







1. 前言
前几天,我写了一篇从腾讯的疫情实时追踪站点抓取数据绘制疫情地图的文章,得到了很多朋友的关注和支持。期间有朋友问,下面这个站点无法使用我介绍的方法抓取数据:
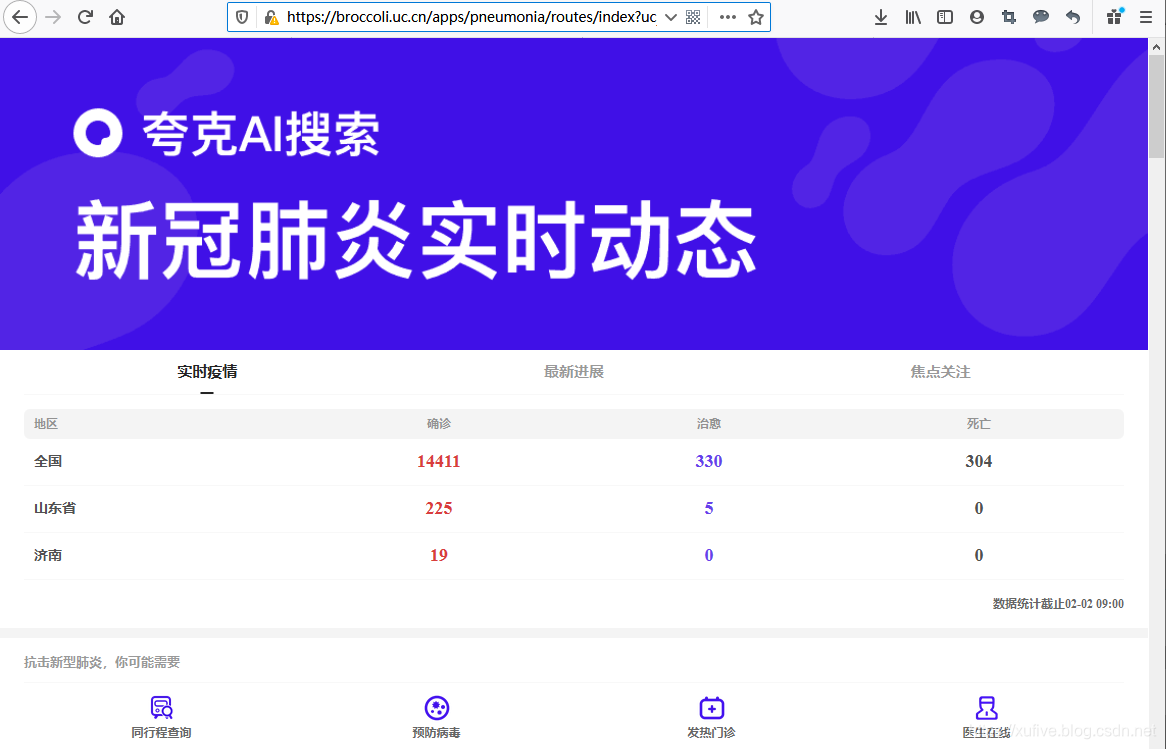
我尝试了一下,的确不能使用常规的手段或者数据。查看网页源代码,和页面显示的内容也完全不搭调。面对这样的网站,我们还有什么技术手段吗?别担心,我今天给大家介绍一个有趣的数据抓取技术:只要通过浏览器地址栏可以访问的数据,都可以抓到,真正做到“可见即可抓”。
可见即可抓的实现,依赖于selenium模块。实际上,selenium并不是专门用于数据抓取的工具,而是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome、Firefox、Safari等主流界面浏览器。用selenium抓取数据,并不是一个通用的方法,因为它仅支持GET方法(当然,也有一些扩展技术可以帮助selenium实现POST,比如安装seleniumrequests模块)。
2. 安装selenium模块
这个就不要多说了,直接pip安装:
python -m pip install selenium
3. 下载浏览器驱动
和大多数模块不同,selenium不能独立工作,它需要浏览器驱动程序的支持。刚才已经说过,selenium支持各种常见的浏览器,你可以选择其中之一或者全部安装。
- Chrome:Google:chromedriver,Taobao:chromedriver
- Firefox:github:geckodriver
近期github无法正常访问,不能科学上网的同学只能从淘宝下载chromedriver了。
4. 配置浏览器驱动环境变量
以chromedriver为例,将下载到的驱动软件chromedriver.exe保存到环境变量path包含的文件夹中,比如C:\Users\xufive\AppData\Local\Programs\Python\Python37,这是python解释器所在的路径。当然,也可以新建一个文件夹保存chromedriver.exe,并将该文件夹添加到环境变量path中。
5. 尝试抓取数据
是时候运行这个神秘工具了:
>>> from selenium import webdriver
>>> driver = webdriver.Chrome()
随着回车键敲击,有两个窗口弹出:一个是刚才下载的浏览器驱动软件chromedriver.exe运行窗口,一个是类似于Chrome浏览器的窗口。
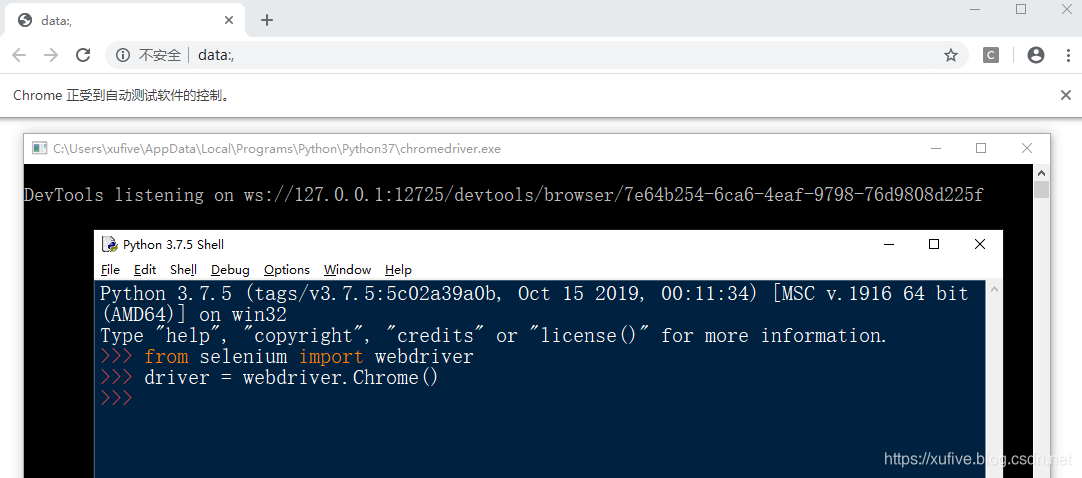 如果不习惯,也可以在启动之前,通过option参数关闭后者,chromedriver.exe的运行窗口无法关闭。当然,在下一步开始前,首先要使用driver.quit()关闭刚才打开的程序。
如果不习惯,也可以在启动之前,通过option参数关闭后者,chromedriver.exe的运行窗口无法关闭。当然,在下一步开始前,首先要使用driver.quit()关闭刚才打开的程序。
>>> from selenium import webdriver
>>> from selenium.webdriver.chrome.options import Options
>>> opt = Options()
>>> opt.add_argument('--headless')
>>> opt.add_argument('--disable-gpu')
>>> opt.add_argument('--window-size=1366,768')
>>> driver = webdriver.Chrome(options=opt)
>>> url = 'https://broccoli.uc.cn/apps/pneumonia/routes/index?uc_param_str=dsdnfrpfbivesscpgimibtbmnijblauputogpintnwktprchmt&fromsource=doodle'
>>> driver.get(url)
>>> with open(r'd:\broccoli.html', 'w') as fp:
fp.write(driver.page_source)
247532
>>> driver.quit()
driver.page_source就是在真正的浏览器中看到的网页内容(渲染后的源代码),现在已经把内容保存成了文件。打开这个文件,和浏览器看到的(未渲染的)源码完全不同,这里面有我们需要的所有数据。
...
<div>
<div class="lable-box">
<div class="lable-item">地区</div>
<div class="lable-item">确诊</div>
<div class="lable-item">治愈</div>
<div class="lable-item">死亡</div>
</div>
<div class="colum-box">
<div class="row-item">
<div class="colum-item">
<div class="colum-item-label">全国</div>
</div>
<div class="colum-item">14415</div>
<div class="colum-item">335</div>
<div class="colum-item">304</div>
</div>
<div class="row-item">
<div class="colum-item">
<div class="colum-item-label">山东省</div>
</div>
<div class="colum-item">225</div>
<div class="colum-item">5</div>
<div class="colum-item">0</div>
</div>
<div class="row-item">
<div class="colum-item">
<div class="colum-item-label">济南</div>
</div>
<div class="colum-item">19</div>
<div class="colum-item">0</div>
<div class="colum-item">0</div>
</div>
</div>
<div class="notify">数据统计截止02-02 12:10</div>
</div>
...
6. 解析数据
刚才把抓到的html脚本数据保存成文件,是为了直观地分析数据组织形式。真正解析数据时,是无需保存文件,selenium提供了足够多的解析技术。
| 定位方式 | 单个节点 | 多个节点 |
|---|---|---|
| id | find_element_by_id() | find_elements_by_id() |
| name | find_element_by_name() | find_elements_by_name() |
| class name | find_element_by_class_name() | find_elements_by_class_name() |
| tag name | find_element_by_tag_name() | find_elements_by_tag_name() |
| link text | find_element_by_link_text() | find_elements_by_link_text() |
| partial link text | find_element_by_partial_link_text() | find_elements_by_partial_link_text() |
| xpath | find_element_by_xpath() | find_elements_by_xpath() |
| css selector | find_element_by_css_selector() | find_elements_by_css_selector() |
以上方法返回的是单个Webelement对象或是多个Webelement对象组成的列表。每一个Webelement对象,都有上述这些方法,以及tag_name、text等属性。
以上面的html为例,我来演示一下如何解析数据:
>>> for item in driver.find_elements_by_class_name("colum-item"):
print(item.text)
全国
14415
338
304
山东省
225
5
0
在Python IDLE中,仅以交互方式就从看似无从下手的网站上抓取并解析出了数据。让我们再次为Python的犀利和简洁点赞!如果喜欢这篇文章,别忘了投票支持我——168号,天元浪子,我正在参加2019年CSDN博客之星总评选活动。谢谢!
















 5740
5740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











