



1.llama.cpp环境安装
拉取项目
git clone https://github.com/ggerganov/llama.cpp
进入目录
cd llama.cpp
CUDA 版本编译
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release
该过程需要等待一段时间
2.模型文件转换
魔搭社区拉取模型文件
git clone https://www.modelscope.cn/Qwen/Qwen2.5-3B-Instruct.git
进入到llama.cpp文件夹下,进行模型文件转换,将safetensor格式转换为gguf格式
python ./convert_hf_to_gguf.py /mnt/workspace/Qwen2.5-3B-Instruct/ --outfile /mnt/workspace/Qwen2.5-3B-Instruct-fp16.gguf
转换后默认为半精度FP16类型
3.模型量化
进入到llama.cpp的build/bin目录下,执行命令
./llama-quantize /mnt/workspace/Qwen2.5-3B-Instruct-fp16.gguf /mnt/workspace/Qwen2.5-3B-int4.gguf q4_0
执行完毕后将FP16类型量化为int4类型的模型
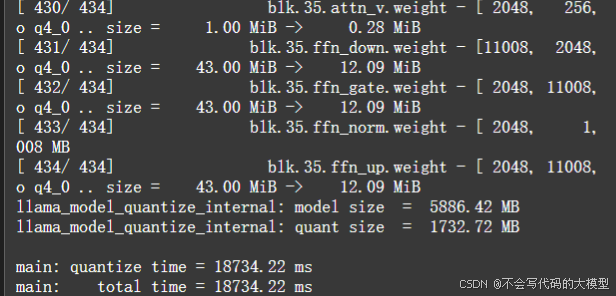
可以看到,量化后的模型大小为1.7G,显著下降
4.模型推理
./llama-cli -m /mnt/workspace/Qwen2.5-3B-int4.gguf --color -c 512 -b 64 -n 256 -t 12 -i -r "助手:" -p "你是人工智能助手" -cnv
还有很多参数可选
 也可以进行API的部署
也可以进行API的部署
./llama-server -m /mnt/workspace/Qwen2.5-3B-int4.gguf --port 8080
启动一个api,运行在8080端口
经过量化后的模型通过llama.cpp进行推理和部署时候,发现比自行计算所占的显存还要小,有了解的朋友麻烦指点下


















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









