







论文题目:Real-time Personalization using Embeddings for Search Ranking at Airbnb
注:以下内容纯个人理解
创新点
- 实时个性化:之前的做法大多是训练得到user-item和item-item离线文件,然后线上实时读取这些文件。本文的做法是利用item的embedding,作为排序算法一部分特征。
- 适应集合搜索:意思是用户只会在特定区域内搜索,很少有跨区域的情况,所以在训练embedding的时候考虑了特定区域的负样本(大部分负样本是不同区域)。
- 利用转换作为全局变量:整个目标是使用户预订,如果有预订行为则把该数据作为全局变量。
- 用户类型embedding:酒店预订的特殊场景,预订数据往往很稀疏,很难学习到每个用户的embedding,因此本文先对用户进行分类,然后再学到每个类型的embedding。
- 拒绝行为作为负样本:有的卖家会有一些限制条件,把这些样本作为负样本,可减少后期拒绝的行为。
学习Listing embedding
- 想法:获取N个用户的点击序列,每个序列以30分钟的间隔分开;
- 网络结构

- 目标函数
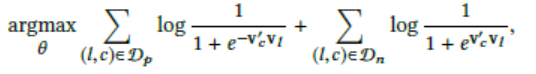
- 加入预订item作为全局信息
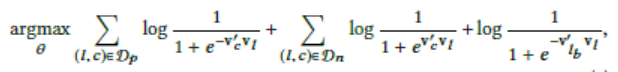
- 加入相同市场负样本
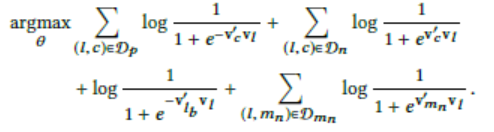
Listing embedding冷启动
- 新item:每天都有新item被雇主发布,这些item不被训练,所以没有embedding;作者提出一种解决方法,使用item的元数据(位置、价格、类型等),计算相似的三个item embedding的平均值作为新item的embedding。
评估embedding
- 评估embedding的好坏:从类型、价格范围方面计算平均余弦相似度,效果如下:

用户类型和item类型embedding
- user type embedding
1)为什么要提出用户类型向量,因为item embedding是基于有限时间窗口训练出来的,所以是短期兴趣。但是用户长期的行为对个性化也是有帮助的。例如:一个用户在洛杉矶搜索酒店,且在伦敦和纽约有过预订的行为,那么可以推荐与之前预订酒店相似的酒店。
2)有人就会问,用户点击的item肯定是和之前预订的item很相似的,而且基于点击行为列表也可以训练出这些item的相似性,那为什么还要构建用户类型向量呢?但是跨区域的item是很难学习到相似性的,因为他们很少共线,常规的做法是使用用户预订的序列作为训练样本。此时会遇到几个问题:
– 数据量很小。
– 绝大多数数据长度为1。
– 许多item出现的频率小于5-10次:因为要学到一个有意义的embedding时,上下文至少需要出现5-10词。
– 用户偏好可能发现变化:由于时间间隔较长,用户的喜好可能发现变化,比如 价格等。
作者提出使用listing type embedding代替listing embedding。
3)用户类型embedding

- listing type embedding
确定item的基本数据:价格、位置、类型、容量、床位等,再通过规则的形式,映射出如下listing type
 例如:Entire Home listing from US that has a 2 person
例如:Entire Home listing from US that has a 2 person
capacity, 1 bed, 1 bedroom & 1 bathroom, with Average Price Per Night of $60.8, Average Price Per Night Per Guest of $29.3, 5 reviews, all 5 stars, and 100% New Guest Accept Rate would map into listing_type = US_lt1_pn3_pg3_r3_5s4_c2_b1_bd2_bt2_nu3 - 训练过程
对于N个用户构造N个预订列表数据,每条数据的user id是一样的。数据格式由用户类型和listing类型组成。

实验
- 训练listing embedding
– 创建8千万条点击序列,时间间隔为30分钟;
– 移除偶然和短时间的点击行为,用户停留时间少于30s;
– 只保留2次及以上点击的序列;
– 设置每天训练:固定的时间窗口滑动,增加新日期数据,去掉旧日期数据,维度:32,窗口大小:5,迭代次数:10,使用mapreduce训练。 - 实时个性化搜索排序
– 标签定义为一些几种:yi ∈ {0, 0.01, 0.25, 1, −0.4},1 是预订,0.25是联系了雇主但没有预订,-0.4是雇主拒绝了客户,0.01是点击,0是没有点击的item。
– 特征向量:listing特征(包含:每晚价格、类型、房间数量、差评率等等),用户特征(平均的预订价格、客户评级等等),搜索特征(顾客数量、停留时间、待几天等等),交叉特征(是上面三个特征的组合)
– 使用GBDT算法
– 把listing embedding加入到搜索排序中
– 加入用户类型embedding和listing类型embedding
– 最后重新训练一个GBDT算法















 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









