







这篇博客用来记录自己阅读 ImportNew 公众帐号文章的笔记.
2015-8-26:《关于 hashCode() 你需要了解的3件事》
- 在一个运行的进程中, 相等的对象必须要有相同的哈希码, 如果你要重写
equals()方法, 一定要同时实现hashCode()方法. - 但这并 不意味 有相同哈希码的对象一定相等 或者 不相等的对象的哈希码一定不相等.
- 两个不同对象拥有相同哈希码称之为冲突. 冲突意味着有多个对象在同一个哈希空间里,
HashMap会再次检查以便来找到正确的对象. 会降低系统性能, 但是不会导致错误结果. - 不可使用哈希码作为 key 值.
- 哈希码是可变的.
- 在分布式应用中不要使用哈希码.
2015-8-27:《危险! 在 HashMap 中将可变对象用作 Key》
- 可变对象是指当对象的状态(属性值等)发生变化之后, 它的哈希值会发生变化的对象.
HashMap用 Key 的哈希值来存储和查找键值对.- 使用可变对象作为
HashMap的 Key 值会造成数据丢失(以及内存无法回收). - 对象不可变的类包括基本数据类型, String 等.
- 自定义不可变数据类型: 重写
hashCode()方法, 用一个不可变的属性作为哈希值计算的唯一参数.
2015-8-28: 《Java 程序优化:字符串操作、基本运算方法等优化策略》– 字符串优化
String 有三个基本特点:
- 不变性:
String对象生成之后就不能再对其进行更改. 属于 “不变(immutable)模式”. 当一个对象需要多线程访问, 并且访问频繁时, 可以省略同步和锁等待的时间, 从而大幅提高系统性能. - 针对常量池优化: 当两个
String对象拥有相同的值时, 它们只引用常量池里的同一个拷贝, 当一个字符串反复出现时, 可以大幅节省内存.
String str1 = "abc"String str2 = "abc"String str3 = new String("abc"); 其中str1,str2都引用了相同的地址, 它们是等同的.str3却重新开辟了一块内存空间. 但即使如此str3所指向的实体(str3.intern())完全一样. - 类的 final 定义: 这个类的定义是被
final修饰的, 它不能被继承.
SubString 技巧
String 类的 subString() 方法内部, 最后执行会新建一个 String 对象, new String(offset + beginIndex, endIndex - beginIndex, value); . 这样做可以 重复使用母串的数组 , 但是如果我们只是想得到母串中的很小一段, 母串又很长, 那结果就是, 我们只想要很小一段字符串, 但是不得不持有整个母串的数组. 这样会 使大量的内存被占用而不能回收 . 建议做法 new String(str.subString(begin, end));, 这样, 母串就可以在之后的内存回收时被回收掉了.
切割字符串
实现方法:
1. String.split() 方法.
2. StringTokenizer 工具类.
3. 自己实现, 通过组合使用 subString() 和 indexOf() 方法.
示例代码中母串很长, split() 方法耗时很大, 而 StringTokenizer 耗时很短. 实例运行结果差异较大的原因是 split 算法对每一个字符进行了对比,这样当字符串较大时,需要把整个字符串读入内存,逐一查找,找到符合条件的字符,这样做较为耗时。而 StringTokenizer 类允许一个应用程序进入一个令牌(tokens),StringTokenizer 类的对象在内部已经标识化的字符串中维持了当前位置。一些操作使得在现有位置上的字符串提前得到处理。 一个令牌的值是由获得其曾经创建 StringTokenizer 类对象的字串所返回的。
字符串合并
String 是不可变对象, 在需要修改字符串的时候都会创建新的字符串, 因此性能较差. 但是 JVM 会对代码优化, 将多个连接操作在编译时合成一个单独的长串.
字符串合并的实现方法: (效率是递增的)
1. 使用加号连接(+).
2. 使用 String.concat() 方法.
3. 使用 StringBuilder / StringBuffer.
StringBuffer 和 StringBuilder 的区别在于 StringBuffer 几乎对所有方法都做了同步, 同步会消耗系统资源, 所以 StringBuilder 效率相对较高; 但是在需要线程同步时, 要么自己做同步, 要么乖乖使用 StringBuffer.
补2015-8-29: 《Java 程序优化:字符串操作、基本运算方法等优化策略》– 数据定义/运算逻辑优化
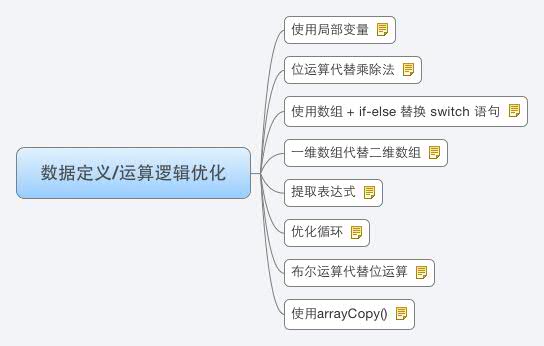
使用局部变量
调用方法时, 方法参数 以及 局部变量 保存在栈(Stack)中, 读写速度较快. 其他变量, 如静态变量, 实例变量等在堆(Heap)中, 读写较慢.
位运算代替乘除法
位运算是所有运算中最高效的.
使用数组 + if-else 替换 switch 语句
在下面的两个方法中, 后者运行时间是前者的一半.
public int switchTest(int value) {
int i = value % 10 + 1;
switch(i) {
case 1: return 10;
case 2: return 11;
case 3: return 12;
case 4: return 13:
case 5: return 14;
case 6: return 15;
case 7: return 16;
case 8: return 17;
case 9: return 18;
default: return -1;
}
}
public int arrayTest(int key) {
int[] values = new int[] {0, 10, 11, 12, 13, 14, 15, 16, 17, 18};
int i = key % 10 + 1;
if(i > 9 || i < 1) {
return -1;
} else {
return value[i];
}
}一维数组代替二维数组
一维数组的访问速度优于二维数组.
提取表达式
将重复的表达式提取出来:
// 将
double b1 = a1*a2*a3/3*4*a3*a4;
double b2 = a1*a2*a4/3*4*a3*a4;
// 改为:
double combine = a1*a2/3*4*a3*a4;
double b1 = combine*a3;
double b2 = combine*a4;优化循环
- 减少循环次数
- 将重复的操作提取到循环外面
布尔运算代替位运算
在判断语句中, 使用布尔运算而不是位运算, 因为 Java 会对布尔运算做相当充分的优化
// 只要 a 是 true, 就不会判断 b 和 c
if(a || b || c){}
// 不论 abc 的值是什么, 都会执行两次位运算
if(a | b | c){}使用arrayCopy()
System.arrayCopy() 是 JDK 提供的高效数据复制方法, 它是一个 native 方法, ArrayList 和 Vector 中大量使用这个方法来进行数据操作.
2015-9-23: 《细话 Java: “失效”的 private 修饰符》
private 修饰的成员是不可以被外部访问的, 但是, 当你定义一个内部类的时候, 会发现在外部类中可以访问到内部类的 private 成员, 而在内部类也同样可以访问到外部类的 private 成员, private 修饰符失效了吗?
并没有, 实际上在调用时是通过间接的方法来获取私有属性的。
同时, Java 内部类在构造时会持有外部类的引用, 这与C++不同
待续…















 148
148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









