







 文章详细介绍了使用VBA进行文件处理的步骤,包括确定读取的内容、文件路径、目标位置以及读取方法。讨论了Dir函数在遍历文件名中的应用,并对比了Input和LineInput命令在读取文件内容时的区别,特别是对于分行和不分行文件的处理。此外,还涉及到文本流对象和处理多层文件夹的方法。
文章详细介绍了使用VBA进行文件处理的步骤,包括确定读取的内容、文件路径、目标位置以及读取方法。讨论了Dir函数在遍历文件名中的应用,并对比了Input和LineInput命令在读取文件内容时的区别,特别是对于分行和不分行文件的处理。此外,还涉及到文本流对象和处理多层文件夹的方法。
0 分析问题
0.1 解决问题前,需要先分析问题
我本来是翻看我自己之前总结的一些文件处理笔记,也搜了下别人的,发现问题很多
- 网上各种例子,也都是为了解决某一个问题/ 一类问题 的特定方案,普适性不强
- 自己以前就是想到哪,写到哪儿,解决的都是当时的问题,没有思考其他的可能性
- 自己以前写的挺乱,需要整理
- 目的改进后,想从问题出发,分析好问题,明确每个分支的问题的解决办法,尽量给自己以后遇到同类问题,都可以有启发,甚至可以直接用
- 同时,如果能方便到其他同学,那更好
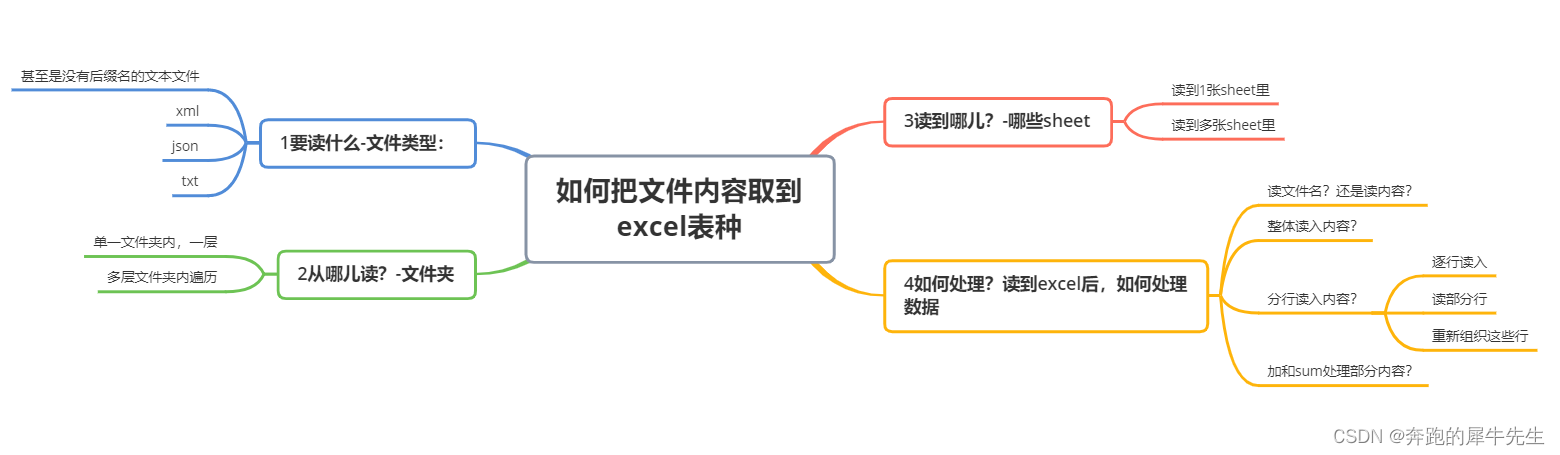
0.2 所以,我决定还是需要先坐下来梳理下问题
下面这些问题,看着很蠢,实际上非常重要
- 首先,你要读什么?
- 从哪儿读,文件在 windows里是存在硬盘上的,是存在不同文件夹内的
- 读到哪儿?读入到1个sheet 还是多个sheet?
- 怎么读? 整体读入?还是分行读?
0.2.1 第1步--你要读什么?
- EXCEL 是处理数据的,VBA一般是辅助EXCEL的,所以我们一般写VBA目的也是处理数据文件
- 不同的数据文件格式
- txt
- json
- xml
- 等等
- 甚至没有后缀名的数据文件,vba 可以读到就无所谓其后缀名
我发现只要是文本文件,无论是.txt .xml .json 甚至没有后缀名可以用写字板等打开的文件,VBA识别起来都很轻松。
附:文本文件格式知识
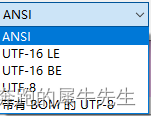
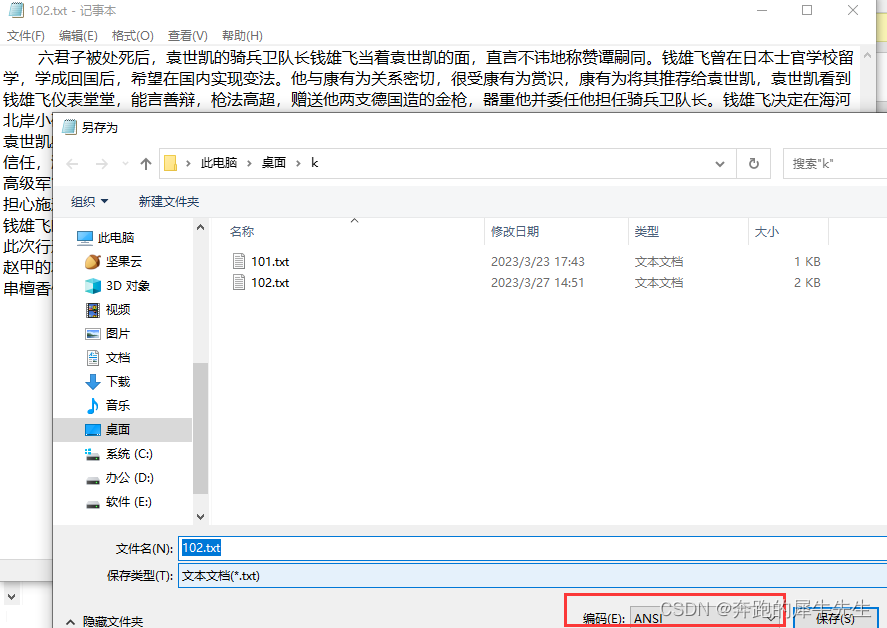
- 很多文本文件内容,可以读到,但是显示乱码
- 需要把文件,另存为,ansi--也就是asci码的方式才可以正常显示!
- 如果默认的是utf-8, 必须先修改,另存为重新保存下
0.2.2 第2步--从哪儿读? 也就是文件在哪儿
文件在哪儿?
- windows的文件夹路径 / 文件路径,path的路径要设定正确,并且最好写成可配置的而不是写死路径,方便不同的本地环境使用。否则换个电脑就很容易报错。
- 存在哪个文件夹内
- 是从单一文件夹内
- 还是从多层文件夹和子文件夹内读? 这个难度要高,需要遍历多层子文件夹
0.2.3 第3步--读到哪儿?
读到哪儿?肯定是读到excel里,但这绝对不是一个蠢问题
- 但是是读到一个sheet表
- 还是读到多个sheet表
- 处理很不相同
0.2.4 第4步--读到后怎么处理?
- 原数据是怎样的?
- 是分行的
- 还是没分行的
- 涉及后续的处理步骤不同,分行符用的什么?等等问题
- 要读入后怎么处理?
- 整体读入
- 分行读入
- 特殊处理,求和等等,分行处理等等
1 第1步,如何从文件夹里取到文件名字
1.1 代码例子和运行结果
- 下面代码
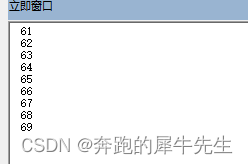
- 是从1个 绝对路径文件夹内,取所有一层内的文件名
- 注意:测试 while 循环内的 fn=dir 修改为 fn=dir(fn) 时,因为会重复定位为第1个文件,会造成无限循环!
Sub merge2()
fp = "C:\Users\Administrator\Desktop\k\*.*"
fn = Dir(fp)
Do While fn <> ""
Debug.Print fn
'fn=dir 达到了显示下一个dir里下一个文件名的效果
fn = Dir '第1次后就可以不带参数乐,就可以直接输入 dir显示目录里的后面的文件名
' fn = Dir(fp) ' 如果这么些,会重新查询dir,且输出dir里的第1个文件的文件名,会造成无限循环!
Loop
End Sub
1.2 dir() 函数
1.2.1 基础语法
- Dir(pathname,attributes)
- path 路径,且是绝对路径
- attributes,属性,可以缺省。但是好像填了属性,必须填路径
- 详细的我没查,需要的时候再查
1.2.2 dir() 函数特点
- 在一段代码内部
- 第1次使用,必须指定路径,得到的是目录中的第1个文件名
- 第2次使用,可以指定路径,如果指定路径,得到的还是目录中的第1个文件名
- 第2次使用,可以不指定路径,如果写成dir(),得到的还是目录中的第2个文件名,从而实现了dir() 逐个获得目录下每个文件名的效果
1.3 试验代码
- 这段代码,故意测试了几种不同的写法
- 可以看出 dir() dir(fp) 的差别
Sub merge21()
fp = "C:\Users\Administrator\Desktop\k\*.*"
fn = Dir(fp)
fn1 = Dir(fp)
fn2 = Dir(fp)
For i = 1 To 3 Step 1
Debug.Print "fn2=" & fn2,
Debug.Print "fn1=" & fn1,
Debug.Print "fn=" & fn,
Debug.Print
fn = Dir
fn2 = Dir(fp)
Next
End Sub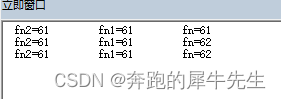
1.4 遍历dir下所有文件名的小套路,判断文件名不为空即可一直遍历
- fn 这里即代表 具体的文件名
Do While fn <> "" fn = Dir Loop
3 如何从文件夹内遍历取出多个子文件夹内的所有文件,这个还没搞--暂缺
因为理论上是无限的
所以这个需要写一个 while 循环遍历文件才可以
4 取某一个文件里的内容
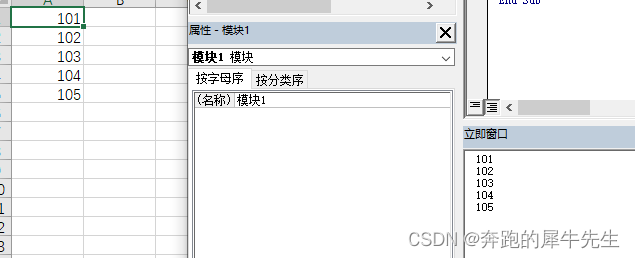
4.1 整体取出到excel
- 读取文件内容
- 本身用 line input 是想逐行读入
- 文件本身是分行的,就会分行读入
- 如果文件内容没有分行,这里就会把全部内容读成1行(根据需要可能需要分行)
Sub merge3()
Dim path1
path1 = "C:\Users\Administrator\Desktop\k\"
k = 1
Open path1 & "101.txt" For Input As #1 '我手动专门增加了一个101的txt文件,分行的数据
Do While Not EOF(1)
Line Input #1, str1
Sheets("a").Cells(k, 1) = str1 '本身就分行的数据,和整体需要再分割分行的数据
Debug.Print str1
k = k + 1
Loop
Close #1
'如果1行,如果多行,处理方法不同?
End Sub
4.2 文本流 ----textstream对象
- 先需要理解textstream对象这个概念
什么是textstream对象?
- textstream对象,包括各种对象,不仅是文件,甚至可以是网页等等
- 是 stream 是流,就是有序的,理解为一条直线也没问题
- 比如 abcd#$%abcd#$%abcd#$%abcd#$%abcd#$%abcd#$%
- 我是这么理解的,对于内容文件,就是把内容,按水流那样按顺序展示出来,或按顺序进行处理,甚至可以理解为 字符串流。
- 为啥可以理解为字符串流,这些内容一般就是字符串嘛
为啥要了解textsteam对象?
- 也就是说,文本文件,网页等都视为textstream对象
- 那就可以把文件想成,一个字符串组成的 字符串数据流 abcd#$%abcd#$%abcd#$%abcd#$%abcd#$% 这类的,后面操作文件内容时,就能理解各种 各种语句和函数了
- 比如 open 语句
- 比如 eof(1) 函数
4.3 函数EOF()
4.3.1 eof() 语法
- 括号内是,文件代号
- 若之前定义文件为#1 ,则 eof(1) 即可,后面关闭 close #1
- 若之前定义文件为#2 ,则 eof(2) 即可,后面关闭 close #2

4.3.2 网上查到的资料
- 前面说到了,文件当成 textstream ,那么既然是有序的 字符串流,那么就需要指针,据说
- eof () 指针指到了,文档内容的末尾,也就是最后一个记录之后
- bof() 指针指到了,文档内容的开头,第一个内容之前。文档开头!
- bof() beganing of file ?
- eof() end of file ?
- bof() 和 eof() 返回的都是 bool 值,true 或者 false
- 当指针指到文件中间的时候, bof(1) =false 同时 eof(1) =false
4.4 打开文件语句,open 语句
- 语法:Open pathname For mode [Access access] [lock] As [#]filenumber [Len=reclength]
- 其中access、lock、reclength为可选参数,一般不用。
- mode 指定打开文件的方式。有5种:
- Input:以输入方式打开,即读取方式。
- Output:以输出方式打开,即写入方式。
- Append:以追加方式打开,即添加内容到文件末尾。
- Binary:以二进制方式打开。
- Random:以随机方式打开,如果未指定方式,则以 Random 方式打开文件。(也就是缺省时,随机方式打开?有点不靠谱,为啥不默认是读取方式呢。。。)
- Open path1 & "101.txt" For Input As #1
- Open path1 & "101.txt" For output As #1
- Open path1 & "101.txt" For append As #1
- Open path1 & "101.txt" For binary As #1
- Open path1 & "101.txt" As #1 '类random
4.4 bof()
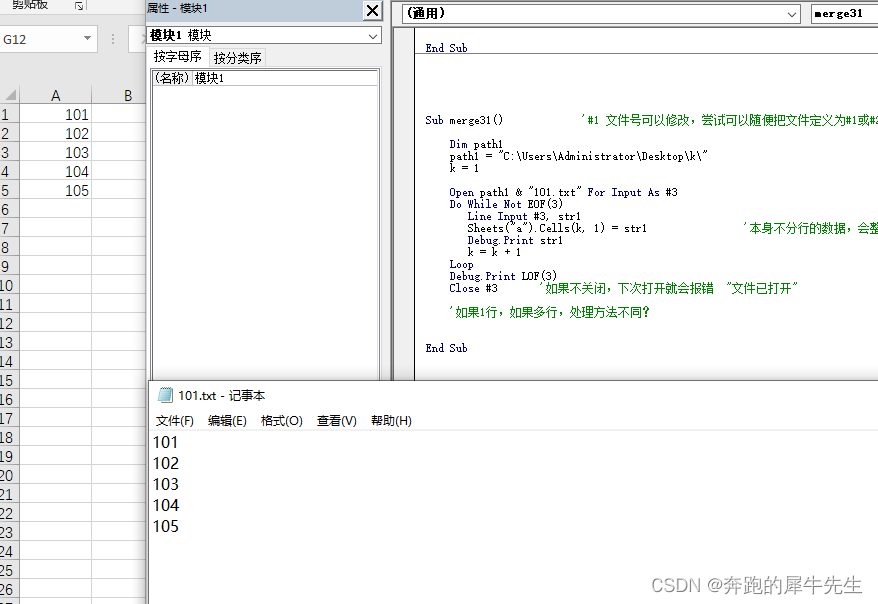
4.5 LOF() 函数
- 语法:LOF(filenumber)
- 功能:返回一个 Long,表示用 Open 语句打开的文件的大小,该大小以字节为单位。
- 例子: lof(1) 返回文件字体大小
代码举例
- 如果1行,101 ,lof(1) 返回3
- 如果2行,101chr(10)102,lof(1) 返回8 (3+3+2)
- 如果3行,101chr(10)102chr(10)103 ,lof(1) 返回13 (3+3+3+2+2)
- 如果4行,101 chr(10)102chr(10)103chr(10)104,lof(1) 返回16 (3+3+3+3+2+2+2)
- 如果5行,101chr(10)102chr(10)103chr(10)104chr(10)105 ,lof(1) 返回23 (3+3+3+3+3+2+2+2+2)
- 为什么是这样
- 第1,lof() 返回的是字节数
- 第2, lof() 也会统计各种不可见字符的字节数,比如换行 chr(10)
- 我觉得,换行chr(10) 被统计为2个字节,ascii码里就是10
4.6 Loc() 函数
语法:LOc(filenumber)
功能:返回一个 Long,在已打开的文件中指定当前读/写位置。
4.7 关闭文件语句,close 语句
- 语法:Close [filenumberlist]
filenumberlist 参数为一个或多个文件号,若省略 filenumberlist,则将关闭 Open 语句打开的所有活动文件。 - 打开文件后,必须在使用完后关闭文件。否则打开文件时会弹窗报错“文件已打开!”
- close #1
- close '关闭block内所有open打开的文件,可好
4.8 Reset 语句
- Reset 语句关闭 Open 语句打开的所有活动文件,并将文件缓冲区的所有内容写入磁盘。
- 感觉 等同于 close 不带参数
4.9 FreeFile 函数
- 语法:FreeFile[(rangenumber)]
- 参数 rangenumber指定一个范围,以便返回该范围之内的下一个可用文件号。指定 0(缺省值)则返回一个介于 1 – 255 之间的文件号。指定 1 则返回一个介于 256 – 511 之间的文件号。
- 功能:提供一个尚未使用的文件号。
- 一般情况下,直接 open XXX for input as #1 这种直接把原来的#1给覆盖了把,所以是有点粗暴,但是好用是没问题。
- 所以我现在能想到的应用场景就是:不想弄乱其他的文件代号# 而随便用一个文件代号,用 freefile 生成一个,然后消除。
- 具体例子,见下面的 input 和 line input 同时使用了 freefile
4.10 读入文件 input 语句
- 读入方式
- input '整体读入,而且无视 文本开头的空格!
- line input ’分行读入,以分行符 chr(10) 为标志,并且,这次只读1行!
- 同时,指针会下移动,下次读下一行
| line input可直接识别 | line input不可识别 但是可以通过split()分行 | ||
| 文件分多行 | 文件分多行 | 文件内未分行 | |
| input | 只能读到第1行 | 只能读到第1行 | 全部内容读成为1行 |
| line input不可识别的多行 | 全部内容读成为1行 | 全部内容读成为1行 | 全部内容读成为1行 |
| line input可识别的多行 | 读成为多行 | 全部内容读成为1行 | 全部内容读成为1行 |
| line input+split()可处理的多行 | 读成为多行 | 读成为多行 | 全部内容读成为1行 |
4.10.1 下面这2个过程,先读一个 101.txt 本身数据是多行的文件

Sub test201()
fnum = FreeFile
Open "C:\Users\Administrator\Desktop\k\101.txt" For Input As #fnum
Input #fnum, aaa1
Debug.Print aaa1
Debug.Print "test201结束"
Close fnum
End Sub
Sub test202()
fnum = FreeFile
Open "C:\Users\Administrator\Desktop\k\101.txt" For Input As #fnum
Do While Not EOF(fnum)
Line Input #fnum, aaa1
Debug.Print aaa1
Loop
Debug.Print "test202结束"
Close fnum
End Sub
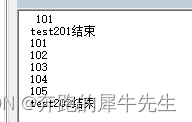
4.10.2 下面这2个过程,修改为,读一个 102.txt 本身数据是1行的文件

Sub test201()
fnum = FreeFile
Open "C:\Users\Administrator\Desktop\k\102.txt" For Input As #fnum
Input #fnum, aaa1
Debug.Print aaa1
Debug.Print "test201结束"
Close fnum
End Sub
Sub test202()
fnum = FreeFile
Open "C:\Users\Administrator\Desktop\k\102.txt" For Input As #fnum
Do While Not EOF(fnum)
Line Input #fnum, aaa1
Debug.Print aaa1
Loop
Debug.Print "test202结束"
Close fnum
End Sub
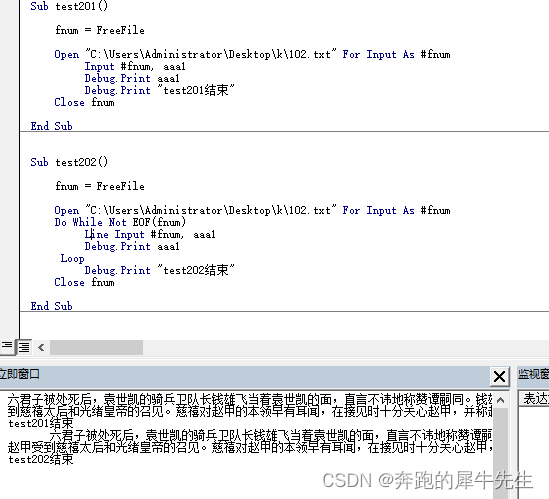
4.10.3 如果文件需要分行呢?需要做处理
- 有些文件内容,其实是分行的,但是无法 被line input 识别为分行内容
- 推测原因
- 可能是因为文件格式问题,比如不是 ansi 而是utf-8等
- 有些换行符,line input 不识别
- 文件里有可能是用其他特殊符号分割的,比如 | ,$ 等等
- 所以先把内容,用split() 函数分割为一个数组,然后再把这个数组进行输出
- split() 函数 ,返回一个数组对象,index从0开始
- split(文本对象,分割符)
代码举例,读62这个文件的内容,保存为utf-8格式

4.10.4 代码效果比较
- test205() ,整体读入,会发现,input 只会读到第1行,无论debug.print 还是读到 excel里
- test206() ,按行line input 逐行读入,会发现,实际上EXCEL里还是不能分行,还是读到了一行里去了,debug.print里看不出来是否分行,和原来文件内容现实一样
- test207(),按行line input 逐行读入,切先把内容split(),然后读数组的元素,就实现了EXCEL表里的分行效果
| line input可直接识别 | line input不可识别 但是可以通过split()分行 | ||
| 文件分多行 | 文件分多行 | 文件内未分行 | |
| input | 只能读到第1行 | 只能读到第1行 | 全部内容读成为1行 |
| line input不可识别的多行 | 全部内容读成为1行 | 全部内容读成为1行 | 全部内容读成为1行 |
| line input可识别的多行 | 读成为多行 | 全部内容读成为1行 | 全部内容读成为1行 |
| line input+split()可处理的多行 | 读成为多行 | 读成为多行 | 全部内容读成为1行 |
test205() 代码和跑得结果
Sub test205()
Dim sh1 As Object
fnum = FreeFile
Set sh1 = ThisWorkbook.Worksheets("a")
Open "C:\Users\Administrator\Desktop\k\62" For Input As #fnum
Input #fnum, aaa1
Debug.Print aaa1
sh1.Cells(1, 2) = aaa1
Debug.Print "test205结束"
Close fnum
End Sub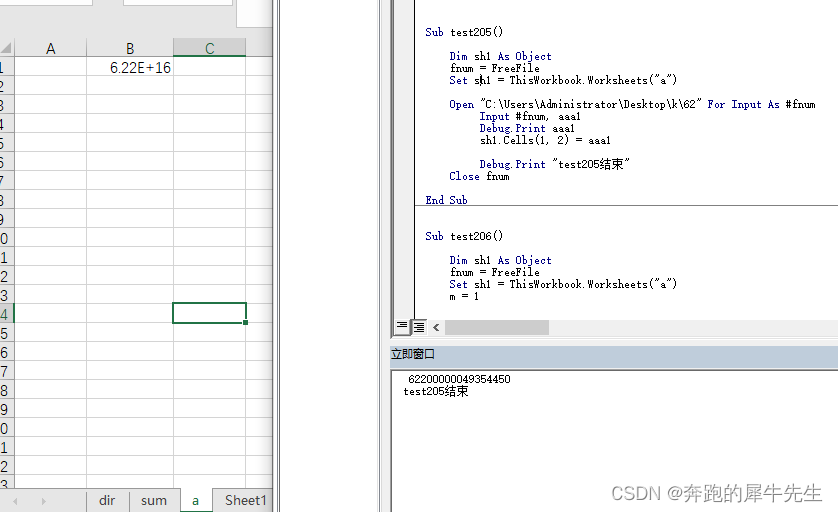
test206() 代码和跑得结果
Sub test206()
Dim sh1 As Object
fnum = FreeFile
Set sh1 = ThisWorkbook.Worksheets("a")
m = 1
Open "C:\Users\Administrator\Desktop\k\62" For Input As #fnum
Do While Not EOF(fnum)
Line Input #fnum, aaa1
Debug.Print aaa1
sh1.Cells(m, 2) = aaa1
m = m + 1
Loop
Debug.Print "test206结束"
Close fnum
End Sub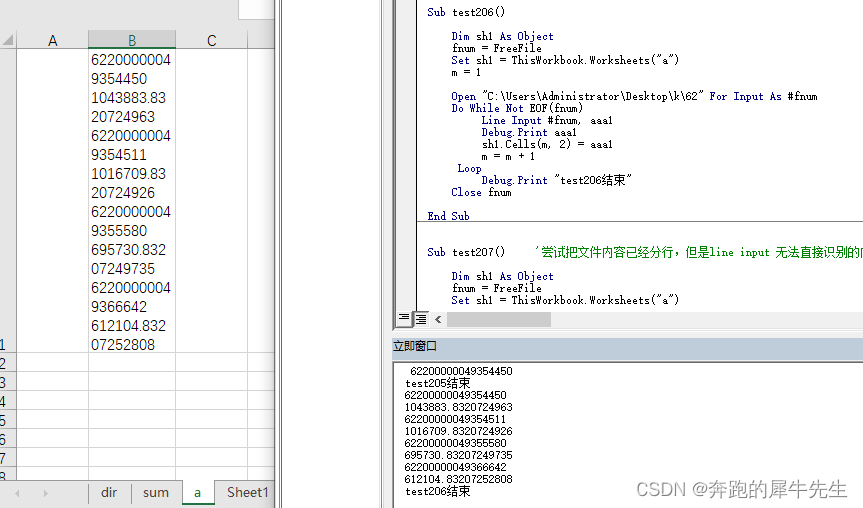
test207() 代码和跑得结果
Sub test207() '尝试把文件内容已经分行,但是line input 无法直接识别的内容,变为分行后读入
Dim sh1 As Object
fnum = FreeFile
Set sh1 = ThisWorkbook.Worksheets("a")
m = 1
Open "C:\Users\Administrator\Desktop\k\62" For Input As #fnum
Do While Not EOF(fnum)
Line Input #fnum, aaa1
lll1 = Split(aaa1, Chr(10)) 'split()返回一个数组,以chr(10)为间隔分行
' For i = 0 To UBound(lll1) Step 1 'split()返回一个数组,index从0开始,千万别写成1,会少1个数据
For i = LBound(lll1) To UBound(lll1) Step 1
Debug.Print lll1(i)
sh1.Cells(m, 2) = lll1(i)
m = m + 1
Next
Loop
Debug.Print "test207结束"
Close fnum
End Sub

5 这段代码是对数据做特殊处理的代码
- 把分行后的数据,还做了特殊处理
- 把不同行的数据放在了EXCEL的不同列
Sub merge13() '只适用1个文件夹内的合并到1个excel, 而并没有遍历全部子文件夹里的文件
Dim s As String
Dim fp, fn
Dim sh1 As Object
Set sh1 = ThisWorkbook.Worksheets("sum")
sh1.Range("A:d").Clear
fff1 = sh1.Cells(1, 7)
m = 1
fp = fff1 & "*.*"
fn = Dir(fp)
i = 0
Do While fn <> ""
' path1 = "C:\Users\Administrator\Desktop\k\" & fn
path1 = fff1 & fn
Open path1 For Input As #1
' If i >= 1 Then
' j = j + maxr1
' End If
Do While Not EOF(1)
Line Input #1, s1
l1 = Split(s1, Chr(10))
For j = 0 To UBound(l1) Step 2
sh1.Cells(m, 2) = "'" & l1(j) & ""
sh1.Cells(m, 3) = "'" & l1(j + 1)
sh1.Cells(m, 4) = fn
m = m + 1
Next
Loop
' maxr1 = sh1.Cells(1, 1).End(xlDown).Row
Close #1
i = i + 1
sh1.Cells(i, 1).Value = fn
fn = Dir
Loop
End SubSub merge12()
Dim s As String
Dim fp, fn
Dim sh1 As Object
Set sh1 = ThisWorkbook.Worksheets("sum")
sh1.Range("A:B").Clear
m = 1
fp = sh1.Cells(1, 3) & "*.*"
fn = Dir(fp)
i = 0
Do While fn <> ""
' path1 = "C:\Users\Administrator\Desktop\k\" & fn
path1 = sh1.Cells(1, 3) & fn
Open path1 For Input As #1
' If i >= 1 Then
' j = j + maxr1
' End If
Do While Not EOF(1)
Line Input #1, s1
l1 = Split(s1, Chr(10))
For j = 0 To UBound(l1)
sh1.Cells(m, 2) = l1(j)
m = m + 1
Next
Loop
' maxr1 = sh1.Cells(1, 1).End(xlDown).Row
Close #1
i = i + 1
sh1.Cells(i, 1).Value = fn
fn = Dir
Loop
End Sub
6 合并,取多个文件内容 + 取文件内所有/部分内容
7 总结方法--横向方法比较
1 取文件名方法
2 遍历文件夹,子文件夹的办法
3 取文件内容的多种方法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









