







原文链接:http://blog.csdn.net/u014696921/article/details/53138327
SSD的安装
- 在home目录下,获取SSD的代码,下载完成后有一个caffe文件夹
-
git clone https://github.com/weiliu89/caffe.git cd caffe git checkout ssd(出现“分支”则说明copy-check成功)- 进入下载好的caffe目录,复制配置文件
cd /home/usrname/caffe cp Makefile.config.example Makefile.config- 编译caffe三部曲
make all -j16 //-j16根据本机的处理器配置,16是16核处理器的意思 make test -j16 make runtest -j16(这一步不是必须的)- 额外编译,根据需要(因为SSD利用python完成,需编译pycaffe)
make pycaffe -j16准备工作
-
下载预训练模型 链接:http://pan.baidu.com/s/1miDE9h2 密码:0hf2,将它放入caffe/models/VGGNet/目录下
-
下载VOC2007和VOC2012数据集,放到/home/data下。(请注意,这里改变了目录)
cd .. mkdir data cd data/- 下载数据集
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar- 数据集解压
tar -xvf VOCtrainval_11-May-2012.tar tar -xvf VOCtrainval_06-Nov-2007.tar tar -xvf VOCtest_06-Nov-2007.tar- 将图片转化为LMDB文件,用于训练
cd .. cd caffe/ ./data/VOC0712/create_list.sh ./data/VOC0712/create_data.sh- 这里用的脚本实现批处理,可能会出现:no module named caffe等错误,这是由于caffe的Python环境变量未配置好,可按照下面方法解决:
echo "export PYTHONPATH=/home/usrname/caffe/python" >> ~/.profile source ~/.profile echo $PYTHONPATH #检查环境变量的值
*这里也可以使用sudo vim ~/.profile打开环境变量profile文件,在文件最后添加“exprot PYTHONPATH=/home/yourname/caffe/python”,然后保存关闭。
然后使用命令:source ~/.profile使其生
-
训练模型
- 在下载的caffe根目录执行如下命令训练,在examples/ssd下存在几个.py文件,训练的时间较长,迭代60000次,博主训练了一天!
python examples/ssd/ssd_pascal.py实验效果
(1)在图片测试集上测试
python examples/ssd/score_ssd_pascal.py利用它跑了一遍数据集,得出准确率可以达到百分之70多
(2)在视频上测试
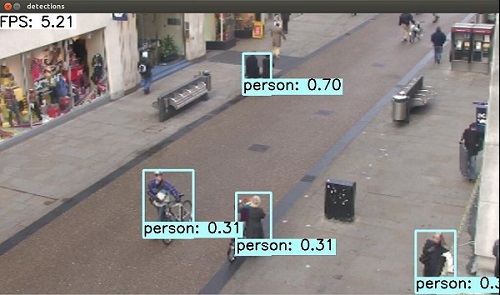
python examples/ssd/ssd_pascal_video.py利用师兄的行人视频做了测试,实时性高,但是漏检率蛮严重的,这是不可避免的
当然,直接跑是他自带的视频,想跑自己的代码的话,要先用vim打开该文件,定位到51行,修改视频路径为已有本地视频,这样就可以畅快的跑自己的视频(3)在摄像头上测试
python examples/ssd/ssd_pascal_webcam.py博主移植到台式机上出现了问题,还没有改好bug,改好了会分享给大家
后期工作
- 研究SSD的python源代码,用来训练和检测交通标志\文本检测,人脸检测等等
作者给定的预训练模型
如果没有好的机器配置或者省事一些的,可以使用作者给出的训练好的模型:
最近一直在搞object detection玩,之前用的是faster-rcnn,准确率方面73.2%,效果还不错,但是识别速度有点欠缺,我用的GPU是GTX980ti, 识别速度大概是15fps.最近发现SSD(single shot multibox detector) 这篇论文效果和速度都不错,我自己实验了一下,速度确实比faster-rcnn快不少。下面分两部分来介绍。第一部分介绍SSD的安装,第二部分介绍如何基于SSD训练自己的数据集。
第二部分 训练自己的数据集
首先我们不妨先跑一下项目的demo, 需要下载数据集,提前训练好的数据集等。
下载预训练的模型,链接:http://pan.baidu.com/s/1miDE9h2 密码:0hf2,下载完成后保存在:caffe/models/VGGNet/下载VOC2007和VOC2012数据集, 放在/data目录下:
cd data wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar tar -xvf VOCtrainval_11-May-2012.tar tar -xvf VOCtrainval_06-Nov-2007.tar tar -xvf VOCtest_06-Nov-2007.tar创建lmdb格式的数据:
cd caffe ./data/VOC0712/create_list.sh # It will create lmdb files for trainval and test with encoded original image: # - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb # - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb ./data/VOC0712/create_data.sh训练和测试:
python examples/ssd/ssd_pascal.py论文中,作者已经预训练好模型,下载链接:http://www.cs.unc.edu/%7Ewliu/projects/SSD/models_VGGNet_VOC0712_SSD_300x300.tar.gz,我们不必自己再去训练, 下载完成后放入指定的文件夹下。
测试时,我们使用/example/ssd/目录里的ssd_detect.ipynb,运行这个文件,需要安装ipython及ipython-notebook, 或者直接把里面的代码拷贝出来,写到一个新的python文件里,比如命名ssd_detector.py.OK, 下面修改一系列文件来训练自己的数据集
两种方案, 第一:保持原来的文件目录结构及文件名不变, 只替换里面的数据。第二:重新新建一个与之前类似的目录结构,改成自己命名的文件夹,第二种方法,有一定的风险性,需要修改程序里涉及数据路径的代码。在之前讲解的faster-rcnnan那篇博客中, 我们采用第一种方案。本次我们采用第二种方案。
在/data目录下创建一个自己的文件夹:cd /data mkdir mydataset把/data/VOC0712目录下的create_list.sh 、create_data.sh、labelmap_voc.prototxt 这三个文件拷贝到/mydataset下:
cp data/create* ./mydataset cp data/label* ./mydatasetlabelmap_voc.prototxt, 此文件定义label。
在/data/VOCdevkit目录下创建mydataset, 并放入自己的数据集:
cd data/VOCdevkit mkdir mydataset cd mydataset mkdir Annotations mkdir ImageSets mkdir JPEGImages cd ImageSets mkdir Layout mkdir Main mkdir Segmentation其中Annotations中存放一些列XML文件,包含object的bbox,name等;
ImageSets中三个子目录下均存放train.txt, val.txt, trainval.txt, test.txt这几个文件,文件内容为图片的文件名(不带后缀);
JPEGImages存放所有的图片;在/examples下创建mydataset文件夹:
mkdir mydataset文件夹内存放生成的lmdb文件。
上述文件夹创建好后, 开始生成lmdb文件, 在创建之前需要修改相关路径:
./data/mydataset/create_list.sh ./data/mydataset/create_data.sh此时,在examples/mydataset/文件夹下可以看到两个子文件夹, mydataset_trainval_lmdb, mydataset_test_lmdb;里面均包含data.dmb和lock.dmb;
到此为止,我们的数据集就做好了。接下来就开始训练了。训练程序为/examples/ssd/ssd_pascal.py,运行之前,我们需要修改相关路径代码:
cd /examples/ssd vim sd_pascal.py, 修改如下: 57行: train_data路径; 59行:test_data路径; 197-203行:save_dir、snapshot_dir、job_dir、output_result_dir路径; 216-220行: name_size_file、label_map_file路径; 223行:num_classes 修改为1 + 类别数 315行:num_test_image:测试集图片数目另外, 如果你只有一个GPU, 需要修改285行:
gpus=”0,1,2,3” ===> 改为”0”
否则,训练的时候会出错。
修改完后运行python ./examples/ssd/ssd_pascal.py训练完, 修改ssd_detector.py中模型路径, 任意找一张图片识别,看看效果怎么样。
参考:
【1】SSD论文Single Shot MultiBox Detector
【2】https://github.com/weiliu89/caffe/tree/ssd
















 5594
5594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









