







0.前言
我要搭建的集群是一台Master和3台Worker。先按照以下博客内容配置。
第一步:修改hostname和hosts
http://blog.csdn.net/xummgg/article/details/50634327
第二步:ubuntu下ssh无密码登入(设置ssh公钥认证)
http://blog.csdn.net/xummgg/article/details/50634730
1.安装rsync

rsync,remote synchronize顾名思意就知道它是一款实现远程同步功能的软件,它在同步文件的同时,可以保持原来文件的权限、时间、软硬链接等附加信息。可以通过ssh方式来传输文件。
在4台机器上都安装好rsync,可通过ssh进入其他机器并输入安装指令。
2.安装JDK
Hadoop是要安装在JVM上运行的,所以都要安装JDK。这里的操作先在一台机器上进行,先在Master机器上进行。
2.1 下载JDK
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
选择linux 64位系统,压缩凡是tar.gz

截图中时8.73版本。我实际下载的时8.71版本。
2.2 解压
我下载的在Downloads文件夹里,所以先直接解压在当前目录:

复制到local目录下(我把要安装的东西都放在了这个目录下)

2.3 配置JDK,JRE环境变量
修改bashrc文件,添加环境变量

在文件末尾加入如下内容:
再用soure命令,使其生效:
2.4 验证
输入java -version,能显示版本好,就表示JDK配置成功。

4台电脑都要配置jdk,后面配置中会用scp命令来传输给其他3台。
3.安装Hadoop
继续先在Master机器上进行单台配置。
3.1下载Hadoop
下载地址:
http://hadoop.apache.org/releases.html
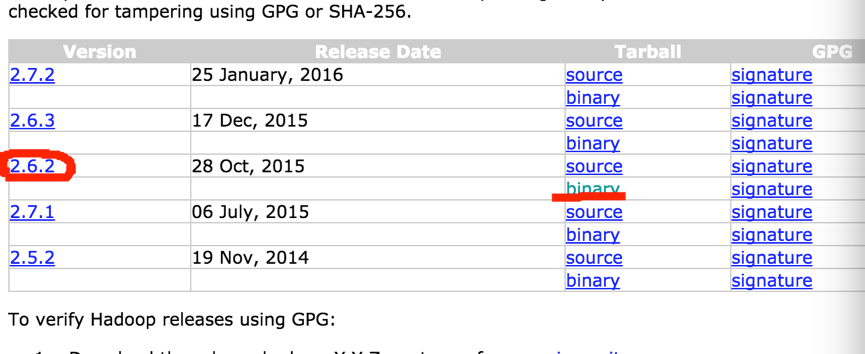
我选用时2.6.2版本,binary的。
3.2 解压
解压在当前目录

复制到local目录下

3.3 配置Hadoop环境变量
用vim命令编辑bashrc文件:
添加如下内容:
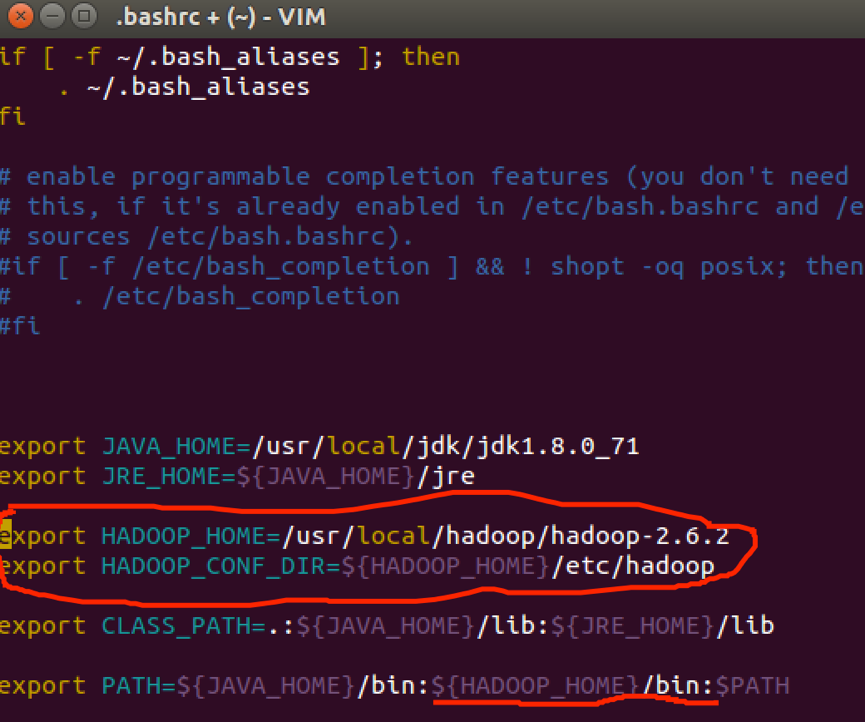
保存并退出。再用source使其生效。

图中配置HADOOP_CONF_DIR文件时为了更好多支持yarn的运行(yarn是个资源管理框架)
监测环境配置是否正确,输入hadoop version
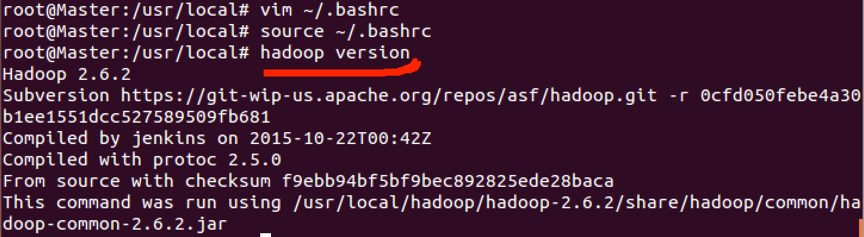
能显示版本就表示正确。
3.4 单台设置Hadoop文件配置
Hadoop的配置文件在etc里的hadoop里面,我一共是配置了6个文件,core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml,hadoop-env.sh,slaves
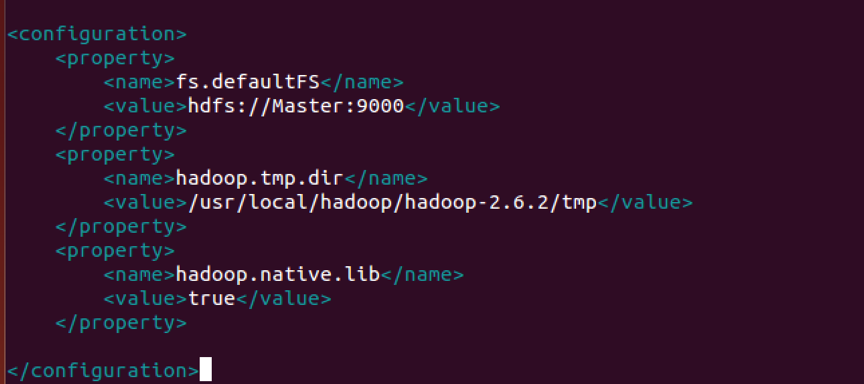
- 配置core-site.xml
先cd进入etc的hadoop里。
vim命令打开core-site.xml文件
添加如下配置内容:
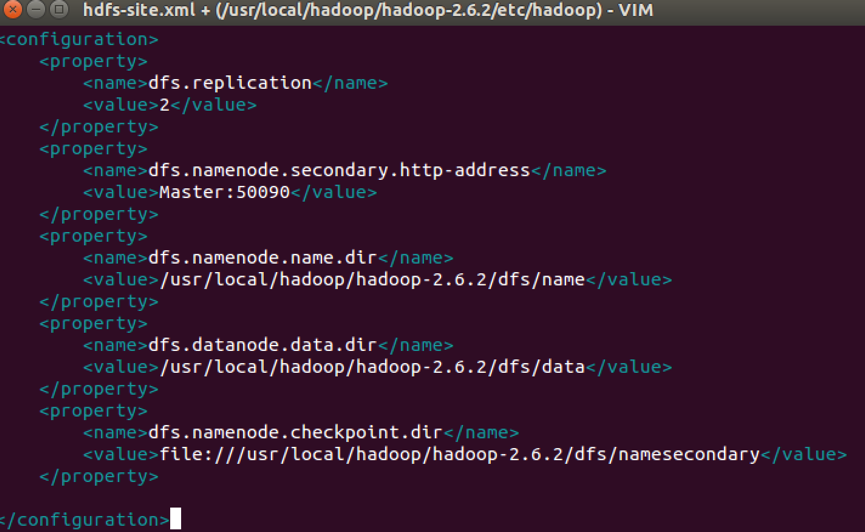
- 配置hdfs-site.xml
vim命令打开hdfs-site.xml文件
添加如下配置内容:
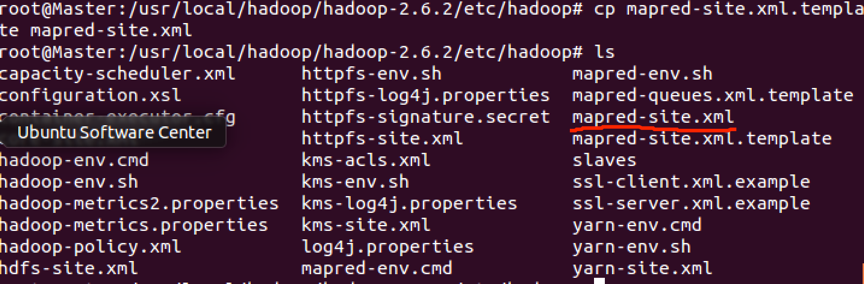
- 配置mapred-site.xml
在目录里木有mapred-site.xml文件,只有mapred-site.xml.template文件,先复制这个文件,并命名为mapred-site.xml,用cp命令复制,代码如下:
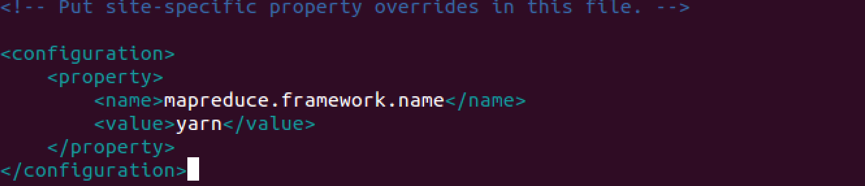
vim命令打开mapred-site.xml文件
添加如下配置内容:
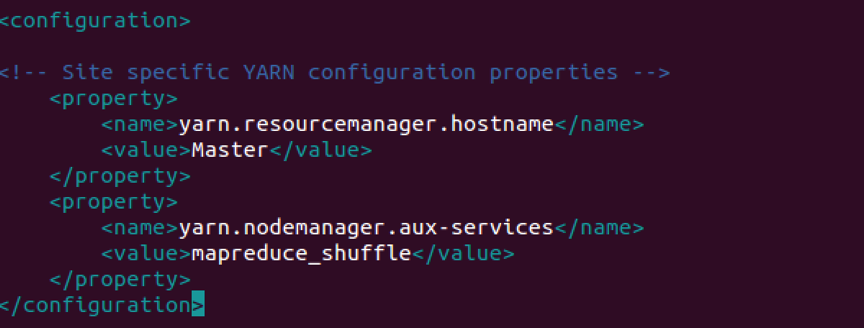
- 配置yarn-site.xml
vim命令打开yarn-site.xml文件
添加如下配置内容:
- 配置hadoop-env.sh
vim命令打开hadoop-env.sh文件
添加如下配置内容:
- 配置slaves
vim命令打开slaves文件
修改配置如下:
这个时候Master里的Hadoop内容都配置完成了。







3.5 配置Hadoop集群
直接从Master机器上将JDK,Hadoop,bashrc文件都发送到各个Worker机器上。
scp传bashrc文件给3台Worker机器:

scp传hadoop文件夹给3台Worker机器:




scp传JDk文件夹给3台Worker机器:



并用ssh登入其他worker,用source使每台的bashrc文件生效。下面只取Worker1机器的操作。
到这里所以相关配置完成了。
4.运行Hadoop集群
格式化文件系统(必须做):

开启dfs文件系统:

用JPS查看当前进行,显示如下则启动成功:

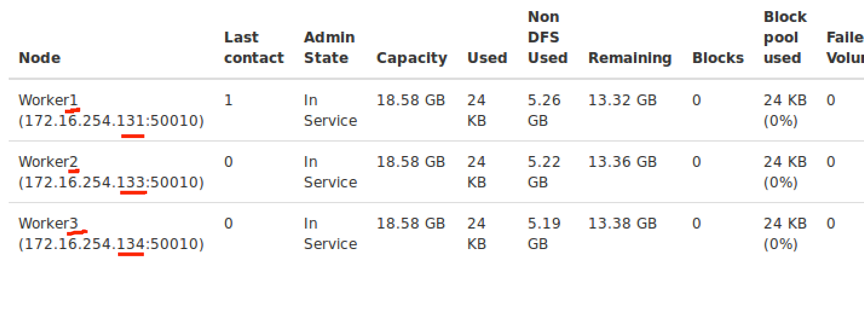
也可以在WEB浏览器等入Master:50070来查看,可以看到我的Live Nodes 显示有3台存在,说明成功了。
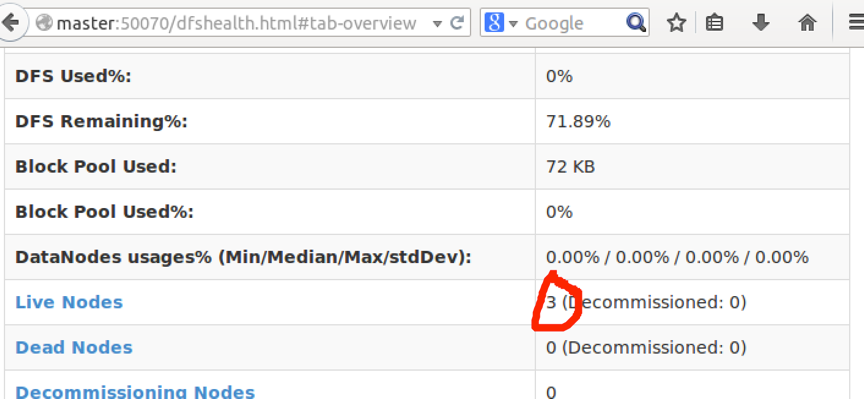
也可以在Live Nodes点进去,查看具体信息:
开启yarn资源管理模块:
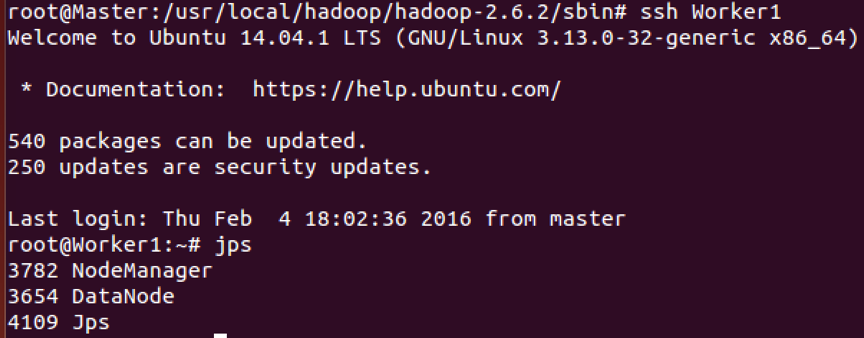
再用jps来查看,发现多开启了个ResoureManager,说明资源管理模块yarn开启成功。

可以登入到Woker节点,用jps查看,内容如下:
还可以再Master:8088上查看内容:
再这上面就可以开启mapreduce。
5.测试Hadoop集群
在测试中发现我的Mac,跑4台虚拟机,运行hadoop,内存不够。所以测试改为1台master和2台worker。请自行修改slave,hosts 文档。
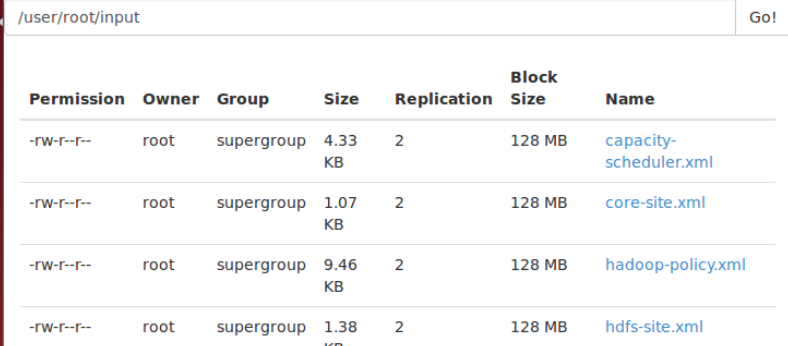
先在hadoop文件系统上创建用户文件夹,如下图中前2行代码。
在本地hadoop目录下创建一个input文件夹,把hadoop目录x下的etc/hadoop目录里所有xml格式结尾的文件都复制到input文件夹。将本地的input文件夹上传到远程hadoop的文件系统上去。(用hadoop的put命令)

可以到master:50070里看下,文件是否上传成功。
运行官方自带的wordcount程序,将input作为输入,将output/wordcount 作为输出地址:

运行完成后,可以看到root用户下多了wordcount的结果:
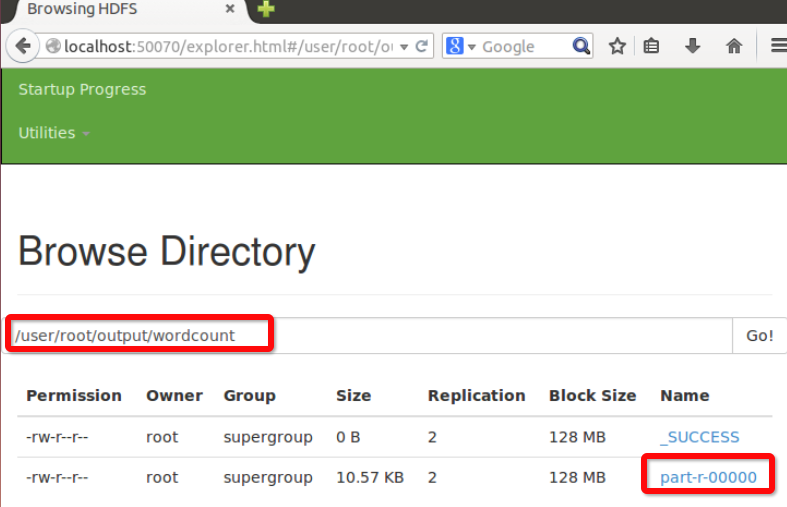
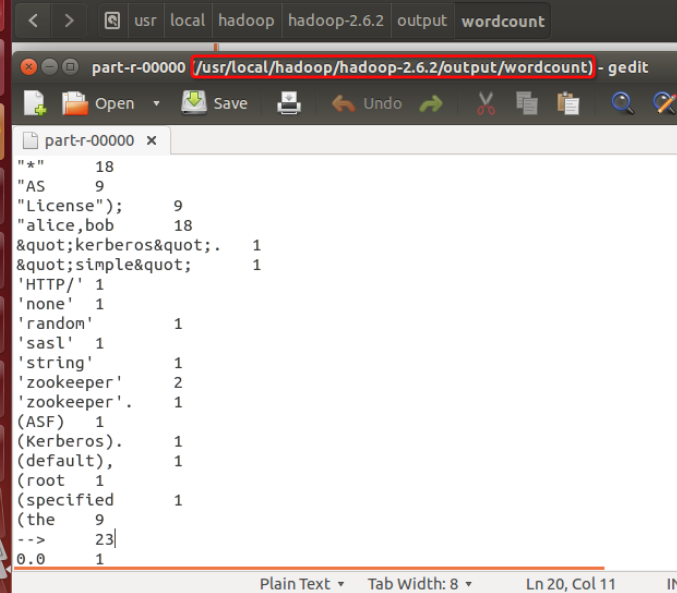
获取分布式系统上的output文件夹,放到本地hadoop-2.6.2目录下:

进入文件夹内查看结果:
还可以在master:8080里查看job的记录:

XianMing














 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









