







之前的文章集合:
一些可以参考文章集合1_xuejianxinokok的博客-CSDN博客
一些可以参考文章集合2_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合3_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合4_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合5_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合6_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合7_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合8_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合9_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合10_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合11_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合12_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合13_xuejianxinokok的博客-CSDN博客
20231110
命名篇
-
字母使用小写。有些系统对大小写不敏感。
-
名词使用单数。英文的复数规则比较复杂,尤其对于英语非母语程序员来说,用复数容易造成代码命名不一致。如果是表示数组的话,可以加上 List 后缀。
-
动词使用一般时态。同样英文的动词被动时态规则也有好多种,使用被动时态容易造成命名不一致。
-
使用 Reversed domain name notation (reverse-DNS) 来命名。比如在 Bytebase 里定义 issue 创建这个活动,我们可以用 bb.issue.create。而成员的创建可以用 bb.member.create。名字定义本身包含了结构,具备更好的可读性,同时搜索的时候也可以使用 bb.member 这样的前缀搜索。
技术选型篇
-
使用 Restful 而不是 GraphQL。
-
-
RESTful 是更成熟的技术,有成熟的生态。
-
RESTful 帮助团队更早关注领域建模,因为需要识别出对象以及对象上的行为。
-
RESTful 帮助架构做更好的分层。RESTful 定义了更加克制的接口,界定了前后端的边界。而 GraphQL 很容易穿透界定的边界和抽象。
-
-
使用关系型数据库而不是 NoSQL。
-
想走得快用 MySQL,要走得远用 PostgreSQL。
-
除非业务本身需要对接多种数据库,否则谨慎考虑使用 ORM。ORM 通常只支持所有数据库功能的最大公约数,一些特色功能要么不支持,要么要用晦涩的语法。而且你无法精确控制生成的 SQL,影响代码可读性。
-
新的后端项目优先考虑使用 Go。
50 万行代码喂出来的一些编程经验天下无码 https://mp.weixin.qq.com/s/SMxcxWZt4atct0bUHPMO0g
https://mp.weixin.qq.com/s/SMxcxWZt4atct0bUHPMO0g
20231109
不是吧?async/await异常捕获你还在用try-catch~给你说两种相对简单的解决方法~https://mp.weixin.qq.com/s/5wd4JhZyLXL9uC4lYBgnoA
20231107
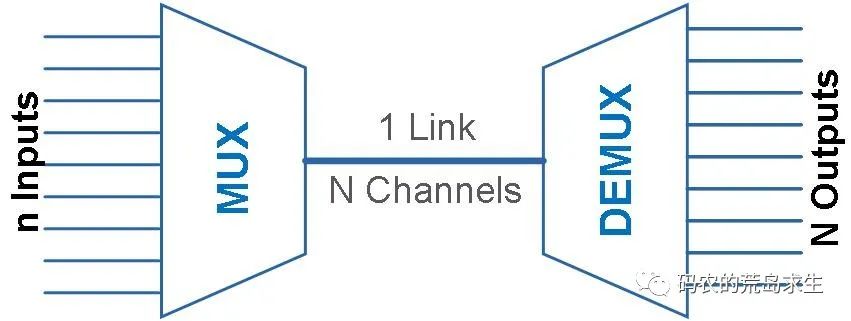
multiplexing一词其实多用于通信领域,为了充分利用通信线路,希望在一个信道中传输多路信号,要想在一个信道中传输多路信号就需要把这多路信号结合为一路,将多路信号组合成一个信号的设备被称为multiplexer,显然接收方接收到这一路组合后的信号后要恢复原先的多路信号,这个设备被称为demultiplexer,如图所示:
在select这种I/O多路复用机制下,我们需要把想监控的文件描述集合通过函数参数的形式告诉select,然后select会将这些文件描述符集合拷贝到内核中,我们知道数据拷贝是有性能损耗的,因此为了减少这种数据拷贝带来的性能损耗,Linux内核对集合的大小做了限制,并规定用户监控的文件描述集合不能超过1024个,同时当select返回后我们仅仅能知道有些文件描述符可以读写了,但是我们不知道是哪一个,因此程序员必须再遍历一边找到具体是哪个文件描述符可以读写了。
因此,总结下来select有这样几个特点:
-
我能照看的文件描述符数量有限,不能超过1024个
-
用户给我的文件描述符需要拷贝的内核中
-
我只能告诉你有文件描述符满足要求了,但是我不知道是哪个,你自己一个一个去找吧(遍历)
poll和select是非常相似的,poll相对于select的优化仅仅在于解决了文件描述符不能超过1024个的限制,select和poll都会随着监控的文件描述数量增加而性能下降,因此不适合高并发场景。
在select面临的三个问题中,文件描述数量限制已经在poll中解决了,剩下的两个问题呢?
针对拷贝问题,epoll使用的策略是各个击破与共享内存。
实际上文件描述符集合的变化频率比较低,select和poll频繁的拷贝整个集合,内核都快被烦死了,epoll通过引入epoll_ctl很体贴的做到了只操作那些有变化的文件描述符,同时epoll和内核还成为了好朋友,共享了同一块内存,这块内存中保存的就是那些已经可读或者可写的的文件描述符集合,这样就减少了内核和程序的拷贝开销。
针对需要遍历文件描述符才能知道哪个可读可写这一问题,epoll使用的策略是“当小弟”。
在select和poll机制下,进程要亲自下场去各个文件描述符上等待,任何一个文件描述可读或者可写就唤醒进程,但是进程被唤醒后也是一脸懵逼并不知道到底是哪个文件描述符可读或可写,还要再从头到尾检查一遍。
但epoll就懂事多了,主动找到进程要当小弟替大哥出头。
在这种机制下,进程不需要亲自下场了,进程只要等待在epoll上,epoll代替进程去各个文件描述符上等待,当哪个文件描述符可读或者可写的时候就告诉epoll,epoll用小本本认真记录下来然后唤醒大哥:“进程大哥,快醒醒,你要处理的文件描述符我都记下来了”,这样进程被唤醒后就无需自己从头到尾检查一遍,因为epoll小弟都已经记下来了。
因此我们可以看到,在epoll这种机制下,实际上利用的就是“不要打电话给我,有需要我会打给你”这种策略,进程不需要一遍一遍麻烦的问各个文件描述符,而是翻身做主人了,“你们这些文件描述符有哪个可读或者可写了主动报上来”,这种机制实际上就是大名鼎鼎的事件驱动,Event-driven,这也是我们下一篇的主题。
实际上在Linux平台,epoll基本上就是高并发的代名词。
彻底理解IO多路复用https://mp.weixin.qq.com/s/sLQcgEvW-zh3xqtJRJeniw
20231103
git原理
20231026

20231024
Spring把JDBC 的 Connection或者Hibernate的Session等访问数据库的链接(会话)都统一称为资源,显然我们知道Connection这种是线程不安全的,同一时刻是不能被多个线程共享的。
简单的说,同一时刻我们每个线程持有的Connection应该是独立的,且都是互不干扰和互不相同的
DataSourceUtils
有些场景比如我们使用MyBatis的时候,某些场景下,可能无法使用 Spring 提供的模板类来达到效果,而是需要直接操作原生API Connection。
https://www.cnblogs.com/xfeiyun/p/15114125.htmlhttps://www.cnblogs.com/xfeiyun/p/15114125.html
其实Spring不仅为JDBC提供了这个工具类,还为Hibernate、JPA、JDO等都提供了类似的工具类。
org.springframework.orm.hibernate.SessionFactoryUtils.getSession()
org.springframework.orm.jpa.EntityManagerFactoryUtils.getTransactionalEntityManager()
org.springframework.orm.jdo.PersistenceManagerFactoryUtils.getPersistenceManager()
还有 org.mybatis.spring.SqlSessionUtils
TransactionSynchronization
这个类非常的重要,它是我们程序员对事务同步的扩展点:用于事务同步回调的接口,AbstractPlatformTransactionManager支持它。
注意:自定义的同步器可以通过实现Ordered接口来自己定制化顺序,若没实现接口就按照添加的顺序执行。
https://www.cnblogs.com/xfeiyun/p/15114072.htmlhttps://www.cnblogs.com/xfeiyun/p/15114072.html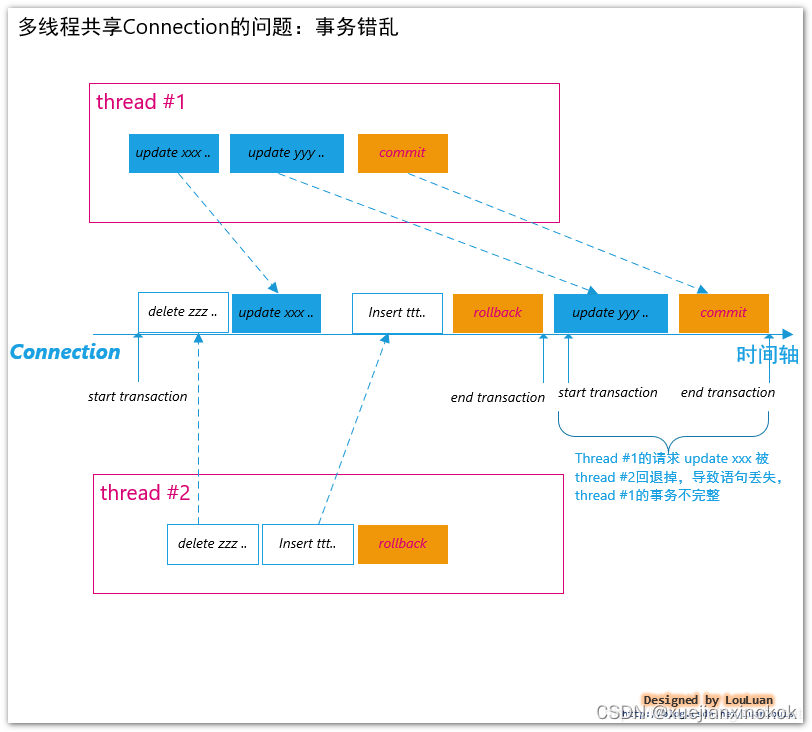
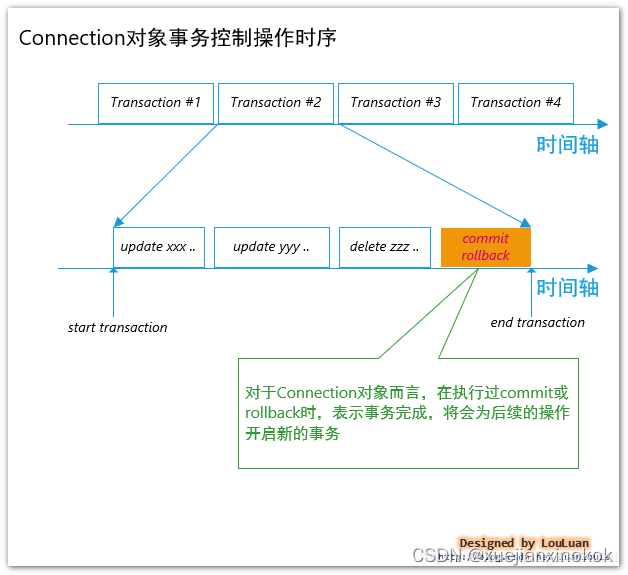
上图所示,对于java.sql.Connection对象的操作,一般会遵循序列化的事务操作模式,即:一个新事务的开启,必须在上一个事务完成之后(如果存在的话);换成另外一种表述方式就是:对connection的操作必须是线性的。
嵌套事务和事务挂起
嵌套事务
什么是嵌套事务呢?
嵌套是子事务套在父事务中执行,子事务是父事务的一部分,在进入子事务之前,父事务建立一个回滚点,叫save point,然后执行子事务,这个子事务的执行也算是父事务的一部分,然后子事务执行结束,父事务继续执行。重点就在于那个save point。看几个问题就明了了:
1、如果子事务回滚,会发生什么?
父事务会回滚到进入子事务前建立的save point,然后尝试其他的事务或者其他的业务逻辑,父事务之前的操作不会受到影响,更不会自动回滚。
2、如果父事务回滚,会发生什么?
父事务回滚,子事务也会跟着回滚!为什么呢,因为父事务结束之前,子事务是不会提交的,我们说子事务是父事务的一部分,正是这个道理。那么:
3、事务的提交,是什么情况?
是父事务先提交,然后子事务提交,还是子事务先提交,父事务再提交?答案是第二种情况,还是那句话,子事务是父事务的一部分,由父事务统一提交。
https://www.cnblogs.com/xfeiyun/p/15114133.htmlhttps://www.cnblogs.com/xfeiyun/p/15114133.html
第一步:模型导入和管理:Elasticsearch 8.x 支持导入预训练的深度学习模型,并提供相应的模型管理工具,方便模型的部署和更新。
第二步:向量表示与转换:通过深度学习模型,可以将非结构化数据如图像和声音转换为向量表示,从而进行有效的检索。
第三步:自定义相似度计算:8.x 版本提供了基于深度学习模型的自定义相似度计算接口,允许用户根据实际需求开发和部署专门的相似度计算方法。20231011
可能有朋友要问,为什么MySQL的默认事务隔离级别不是RC而是RR呢?这和MySQL数据库的历史有关,MySQL数据库因为早期的BINLOG复制不支持RAW格式的问题而必须选择RR,如果使用RC无法确保复制数据的一致性。但是用了RR这种事务隔离级别,又会引起数据库的并发性能受到影响,因此MySQL引入了GAP LOCK这种特殊的锁机制,来降低RR对数据库并发的性能影响。哪怕是引入了GAP LOCK,在RR隔离级别下,对于SELECT … FOR UPDATE的操作,RR隔离级别也会比RC有更多的锁阻塞,因此我们建议MySQL用户如果BINLOG复制使用能够RAW的情况下,还是把默认的事务隔离级别设置为RC。
20231009
20230927
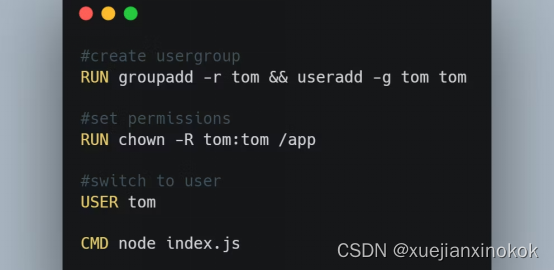
7.使用最小权限用户原则
默认情况下,Docker使用root用户作为管理员以便获得运行命令的权限,但这种做法不好。如果其中一个容器存在漏洞,黑客就可以访问Docker主机。
为了避免这种情况,应创建专用的用户和用户组。您可以为用户组设置相应的权限,以保护敏感信息。如果用户受到危及,您可以在不暴露整个项目的情况下删除该用户。
下面这个例子展示了如何创建用户并设置权限:
一些基本镜像在其中创建了伪用户。您可以使用已安装的用户,而不是root用户权限。
MySQL到PostgreSQL的几种迁移方法https://mp.weixin.qq.com/s/cHnqkLG9651DzAP5Dd2n8wMySQL to PostgreSQL: Migrate Data in 4 Easy Methods
20230915
由于传统磁盘顺序访问性能远好于随机访问,采用Logging的故障恢复机制意图利用顺序写的Log来记录对数据库的操作,并在故障恢复后通过Log内容将数据库恢复到正确的状态。简单的说,每次修改数据内容前先顺序写对应的Log,同时为了保证恢复时可以从Log中看到最新的数据库状态,要求Log先于数据内容落盘,也就是常说的Write Ahead Log,WAL。
在数据库系统发展的历史长河中,故障恢复问题始终伴随左右,也深刻影响着数据库结构的发展变化。通过故障恢复机制,可以实现数据库的两个至关重要的特性:Durability of Updates以及Failure Atomic,也就是我们常说的的ACID中的A和D。
- Durability of Updates:已经Commit的事务的修改,故障恢复后仍然存在;
- Failure Atomic:失败事务的所有修改都不可见。
Redo-Undo Logging
可以看出的只有Undo或Redo的问题,主要来自于对Commit标记及Data落盘顺序的限制,而这种限制归根结底来源于Log信息中对新值或旧值的缺失。因此Redo-Undo采用同时记录新值和旧值的方式,来消除Commit和Data之间刷盘顺序的限制。
如此一来,同Page的不同事务提交就变得非常简单。同时可以将连续的数据攒着进行批量的刷盘已利用磁盘较高的顺序写性能。
这篇文章太经典了!!
腾讯 13 年,我所总结的Code Review终极大法一文梳理Code Review方法与实践https://mp.weixin.qq.com/s/HoFSNCd1U3eoUqYaQiEgwQ
没读过 oauth2.0 RFC,就去设计第三方授权登陆的人,终归还要再发明一个蹩脚的 oauth。
一些通用的原则,你虽然不知道,但是你会最终遵守,但是过程很曲折。如果你一开始就知道这些原则并遵守,那么会轻松很多。
2012 年我刚毕业,和一个去了广州联通公司的华南理工毕业生聊天。当时他说他工作很不开心,因为工作里不经常写代码,而且认为自己有 ACM 竞赛金牌级的算法熟练度+对 CPP 代码的熟悉,写下一个个指针操作内存,还有什么程序写不出来,什么事情做不好。当时我觉得,挺有道理,编程工具在手,我什么事情做不了?
现在我会告诉他,复杂如 Linux 操作系统、Chromium 引擎、Windows Office,你做不了。原因是他根本没进入软件工程的工程世界,不是会搬砖就能修出港珠澳大桥。但是这么回答并不好,举证用的论据离我们太遥远了。我现在会回答,你做不了,简单如一个权限系统,你知道怎么做么?堆积一堆逻辑层次一维展开的 if else?简单如一个共享文件管理,你知道怎么做么?堆积一堆逻辑层次一维展开的 if else?你公司有上万台服务器,你要怎么写一个管理平台?堆积一堆逻辑层次一维展开的 if else?
上来就是干,能实现上面提到的三个看似简单的需求么?想一想,亚马逊、腾讯云们折腾了多少年,最后才找到了容器+Kubernetes 的大杀器。这里需要谷歌多少年在 BORG 系统上的实践,提出了优秀的服务编排领域模型。权限领域,有 RBAC、DAC、MAC 等等模型,到了业务,又会有细节的不同。如 Domain Driven Design 说的,没有良好的领域思考和模型抽象,逻辑复杂度就是 n^2 指数级的,你得写多少 if else,得思考多少可能的 if 路径,来 cover 所有的不合符预期的情况。你必须要有 Domain 思考探索、model 拆解/抽象/构建的能力。有人问过我,要怎么有效地获得这个能力?这个问题我没能回答,就像是在问我,怎么才能获得 MIT 博士的学术能力?我无法回答。唯一回答就是,进入某个领域,就是首先去看前人的思考,站在前人的肩膀上,再用上自己的通识能力,去进一步思考。至于怎么建立好的通识思考能力,可能得去常青藤读个书吧 :),或者就在工程实践中思考和锻炼自己的这个能力!
20230914
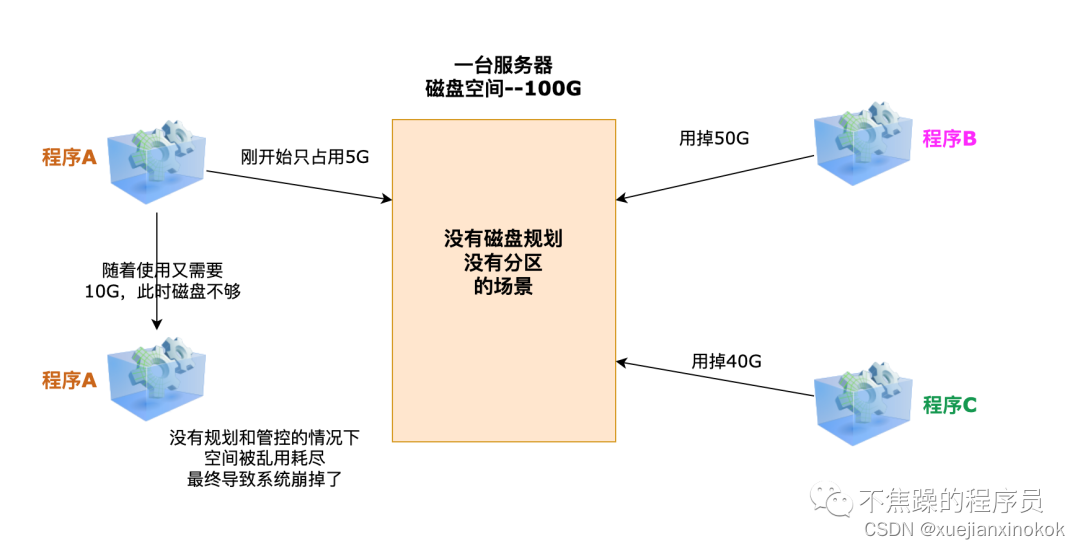
为什么要有pv,pvc:
隔离由于空间不够用导致的风险蔓延
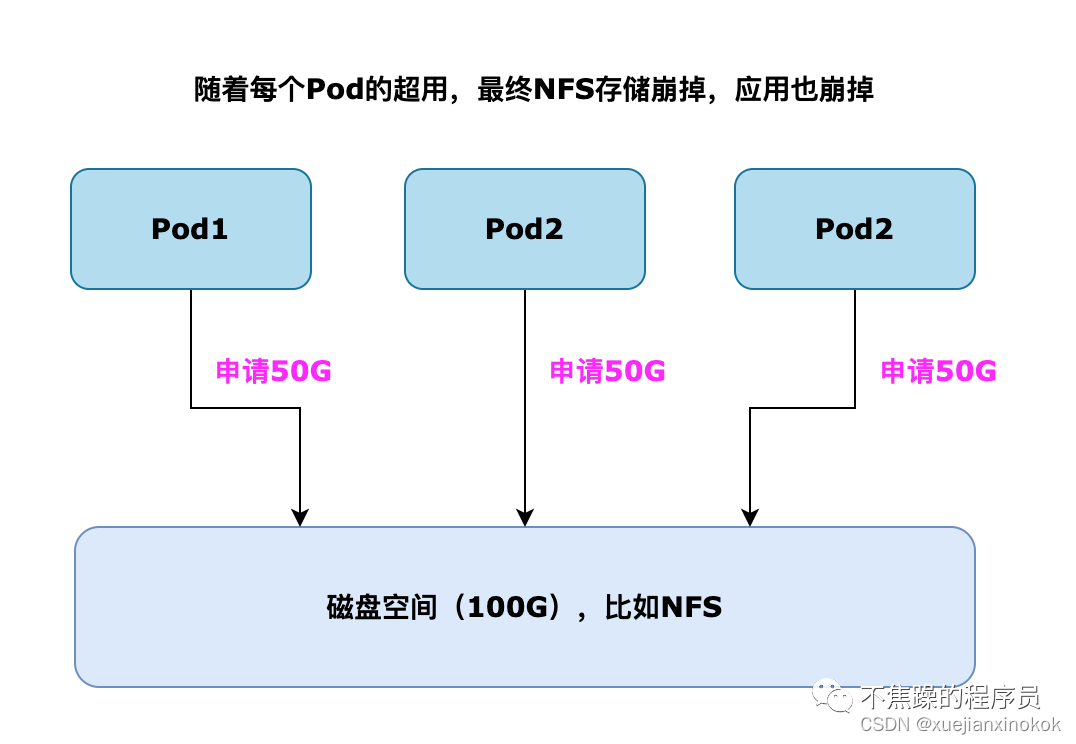
在没有使用PV、PVC之前,各个Pod都可以任意的向存储资源里(比如NFS)写数据,随便一个Pod都可以往磁盘上插一杠子,长期下去磁盘的管理会越来越混乱,然后导致数据使用超限,磁盘爆掉,最后导致磁盘上的所有应用全部挂掉。
为了解决这个问题,引入了PV、PVC的概念,达到限制Pod写入存储数据大小的目的,从而更好地保障了系统的可用性、稳定性。
有了PVC、PV之后,所有Pod使用存储资源,保持一个原则:先规划 → 后申请 → 再使用。
那你肯定有一个疑问,“StorageClass是自动化创建PV,跟原本的无序不可控是一样的效果啊,都可以随便占用存储资源啊”。
其实不然,使用StorageClass只是自动化了创建PV的流程,但依旧执行的是一个存储可控的流程。每个Pod使用多少存储空间是固定的,Pod没有办法超额使用存储空间,更不会影响到别的应用,要出故障也只是某个Pod自己出故障。
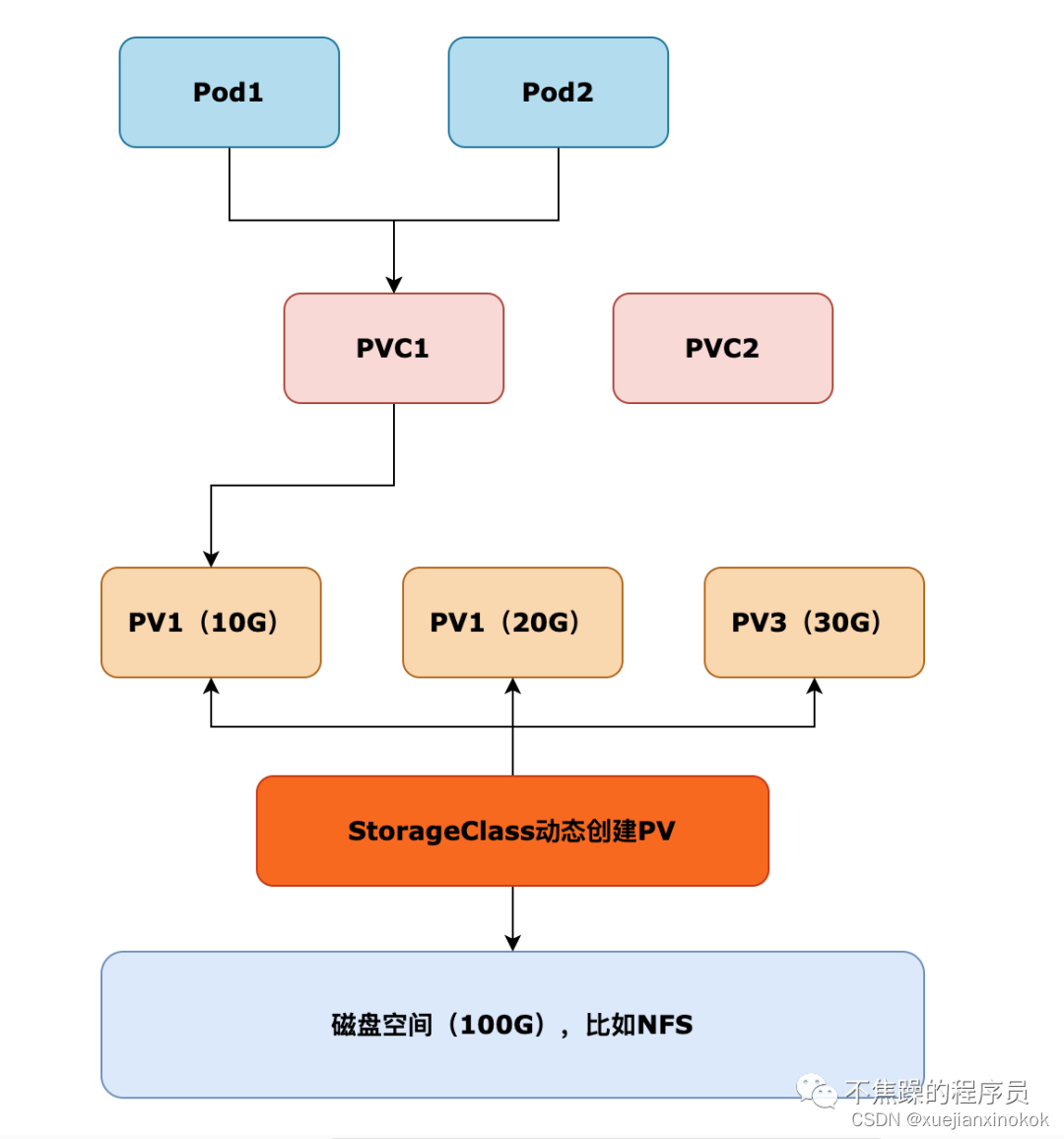
Pod使用StorageClass自动挂载存储卷
文中选择通过helm的方式安装nfs-subdir-external-provisioner,这种方式相对简单。安装文档、安装过程见下文:
- 安装文档:
Pod利用StorageClass自动创建PV,同时在对应的存储目录上创建了文件,写入了数据
20230901
一般来说,订阅有两种类型:
-
临时订阅,其中订阅仅在使用者启动并运行时才有效。一旦消费者关闭,他们的订阅和尚未处理的消息就会丢失。
-
持久订阅,只要未显式删除,订阅就会得到维护。当消费者关闭时,消息平台会维持订阅,稍后可以恢复消息处理。
2019 年 3 月,Mozilla 推出了 WebAssembly 系统接口(Wasi),以标准化 WebAssembly 应用程序与系统资源之间的交互抽象,例如文件系统访问、内存管理和网络连接,该接口类似于 POSIX 等标准 API。Wasi 规范的出现极大地扩展了 WebAssembly 的应用场景,使得 Wasm 不仅限于在浏览器中运行,而且可以在服务器端得到应用。同时,平台开发者可以针对特定的操作系统和运行环境提供 Wasi 接口的不同实现,允许跨平台的 WebAssembly 应用程序运行在不同的设备和操作系统上。
-
可移植性更好:容器的架构限制了它们的可移植性。例如,针对 linux/amd64 构建的容器无法在 linux/arm64 上运行,也无法在 windows/amd64 或 windows/arm64 上运行。这意味着组织需要为同一个应用程序创建和维护多个镜像,以适应不同的操作系统和 CPU 架构。而 WebAssembly 通过创建一个在可以任何地方运行的单一 Wasm 模块来解决这个问题。只需构建一次 wasm32/wasi 的应用程序,任何主机上的 Wasm 运行时都可以执行它。这意味着 WebAssembly 实现了一次构建,到处运行的承诺,不再需要为不同的操作系统和 CPU 架构构建和维护多个镜像。
20230830
WebRTC 主要由三部分组成:「浏览器 API」、「音视频引擎」和「网络 IO」。
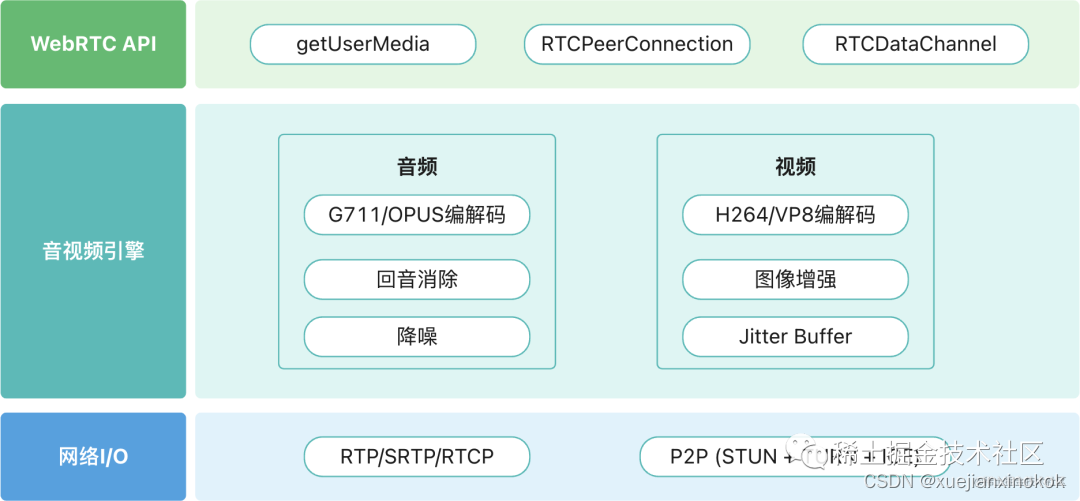
浏览器 API
用于「采集摄像头和麦克风」生成媒体流,并处理音视频通信相关的「编码、解码、传输」过程,可以使用以下 API 在浏览器中创建实时通信应用程序。
还有像回声消除AEC(Acoustic Echo Chancellor)、背景噪音抑制ANS(Automatic Noise Suppression)和Jitter buffer用来防止视频抖动,这些问题在 WebRTC 中也提供了非常成熟、稳定的算法,并且提供图像增加处理,例如美颜,贴图,滤镜处理等。
-
getUserMedia: 获取麦克风和摄像头的许可,使得 WebRTC 可以拿到本地媒体流;
-
RTCPeerConnection: 建立点对点连接的关键,提供了创建,保持,监控,关闭连接的方法的实现。像媒体协商、收集候选地址都需要它来完成;
-
RTCDataChannel: 支持点对点数据传输,可用于传输文件、文本消息等。
WebRTC 「内置了强大的音视频引擎」,可以对媒体流进行编解码、回声消除、降噪、防止视频抖动等处理,我们使用者大可不用去关心如何实现 。主要使用的音视频编解码器有:
-
OPUS: 一个开源的低延迟音频编解码器,WebRTC 默认使用;
-
G711: 国际电信联盟 ITU-T 定制出来的一套语音压缩标准,是主流的波形声音编解码器;
-
VP8: VP8,VP9,都是 Google 开源的视频编解码器,现在主要用于 WebRTC 视频编码;
-
H264: 视频编码领域的通用标准,提供了高效的视频压缩编码,之前 WebRTC 最先支持的是自己家的 VP8,后面也支持了 H264、H265 等。
WebRTC 传输层用的是 「UDP」 协议,因为音视频传输对「及时性」要求更高,如果使用 TCP 当传输层协议的话,如果发生丢包的情况下,因为 TCP 的可靠性,就会尝试重连,如果第七次之后仍然超时,则断开 TCP 连接。而如果第七次收到消息,那么传输的延迟就会达到 2 分钟。在延迟高的情况下,想做到正常的实时通讯显然是不可能的,此时 TCP 的可靠性反而成了弊端。
而 UDP 则正好相反,它只负责有消息就传输,不管有没有收到,这里从底层来看是满足 WebRTC 的需求的,所以 WebRTC 是采用 UDP 来当它的传输层协议的。
这里主要用到以下几种协议/技术:
-
RTP/SRTP: 传输音视频数据流时,我们并不直接将音视频数据流交给 UDP 传输,而是先给音视频数据加个 RTP 头,然后再交给 UDP 进行,但是由于浏览器对安全性要求比较高,增加了加密这块的处理,采用 SRTP 协议; -
RTCP:通过 RTCP 可以知道各端的网络质量,这样对方就可以做流控处理; -
P2P(ICE + STUN + TURN): 这是 WebRTC 最核心的技术,利用 ICE、STUN、TURN 等技术,实现了浏览器之间的直接点对点连接,解决了 NAT 穿透问题,实现了高质量的网络传输。
WebRTC这么火,前端靓仔,请收下这篇入门教程本文是针对小白的 WebRTC 快速入门课,如果你还之前还不了解 WebRTC,希望你能认真阅读本文,实现对 WebRTC 的零的突破 💪https://mp.weixin.qq.com/s/pTGkFqAnGkBmE08nOa4RCwhttps://github.com/wang1xiang/webrtc-tutorial/tree/master/04-one-to-onehttps://github.com/wang1xiang/webrtc-tutorial/tree/master/04-one-to-one
使用下面的命令执行堆dump,方便我们后续分析:
# 安装gdb,如果机器上有就无需安装
yum install -y gdb
# 设置不限制core dump大小
ulimit -c unlimited
# 生成core dump,文件名叫core,也可以自己起名,100是目标Java进程pid,这个需要根据实际的来,命令执行完毕后会生成一个core.100的core dump
gcore 100 -o core
# 生成堆dump
jmap -dump:format=b,file=heap.hprof `which java` core.100
#实际执行的是
jmap -dump:format=b,file=heap.hprof /usr/bin/java ./core.100 有的同学可能看到这里就开始迷糊了,Java堆dump不是用jmap命令吗,上边的命令跟jmap也没什么关系呀,我们这里之所以用gcore而不是jmap来dump,主要是因为在OOM时,通常JVM已经无法正常使用jmap来dump了(针对本次排查就是这种情况),如果你一定要使用jmap来操作,那么他会报错,无法进行堆dump,同时会在错误信息中告诉我们可以尝试使用jmap -F参数来进行堆dump,但是加上这个参数后,你会发现噩梦开始了,因为此时虽然能正常进行dump,但是速度可以说是惨不忍睹,4G的堆dump时间要按小时算,本质上是因为当我们使用jmap -F来进行堆dump的时候实际上底层使用了ptrace来dump(使用ptrace读取目标进程内存然后写出到文件),由于ptrace一次最多只能读取4字节(32位机器),所以导致他的速度也极其的慢; 而gcore生成速度相对于正常jmap来说也是比较快的,对于jmap -F就更快了; 所以,基于以上几点,我们选择了使用gcore来进行堆dump;
当我们使用gcoredump完后,因为最终还是需要使用Java系的工具进行内存分析,所以还是要将core dump转换为Java的堆dump,此时我们就可以执行以下命令来转换了:
# 生成堆dump
jmap -dump:format=b,file=heap.hprof `which java` core.100
jmap 是一个可以输出所有内存中对象的工具,甚至可以将 VM 中的 heap ,以二进制输出成文本。
jmap -dump:format=b,file=f1 3024 可以将 3024 进程的内存 heap 输出出来到 f1 文件里。 它可以打印出某个 java进程(使用 pid )内存内的,所有 ‘ 对象 ’ 的情况(如:产生那些对象,及其数量)
epoll 的工作原理?
先用 epoll_create 创建一个 epoll 对象 epfd,再通过 epoll_ctl 将需要监视的 socket 添加到epfd中,最后调用 epoll_wait 等待数据,当epoll_wait返回后,就可以遍历它返回的事件列表,然后根据事件类型做出相应的处理。
复制
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...);
listen(s, ...)
int epfd = epoll_create(...);
epoll_ctl(epfd, ...); //将所有需要监听的socket添加到epfd中
while(1) {
int n = epoll_wait(...);
for(接收到数据的socket){
//处理
}
}epoll、select、poll的区别?
select 实现多路复用的方式是,将已连接的 Socket 都放到一个文件描述符集合,然后调用 select 函数将文件描述符集合拷贝到内核里,让内核来检查是否有网络事件产生,检查的方式很粗暴,就是通过遍历文件描述符集合的方式,当检查到有事件产生后,将此 Socket 标记为可读或可写, 接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的 Socket,然后再对其处理。
所以,对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ,而且还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的,在 Linux 系统中,由内核中的 FD_SETSIZE 限制, 默认最大值为 1024,只能监听 0~1023 的文件描述符。
poll 不再用 BitsMap 来存储所关注的文件描述符,取而代之用动态数组,以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。
但是 poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
epoll 通过两个方面,很好解决了 select/poll 的问题。
- 第一点,epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过 epoll_ctl() 函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删改一般时间复杂度是 O(logn)。而 select/poll 内核里没有类似 epoll 红黑树这种保存所有待检测的 socket 的数据结构,所以 select/poll 每次操作时都传入整个 socket 集合给内核,而 epoll 因为在内核维护了红黑树,可以保存所有待检测的 socket ,所以只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。
- 第二点, epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用 epoll_wait() 函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
可以看到 epoll 相关的接口作用:
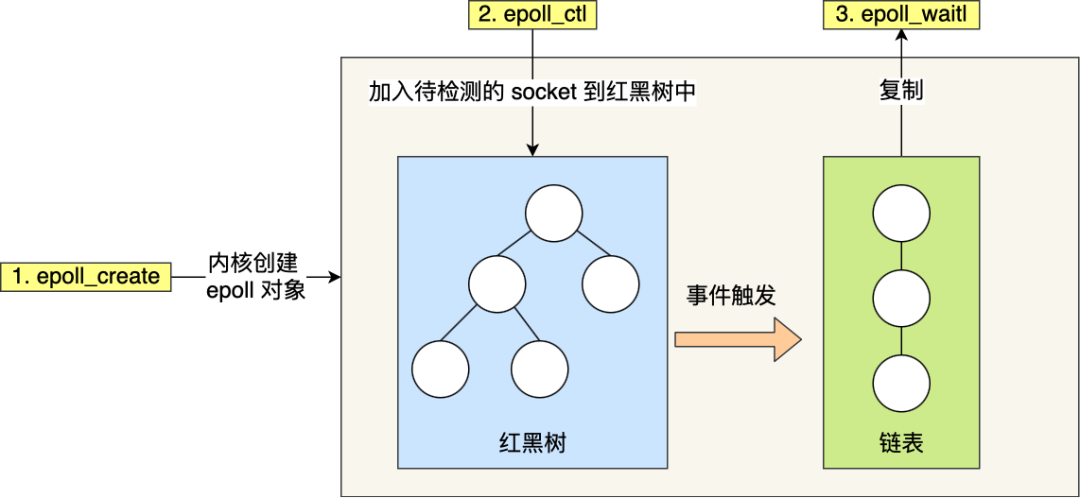
图片
epoll 的方式即使监听的 Socket 数量越多的时候,效率不会大幅度降低,能够同时监听的 Socket 的数目也非常的多了,上限就为系统定义的进程打开的最大文件描述符个数。因而,epoll 被称为解决 C10K 问题的利器。
20230822
优质系列文章
20230821
量化概述
ONNXRuntime 中的量化是指 ONNX 模型的 8 bit 线性量化。
在量化过程中,浮点实数值映射到 8 bit 量化空间,其形式为:
VAL f p 32 = Scale ∗ ( VAL q u a n t i z e d − Zero p o i n t ) \text{VAL}_{fp32}=\text{Scale} * (\text{VAL}_{quantized} - \text{Zero}_{point})VALfp32=Scale∗(VALquantized−Zeropoint)
Scale 是一个正实数,用于将浮点数映射到量化空间,计算方法如下:
-
对于非对称量化:
scale = (data_range_max - data_range_min) / (quantization_range_max - quantization_range_min)
使用一个映射公式将输入数据映射到[0,255]的范围内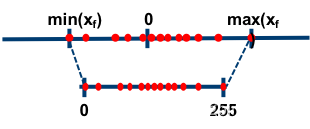
-
对于对称量化:
scale = abs(data_range_max, data_range_min) * 2 / (quantization_range_max - quantization_range_min)
对称量化即使用一个映射公式将输入数据映射到 [-128,127] 的范围内: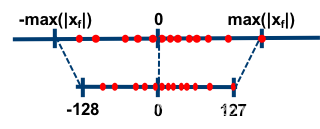
-
Zero_point 表示量化空间中的零。
 https://wangsp.blog.csdn.net/article/details/128078819
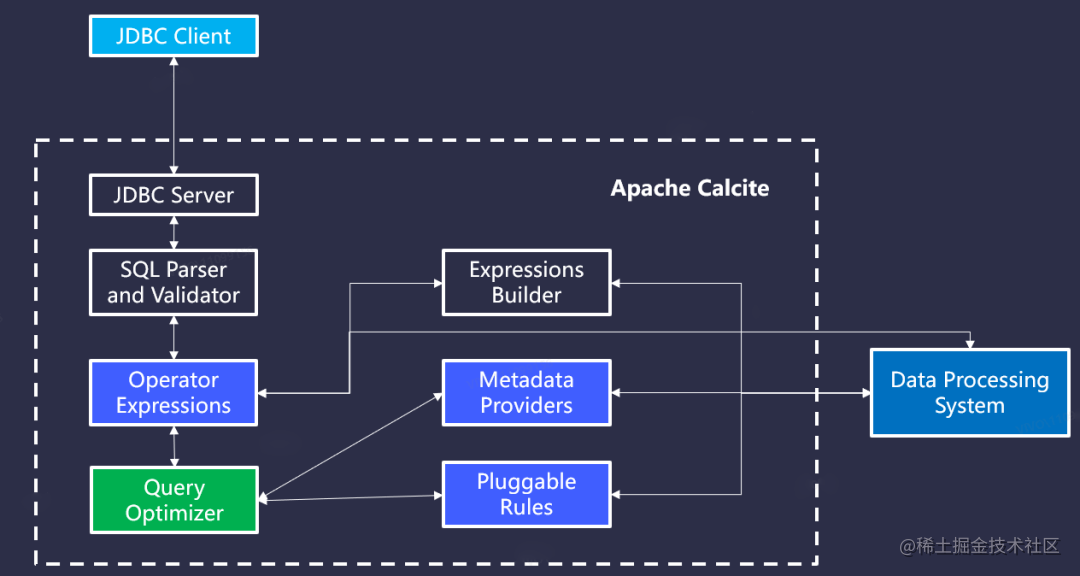
https://wangsp.blog.csdn.net/article/details/128078819Apache Calcite 是一个动态数据管理框架
Backgroundhttps://calcite.apache.org/docs/index.html
public class TestOne {
public static class TestSchema {
public final Triple[] rdf = {new Triple("s", "p", "o")};
}
public static void main(String[] args) {
SchemaPlus schemaPlus = Frameworks.createRootSchema(true);
//给schema T中添加表
schemaPlus.add("T", new ReflectiveSchema(new TestSchema()));
Frameworks.ConfigBuilder configBuilder = Frameworks.newConfigBuilder();
//设置默认schema
configBuilder.defaultSchema(schemaPlus);
FrameworkConfig frameworkConfig = configBuilder.build();
SqlParser.ConfigBuilder paresrConfig = SqlParser.configBuilder(frameworkConfig.getParserConfig());
//SQL 大小写不敏感
paresrConfig.setCaseSensitive(false).setConfig(paresrConfig.build());
Planner planner = Frameworks.getPlanner(frameworkConfig);
SqlNode sqlNode;
RelRoot relRoot = null;
try {
//parser阶段
sqlNode = planner.parse("select \"a\".\"s\", count(\"a\".\"s\") from \"T\".\"rdf\" \"a\" group by \"a\".\"s\"");
//validate阶段
planner.validate(sqlNode);
//获取RelNode树的根
relRoot = planner.rel(sqlNode);
} catch (Exception e) {
e.printStackTrace();
}
RelNode relNode = relRoot.project();
System.out.print(RelOptUtil.toString(relNode));
}
}Apache Calcite的出现,大大简化了这些复杂的工程。Calcite可以让用户很方便的给自己的系统套上一个SQL的外壳,并且提供足够高效的查询性能优化。
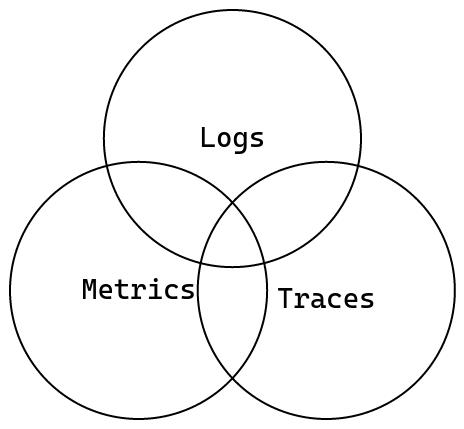
日志(Logs)
日志作为最常用的可观测性数据源之一,相信多数开发者都比较熟悉。其本质上就是一种带有时间戳的离散事件记录,通常用于记录系统的运行状态,日志的使用十分简单,只需要在代码中需要报告信息的点添加一行代码,就可以将这些信息输出到控制台或文件中,但是日志也有很大的缺点,它的输出是离散的,这意味着在记录的时候,无法将日志信息相互关联,也无法知道日志信息的上下文,尤其是在多线程的环境下,最终输出的信息比较混乱,不便于检索和分析。
指标(Metrics)
指标是一种定量衡量,例如平均值、比率和百分比等。其值始终为数字而非文本,可以通过数学方法统计和分析,其主要用于描述系统运行状态的数据,比如 CPU 的使用率、内存的使用率、磁盘的使用率等,这些数据可以用来监控系统的运行状态,也可以用来预警。
追踪(Traces)
追踪是一种用于记录系统中一次请求的完整生命周期的数据,它可以记录下一个请求从开始到结束的所有信息,包括请求的发起者、接收者、请求的路径、请求的状态、请求的耗时、请求的错误信息等,这些信息可以用来分析系统的性能瓶颈,也可以用来分析系统的错误。追踪本质上也是一种日志,他与日志的数据结构十分相似,但是它能够提供比日志更丰富的信息。特别是在分布式系统中,追踪能够跨越多个服务,汇总出一次请求的完整信息,让开发人员能够更方便的找到系统中的问题。
20230818
20230817
const { default: esbuild } = await import("https://esm.sh/esbuild-wasm@0.18.11/");
await esbuild.initialize({
wasmURL: "https://esm.sh/esbuild-wasm@0.18.11/esbuild.wasm",
});
const res = await esbuild.transform(`
let a: number = 2;
`, {
loader: "ts",
});
console.log(res.code);
20230816

缓存不是直接对单个字节进行操作的,而是以块(通常称为“缓存行”)为单位操作的。一个缓存行通常包含64字节的数据。
在Java 8及以上版本中,@Contended注解是属于jdk的内部API,因此在正常情况下使用时需要打开开关-XX:-RestrictContended才能正常使用。同时需要注意的是,@Contended在JDK 9以后的版本中可能无法正常工作,因为JDK 9开始禁止使用Sun的内部API。
伪共享问题假设有内存相邻的数据想 x、y,CPU1 要修改 x,CPU 要修改 y,CPU1 读取 x 时会把 x、y 都读进来,CPU1 改完要通知其他 CPU,CPU1 会把整个缓存行数据都通知一遍,这时 CPU2 虽然不用 x 但 y 被通知了,需要重新在读取 y 所在的缓存行,CPU2 改完 y 后也会把整个缓存行数据都通知一遍,这时 CPU1 虽然不用 y 但 y 被通知了也需要重新读取缓存行,这就产生了位于同一缓存行的两个不同数据,被两个不同 CPU 锁定,产生互相影响问题 ,也就是伪共享问题
20230810
nginx 1.18.0 后版本可以直接使用hash指令 配置一致性hash 并且支持故障转移 只需要修改配置文件
upstream mq{
hash $request_uri consistent;
server 192.168.51.65:15672 weight=1;
server 192.168.50.177:15672 weight=1;
}
upstream mq2{
hash $remote_addr consistent;
server 192.168.51.65:5672 weight=1;
server 192.168.51.67:5672 weight=1;
}
https://www.cnblogs.com/guanxiaohe/p/16227526.htmlhttps://www.cnblogs.com/guanxiaohe/p/16227526.html

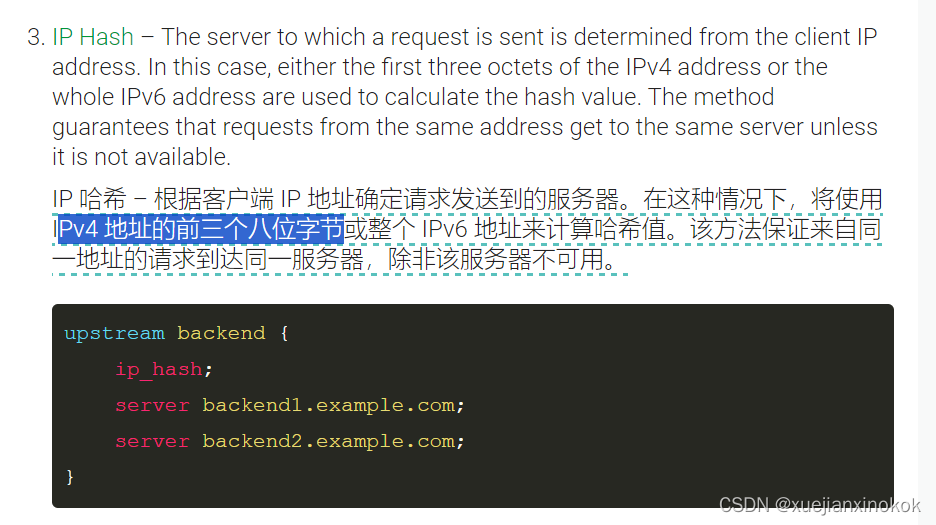
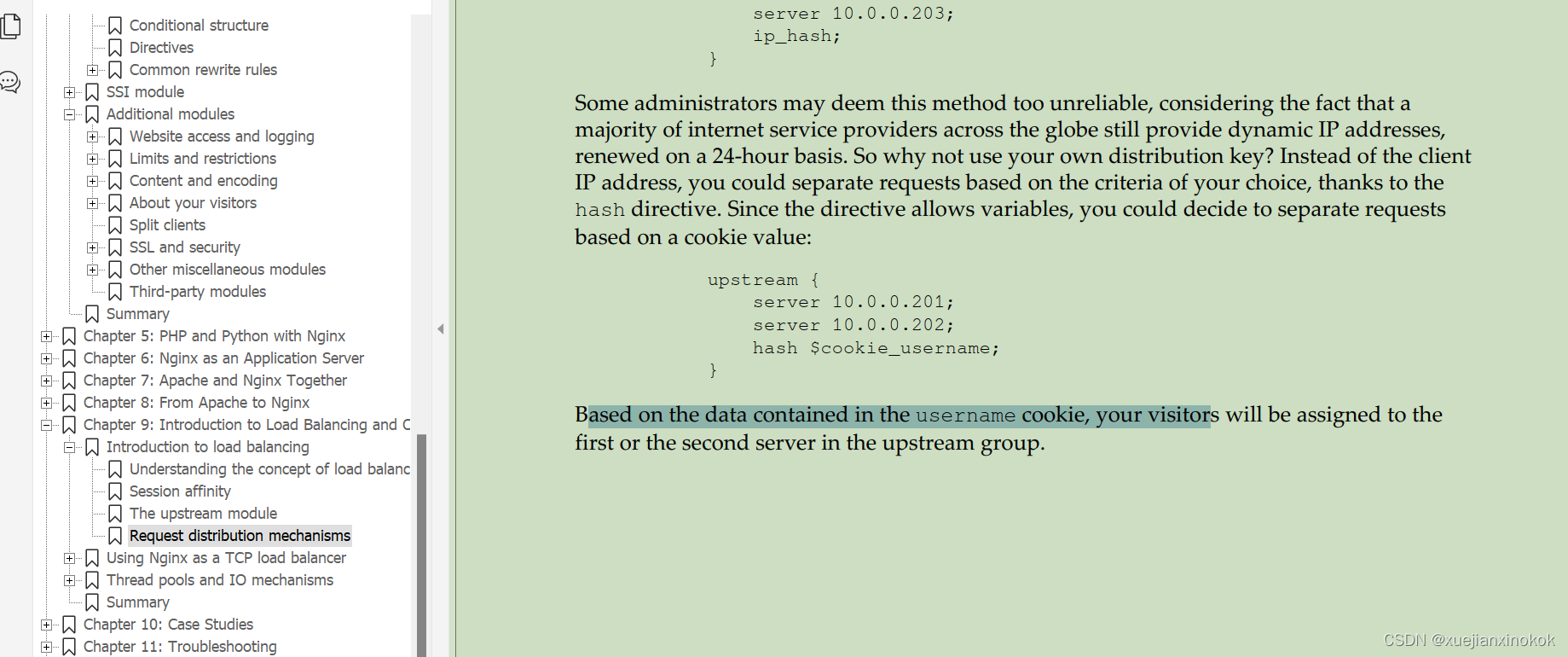
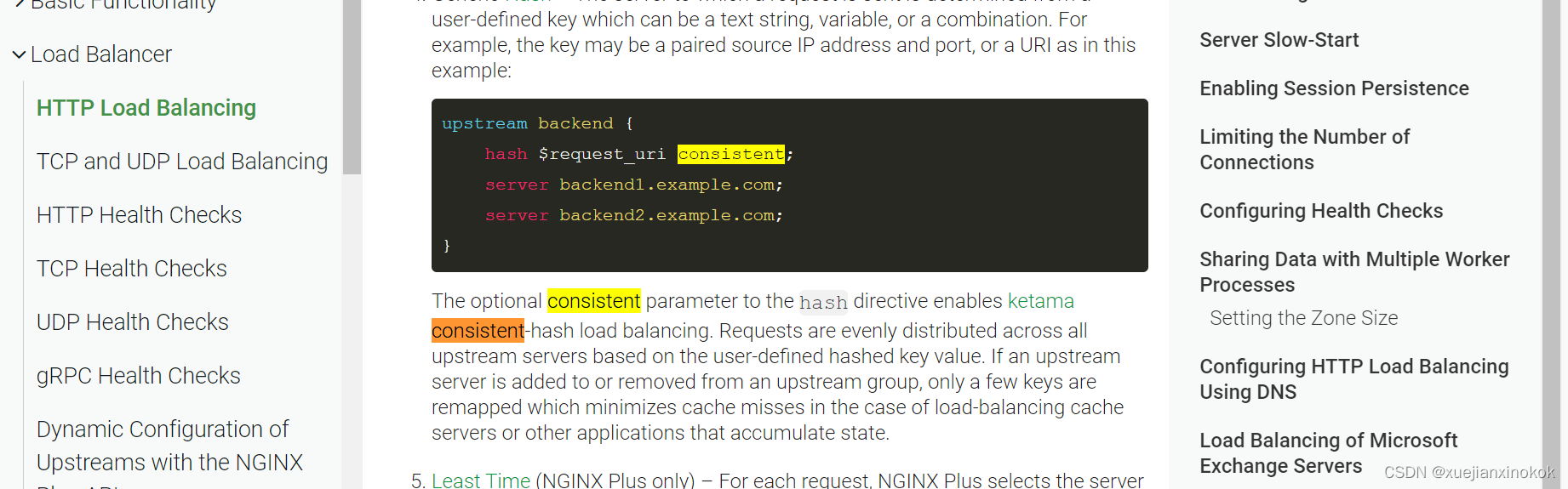
upstream backend {
hash $remote_addr consistent;
server 192.168.120.102:30000;
server 192.168.120.104:30000;
server 192.168.120.106:30000;
}
https://www.cnblogs.com/wh-blog/p/16345569.htmlhttps://www.cnblogs.com/wh-blog/p/16345569.html

20230803
实现步骤如下:
- chrome 浏览器F12或者右键点击“检查”打开控制台,点击控制台右边的设置按钮。如下图所示
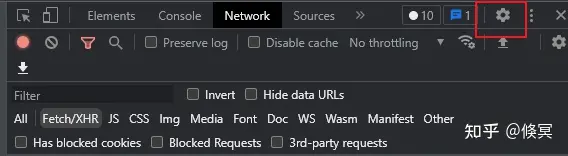
chrome控制台设置
2. 在Ignore List选项里面添加配置,我针对vue2.0项目的所有vue源码文件都做使用正则【vue.*\.js$】做了忽略,debugger 调试的时候跳过这些忽略的文件。
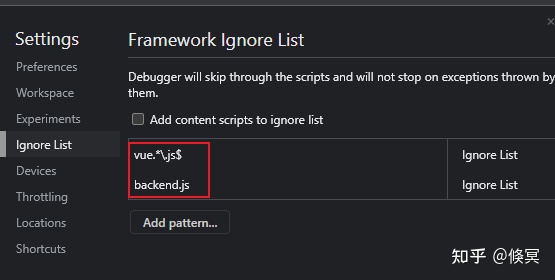
忽略文件js文件配置先。
http://www.kuazhi.com/post/471984.htmlhttp://www.kuazhi.com/post/471984.html

①同一域名下,同一GET请求的并发数是1,也就是说上一个请求结束,才会执行下一个请求,否则置入队列等待发送;
②同一域名下,不同GET/POST请求的并发数量是6。当发送的请求数量达到6个,并且都没有得到响应时,后面的请求会置入队列等待发送
axum 来自于 tokio 团队
Axum 是 tokio 官方出品的一个非常优秀的 web 开发框架
axum框架,因为它有较为易用的 API 设计,且它是基于 hyper 构建的,且它是 tokio 开发组的产物。(它是一个非常年轻的框架,这点会使很多人不敢尝试)
通讯过程中最普遍的请求-响应模型该如何构建?其实,我们只需要一个处理 Request,并返回 Response 的异步函数就可以表达这个模型:
async fn(Request) -> Result<Response, Error>20230728
p2p
性能优化的文章
更好地利用数据缓存使您的程序运行得更快
让你的程序运行得更快:避免函数调用
分支如何影响代码的性能以及您可以采取什么措施?
Make your programs run faster by better using the data cache - Johnny's Software LabWe investigate how the data cache influences the performance of your program, talk about ways for you to write faster programs by better leveraging the data cache.https://johnnysswlab.com/make-your-programs-run-faster-by-better-using-the-data-cache/Make your programs run faster: avoid function calls - Johnny's Software Labhttps://johnnysswlab.com/make-your-programs-run-faster-avoid-function-calls/
20230725
20230721
Realtime Face Recognition in the Browser浏览器中的实时人脸识别
媒体查询、响应式设计?
HashingA visual, interactive introduction to hash functions.https://samwho.dev/hashing/
killport 是一个命令行实用程序,用于终止侦听特定端口的进程。它的设计目标是简单、快速且有效。该工具使用 Rust 构建,适用于 Linux、macOS 和 Windows。
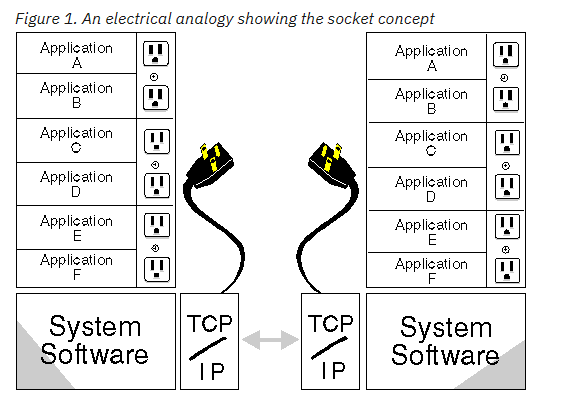
socket 到底是个啥你能解释一下什么是 socket 吗?https://mp.weixin.qq.com/s/Ebvjy132eRDOmcIL5cmxJw
20230720
Chromium 嵌入式框架 (CEF) 是一个简单的框架,用于在其他应用程序中嵌入基于 Chromium 的浏览器。
20230719
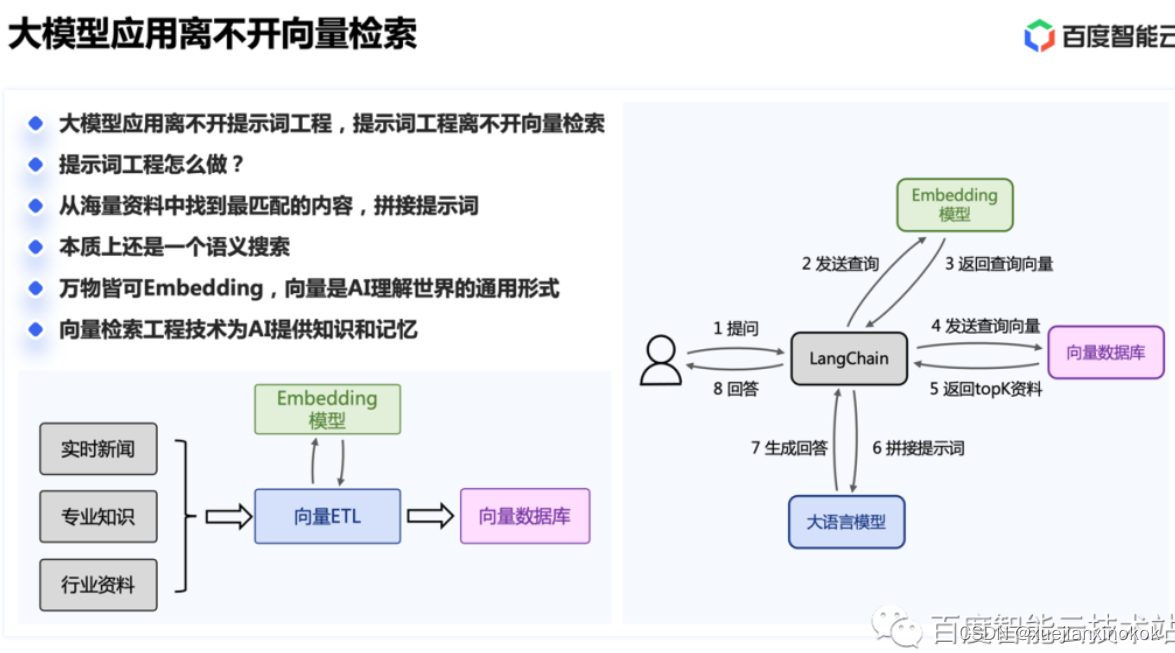
因此业界探索有没有可能放弃全局最优解,寻找局部最优解,来节省计算量。由此发展出了近似最近邻算法,业界有四种算法:哈希、树搜索、倒排、图搜索。哈希、树搜索、倒排这三种类似,都是通过某种分类的方式,将数据预分类,划分空间,对号入座来减少计算量;而图搜索则是一种比较新的思路。
考核算法的效果,主要看两个指标,一是性能,也就是查询的耗时以及能承受的 QPS;另一个就是召回率,代表查询准确度。我们将近似算法查出来的结果跟从全局视角看的结果的集合对比,重叠度就是召回率。比如暴力算法,那他召回率就是 100%,近似算法则有高有低,有的也可以逼近 99% 以上。
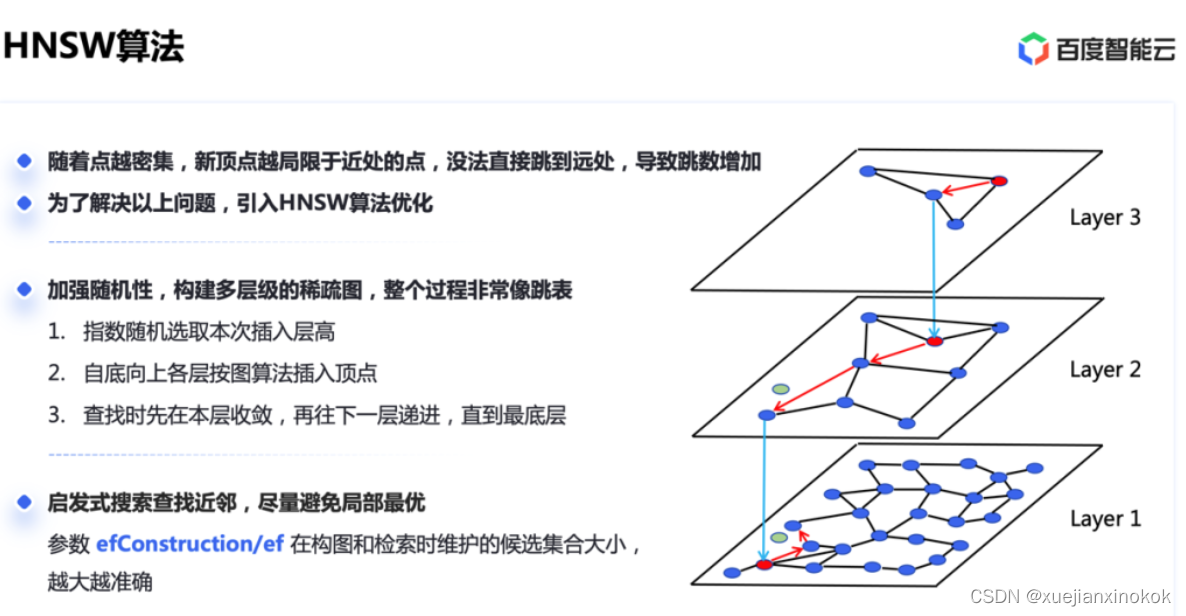
HNSW(Hierarchical Navigable Small Word)
HNSW图算法是一种比较新的近似向量检索思路,它基于最小世界理论,就是说世界上任意两个人,都可以通过六跳联系起来。如果把向量看做人的话,按向量间的距离关系构造一个这样类似于真实世界的「小世界网络」,通过贪心算法,按距离建立联系一跳一跳逼近目标的向量定点。
业界摸索出了 HNSW 算法,即采用类似链表查找算法里的跳表的思路。链表是一维的,图是二维的。我们来建立不同层级的图,往上指数递减定点数量来形成稀疏图,这样越稀疏的图自然就越能连接远方。

Locality Sensitive Hashing: search for cosine similarity
之前介绍的所有方法都适用于搜索高维空间上距离相邻的点(比如欧式距离)。下面,我们来介绍一个用来高效检索 cosine similarity metrics 的算法,locality sensitive hashing(LSH)。LSH 的思路和 IVF 类似,也是通过一种手段将空间上的 vector points hash 到不同的 bucket 里面,且保证同一个 bucket 里的 points 在 cosine similarity 上更相近(角度接近)。
要了解 LSH,依然需要我们发挥一下高维空间想象力。咱们一步一步来。
1)LSH 需要给定一个固定数字(say num)的 random projections,每个 random projection 就是一个和维度等长的 vector。这个 random projection 在这个高维空间中相当于一个 hyperplane(超平面),把整个高维空间一分为二。
2)DotProduct 计算:给定空间中的一个 vector,和某个 random projection 求 dot product,值是一个标量。这个标量>0 表示这个 vector 在这个超平面的一边(<0 则表示在另一边)。将这个标量用 0 或 1 表示,然后给定一个 vector 和所有的 random projections 求 dot product 就会得到 num of bits,这个 bit string 就是这个 vector 在这组 random projections 下的 hash bucket(比如当 num=8 时,一个 bit string 可以是 01101011)。
3)DotProduct 和 Cosine similarity 的关系:当两个向量在角度上接近时,它们倾向于落在随机绘制的超平面的同一侧。因此,对于这些随机超平面的投影,它们的哈希位会是相同的。这就是 LSH 与余弦相似度相结合的原因。当随机投影的超平面数量更多时(即,更长的哈希码),方向接近(根据余弦相似度)的向量会得到相同或相似的哈希码的可能性就会增加。
4)建立多组 random projections 和多个 hash 表映射:由于超平面是随机生成的,有可能它无法正确地将相似和不相似的向量分开。为了解决这个问题,使用多个哈希表(每个表都有一组不同的随机超平面)。这增加了相似向量在至少一个表的同一桶中被哈希的概率,从而提升了搜索的准确性。
有了上述的理论铺垫,可以总结出 LSH 的算法描述:
1)通过一组 random projections 将整个空间分成了 2^num 个 hash bucket,然后将不同的点通过计算 hash bits 映射到这些 bucket 里面。
2)然后给定一个要查询的 vector,计算出相应的 bucket,然后通过 linear search 来找到在这个 bucket 里 cosine similarity 最高的点。
3)提升准确率:也可以通过创建多组 random projections,将整个空间的点映射到多个 hash table 里面,找到对应每个 hash table 里 match 的 hash bits 的点的集合。通过计算 cosine similarity 找到最相似的点。
在关系型数据库中,为了提升查询效率,我们通常用 B+树来建立索引,原因是 1)B+树的搜索效率更高(因为 fanout children 更多,搜索 1 亿数据,fanout 100 的话只需要 4 次查询);2)对内存更友好,把非叶节点存在内存中,支持高效索引,然后 sequential IO 来读取具体的数据。
20230717
18 张图,总结 Java 容器化的最佳实践https://mp.weixin.qq.com/s/2S63ewuYes5FP5hh3Hq7Sg
20230714
灰度->二值->求导找边界

20230712

2023,我私藏的英语学习工具 - 少数派在这篇文章中,我会介绍 2023 年对我来说英语学习最有帮助的辅助工具和我自己的使用心得。https://sspai.com/post/80086
20230711
当没有设置这个参数时,默认的参数其实是--target bundler,其是编译成给webpack之类的脚手架使用的。因此这里使用—target web,则是使其编译成可直接在web中使用。
相关参数如下:
-
• bundler:编译成给webpack之类的脚手架使用
-
• web:编译成web可直接使用
-
• nodejs:编译成可通过require来加载的node模块
-
• deno:编译成可通过import加载的deno模块
-
• no-modules:跟web类似,但是更旧,且不能使用es模块
wasm-pack build --target web 可以直接引入JS类型!这里主要是利用js-sys这个依赖,可以在官方文档上看到很多JS的类型和函数,直接引入即可使用。
20230710
fasttext 做词嵌入,作为向量搜索的数据预处理
先前训练的模型可用于计算词汇表外单词的单词向量。假设您有一个包含要计算向量的单词的文本文件 queries.txt ,请使用以下命令:
$ ./fasttext print-word-vectors model.bin < queries.txt
这会将词向量输出到标准输出,每行一个向量。
200 行 Rust 代码编写一个向量搜索库,代码已开源!Rust 实践https://mp.weixin.qq.com/s/xdZHGu1qWDnUhJZTPGp42w
InnodDB 的每个事务都有一个唯一的事务 ID,叫做 transaction id,该 ID 在事务开始的时候向 InnoDB 申请,并且按照申请顺序严格递增。
每行数据都会有多个版本,每次事务更新数据的时候都会生成一个新的数据版本,并且把 transaction id 赋值给这个数据版本的事务 id,称为 row trx_id。
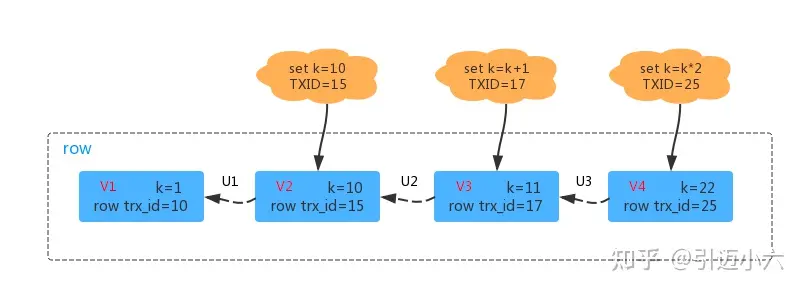
上图是一条行数据的多个版本,最新的版本是 V4。
其中 U3、U2、U1 代表的是 undo log,V1、V2、V3 在物理上并不真实存在,而是在需要的时候通过 V4 配合 undo log 计算获得。
ReadView 如何工作
ReadView 中主要包含 4 个比较重要的内容:
-
m_ids:表示在 生成 ReadView 时 当前系统中活跃的读写事务的事务 id 列表。
-
min_trx_id:表示在生成 ReadView 时当前系统中活跃的读写事务中最小的事务 id,也就是 m_ids 中的最小值。
-
max_trx_id:表示生成 ReadView 时系统中应该分配给下一个事务的 id 值。
-
creator_trx_id:表示生成该 ReadView 的事务的事务 id。
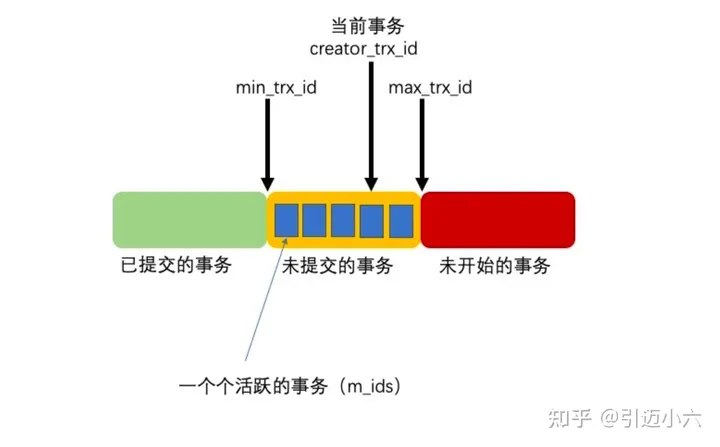
在访问某条记录时,按照下边的步骤判断记录的某个版本是否可见:
-
如果被访问版本的 trx_id 属性值与 ReadView 中的 creator_trx_id 值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。
-
如果被访问版本的 trx_id 属性值小于 ReadView 中的 min_trx_id 值,表明生成该版本的事务在当前事务生成 ReadView 前已经提交,所以该版本可以被当前事务访问。
-
如果被访问版本的 trx_id 属性值大于 ReadView 中的 max_trx_id 值,表明生成该版本的事务在当前事务生成 ReadView 后才开启,所以该版本不可以被当前事务访问。
-
如果被访问版本的 trx_id 属性值在 ReadView 的 min_trx_id 和 max_trx_id 之间,那就需要判断一下 trx_id 属性值是不是在 m_ids 列表中,如果在,说明创建 ReadView 时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
3、记录未提交的场景
如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本。
如果最后一个版本也不可见的话,那么就意味着该条记录对该事务完全不可见,查询结果就不包含该记录。
预写日志 (WAL) 是数据库最重要的组件之一,对数据文件的所有更改都记录在 WAL 中(在 InnoDB 中称为 Redo 日志),并且推迟将修改的页面刷新(Flushed)到磁盘的时间,同时仍然防止数据丢失。
20230707
方法一
- ping -n 3 127.0.0.1 > nul
其中3是需要sleep的秒数
方法二
- timeout /t 3 /nobreak > nul
其中3是需要sleep的秒数
https://www.cnblogs.com/wz0314/p/5523150.htmlhttps://www.cnblogs.com/wz0314/p/5523150.html
本文使用的方法基于流行库 annoy 中使用的一种名叫“Locality Sensitive Hashing”(局部敏感哈希,LSH)的系列算法。
在实际情况下,我们并不需要找到“最近”的视频,只要足够接近就可以了。这就是“近似最近邻”(Approximate Nearest Neighbor,ANN)算法,又称为向量搜索。我们的目标是通过次线性方法找到空间中任何足够近的最近邻。
200 行 Rust 代码编写一个向量搜索库,代码已开源!Rust 实践https://mp.weixin.qq.com/s/xdZHGu1qWDnUhJZTPGp42w
Wasmer 提供基于 WebAssembly 的超轻量级容器,其可以在任何地方运行:从桌面到云、以及 IoT 设备,并且也能嵌入到 任何编程语言 中.
Wasm 以模块的形式组织,模块内部主要包括类型定义、函数、全局变量、内存段、表和导入导出项。我们提供 Runtime 原生模块作为 Wasm 虚拟机和链交互的桥梁,在虚拟机启动时会默认加载该 Runtime 模块,供 Wasm 合约导入和调用。
由于 Wasm 只定义了内存块,没有内置内存分配使用的逻辑,所以要么由 Runtime 提供 malloc、free 等内存分配管理 API,要么由合约自身进行管理。经过细致比较分析,Runtime 管理会限制内存分配算法的升级:
由于 Wasm 自身只支持 u32、u64等简单的类型,对于 Runtime 需要向 Wasm 传递复杂的数据结构时,我们定义了 Abi Codec 对数据结构序列化为字节数组的形式,写入 Wasm 内存,然后由用户合约还原出原数据结构。
如果想要降低软件的成本,一般有两种方法。
(1)加快软件开发速度,缓慢的开发会耗尽公司的资金。
(2)提高软件性能,更好的性能会减少资源消耗。
这两种方法,哪一种能够更有效地降低成本呢?
我们用谷歌的数据来说明。
2020年,谷歌使用了 15.5TW 的电力,其中大部分用于数据中心。如果按照美国加州昂贵的电费(0.199美元/千瓦时)来计算,电费总计30.85亿美元。
同年,谷歌雇佣了27,169名软件工程师。我们就用初级程序员在加州的平均年薪17.8751万美元来计算,人力成本总计48.56亿美元。
由此可见,软件开发的人力成本比电费高得多。
加快软件开发速度,可以节约人力成本,而提高软件性能可以节约电费。因此,针对开发速度进行优化,对降低成本的效果可能更明显。
我的感想:对于业务系统要采用最合适的技术来节约时间
20230706
// 判断页面是否不可见然后发出可靠请求
window.addEventListener('visibilitychange', () => {
if (document.visibilityState == 'hidden') {
fetch(`uurl`, {
method: 'post',
headers: {
'Content-type': 'application/json',
'token': _utils.getUser().token
},
body: _utils.toStringify({
coreStudentId: _this.paperId,
testDate: _this.testDate
}),
keepalive: true //这里很重要否则请求会取消
})
.then(res => {
console.log('success:', res);
})
.catch(err => {
console.error(err);
});
}
})navigator.sendBeacon,不仅是异步的,而且不受同域限制,而且作为浏览器的任务,因此可以保证会把数据发出去,不影响页面卸载。
var observer = new IntersectionObserver(callback,options);IntersectionObserver支持两个参数:
callback是当被监听元素的可见性变化时,触发的回调函数
options是一个配置参数,可选,有默认的属性值
callback
目标元素的可见性变化时,就会调用观察器的回调函数callback。
callback一般会触发两次。一次是目标元素刚刚进入视口(开始可见),另一次是完全离开视口(开始不可见)。
三分钟,教你3种前端埋点方式!https://mp.weixin.qq.com/s/TPyVqsB4HZU1dPgGA0pIhQIntersectionObserver简单介绍及使用IntersectionObserver简单介绍及使用,之前就有关注过,但是一直没有使用,因为当时觉得兼容性不好,但是最近发现浏览器兼容性还可以了,所以用了一把。https://www.haorooms.com/post/intersectionobserver

















 1458
1458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









