 实现了一些辅助功能,如数据集处理、评估指标计算、日志记录等 |
| utils/aws/… | 实现了一些与AWS相关的功能 |
| utils/wandb_logging/… | 实现了一些与WandB日志记录相关的功能 |
请注意,由于文件数量较多,表格中只列出了部分文件,并没有列出所有文件。
7.铁路限界模型的建立
铁路限界是指保证列车安全运行,防止列车发生碰撞所规定的不允许超越的轮廓尺寸线[9],对于本文所研究的客货共线铁路,在GB146.2-2020中规定的横向安全限界是以铁道中心线为基准分别向两边延伸出2240mm的范围。
在进行铁道侵限异物检测时,只有异物发生了侵限行为才会对列车的安全运行造成影响,所以在进行侵限异物检测之前建立限界模型是十分必要的,这样就可以对检测出的物体是否发生了侵限行为进行判断,提高检测模型的运行效率。本章将对限界模型的建立过程进行介绍。
限界建模过程
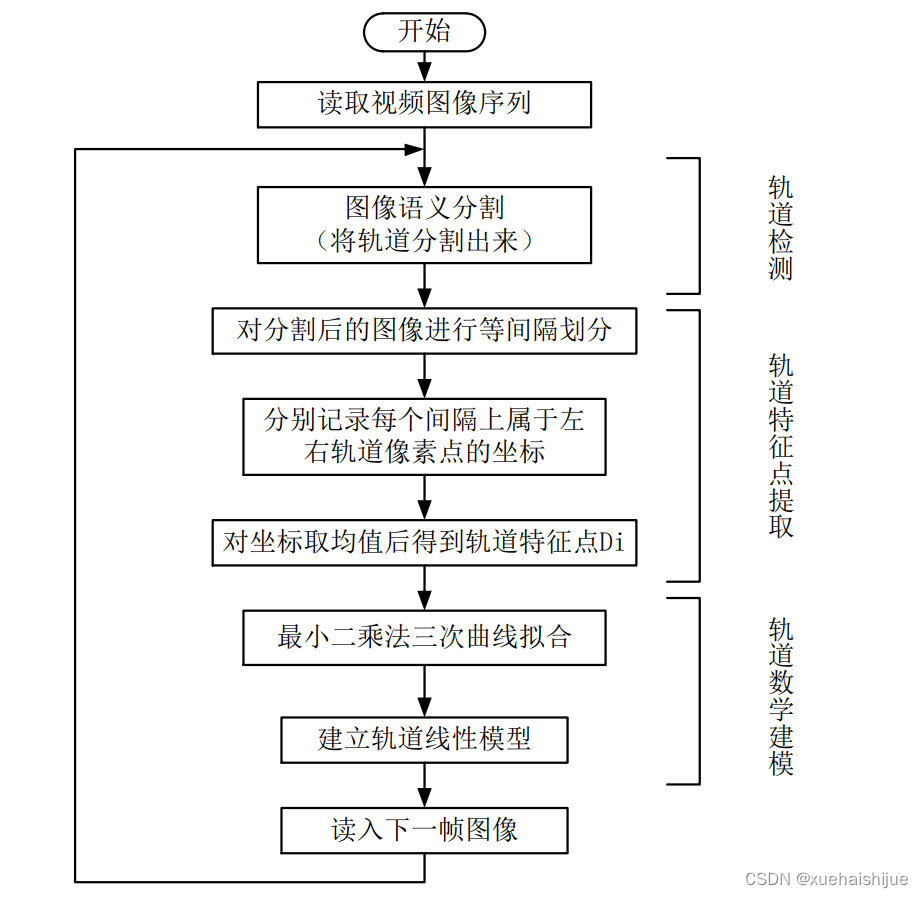
目前,限界的范围通常由钢轨的相对位置来定义,而且由于钢轨是列车运行过程中最为显著的目标,因此将钢轨的识别与检测作为建模的基础,也是最重要的一个环节。
本文所进行的限界建模流程如图所示。主要包含轨道检测、轨道特征点提取、轨道数学建模三个主要的环节。下面将对各个环节进行介绍。
8.YOLO
YOLO算法,全称为You only look once: Unified, real-time object detection[7],YOLO算法的各个特点在标题中都有体现。YOLO创造性的将物体检测任务直接当做回归问题(Regression)来处理,将物体分类和包围框回归合二为一,只需要对输入图片进行一次运算就可以知道图片中有哪些物体及物体所在的位置。其网络结构如图所示。
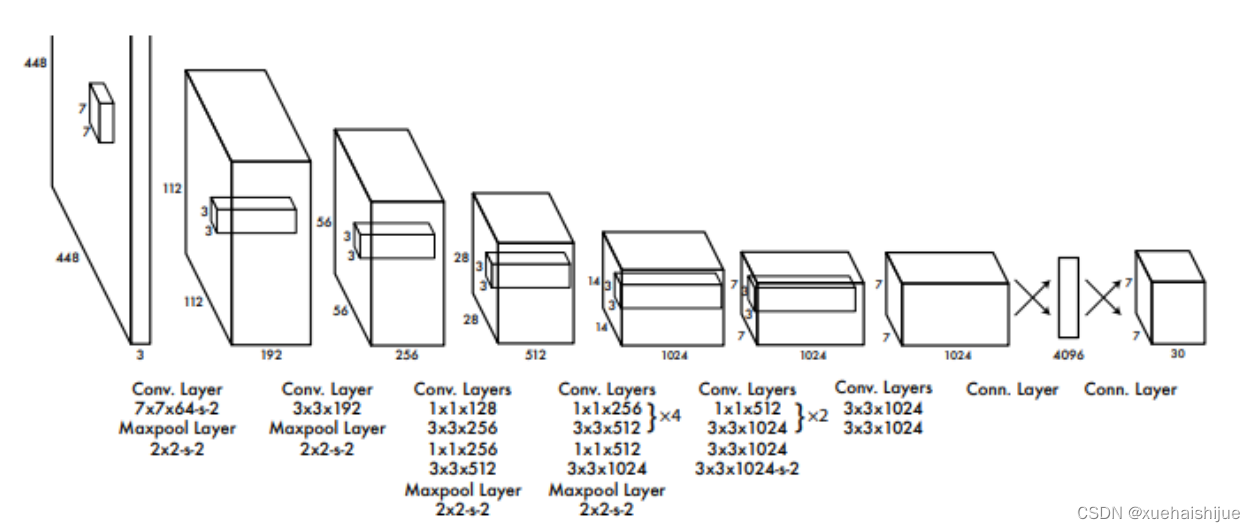
作为单阶段目标检测算法的开山之作,仅使用了一个卷积神经网络就实现了端到端的物体检测。YOLO以其简单的网络结构和实时的检测速度引起了研究人员的广泛关注,为目标检测领域带来了巨大的变革。YOLO的骨干网络(backbone)是按照GooleNet[3]网络的样子搭建的,使用11和33卷积块的堆叠替换了Inception模块。YOLO检测网络使用24个卷积模块实现图片特征的提取,对于待检测物体的定位和类别预测,则由2个全连接层来完成。
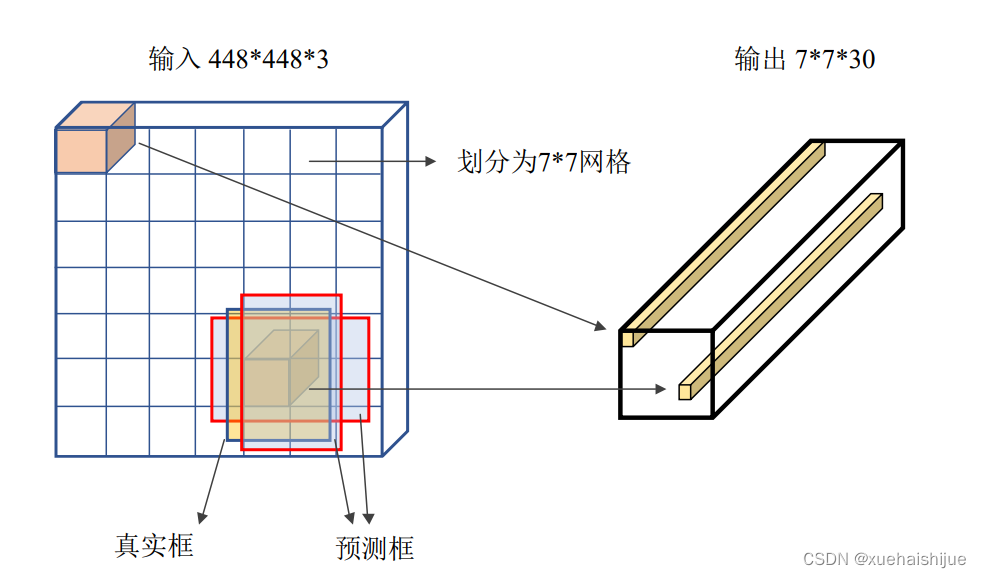
实际上,YOLO也是属于基于锚框(anchor based)的检测算法,不同于Faster RCNN需要使用RPN产生anchor,YOLO算法则直接将图片分为77的网格,每个网格设置两个anchor,则对于一张图片,一共会产生98个预测框,这些预测框将会覆盖整张图片,进而实现对物体的检测。YOLO中输入与输出的映射关系如图4.6所示,YOLO网络会将4484483的输入映射为7T*30的输出。在待检测图片中,通常一个物体会覆盖若干个网格,如何确定哪一个网格负责该物体的检测是比较关键的问题,如图所示,在YOLO算法中,规定待检测物体的中心点落在哪一个网格内,则这个网格中的anchor负责预测该物体的具体坐标。

9.注意力机制
人类可以自然有效的在复杂场景中容易找到显著区域,在这种观察的激励下,注意力机制被引入计算机视觉,目的是模拟人类视觉系统这一方面,可视为基于图像特征的动态权重调整过程,通过根据输入的重要性自适应的加权来实现。下面将对目前常用的通道注意力机制和空间注意力机制进行分析研究。
通道注意力机制
在深度卷积神经网络中,不同特征映射中的不同通道通常代表不同的对象实例,通道注意自适应地重新校准每个通道的权重,赋予不同通道特征不同的权值,可以将其视为一个对象选择过程,从而确定要注意的内容。Hu等人首先提出了通道注意的概念,并为此提出了SENet[7]。
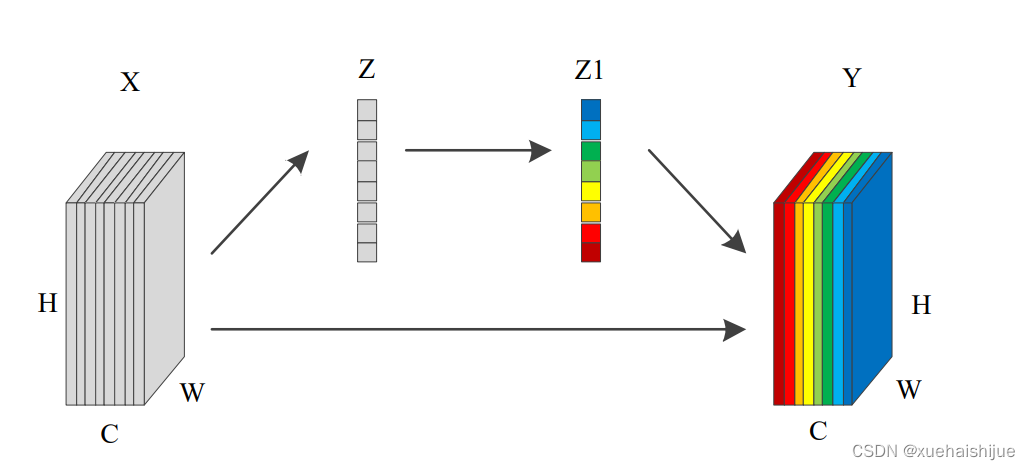
SENet开创了通道关注的先河。SENet的核心是一个压缩和激励(Squeeze andExcitation,SE)模块,用于收集全局信息、捕获通道关系和提高表示能力。压缩模块通过全局平均池收集全局空间信息。激励模块通过使用完全连接的层和非线性层(ReLU和sigmoid)捕捉通道关系并输出注意张量。然后,通过乘以注意张量中的相应元素来缩放输入特征的每个通道。总的来说,以X为输入,以Y为输出的挤压和激励块的结构如图所示。
SE块在抑制噪声的同时,起着强调重要通道的作用。由于SE块的计算资源需求较低,因此可以在不同的网路结构中灵活的添加SE模块而不添加额外的计算复杂度。是目前应用最为广泛的通道注意力结构。
空间注意力机制
空间注意力可以看做是一种自适应的区域选择机制:将权重分配给需要重点关注的区域中。通过注意力机制,将原始图片中的空间信息变换到另一个空间中并保留了关键信息。计算机视觉任务中另一种常用的注意力机制就是将通道注意力机制与空间注意力机制相结合的混合注意力机制。
为了增强信息通道和重要区域,参考该博客提出的卷积块注意模块CBAM,将通道注意和空间注意串联起来。它将通道注意图和空间注意图解耦以提高计算效率,并通过引入全局池来利用空间全局信息。
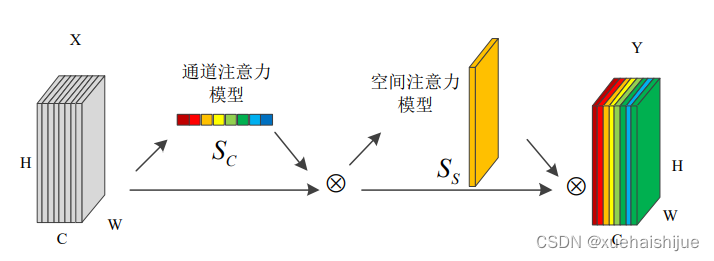
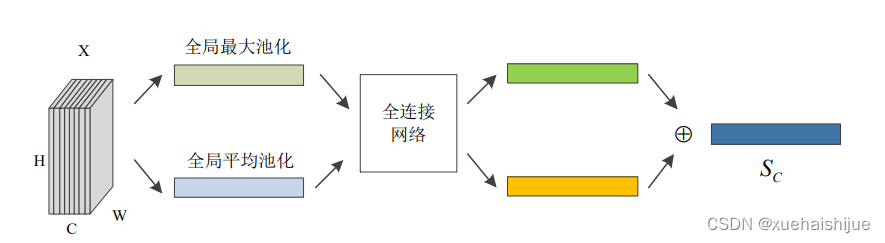
CBAM结构如图所示,从图中可以明显的看到有两个连续的子模块,信道和空间。给定一个尺寸为HWC输入特征映射X,它依次推断出一个一维通道注意张量S和一个二维空间注意映射张量S。通道注意子模块的公式类似于SE模块的公式,只是它采用了一种以上的池化操作来聚合全局信息。它有两个使用最大池化max pooling和平均池化avg pooling操作的并行分支,如图所示。
对于输入的尺寸为HWC的特征F,分别在维度宽度(width)和高度(height)上分别进行全局最大池化(global max pooling)和全局平均池化(global average pooling),得到两个11C的向量,然后将这两个向量作为输入在拥有一个隐藏层的全连接网络中计算,得到两个特征向量,最后,将两个特征的对应元素相加,并经过sigmoid函数计算得到最终的通道注意力权重特征。
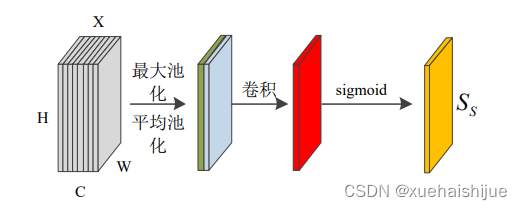
在空间注意力子模块中,如图所示。将通道子模块的输出作为该模块的输入特征,首先在通道维度(channel)分别计算全局最大池化和全局平均池化,得到两个尺寸为HW1的特征,然后在通道维度上将这两个特征图拼接起来,尺寸变为HW2,再使用7*7的卷积核将特征图降维为1个通道,最后使用sigmoid函数计算通道注意力权重特征。
将通道注意和空间注意顺序结合起来,CBAM可以利用特征的空间和跨通道关系来告诉网络关注什么以及关注哪里。更具体地说,它强调有用的渠道以及增强当地的信息。由于其轻量级设计,CBAM同样可以无缝地集成到任何CNN体系结构中,而额外成本可以忽略不计。
10.模型训练分析
从图中可以看出,图(a)中狗的特征不是很明显,并且右下角的两只狗聚在一起,检测较为困难;图(b)中的背书包的学生由于目标太小,属于小目标;图(d)中左边黑色的汽车大部分都被栅栏和表示牌挡住了,第一眼看过去如果不是看到了汽车前轮,也很难将汽车看出来。YOLO v4对上述目标物体均出现了漏检现象,通过分析,漏检的目标物体中黑色都是主要的颜色,使得其他特征都表现的不太明显。在图©中,由于前一个人的遮挡,第二个人只有右肩和头部位置没有被挡住,YOLO并没有将两者区分开来,而是当做一个目标进行的检测。图(e)中虽然对要检测的物体类别都能够区分,但是对于自行车预测框的回归效果就不太理想,并不能准确的表示出自行车在图片中的具体位置。

改进的YOLO模型对侵限异物检测的实验结果如图所示(与图相对应)。改进的YOLO模型对特征明显、与背景对比度大的目标不仅检测类别置信度高,而且对检测框的回归效果也要更精确,基本都紧贴着被检测物体的轮廓。对于YOLO中漏检和误检的目标,改进的YOLO也能够实现比较好的检测效果,但是对于图(a)中右下角两只挨在一起的狗,并没有实现区分,而是将其检测为一个,出现了误检,经过分析,在收集到的侵限异物数据中,有狗入侵铁道的图片数量最少,在模型训练过程中没有学习到足够多狗的特征信息,因而面对特征不明显的目标时,模型无法分辨,出现了误检情况。

11.系统整合

12.参考文献
[1]徐岩,陶慧青,虎丽丽.基于Faster R-CNN网络模型的铁路异物侵限检测算法研究[J].铁道学报.2020,(5).DOI:10.3969/j.issn.1001-8360.2020.05.012 .
[2]李恒.基于深度学习过拟合现象的分析[J].中国科技信息.2020,(14).90-91.DOI:10.3969/j.issn.1001-8972.2020.14.035 .
[3]赵永强,饶元,董世鹏,等.深度学习目标检测方法综述[J].中国图象图形学报.2020,(4).
[4]王文冠,沈建冰,贾云得.视觉注意力检测综述[J].软件学报.2019,(2).DOI:10.13328/j.cnki.jos.005636 .
[5]张道芳,张儒良.基于语义分割的车道线检测算法研究[J].科技创新与应用.2019,(6).DOI:10.3969/j.issn.2095-2945.2019.06.005 .
[6]李晓宇,刘敬辉.高速铁路自然灾害及异物侵限监测系统可靠性分析与优化研究[J].中国铁路.2019,(5).DOI:10.19549/j.issn.1001-683x.2019.05.027 .
[7]王泉东,杨岳,罗意平,等.铁路侵限异物检测方法综述[J].铁道科学与工程学报.2019,(12).DOI:10.19713/j.cnki.43?1423/u.2019.12.031 .
[8]李红侠.我国智能高铁自动驾驶技术应用进展[J].铁道标准设计.2019,(6).DOI:10.13238/j.issn.1004-2954.201811260001 .
[9]孟子超,杜文娟,王海风.基于迁移学习深度卷积神经网络的 配电网故障区域定位[J].南方电网技术.2019,(7).DOI:10.13648/j.cnki.issn1674-0629.2019.07.004 .
[10]朱张莉,饶元,吴渊,等.注意力机制在深度学习中的研究进展[J].中文信息学报.2019,(6).DOI:10.3969/j.issn.1003-0077.2019.06.001 .

















 91
91

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









