







0.前言
先介绍下现在的整体大数据架构的内容。见下图。
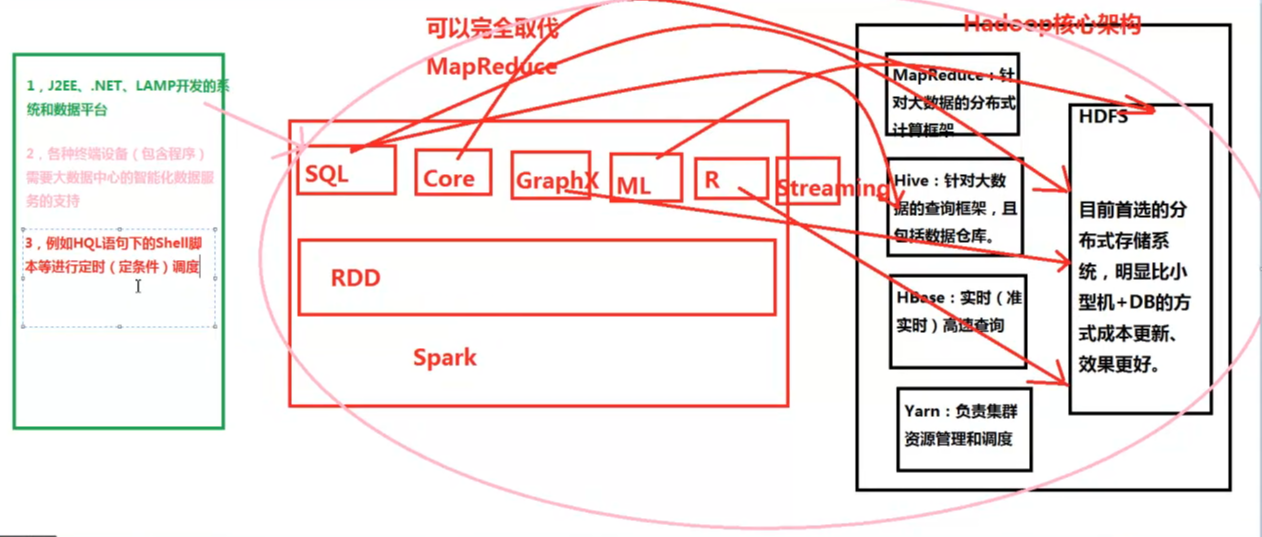
右边的黑框部分是hadoop的核心架构。包括HDFS,MapReduce,yarn,hive,hbase。
中间红框部分是saprk的生态圈,有RDD,sparkCore,sparkSQL,sparkGraphX,sparkML,sparkR,sparkStreaming。Spark可以完全代替Hadoop中的MapReduce部分。
现在的hadoop+spark是最重要的大数据框架。可以用来解决J2EE,.NET,LAMP开发的系统平台的数据处理;支持各类终端设备的数据中心;HQL(理解为面向对象的SQL语句)的查询。
1.Hadoop生态系统解析与实际应用
1.1 Hadoop是一个适合分布式海量数据存储和处理的大数据存储和计算引擎;
1.2 Hadoop核心包含三大部分:
a) HDFS:高效、可靠、低成本的分布式数据存储首选方案;
b) MapReduce: Hadoop的分布式计算模型,基于该模型产生了很多Hadoop适合于具体场景的计算框架,例如Hive、Mahout等;但是由于其先天DNA的缺陷,导致在实现迭代类型的算法的时候显得力不从心,所以正在逐渐和彻底的被新一代最火爆的大数据计算框架Spark所取代;
c) Yarn:大数据集群资源管理器,用于管理同一个集群中不同大数据计算框架资源的使用;
1.3 建议实际生产环境下使用Hadoop 2.6.x版本,http://hadoop.apache.org/releases.html
1.4 Hadoop的生态系统

HDFS:海量分布式数据的存储;
MapReduce:海量数据的计算框架;
Sqoop/HIHO:DB和HDFS是相互导入导出数据;
Hive/Pig:在MapReduce的基础上构建的更加方便人们使用Hadoop的子框架;
Ganglia:集群的监控管理工具;
ZooKeeper:集群的同步工具,一般用来做HA;
HBase:OLTP(On-Line Transaction Processing联机事务处理系统)存储和高速实时查询系统;
1, Hive:Hadoop的数据仓库,包含两部分数据仓库本身以及基于数据仓库的查询计算引擎;把数据映射成为数据库的表并提供完整的SQL查询功能,实际计算的时候是在背后把SQL语句转换成为MapReduce任务进行运行,所以计算Hive的计算引擎只是一个单机版本的客户端而已;
2, Pig,使用SQL-Like的语言Pig Latin来进行Hadoop更加简易的操作和编程接口;
3, HBase:是Hadoop的数据库,其本质是一个NoSQL类型的实时高速检索引擎;
4, ZooKeeper:一般用做HA(高可用);
5, Sqoop:用于在Hadoop和关系型数据库之间的数据相互转移的工具
具体每块内容后面一一学习。博主也是学习中。
本博客学习自王家林的视频。















 1525
1525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









