







本总结是是个人为防止遗忘而作,不得转载和商用。
说明:此篇是作者对“SVM”的第二次总结,因此可以算作对上次总结的查漏补缺以及更进一步的理解,所以很多在第一次总结中已经整理过的内容在本篇中将不再重复,如果你看的有些吃力,那建议你看下我的第一次总结:
http://blog.csdn.net/xueyingxue001/article/details/51261397
百分百正确一定是最好的吗
先看一个情况,如下图所示

图中的实线百分百正确分类了两种数据,但是这样一定是最好的吗?
你看,至少对这个样本集合,如果我舍弃了最左上角的那个点而有了虚线所示的分隔超平面的话,那这个模型的泛化能力更强。
所以,百分百正确不一定最好,而且很多情况下你也做不到百分百正确,比如:你能让所有人都喜欢你吗?不能,而且你追求所有人都喜欢你的话反而会失去本来喜欢你的人的喜欢。
线性支持向量机面临的情况
在上面的基础上,线性支持向量机面临的情况如下:
1,不一定分类完全正确的超平面就是最好的;
2,样本数据本身线性不可分,只好允许错误。
线性支持向量机的目标函数
还记得线性可分支持向量机的约束条件吗?即:
yi·(wT·φ(xi)+b) ≥ 1
而因为线性支持向量机允许错误,即:某个点到分隔超平面的距离不大于1(甚至允许分错),即:
yi·(wT·φ(xi)+b) ≥ 1 - ξi, ξi ≥ 0
这里ξi被称为松弛因子。
相对于线性可分支持向量机的目标函数:

线性支持向量机的目标函数就成为了:

这里C是个超参,用于调节松弛因子和原始目标函数之间的比例关系
PS:如果C=∞时,哪怕ξ十分十分小,上面式子的第二项也会很大,那第二项就起决定性作用了,即:虽然有一点点小“松弛”,原函数也受不了,这样一来为了让前面的原始目标函数不失效,就必须要求ξ=0,这样一来这就是线性可分支持向量机了(不允许任何一点点松弛),所以第二项也是个正则项。
求解方面和线性可分支持向量机那一套一样,这里就直接放截图了(图片来自邹博老师)


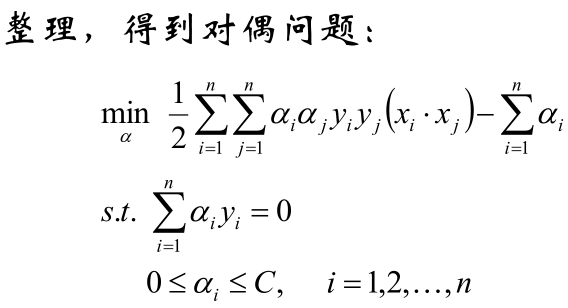
然后和线性可分支持向量机中求α的方法一样求得α后回代到下面的式子:

最后得到分隔超平面:
w*x+ b* = 0
和分类决策函数:
f(x)= sign(w*x + b*)
损失函数分析
这个在我的第一篇总结中已经说明了,所以此处只贴结论(图片来自邹博老师)。
















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









