







java Lambda表达式
Lambda表达式 以下简写为 L表达式
1. 什么是 @FunctionalInterface 函数式接口
1.1 只含有且只有 单个抽象方法 的 接口
1.2 必须是接口 不能是抽象类
1.3 接口中可以有default (默认) 方法,私有方法和其他的静态方法
1.4 主要用途 用作 Lambda 表达式的类型
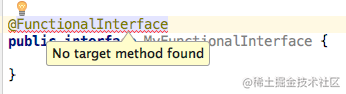
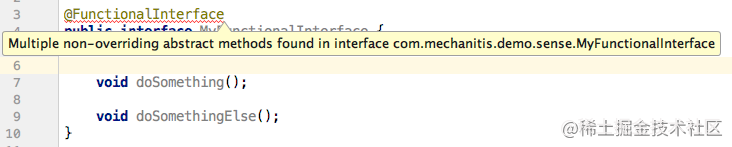
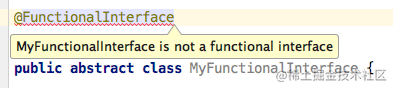
2. Lambda表达式为什么和接口中的方法名称没有关系
2.1 首先来说 L表达式 作为函数参数 一定是有类型的,那他是什么类型呢??
String G7Countries = G7.stream().map(x -> x.toUpperCase()).collect(Collectors.joining(", "));
x -> x.toUpperCase() 这个表达式是什么类型的呢?
2.2 常见通用单参数函数
第一种 有入有出 类似一种 函数隐射(或转化工厂) 把输入T 转化为输出V

对应于
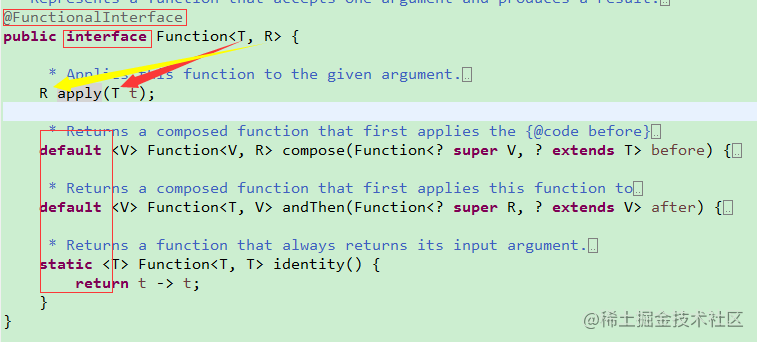
也就是说在你写出 L表达式 t-> {…; return r;} 这儿L 表达式的类型就是 Function
在你想把输入a转化为输入b时 就用的是Function 类型的L表达式
第二种类型 只进不出 也叫消费型,就是把你传入的T 给消费掉了

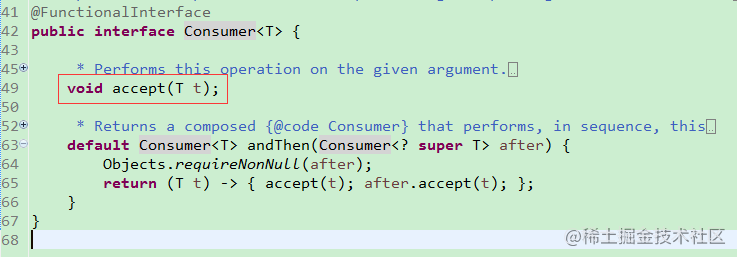
L表达式 t->{ 没有返回值} ,注意返回类型是void 也就是没有返回值
第三种类型 只出不进 也叫生产者型

L 表达式 ()->{…; return t;} ,注意输入参数为void
第四种类型 这是一种Function 变体


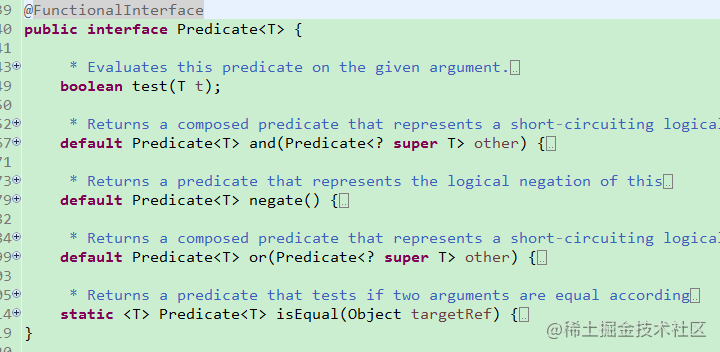
就是输入一个表达式 返回bolean 类型的
(t)->{…; return true or false };
Predicate atLeast5 = x - > x > 5;
Predicate 类型是一种特殊的 Function: Function<T, Boolean>
Predicate类型一般用于 filter 过滤数据
第五种类型:没进没出型


2.3 常用双参数函数式接口
BinaryOperator extends BiFunction<T,T,T>

BinaryOperator 一般用于 L表达式型如: (Integer a,Float b)->{ return a+b; }
BinaryOperator<Long> addLongs = (x, y) - > x + y;
由于L 是实现的 函数式接口,而函数式接口中只有单个抽象方法,所有没有方法名称
也能从上下文推断出来。另外函数的调用只和传入和传出的参数有关。
filter():对元素进行过滤; Predicate
sorted():对元素排序; function
map():元素的映射;function
distinct():去除重复元素;
3. lambada 表达式和 实现接口的关系
比如 线程的Runnable 接口

一般的代码:
Runnable task=new Runnable() {
@Override
public void run() {
System.out.println("努力工作中...");
}
};
或
Runnable task=()->{ System.out.println("努力工作中..."); }
Thead t=new Thead(task);
t.start();
也就是说
()->{ System.out.println("努力工作中..."); } 是 Runnable 类型的实例
4. lambda 表达式的一般写法



5. 集合类的流式编程 【数据处理的工序】
先看一下整体
https://www.ibm.com/developerworks/cn/java/j-java-streams-3-brian-goetz/index.html

5.1 理解Map方法
以下代码把Integer List 隐射为String List
List<Integer> numbers = Arrays.asList(9, 10, 3, 4, 7, 3, 4,3);
List<String> distinct = numbers.stream().map( i -> i+"" ).distinct().collect(Collectors.toList());
map 中的 i->i+"" 表达式就是 Function 类型的
再看一个例子
List<String> G7 = Arrays.asList("USA", "Japan", "France", "Germany", "Italy", "U.K.","Canada");
String G7Countries = G7.stream().map(x -> x.toUpperCase()).collect(Collectors.joining(", "));
** 理解flatMap**
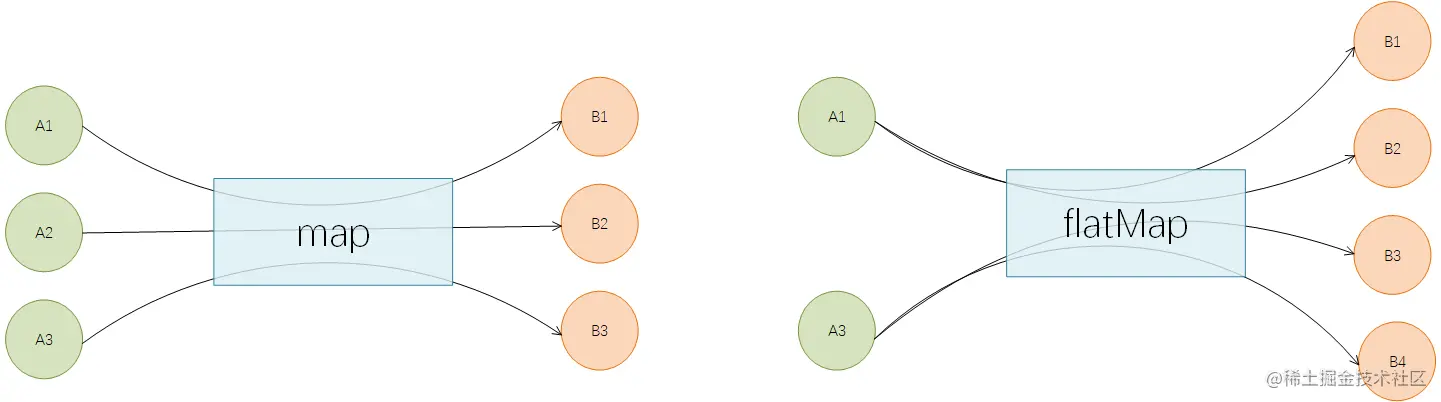
map与flatMap都是用于转换已有的元素为其它元素,区别点在于:
map 必须是一对一的,即每个元素都只能转换为1个新的元素
flatMap 可以是一对多的,即每个元素都可以转换为1个或者多个新的元素
比如:有一个字符串ID列表,现在需要将其转为User对象列表。可以使用map来实现:
/**
* 演示map的用途:一对一转换
*/
public void stringToIntMap() {
List<String> ids = Arrays.asList("205", "105", "308", "469", "627", "193", "111");
// 使用流操作
List<User> results = ids.stream()
.map(id -> {
User user = new User();
user.setId(id);
return user;
})
.collect(Collectors.toList());
System.out.println(results);
}
执行之后,会发现每一个元素都被转换为对应新的元素,但是前后总元素个数是一致的:
[User{id='205'},
User{id='105'},
User{id='308'},
User{id='469'},
User{id='627'},
User{id='193'},
User{id='111'}]
再比如:现有一个句子列表,需要将句子中每个单词都提取出来得到一个所有单词列表。这种情况用map就搞不定了,需要flatMap上场了:
public void stringToIntFlatmap() {
List<String> sentences = Arrays.asList("hello world","Jia Gou Wu Dao");
// 使用流操作
List<String> results = sentences.stream()
.flatMap(sentence -> Arrays.stream(sentence.split(" ")))
.collect(Collectors.toList());
System.out.println(results);
}
执行结果如下,可以看到结果列表中元素个数是比原始列表元素个数要多的:
[hello, world, Jia, Gou, Wu, Dao]
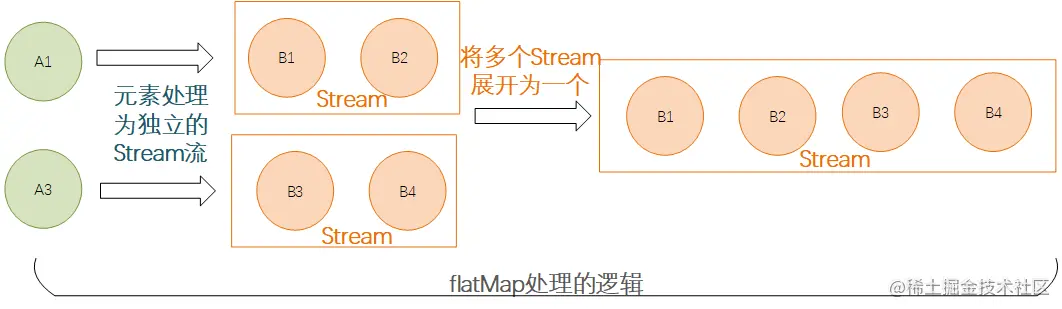
这里需要补充一句,flatMap操作的时候其实是先每个元素处理并返回一个新的Stream,然后将多个Stream展开合并为了一个完整的新的Stream,如下:
5.2 理解 filter
List<String> filtered = strList.stream().filter(x -> x.length()> 2).collect(Collectors.toList());
x -> x.length()> 2 是Predicate 的类型
其他的可以参考这里 http://www.importnew.com/16436.html
5.3 理解 分组 groupby 和收集器 collectors
例1:把课程信息组装成map
List<BwXyCourseinfo> courseList = courseinfoService.queryAll(pMap);
Map<String, BwXyCourseinfo> courseMap = courseList.stream().collect(
Collectors.toMap(
(BwXyCourseinfo o) -> o.getId(),
(BwXyCourseinfo o) -> o,
(k1, k2) -> {
throw new RuntimeException(String.format("Duplicate key for values %s and %s", k1,k2));
}, LinkedHashMap::new));
例2:
// 提取班号并去重复
Set<String> bjmcSet = list.stream().map(o -> o.getClassid()).collect(Collectors.toSet());
List<String> bjmcs = new ArrayList<String>(bjmcSet);
Map<String, Object> params = new HashMap<String, Object>();
params.put("bjmcs", bjmcs);
final Map<String, BwXyBjbm> bjMap = bjbmService.getBwXyBjbmMap(params);
// 填充学院id
list.stream().filter(o -> null != o.getClassid()).forEach(o -> {
BwXyBjbm bj = bjMap.get(o.getClassid());
if (null != bj) {
o.setCollegeid(bj.getSsxy());
}
});

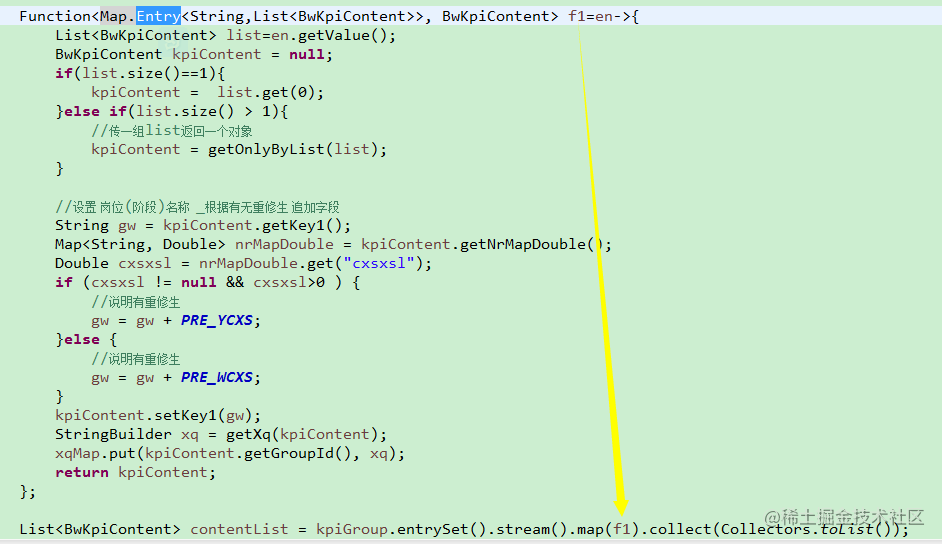
例3: 字符串拼接
List names=new ArrayList<String>();
names.add("1");
names.add("2");
names.add("3");
System.out.println(String.join("-", names));
输出:
1-2-3
带前后缀
StringJoiner sj = new StringJoiner(",", "[", "]");
sj.add("a").add("b").add("c");
System.out.println("The final Joined string is " + sjr);
输出: "[a,b,c]
// 中间以or 连接,开始 and ( 结尾 )
category = new StringJoiner(" or ", " and ( ", " ) ");
例4:分组 ,这个比较费脑
List<ExamQuestionMain> mList = mainDao.queryAll(pMap);
// 按科目分组,英语,语文,数学,专业知识
Map<String, List<ExamQuestionMain>> subjectQuetionMap = mList.stream()
.collect(
Collectors.groupingBy(
(ExamQuestionMain o) -> o.getSubject(),
Collectors.toList()));
下边这个例子更费脑
// 按问题id 分组 获取属性的 id列表
List<ExamQuestionAttribute> categoryList =null;
Map<String, List<String>> categoryMap = categoryList.stream().collect
(
Collectors.groupingBy(
ExamQuestionAttribute::getQuestionId,
Collectors.mapping(ExamQuestionAttribute::getAttributeId, Collectors.toList())
)
);
// 一个 Question问题有多个Attribute
//在groupingBy 操作时 返回的类型为 Map<String, List<ExamQuestionAttribute>>
即 {
key = QuestionId这个试题的id
value= 这个试题对应的所有Attribute对象
}
//但是 我想要 {key =QuestionId这个试题的id , value=这个试题对应的所有 Attribute对象的id}
即返回结果 不是 Map<String, List<ExamQuestionAttribute>> 而是Map<String, List<String>>
所以还需要再次map一下也就是把 ExamQuestionAttribute 对象转化为一个String对象
Collectors.mapping(ExamQuestionAttribute::getAttributeId, Collectors.toList()
分组计数

多级分组
// 2级分组,先按子公司SubCompany 分组后再按Department 分组统计部门人数
public void groupByCompanyAndDepartment() {
// 按照子公司+部门双层维度,统计各个部门内的人员数
Map<String, Map<String, Long>> resultMap = getAllEmployees().stream()
.collect(Collectors.groupingBy(Employee::getSubCompany,
Collectors.groupingBy(Employee::getDepartment,
Collectors.counting())));
System.out.println(resultMap);
}
运行结果
{
南京公司={
测试二部=1,
测试一部=1},
上海公司={
研发二部=1,
研发一部=2}
}
6. 其他
Java 16 对此进行了改进,因为现在还可以在方法体中定义本地record ,
本地record 还可以在Collectors.groupingBy 多字段分组时使用
public List<Product> findProductsWithMostSaving(List<Product> products) {
//方法内部的 record ,所谓的本地record
record ProductWithSaving(Product product, double savingInEur) {}
products.stream()
.map(p -> new ProductWithSaving(p, p.basePriceInEur * p.discountPercentage))
.sorted((p1, p2) -> Double.compare(p2.savingInEur, p1.savingInEur))
.map(ProductWithSaving::product)
.limit(5)
.collect(Collectors.toList());
}
更多例子请参考 :















 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









