- 本文介绍了一种通过OCR识别实现识别指定多个指定区域的文字的方案
- 本文案例使用python实现,不过其他语言可以通过命令调用的方式接入
- 文末提供了一种使用Java语言调用的办法
【图像识别】识别指定多个指定区域的文字
一、实现方案
- 本脚本使用了 Tesseract OCR 引擎。它旨在从图像中识别文本,特别是从指定的图像区域中识别。
- 为了提高速度,这个还使用了多线程进行识别
- 脚本通过命令输入图像路径、识别区域,使用命令如下所示:
python ocrr.py 1712823565608.png 130 478 456 60 195 560 480 60 195 640 480 60 195 727 480 60 195 820 480 60 195 905 480 60 195 995 480 60 195 1085 480 60 195 1176 480 60
二、代码
(一)环境和依赖
pip install Pillow
pip install pytesseract
- 此外,还需要安装Tesseract OCR ,并填写在下方代码处
(二)python代码和解释
import sys
import io
import concurrent.futures
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'D:\software\Tesseract-OCR\tesseract.exe'
custom_config = r'--oem 3 --psm 6 -l eng+chi_sim'
def recognize_text(image_path, rectangles):
"""
识别图片上指定区域的文字
:param image_path: 图片路径
:param rectangles: Rectangle的列表,每个Rectangle为(x, y, width, height)
:return: 一个字典,包含每个Rectangle对应的文字
"""
text_dict = {}
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = []
for i, rect in enumerate(rectangles):
future = executor.submit(recognize_text_region, image_path, rect)
futures.append((i, future))
for i, future in futures:
text_dict[i] = future.result()
return text_dict
def recognize_text_region(image_path, rect):
x, y, width, height = rect
image = Image.open(image_path)
region = image.crop((x, y, x + width, y + height))
text = pytesseract.image_to_string(region, config=custom_config)
return text.strip()
def main():
if len(sys.argv) < 2:
print("用法: python script.py <图片路径> <x1> <y1> <宽度1> <高度1> <x2> <y2> <宽度2> <高度2> ...")
return
image_path = sys.argv[1]
rectangles = []
for i in range(2, len(sys.argv), 4):
try:
x = int(sys.argv[i])
y = int(sys.argv[i+1])
width = int(sys.argv[i+2])
height = int(sys.argv[i+3])
rectangles.append((x, y, width, height))
except ValueError:
print("矩形坐标输入无效。")
return
result = recognize_text(image_path, rectangles)
for i in range(len(rectangles)):
print(result[i])
if __name__ == "__main__":
main()
三、运行效果
- 图片不大方便展示,请看下方的执行效果
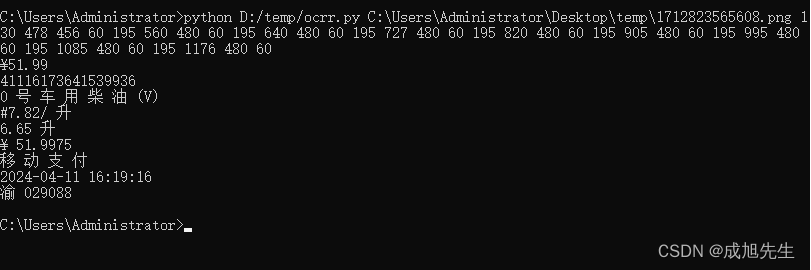
四、Java如何调用
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
public class Test {
public static void main(String[] args) {
try {
long timestamp = System.currentTimeMillis();
String pythonCommand = "python D:/temp/ocrr.py C:\\Users\\Administrator\\Desktop\\temp\\1712823565608.png " +
"130 478 456 60 " +
"195 560 480 60 " +
"195 640 480 60 " +
"195 727 480 60 " +
"195 820 480 60 " +
"195 905 480 60 " +
"195 995 480 60 " +
"195 1085 480 60 " +
"195 1176 480 60 "
;
System.out.println(pythonCommand);
Process process = Runtime.getRuntime().exec(pythonCommand);
InputStream inputStream = process.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line.replaceAll(" ",""));
}
BufferedReader errorReader = new BufferedReader(new InputStreamReader(process.getErrorStream()));
while ((line = errorReader.readLine()) != null) {
System.err.println(line);
}
int exitCode = process.waitFor();
if (exitCode == 0) {
System.out.println("Command executed successfully");
} else {
System.out.println("Command execution failed with error code: " + exitCode);
}
System.out.println((System.currentTimeMillis() - timestamp) + "ms.");
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
}
五、其他
- 如果各位有需要,我可以封装为API给大家?有需要的在评论区高速我,也可以加V:xujian_cq
- 在下的小程序“数字续坚”上还有更多有趣的东西,欢迎交流






















 2850
2850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









