







之前的文章集合:
一些可以参考文章集合1_xuejianxinokok的博客-CSDN博客
一些可以参考文章集合2_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合3_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合4_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合5_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合6_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合7_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合8_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合9_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合10_xuejianxinokok的博客-CSDN博客
20230607
即使没有这些商业数据库,用户可以很轻易的安装 PostgreSQL,并使用 PostgreSQL 内置的 pgvector 功能进行向量搜索。

 https://www.infoq.cn/article/GUM31ROwou6XA9P095Ay
https://www.infoq.cn/article/GUM31ROwou6XA9P095Ay向量数据库旨在提供一种原生的,更高效的对 vector embedding 的使用(无论是从存储,或者是查询的角度)。相比于传统的关系型数据库,向量数据库的挑战在于,如何能够存储下成千上亿个 VE,并提供类似于相似度查询,聚类查询等基于 VE 的操作,同时,也需要具备典型数据库的功能。
20230606
采用 select into outfile + load infile 会快一点,但是该方案有个致命问题:该命令在主库会把所有数据当成单个事务执行,只有把数据全部成功插入后,才会将 binlog 复制到从库,这样会造成从库严重延迟,而且生成的单个 binlog 大小严重超标,在磁盘空间不足时可能会把磁盘占满。
技术分享 | MySQL Load Data 的多种用法Load Data 文本导入 定长导入 https://opensource.actionsky.com/20210325-mysql/
https://opensource.actionsky.com/20210325-mysql/

20230605
20230602
 https://www.landui.com/docs-1321
https://www.landui.com/docs-132120230531
 https://www.lmcc.top/articles/73.html
https://www.lmcc.top/articles/73.htmlFTP部署与详解https://mp.weixin.qq.com/s/tH79TDiovvPxKVh0EqzZ7g
20230530

 https://xie.infoq.cn/article/f2bf70796980e99632f5763b0
https://xie.infoq.cn/article/f2bf70796980e99632f5763b020230529
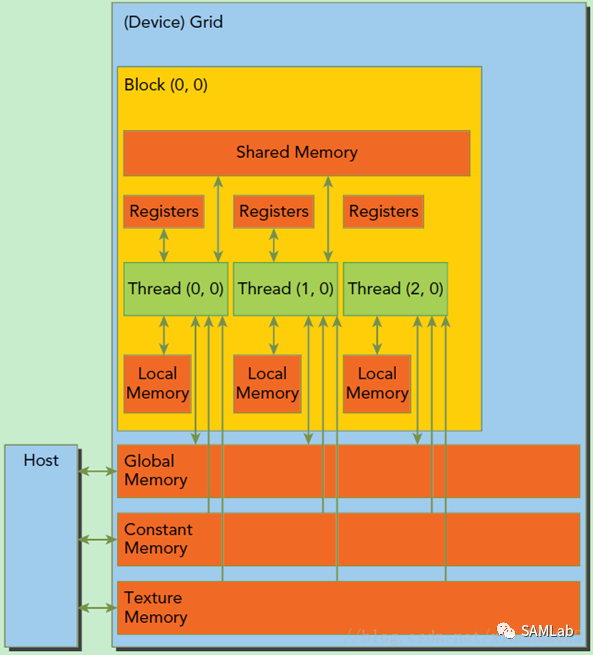
GPU在运行程序时的操作单元是一组线程,这组线程以Grid为单位,同一个Grid上的所有线程共享相同的Global Memory,用于显卡计算过程中与CPU发生的数据交换。由于GPU的操作大多是流操作,一组线程计算同一指令的设计降低了时间局部性对于GPU计算的影响。
一个Grid由多个Block构成,每个Block内包含了多个线程。具体示意图如下:
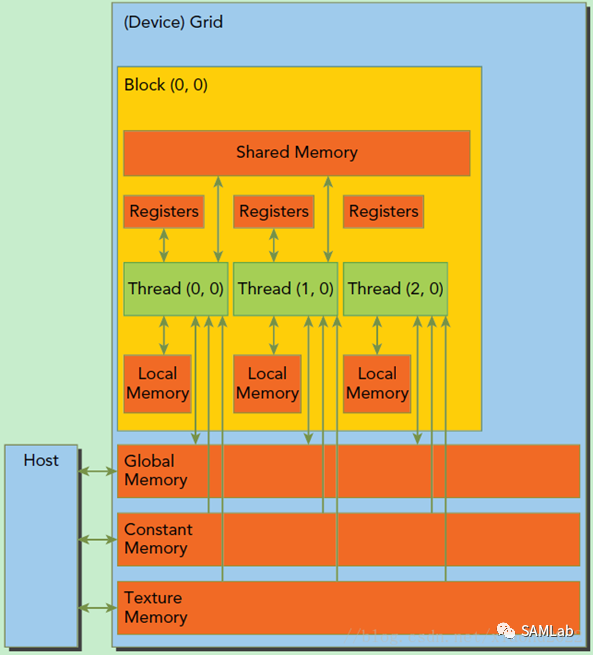
在GPU中,一个Grid将被赋予一个全局内存,允许GPU与CPU进行内存交换。而对于每个Block而言,还具有一个共享内存,允许同一Block的各个线程进行访问和写入。每个Grid还具有只读性质的固定内存和纹理内存,仅在GPU不执行指令时可由CPU导入数据,只读性质的存储能够最大限度地提高GPU的计算效率。
20230522

现在的cpu具有更复杂的cache层次结构,因为它们通常具有每个核心的L2 cache和跨核心共享的额外L3 cache(有时甚至是L4 cache),以便使更多的数据更接近需要的位置,但我们选择了core 2 Duo,因为它的cache 层次结构抓住了多核处理器cache组织的本质。特别是,多核处理器总是具有至少两个级别的cache。
-
最近级别的cache是处理器核心私有的
-
最后一级cache在所有处理器内核之间共享
此外,第一层由两个cache组成,一个专用于指令cache,另一个专用于数据cache,以承认代码和数据之间的使用模式差异,因为从处理器核心的角度来看,代码是只读的,指令流通常遵循特定的访问模式,而数据是读/写的,访问模式在一般情况下可以是任意的。
cache一致性
cache保存了数据在CPU的本地副本,而这些副本在内存中的数据是真正标准的,这引入了cache不一致的问题。例如,如果一个核心正在修改存储在该核心的私有D-Cache中的数据,那么其他核心可能看不到该更新,因为它们会通过自己的cache查看相同的内存位置。另外,如果一个设备修改了内存中的数据,那么这个更新可能不会立即被任何处理器内核看到,因为它们可能正在从层次结构中的一个cache中读取过时的数据。
cpu通过在不同cache和内存总线之间设置cache一致性协议来解决这个问题,该协议使用总线snoop或其他解决方案来检测数据更新并相应地同步/无效cache数据(例如参见MOESI和MESIF协议)。这对于只有相对少量处理内核的CPU来说非常有意义,并且由于编程模型的灵活性,通常认为软件实在具有一致内存系统的假设下工作的,因此必须支持在任意CPU内核/线程上运行的软件之间可以对有效数据进行共享。
在gpu的情况下,内核(计算单元/流多处理器)的数量要大得多,因此实现cache一致性协议在芯片面积和性能方面都过于昂贵。因此,GPU cache通常是不一致的,并且需要显式的刷新和/或cache失效,以便重新聚集(即在GPU内核和/或其他设备之间具有一致的数据视图)。然而,在实践中,由于GPU的特殊编程模型,在不同GPU内核上运行的着色器/内核之间几乎不需要进行高频数据共享,因此这并不是一个问题。比如说:
-
在不同GPU内核上运行的单个绘制或计算调度命令中的着色器调用可能会看到相同内存数据的不一致视图,除非使用一致的资源(见后面),或者在着色器中发出内存屏障,刷新/使每个核心cache无效
-
后续的draw或compute dispatch命令可能会看到相同内存数据的不一致视图,除非通过刷新/使相应cache失效的API发出适当的内存屏障
-
GPU命令和其他设备执行的操作(例如CPU读/写)可能会看到相同内存数据的不一致视图,除非使用适当的同步原语(例如fences或信号量)来同步它们,这将隐式地插入必要的内存屏障
当然,这不是一组正式的规则,而只是对预期内容的粗略总结,单个GPU编程api可能有不同的规则、默认行为和同步手段
单核指令cache
我们将开始探索使用着色器指令cache的GPU的单核cache,因为这是最简单的一个。
虽然GPU的编程模型和硬件实现与CPU有很大不同,但它们所使用的核心构建模块和技术并没有那么不同。例如,流行的GPU架构使用SIMD处理单元,但不是使用它们来启用来自各个线程的向量指令,而是使用SIMT(单指令多线程)执行模型,其中每个通道实际上运行单独的线程(着色器调用)。对于GPU来说,这是一个很好的模型,因为它们通常在一大组工作项目上运行相对简单的程序,因此它们能够一起调度一组线程的指令,而不是单独调度它们。以这种SIMT方式(通常以锁步[lock-step 连锁步伐(队列行进时步伐完全一致)])共同执行的线程组形一个wave(AMD术语中的Wavefront,NVIDIA术语中的Warp,Vulkan术语中的subgroup)。
SIMT 和 SIMD对比
-
SIMD(单指令多数据),是指对多个数据进行同样操作。这种利用了数据级别的并行性,而不是并发性(不是多线程那种);有多个计算,但是只有一个进程在运行。SIMD允许使用单一命令对多个数据值进行操作。这是一种增加CPU的计算能力的便宜的方法。仅需要宽的ALU和较小的控制逻辑。(这里说明他还是一个线程,不是多线程那种操作,仅需要一个核心,只不过一次操作多个数据而已,不是GPU的多个线程那种方法)
-
SIMT(单指令多线程),想象有这样一个多核系统,每一个core有自己的寄存器文件、自己的ALU、自己的data cache,但是没有独立的instruction cache(指令缓存)、没有独立的解码器、没有独立的Program Counter register,命令是从单一的instruction cache同时被广播给多个SIMT core的。即所有的core是各有各的执行单元,数据不同,执行的命令却是相同的。多个线程各有各的处理单元,和SIMD公用一个ALU不同。
此外,与CPU的同步多线程(SMT)特性(例如超线程)类似,GPU也可以在单个内核上运行多个Wave。这使得能够增加流水线中的独立指令的数量,但更重要的是允许GPU在Wave等待来自存储器/cache/等的数据时执行其他Wave的指令。在实践中,单个GPU核心可以有数千个线程在其上运行,尽管大多数线程只是轮流运行。例如
-
AMD GCN计算单元(Cu)可以有40个正在进行的waves,每个wave有64个线程,总计高达2560个线程/Cu
-
NVIDIA Volta流多处理器(SM)可以有64个waves正在进行,每个wave32个线程,总计2048个线程/ SM
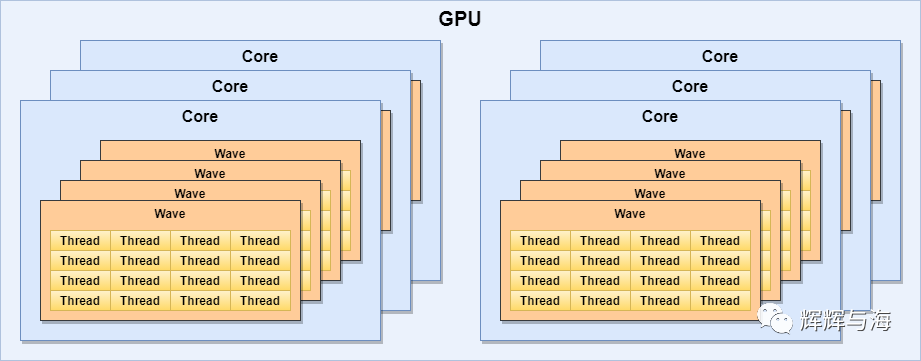
由于各种因素,在任何给定GPU核心上运行的有效线程数在实践中可能要低得多,但讨论其细节超出了本文的范围。
然而,值得注意的是,尽管有大量的线程运行在单个GPU核心上,但它们通常都运行相同的代码。根据SIMT执行模型的定义,对于单个wave的线程,这是正确的。事实上,跨多个GPU内核的wave执行相同的代码是很常见的,因为在典型的GPU工作负载中执行程序的工作项数量甚至大于单个GPU内核所能容纳的数量(例如,在全高清图像上进行全屏处理会导致超过200万次线程调用)。
这意味着即使考虑到在单个GPU核心上运行的大量线程,每个核心的小指令cache也更令人满意。一些GPU甚至在多个GPU内核之间共享指令cache(例如,AMD的GCN架构在多达4个计算单元的集群中共享单个32KB指令cache)。
从性能的角度来看,要记住的一件事是,在gpu上,指令cache丢失可能会导致数千个线程而不是一个线程停滞,就像在cpu的情况下一样,所以通常强烈建议着色器/内核代码足够小,以完全适合这个cache。
-
单核数据cache
每个GPU核心通常有一个或多个专用的着色器数据cache。在早期的GPU设计中,着色器只能从内存中读取数据,而不能写入数据,因为通常着色器只需要访问纹理和缓冲区输入来执行任务,所以每个核心的数据cache传统上是只读的。然而,后来为灵活的GPGPU计算操作而定制的体系结构需要支持对内存的分散写操作,因此出现了对读写数据cache的需求。这些cache通常使用write-through策略,即写入立即传播到下一个cache级别。
-
因此,GPU上的cache数据的重用通常不像CPU的情况那样发生在时域中(即,同一线程的后续指令多次访问同一数据),而是发生在空间域中(即,同一核上的不同线程的指令访问同一数据)。因此,与CPU不同,在GPU上使用内存作为临时存储并依赖cache进行快速重复访问并不是一个好主意。然而,更大的寄存器空间和共享内存的可用性在实践中弥补了这一点。
数据跨线程重用的极端情况是一个或多个wave的所有线程都需要从同一地址读取数据。这很常见,因为着色器/内核经常访问常量数据或其他低频数据(例如,计算着色器中特定于工作组的数据)。为了提高这种访问的性能,许多GPU具有专用的统一数据cache(有时称为标量或常量cache)。具有用于此目的的单独cache的好处是,它确保这样的低频数据不会被高频数据访问从数据cache中逐出,否则,如果它们在共同的替换策略下被存储在相同的cache中,则会发生这种情况。
与代码类似,这种统一的数据通常不仅在单个GPU核心内的Waves之间共享,而且在多个GPU核心的Waves之间共享,因此这是另一种cache,是在多个GPU核心之间共享的良好候选(例如,AMD的GCN架构在多达4个计算单元的集群之间共享单个16KB标量cache)
-
gpu和cpu是为不同类型的任务而构建的。cpu只并行运行几个线程,但每个线程都有大量复杂的代码和数据集,而gpu同时执行的线程数量要大得多,但通常大多数线程共享相同的代码,每个线程访问相对较少的数据。因此,尽管这两种处理器类型使用的实际缓存层次结构非常相似,但在实践中,缓存的实际使用模式却有很大不同。记住这一点对于获得良好的性能至关重要,这也是为什么以cpu为中心的算法在gpu上表现不佳的原因。
CUDA编程学习笔记-02(GPU硬件架构)GPU硬件架构概述~https://mp.weixin.qq.com/s/qakvAfNV4KkmNa3P56i-dQ
20230517
P/Invoke 之 C# 调用动态链接库DLLhttps://mp.weixin.qq.com/s/zf7VsG_t2AaLPbtfj0RldQ
高可用: 体验使用Odyssey连接池(二)https://mp.weixin.qq.com/s/bKiwJ8ftxzQipL1M5ERvQg
20230515
mvcc,Multiversion Concurrency Control,多版本并发控制机制,本身上是一个指导性的概念,本身的指导思想是这样的:与其锁定数据行,不如让写入去写这一行新的版本,而需要读的时候,在新行提交之前(假设隔离级别是Read Commited),直接去读老的行数据,既保证隔离性,也让读写可以不要相互锁定.
每当发生数据写入(delete或者update),InnoDB会做一个操作,就是把老的行做一个删除标记,然后带着当前的事务id插入新行(由于是索引组织表,保证必须在同一个数据块中),这个操作本身,一是会把修改本身写入redo,二是会让这个数据块被记录到undo,而undo表空间的写入,也会生成一个对应的redo,写入到redo,也就是说,每次数据修改,会产生两个redo记录(对于insert来说,由于数据前镜像是空,所以并没有第二个undo对应的redo生成,也就是只产生一个redo记录,需要注意),详细说明可以参考 http://hedengcheng.com/?p=489
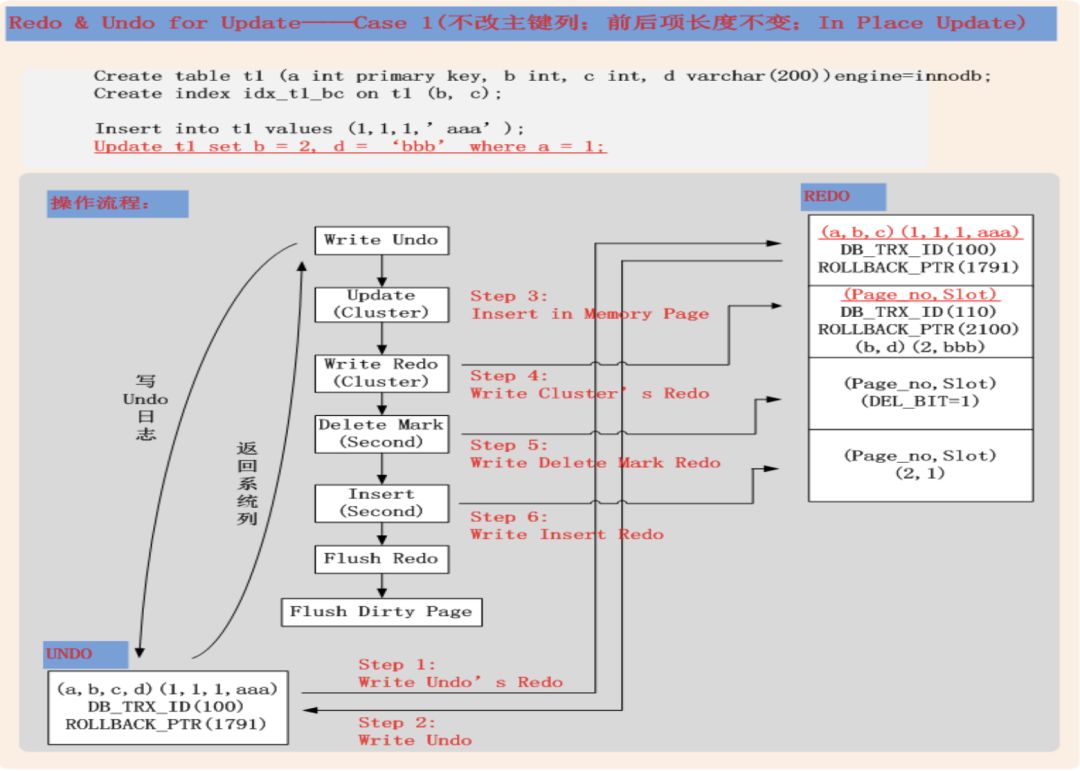
图片来自http://hedengcheng.com
当修改期间,有读行为过来的时候,读的游标,就会直接去读undo中的老数据,而不会去求正在被修改的数据的锁.
而为了实现隔离级别(可重复读级别),事务id的作用在于,如果一个数据块在事务开始后,才被修改并提交了,当游标读取到这里,会扫到当前数据块里面,所有在这期间被修改并提交的行,读取到对应行id小于事务id的数据.
打个比方,一个事务开始之后,sleep了10秒,期间别的三个事务修改并提交了同一行记录,当这个事务在之后读取的时候,会沿着undo一路读取到10秒前的记录.
-------------------------------------------------------
数据库中的事务ID递增。可通过txid_current()函数获取当前事务的ID。
隐藏多版本标记字段
PostgreSQL中,对于每一行数据(称为一个tuple),包含有4个隐藏字段。这四个字段是隐藏的,但可直接访问。
- xmin 在创建(insert)记录(tuple)时,记录此值为插入tuple的事务ID
- xmax 默认值为0.在删除tuple时,记录此值(即若tuple被删除,则xmax被设置为删除tuple的事务的ID).即 未被删除时xmax为0
- cmin和cmax 标识在同一个事务中多个语句命令的序列值,从0开始,用于同一个事务中实现版本可见性判断。(即在上一个语句的基础上加1)
因为PostgreSQL的更新操作并非真正更新数据,而是将旧数据标记为删除,并插入新数据,所以“更新的事务ID”也就是“创建记录的事务ID”。
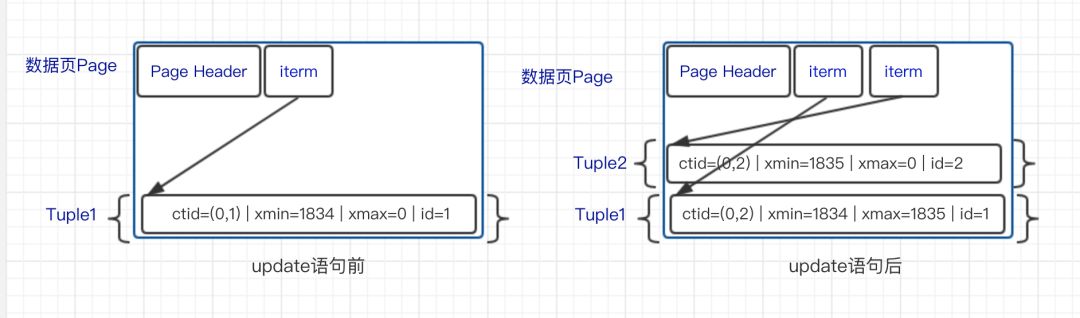
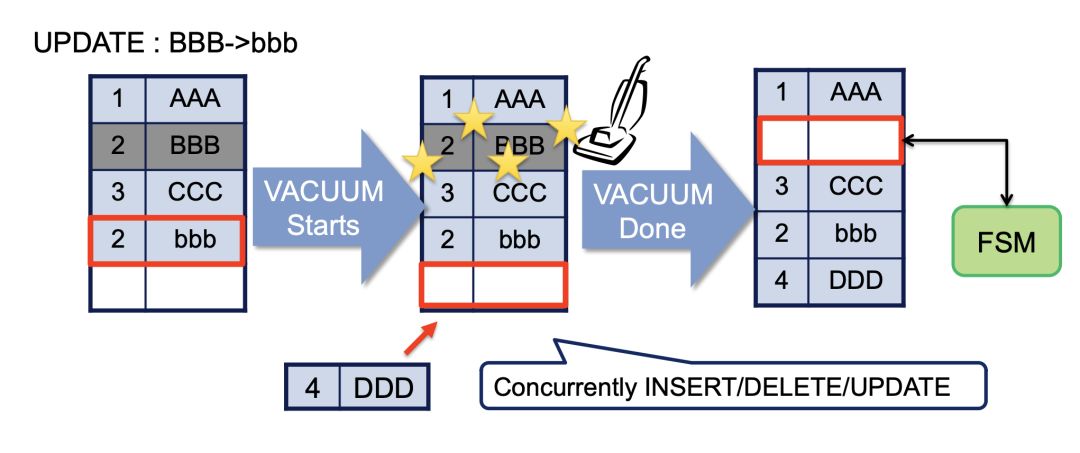

事实证明,当一行已被 MultiXact ID 锁定时,该 ID 不会被同步删除;即使所有锁定事务都已完成,ID 仍然存在,并且未来的事务必须查询 MultiXact 存储以确定锁定是否已过期。因此,随着我们的应用程序在越来越多的行上累积这些 MultiXact 锁,随着时间的推移,越来越多的事务将不得不引用 MultiXact 存储,并且会争夺上述锁。
这些 ID 由 Postgres 的 VACUUM 进程定期清理; Postgres VACUUM 文档很好地解释了它在清理 MultiXact ID 方面的作用。
postgres=# create extension pageinspect;
CREATE EXTENSION
postgres=# create table test(i int);
CREATE TABLE
postgres=# insert into test (i) values (1);
INSERT 0 1
postgres=# select lp, t_xmin, t_xmax, t_ctid, t_infomask, (t_infomask&4096)!=0 as is_multixact from heap_page_items(get_raw_page('test', 0));
lp | t_xmin | t_xmax | t_ctid | t_infomask | is_multixact
----+--------+--------+--------+------------+--------------
1 | 488 | 0 | (0,1) | 2048 | f
(1 row)
postgres=# begin;
BEGIN
postgres=*# select * from test where i = 1 for update;
i
---
1
(1 row)
postgres=*# savepoint a;
SAVEPOINT
postgres=*# update test set i = i+1 where i = 1;
UPDATE 1
postgres=*# commit;
COMMIT
postgres=# select lp, t_xmin, t_xmax, t_ctid, t_infomask, (t_infomask&4096)!=0 as is_multixact from heap_page_items(get_raw_page('test', 0));
lp | t_xmin | t_xmax | t_ctid | t_infomask | is_multixact
----+--------+--------+--------+------------+--------------
1 | 488 | 1 | (0,2) | 4416 | t
2 | 490 | 489 | (0,2) | 8336 | f
(2 rows)heap_page_items(get_raw_page(…)) 让我们检查 postgres 表中物理页中的实际磁盘元组。我不会在这里解释所有字段,但我会注意到 t_infomask 中的位 0x1000 (4096) 记录行是否具有 MultiXact ID ,这让我们可以选择 (t_infomask&4096)!=0 as is_multixact 来确定哪些行已被锁定MultiXact ID。我们还可以看到 MultiXact 锁定行上的 t_xmax 比其他 t_xmin 和 t_xmax 值小得多,因为它来自 MultiXact 命名空间,而不是普通的 XID 命名空间
@RabbitListener(queues = RabbitConfig.JAVABOY_QUEUE_NAME,concurrency = "10")
public void handleMsg(String msg) {
logger.info("msg:{}", msg);
}concurrency = "10" 相当于建立了 10 个 channel 去同时消费消息
20230508
CPU基本上是实时响应,采用多级缓存来保障多个任务的响应速度。
GPU往往采用的是批处理的机制,即:任务先排好队,挨个处理。
RTX3090的流式多处理器有10496个,每个内核都有具备整数运算和浮点运算的部分,还有用于在操作数中排队和收集结果的部分。
所谓流式多处理器可以认为是一个独立的任务处理单元,也可以认为一颗GPU包含了10496个CPU同时处理各个图片处理任务。
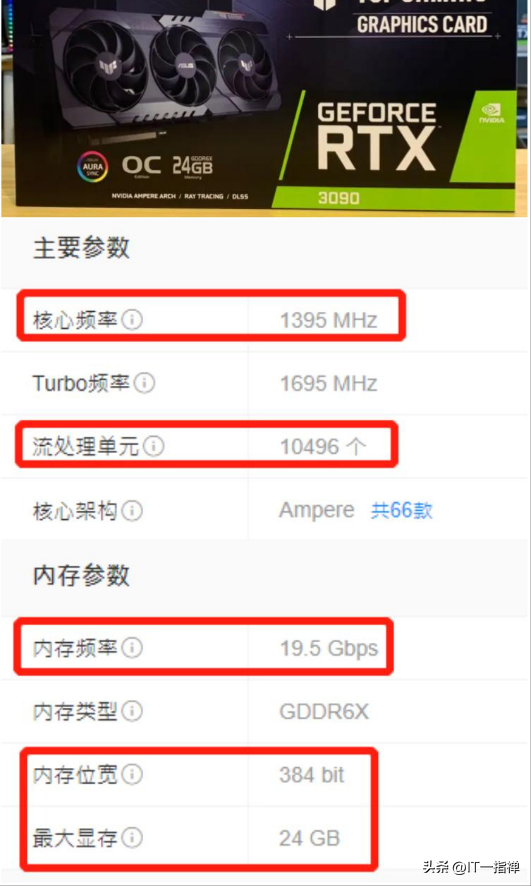
我们就可以通过算法和程序,对1秒钟18662400个像素点的整体任务进行切割分片,让10496颗处理器并行计算。
这样的话,每个处理器负责大概每秒处理18662400/10496,即1778个像素点的渲染任务就行了。
如下图所示,在GPU中会划分为多个流式处理区,每个处理区包含数百个内核,每个内核相当于一颗简化版的CPU,具备整数运算和浮点运算的功能,以及排队和结果收集功能。

一文搞懂GPU的概念、工作原理,以及与CPU的区别一文搞懂GPU的概念、工作原理,以及与CPU的区别https://mp.weixin.qq.com/s/PZWMMJN16-pKN6FJQGKZfA
PostgreSQL、Greenplum 《如来神掌》 - 目录 - 珍藏级
 https://github.com/digoal/blog/blob/master/201706/20170601_02.md
https://github.com/digoal/blog/blob/master/201706/20170601_02.mdPostgreSQL DBA最常用SQL
PostgreSQL 最常用的插件
20230507
PostgreSQL开发技术基础:过程与函数PostgreSQL开发技术基础:过程与函数.https://mp.weixin.qq.com/s/d1gyKFbqMhjN0Mx8snrQ1g
20230506
20230428
2023 Web Components 现状 | Silas's Blog https://blog.5bang.top/2023/04/21/2023_state_of_web_component
https://blog.5bang.top/2023/04/21/2023_state_of_web_component
20230427
图解MySQL | MySQL insert 语句的磁盘写入之旅MySQLhttps://opensource.actionsky.com/20200409-mysql/
20230423
-- 查询死元组占用比
select relname, n_dead_tup as "deads",
(
case when n_live_tup > 0 then n_dead_tup::float8/n_live_tup::float8
else 0 end
) as "dead/live_percent"
from pg_stat_all_tables where n_dead_tup>0 and schemaname='public';
SELECT
table_schema || '.' || table_name AS table_full_name,
pg_size_pretty(pg_total_relation_size('"' || table_schema || '"."' || table_name || '"')) AS size,
(case when n_live_tup > 0 then
round(100*n_dead_tup::numeric(19)/n_live_tup,2)
else 0 end) as dead_percent,
last_autovacuum, last_vacuum, n_dead_tup, n_live_tup, n_tup_ins, n_tup_upd, n_tup_del, vacuum_count, autovacuum_count
FROM information_schema.tables, pg_stat_all_tables stat
WHERE table_schema = 'public' and stat.schemaname = table_schema and stat.relname = table_name and stat.n_dead_tup>0
ORDER BY
dead_percent, pg_total_relation_size('"' || table_schema || '"."' || table_name || '"') desc
limit 100;
-[ RECORD 1 ]----+----------
table_full_name | public.t1
size | 4352 kB
dead_percent | 900.00
last_autovacuum |
last_vacuum |
n_dead_tup | 90000
n_live_tup | 10000
n_tup_ins | 100000
n_tup_upd | 0
n_tup_del | 90000
vacuum_count | 0
autovacuum_count | 0pg_controldata -D $PGDATApg_control version number: 1300Catalog version number: 202107181Database system identifier: 7138432685960386315Database cluster state: in production
PostgreSQL中控制文件的解析与恢复最近遇到有人问起PG中控制文件的一些使用问题,总结了一下。简略介绍PG中控制文件的使用。https://mp.weixin.qq.com/s/Mw1YqmZ9vayxocNF3TGDkg入门ETCD——基础简介本文为入门etcd系列文章第一篇,主要是对etcd有一个简单的介绍包括etcd的用途、应用场景、特点等方面做介绍,以及etcd的架构图,核心概念术语等。
https://mp.weixin.qq.com/s/CrLtekDLOUzNWYSLx7jxrAC语言实现面向对象三大特性 : 封装、继承、多态不知道有多少人去了解过语言的发展史,早期C语言的语法功能其实比较简单。随着应用需求和场景的变化,C语言的语法
https://mp.weixin.qq.com/s/TDOgLYTG6VHob7ygsLB5ZA入门ETCD——常用命令本文主要总结了etcd常用的管理命令,包括集群管理命令、数据库操作命令、监听命令、租约命令、备份恢复命令、用户管理命令
https://mp.weixin.qq.com/s/lHxvsdL4mBbH4SRIPPEiGg用 C 语言实现有限状态机 FSM--基于表驱动实用!非常实用!!!在传统的控制逻辑中,我们常常使用 if、else if、else 或者 switch case 进行判断处理,但是当业务需求逻辑复杂了,使用这种方式实现往往会变得很复杂,且写出的代码不易维护。
https://mp.weixin.qq.com/s/SOA2R9jenV-qFcAF1Tif8g轻松拿下PostgreSQL,这30个实用SQL语句你细品你品,你细品!
https://mp.weixin.qq.com/s/THJxedvvyC_eQenCCw2nJg
20230422
oracle
nohup docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/oracle23cfree:1.0 &
nohup docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/oracle21c_ee_db_21.3.0.0 &
nohup docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/oracle19clhr_asm_db_12.2.0.3:2.0 &
nohup docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/oracle18clhr_rpm_db_12.2.0.2:2.0 &
nohup docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/oracle_12cr2_ee_lhr_12.2.0.1:2.0 &
nohup docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/oracle_12cr1_ee_lhr_12.1.0.2:2.0 &
nohup docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/oracle_11g_ee_lhr_11.2.0.4:2.0 &
nohup docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/oracle_11g_ee_lhr_11.2.0.3:2.0 &
nohup docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/oracle_10g_ee_lhr_10.2.0.5:2.0 &
nohup docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/oracle_10g_ee_lhr_10.2.0.1:2.0 &
# 23c免费开发者版本
docker run -itd --name lhroracle23c -h lhroel87 \
-p 1530:1521 -p 38389:3389 \
-v /sys/fs/cgroup:/sys/fs/cgroup \
--privileged=true lhrbest/oracle23cfree:1.0 \
/usr/sbin/init
docker exec -it lhroel87 bash
# 21c 二进制安装
docker run -d --name lhroracle21c -h lhroracle21c \
-p 5510:5500 -p 55100:5501 -p 1530:1521 -p 3400:3389 \
-v /sys/fs/cgroup:/sys/fs/cgroup \
--privileged=true lhrbest/oracle21c_ee_db_21.3.0.0 \
/usr/sbin/init
# 19c ASM
docker run -itd -h lhr2019ocpasm --name lhr2019ocpasm \
-p 1555:1521 -p 5555:5500 -p 55550:5501 -p 555:22 -p 3400:3389 \
--privileged=true \
lhrbest/oracle19clhr_asm_db_12.2.0.3:2.0 init
# 对于ASM,① ASM磁盘脚本:/etc/initASMDISK.sh,请确保脚本/etc/initASMDISK.sh中的内容都可以正常执行
# ② 需要在宿主机上安装以下软件
yum install -y kmod-oracleasm
wget https://yum.oracle.com/repo/OracleLinux/OL7/latest/x86_64/getPackage/oracleasm-support-2.1.11-2.el7.x86_64.rpm
wget https://download.oracle.com/otn_software/asmlib/oracleasmlib-2.0.12-1.el7.x86_64.rpm
rpm -ivh *.rpm
systemctl enable oracleasm.service
oracleasm init
oracleasm status
# 19c rpm方式安装
docker run -itd -h lhrora19c --name lhrora19c \
-p 1529:1521 -p 5509:5500 -p 55090:5501 -p 229:22 -p 3399:3389 \
--privileged=true \
lhrbest/oracle19clhr_rpm_db_12.2.0.3:2.0 init
# 18c rpm方式安装
docker run -itd -h lhrora18c --name lhrora18c \
-p 1528:1521 -p 5508:5500 -p 55080:5501 -p 228:22 -p 3398:3389 \
--privileged=true \
lhrbest/oracle18clhr_rpm_db_12.2.0.2:2.0 init
# 12.2.0.1 二进制安装
docker run -itd --name lhrora1221 -h lhrora1221 \
-p 1526:1521 -p 5526:5500 -p 55260:5501 -p 226:22 -p 3396:3389 \
--privileged=true \
lhrbest/oracle_12cr2_ee_lhr_12.2.0.1:2.0 init
# 12.1.0.2 二进制安装
docker run -itd --name lhrora1212 -h lhrora1212 \
-p 1525:1521 -p 5525:5500 -p 55250:5501 -p 225:22 -p 3395:3389 \
--privileged=true \
lhrbest/oracle_12cr1_ee_lhr_12.1.0.2:2.0 init
# 11.2.0.4 二进制安装
docker run -itd --name lhrora11204 -h lhrora11204 -p 3394:3389 \
-p 1524:1521 -p 1124:1158 -p 224:22 \
--privileged=true \
lhrbest/oracle_11g_ee_lhr_11.2.0.4:2.0 init
# 11.2.0.3 二进制安装
docker run -itd --name lhrora11203 -h lhrora11203 -p 3393:3389 \
-p 1523:1521 -p 1123:1158 -p 223:22 \
--privileged=true \
lhrbest/oracle_11g_ee_lhr_11.2.0.3:2.0 init
# 10.2.0.5 二进制安装,-h参数不能变
docker run -itd --name lhrora10205 -h lhrora10g -p 3380:3389 \
-p 1512:1521 -p 212:22 \
--privileged=true \
lhrbest/oracle_10g_ee_lhr_10.2.0.5:2.0 init
# 10.2.0.1 二进制安装,-h参数不能变
docker run -itd --name lhrora10201 -h lhrora10g -p 3379:3389 \
-p 1511:1521 -p 211:22 \
--privileged=true \
lhrbest/oracle_10g_ee_lhr_10.2.0.1:2.0 init 20230421
 https://sspai.com/post/63088
https://sspai.com/post/6308820230412
20230410
小心使用UUID, PostgreSQL中的UUID的弊端及解决方案小心使用UUID, PostgreSQL中的UUID的弊端及解决方案, 可以考虑NanoID相关方案https://mp.weixin.qq.com/s/HrodlNtKzignuVbDrslDTA
pageinspect
内置插件。大家可以自行安装:(create extension pageinspect)
 https://www.infoq.com/news/2023/04/virtual-threads-arrives-jdk21/
https://www.infoq.com/news/2023/04/virtual-threads-arrives-jdk21/20230405
解决windows10,11 磁盘和cpu飙高卡顿的问题
关闭如下服务,亲测有效
SysMain
Diagnostic Execution Service
Diagnostic Policy Service
Diagnostic Service Host
Diagnostic System Host
Windows Search



20230330

20230329
什么是 MinGW
- MinGw全称 Minimalistic GNU for Windows,某种程度上可以看做是win版本下的GCC。Mingw有一个Msys的子项目,可以提供一些模拟Linux的shell和基本的Linux工具,Msys是一个辅助环境。
- MinGw 有专门的Win32 API的头文件,来把代码中Linux方式的系统调用替换为对应的Windows下的调用方式,某种程度上可以称之为将Linux调用 翻译为 Windows调用。
3. 什么是 cygwin
- Cygwin 则是一个在Windows平台上运行的unix模拟环境,是cygnus solutions 公司开发的自由软件。Cygwin更像一个平台,模拟了Linux的接口,提供了运行在它上面的程序使用,提供了很多Linux环境下的GNU软件。
- Cygwin 通过Cygwin1.dll的文件实现操作系统API的转换,模拟了Linux的调用接口给程序,程序以Linux的方式调用系统API,但这个API的目标库是Cygwin1.dll,Cygwin1.dll再调用Windows对用的方式实现,再把结果返回给程序。
4. 两者的区别
- MinGW生成的程序,究其本质调用的是Kernel.32导出的标准Windows系统API,在windows下Mingw的编译性能会高一些,编译速度也会快一些。
- Cygwin更像一个平台,它相对完整地模拟了LInux,提供了一个接近2M的Cygwin1.dll的文件作为目标库,来模拟Linux系统的接口,但是相对来说编译的速度就要慢一些。如果想要在Windows上开发可以运行在LInux上的程序,应该选用Cygwin。
- 总的来说:
- cygwin大,mingw小
- cygwin编译后的exe需要cygwin1.dll作为支持,而mingw不需要就可以直接运行,因为有中间层所以cygwin慢,mingw快。
- cygwin包含的内容更全面,能编译通过的linux源文件更多,mingw的min是minimalist所以能编译通过的更少。但,不是全部,就是说别指望你可以把任何为linux写的源代码在cygwin或mingw编译通过并运行。
基于执行速度还有大小的原因,我倾向于在Windows下选择使用MinGW64.
https://www.cnblogs.com/zoe-mine/p/7056369.html![]() https://www.cnblogs.com/zoe-mine/p/7056369.html
https://www.cnblogs.com/zoe-mine/p/7056369.html
20230328
ALTER TABLE <target table> SET UNLOGGED
<bulk data insert operations…>
ALTER TABLE <target table> LOGGED
20230327
MERGE 命令
PostgreSQL 社区多年来一直致力于 MERGE 功能,PostgreSQL 15 引入了这个命令,它可以处理 INSERT、UPDATE 和 DELETE 操作——所有这些都在一个事务中。
下面的示例将从目标表中插入、更新或删除,具体取决于表是否匹配以及是否满足指定条件。
MERGE INTO TargetProducts Target
USING SourceProducts Source
ON Source.ProductID = Target.ProductID
WHEN NOT MATCHED AND Source.ProductId IS NOT NULL THEN
INSERT VALUES (Source.ProductID, Source.ProductName, Source.Price)
WHEN MATCHED AND Target.ProductName IN ('Table', 'Desk') THEN
UPDATE SET ProductName = Source.ProductName, Price = Source.Price
WHEN MATCHED THEN
DELETE;如果没有 MERGE,上面的示例将需要具有各种 if-else 条件的 PL 过程或 PL SQL 函数,这也将花费更多的时间来执行。
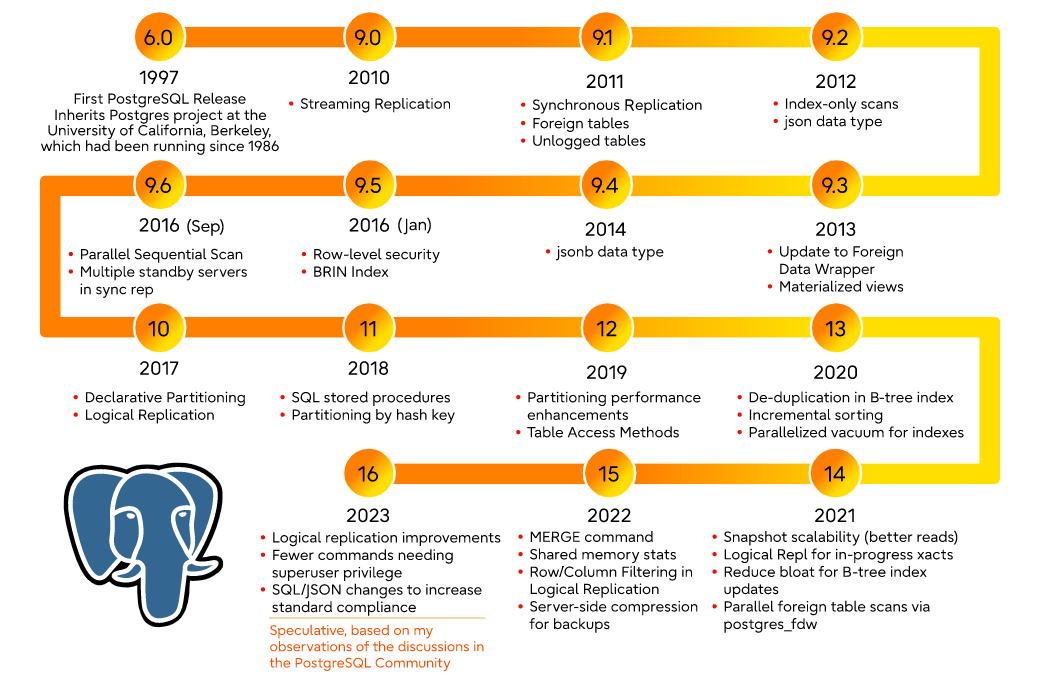
PGSQL每年一个大版本发布,大版本发布的第二年就可以上生产环境,版本迭代速度很快
次要版本永远不会更改内部存储格式,并且始终与相同主要版本号的早期和后期次要版本兼容。例如,10.1 版与 10.0 版和 10.6 版兼容。同样,例如,9.5.3 与 9.5.0、9.5.1 和 9.5.6 兼容。要在兼容版本之间进行更新,您只需在服务器关闭时替换可执行文件并重新启动服务器。数据目录保持不变——小升级就是这么简单。
对于PostgreSQL的主要版本,内部数据存储格式可能会发生变化,从而使升级变得复杂。将数据移动到新的主要版本的传统方法是转储并重新加载数据库,尽管这可能会很慢。更快的方法是pg_upgrade。复制方法也可用,如下所述。(如果您使用的是PostgreSQL的预打包版本,它可能会提供脚本来帮助进行主要版本升级。有关详细信息,请参阅包级文档。)
新的主要版本通常还会引入一些用户可见的不兼容性,因此可能需要更改应用程序编程。所有用户可见的更改都列在发行说明中;请特别注意标有“迁移”的部分。尽管您可以从一个主要版本升级到另一个版本而无需升级到中间版本,但您应该阅读所有中间版本的主要发行说明。
pg_upgrade模块允许将安装从一个主要的PostgreSQL版本就地迁移到另一个。升级可以在几分钟内完成,特别是在模式下。它需要类似于上面的pg_dumpall的步骤,例如,启动/停止服务器,运行initdb。pg_upgrade文档概述了必要的步骤。
先检查一遍新旧数据库是否存在不兼容情况,若兼容则会全部显示ok如下图,如果有异常,会报错,执行脚本:
/usr/pgsql-14/bin/pg_upgrade --old-datadir /var/lib/pgsql/11/data/ --new-datadir /usr/pgsql-14/data/ --old-bindir /usr/pgsql-11/bin/ --new-bindir /usr/pgsql-14/bin/ --check
全部ok可执行升级:
/usr/pgsql-14/bin/pg_upgrade --old-datadir /var/lib/pgsql/11/data/ --new-datadir /usr/pgsql-14/data/ --old-bindir /usr/pgsql-11/bin/ --new-bindir /usr/pgsql-14/bin/
mysql innodb的基于回滚段实现的MVCC机制,相对PG新老数据一起存放的基于XID的MVCC机制,是占优的。新老数据一起存放,需要定时触发VACUUM,会带来多余的IO和数据库对象加锁开销,引起数据库整体的并发能力下降。而且VACUUM清理不及时,还可能会引发数据膨胀
 https://www.modb.pro/db/609411
https://www.modb.pro/db/609411 https://www.cnblogs.com/kuang17/p/13164266.html![]() https://www.cnblogs.com/kuang17/p/13164266.html
https://www.cnblogs.com/kuang17/p/13164266.html
20230324
wal_level决定多少信息写入到 WAL 中。默认值是replica,它会写入足够的数据以支持WAL归档和复制,包括在后备服务器上运行只读查询。minimal会去掉除从崩溃或者立即关机中进行恢复所需的信息之外的所有记录。最后,logical`会增加支持逻辑解码所需的信息。每个层次包括所有更低层次记录的信息。这个参数只能在服务器启动时设置。
在minimal级别中,某些批量操作的 WAL 日志可以被安全地跳过,这可以使那些操作更快(见populate-pitr)。这种优化可以应用的操作包括:
- CREATE TABLE AS
- CREATE INDEX
- CLUSTER
- COPY到在同一个事务中被创建或截断的表中
但最少的 WAL 不会包括足够的信息来从基础备份和 WAL 日志中重建数据,因此,要启用 WAL 归档(archive_mode)和流复制,必须使用replica或更高级别。
在logical层,与replica相同的信息会被记录,外加上 允许从 WAL 抽取逻辑修改集所需的信息。使用级别 logical将增加 WAL 容量,特别是如果为了REPLICA IDENTITY FULL配置了很多表并且执行了很多UPDATE和DELETE 语句时。
在 9.6 之前的版本中,这个参数也允许值archive和hot_standby。现在仍然接受这些值,但是它们会被映射到replica。
WAL保存了对数据库的操作记录,保证了PostgreSQL的事务持久性和和原子性,同时避免了频繁的io对数据库性能的影响。
事务的基本性质是:ACID, WAL 日志保证了 原子性A 和 持久性 D,并发C和隔离I需要锁和MVCC来保证
WAL机制的核心理念是,对数据文件的操作,例如表和索引,都应该先将操作日志写入磁盘中的WAL日志文件,而Data Buffer中的脏页延迟至checkpoint发生时候才刷新到磁盘中的数据文件,这样做的原因:
(1) 刷新数据页涉及大量的随机io,即刷新脏页需对硬盘中的多个分散的数据块进行写操作,这里会涉及硬盘磁头的寻道操作,非常耗时;相比之下刷新WAL是把记录追加到WAL文件上,属于连续写的,效率要高得多。 (2) 日志先被持久化,即使数据库发生宕机,即使Data Buffer存在未刷新到数据文件的数据页,当数据库重新启动后,那些未刷新的数据页上的变动可以根据WAL日志重做,保证数据的完整性。
流复制是指主库把WAL的记录传输到备库,备库再回放record,从而保证了与主库的数据一致性。流复制过程如下图所示:

(1) 发生DML时,WAL记录先被写入内存的WAL Buffer中。
(2) 提交事务时,WAL Buffer相关的WAL记录被刷新到硬盘的WAL日志文件中。
(3) 主库会启动一个WAL Sender进程负责把刚刚刷新到硬盘的WAL记录传输到备库。
(4) WAL Sender进程把WAL记录发送给备库的WAL Receiver。
(5) WAL Receiver接收到WAL记录后会通知WAL Writer进程。
(6) WAL Writer负责把WAL Receiver接收到的WAL记录写入硬盘的WAL日志文件。
(7) 备库接收WAL记录后,重播日志,并把数据写入硬盘的数据文件。
经过上面的步骤,从库跟备库实现了数据一致性。
3.2 逻辑复制(logical replication)
流复制的对象是数据库实例,适用于复制一个与主库实例一模一样的从库的场景。
当需要把同步的粒度细化到表级别,就需要使用逻辑流复制。Debezium的PostgreSQL Connector就是基于逻辑复制实现的。
两者还有以下区别:
流复制可以同步DDL操作,但逻辑复制不可以。
逻辑复制需要编码器,例如pgoutput,把WAL解释成其他应用可以理解的格式,如在上一篇文章做的实验,Debezium收到的记录里面除了当前的数据外,还包含了修改前的数据。pgoutput是PostgreSQL自带的编码器。
流复制要求数据库版本必须一致,而逻辑复制没有这个要求。
流复制更适用于主备模式,主库可读可写,备库则可读但不可写。逻辑复制的发布节点和订阅节点皆为可读可写。
20230321
HanLP | 在线演示HanLP的在线交互式演示,为生产环境带来次世代最先进的多语种自然语言处理技术。![]() https://hanlp.hankcs.com/
https://hanlp.hankcs.com/















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









