







一、LoRA与QLoRA
LoRA:LoRA 是一种用于微调大型语言模型的技术,通过低秩近似方法降低适应数十亿参数模型(如GPT-3)到特定任务或领域。
QLoRA:QLoRA 是一种高效的大型语言模型微调方法,它显著降低了内存使用量,同时保持了全16 位微调的性能。它通过在一个固定的、4 位量化的预训练语言模型中反向传播梯度到低秩适配器来实现这一目标。
下载qwen模型,比如Qwen/Qwen2.5-1.5B-Instruct
启动LLaMA-Factory
cd llamafactory
llamafactory-cli webui
然后使用自己的数据集开始训练自己的Qwen2.5-1.5B-Instruct
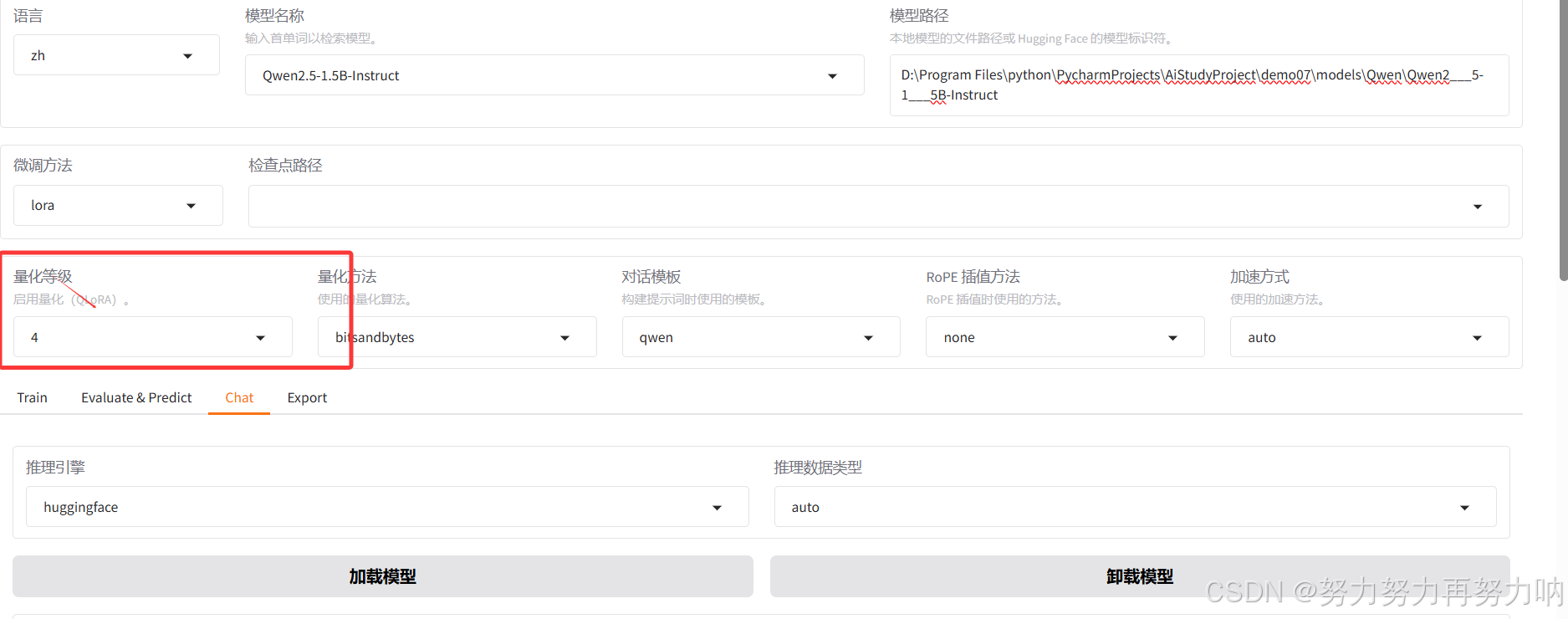
二、量化等级选择建议
量化等级QLoRA选择
如果你的模型足够大,那么就选择4,因为参数量足够多 如果你的模型足够小,那么就选择8,因为参数量足够少
选择量化等级(如 QLoRA 中的量化位数)时,确实需要考虑模型的规模和参数数量。QLoRA(Quantized Low-Rank Adaptation)是一种用于大语言模型的高效微调方法,它结合了量化和低秩适应技术,以减少内存使用和计算成本。
-
大模型(参数量多):
- 选择较低的量化位数(如 4 位):
- 大模型通常具有更多的参数,因此可以承受更激进的量化而不会显著损失性能。
- 4 位量化可以显著减少内存占用和计算需求,同时保持相对较高的模型精度。
- 选择较低的量化位数(如 4 位):
-
小模型(参数量少):
- 选择较高的量化位数(如 8 位):
- 小模型对量化的敏感度更高,因为每个参数对模型性能的影响更大。
- 8 位量化提供了更好的精度平衡,减少了量化误差对模型性能的影响。
- 选择较高的量化位数(如 8 位):
其他考虑因素
-
任务需求:
- 某些任务可能对模型精度要求更高,即使模型较小,也可能需要选择较低的量化误差(即较高的量化位数)。
-
硬件限制:
- 如果你的硬件资源有限(如 GPU 内存不足),可能需要选择更高的量化等级以减少内存占用。
示例
假设你有一个大语言模型,参数量超过 10 亿,你可能会选择 4 位量化来减少内存占用和计算成本。相反,如果你有一个参数量较少的模型(如几百万参数),你可能会选择 8 位量化来保持模型性能。
三、加速方式选择
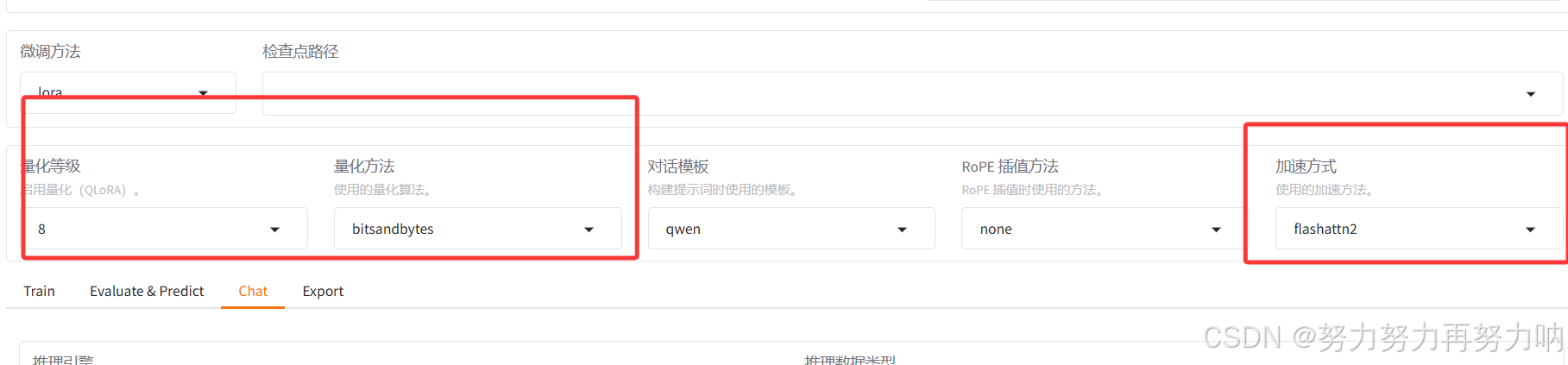
如果你的显卡架构是 SM80 或更高(例如,NVIDIA Ampere 架构及以后的 GPU,如 A100、H100、RTX 30 系列和 RTX 40 系列),选择使用 FlashAttention-2(通常简称为 FlashAttn2)可以显著加速训练过程,尤其是在处理注意力机制时。
FlashAttention-2 的优势
-
高效的内存使用:
- FlashAttention-2 通过优化内存访问模式,减少了注意力计算中的内存带宽瓶颈。
-
加速计算:
- 利用现代 GPU 的张量核心(Tensor Cores)和混合精度计算,FlashAttention-2 可以显著加速注意力机制的计算。
-
支持长序列:
- 对于需要处理长序列的任务,FlashAttention-2 提供了更好的性能和可扩展性。
适用场景
-
大语言模型训练:
- 在训练大型 Transformer 模型时,注意力机制的计算是主要的性能瓶颈之一。FlashAttention-2 可以有效缓解这一问题。
-
长序列处理:
- 如果你的任务涉及处理长文本序列(如长文档摘要、长对话生成等),FlashAttention-2 可以提供更好的性能。
如何使用 FlashAttention-2
-
检查显卡兼容性:
- 确保你的显卡架构是 SM80 或更高。你可以通过 NVIDIA 的官方文档或工具(如
nvidia-smi)来检查显卡的架构。
- 确保你的显卡架构是 SM80 或更高。你可以通过 NVIDIA 的官方文档或工具(如
-
安装依赖:
- FlashAttention-2 可能需要特定的库和依赖项。确保你已经安装了所有必要的软件和库。
-
集成到模型:
- 根据你使用的深度学习框架(如 PyTorch、TensorFlow 等),将 FlashAttention-2 集成到你的模型中。这通常涉及替换标准的注意力实现为 FlashAttention-2 的实现。
-
验证性能:
- 在集成 FlashAttention-2 后,运行一些基准测试来验证性能提升。确保模型在保持准确性的同时,训练速度得到了显著提高。
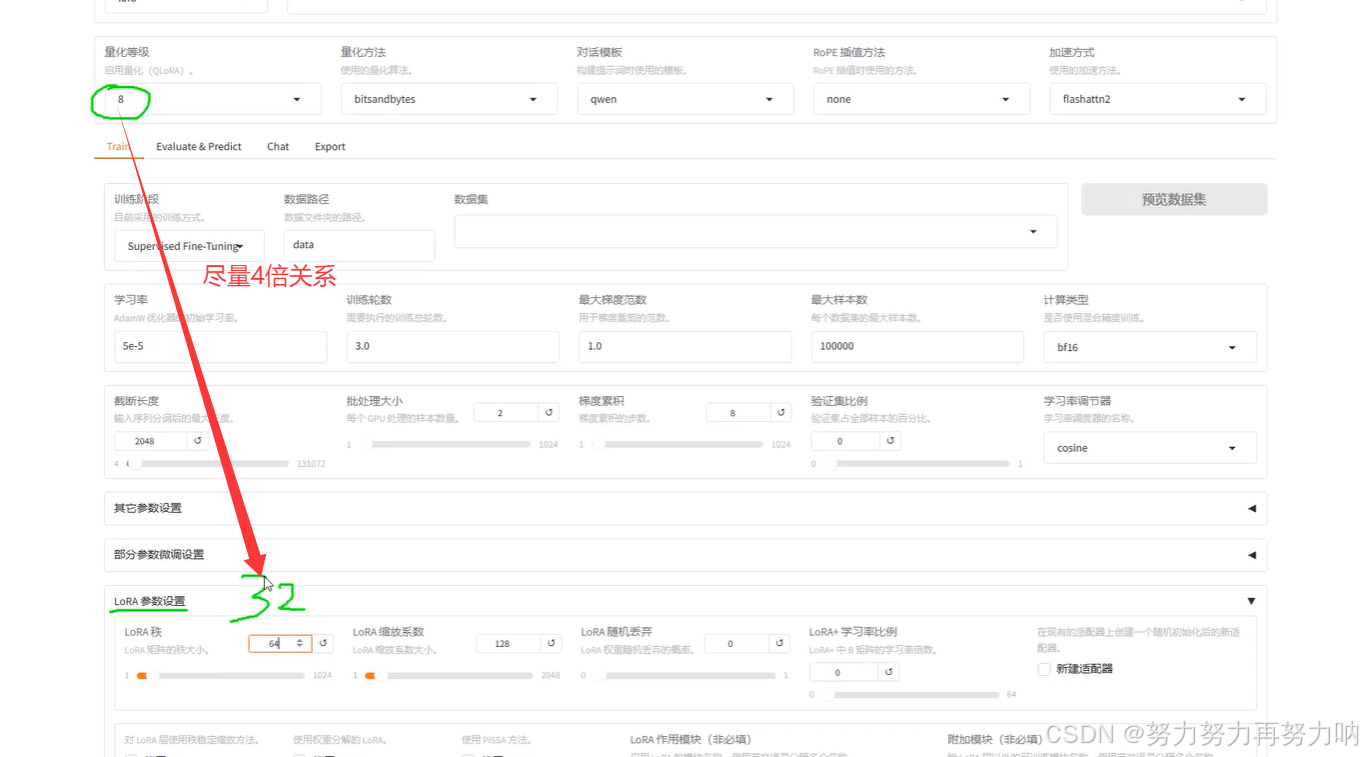
四、LoRA参数设置
官方给的最理想的的是设置为52,LoRA秩的范围32~128,系数为LoRA秩的2倍

量化等级与LoRA秩
LoRA秩与LoRA缩放系数越大,训练效果可能越好,基座模型越大,LoRA秩越大,LoRA秩的范围32~128,LoRA秩越大,显存占用越大。
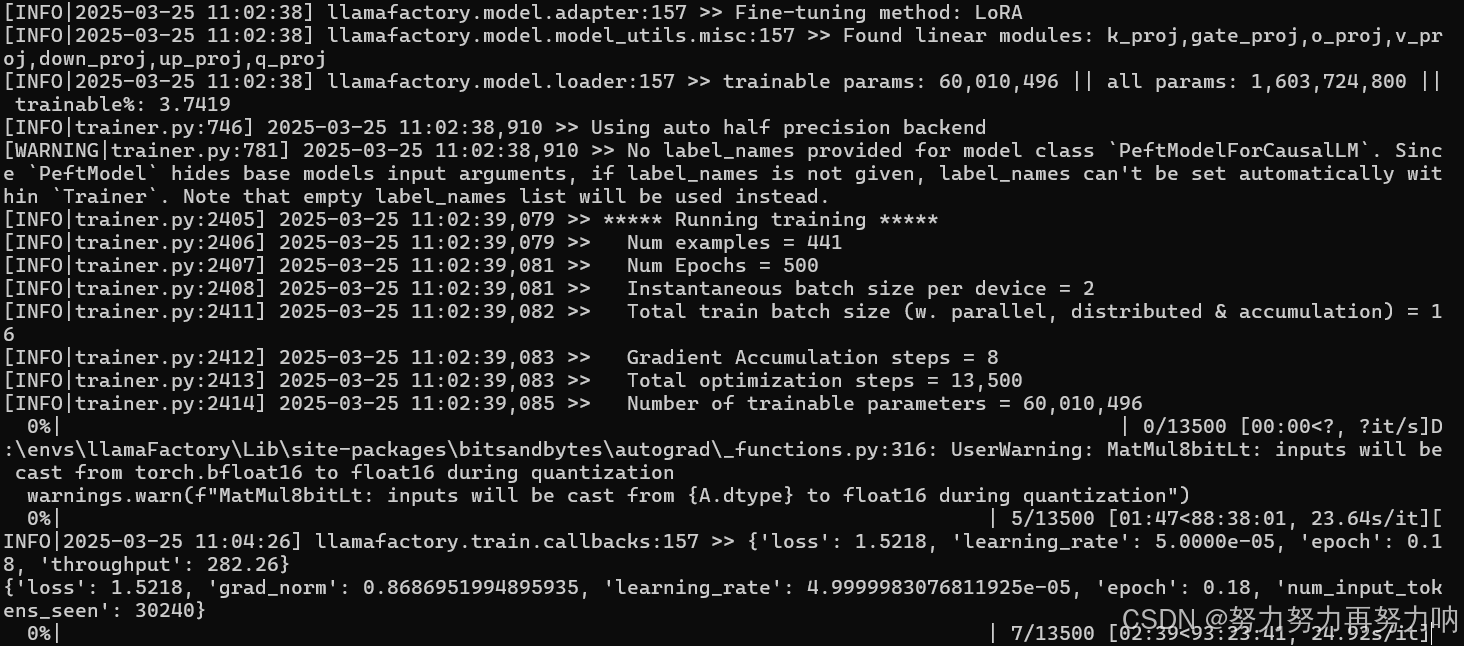
训练报错
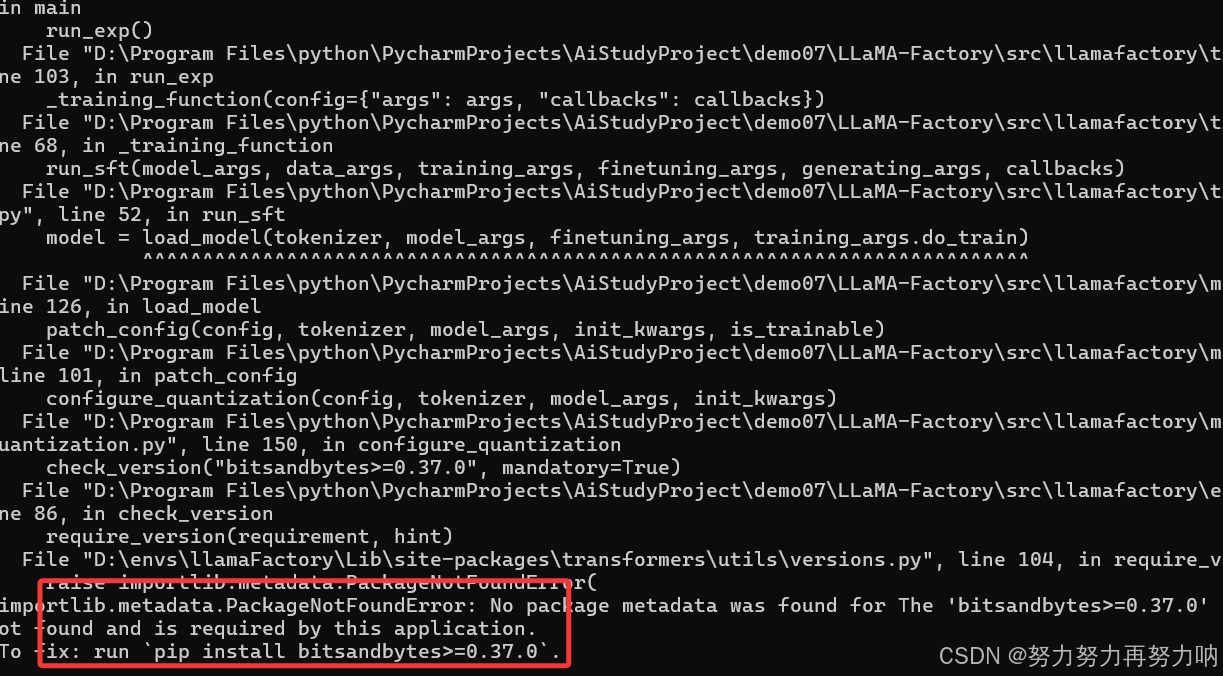
安装pip install bitsandbytes==0.37.0或者最新版就会报如下错误,怎么改版本都不行。尝试了43.3就可以了
pip install bitsandbytes==0.43.3
调试过程中的报错
以下可以不用看
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
llamafactory 0.9.3.dev0 requires peft<=0.12.0,>=0.11.1, but you have peft 0.15.0 which is incompatible.
llamafactory 0.9.3.dev0 requires transformers!=4.46.*,!=4.47.*,!=4.48.0,<=4.49.0,>=4.41.2; python_version >= "3.10", but you have transformers 4.50.0 which is incompatible.
LLaMA-Factory与最新版本的Transformers库存在兼容性问题
安装兼容版本(例如4.49.0)
pip install transformers==4.49.0
安装兼容版本(例如0.12.0)
pip install peft==0.12.0
训练还是报错
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Program Files\python\PycharmProjects\AiStudyProject\demo07\LLaMA-Factory\src\llamafactory\model\adapter.py", line 297, in init_adapter
model = _setup_lora_tuning(
^^^^^^^^^^^^^^^^^^^
File "D:\Program Files\python\PycharmProjects\AiStudyProject\demo07\LLaMA-Factory\src\llamafactory\model\adapter.py", line 249, in _setup_lora_tuning
model = get_peft_model(model, lora_config)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaFactory\Lib\site-packages\peft\mapping.py", line 183, in get_peft_model
return MODEL_TYPE_TO_PEFT_MODEL_MAPPING[peft_config.task_type](
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaFactory\Lib\site-packages\peft\peft_model.py", line 1542, in __init__
super().__init__(model, peft_config, adapter_name, **kwargs)
File "D:\envs\llamaFactory\Lib\site-packages\peft\peft_model.py", line 155, in __init__
self.base_model = cls(model, {adapter_name: peft_config}, adapter_name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaFactory\Lib\site-packages\peft\tuners\lora\model.py", line 139, in __init__
super().__init__(model, config, adapter_name)
File "D:\envs\llamaFactory\Lib\site-packages\peft\tuners\tuners_utils.py", line 175, in __init__
self.inject_adapter(self.model, adapter_name)
File "D:\envs\llamaFactory\Lib\site-packages\peft\tuners\tuners_utils.py", line 431, in inject_adapter
self._create_and_replace(peft_config, adapter_name, target, target_name, parent, current_key=key)
File "D:\envs\llamaFactory\Lib\site-packages\peft\tuners\lora\model.py", line 224, in _create_and_replace
new_module = self._create_new_module(lora_config, adapter_name, target, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaFactory\Lib\site-packages\peft\tuners\lora\model.py", line 340, in _create_new_module
new_module = dispatcher(target, adapter_name, lora_config=lora_config, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\envs\llamaFactory\Lib\site-packages\peft\tuners\lora\bnb.py", line 273, in dispatch_bnb_8bit
"memory_efficient_backward": target.state.memory_efficient_backward,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'MatmulLtState' object has no attribute 'memory_efficient_backward'
peft库与LLaMA-Factory之间的兼容性问题,具体表现为MatmulLtState对象缺少memory_efficient_backward属性。这个问题通常发生在库版本不匹配或代码更新后未同步适配的情况下。
我的版本
(llamaFactory) PS D:\Program Files\python\PycharmProjects\AiStudyProject\demo07\LLaMA-Factory> python -c "import llamafactory; print(llamafactory.__version__)"
0.9.3.dev0
该本版不稳定,尝试以下稳定版本组合
pip install llamafactory==0.9.2 peft==0.12.0 transformers==4.49.0
再次安装
pip install bitsandbytes==0.43.3
pip install flash-attention-2
不在报错,版本兼容问题真的头大,毕竟目前市面上微调环境都是测试环境
五、什么是GGUF
GGUF 格式的全名为(GPT-Generated Unified Format),提到GGUF 就不得不提到它的前身GGML(GPT-GeneratedModel
Language)。GGML 是专门为了机器学习设计的张量库,最早可以追溯到 2022/10。其目的是为了有一个单文件共享的格式,并且易于在不同架构的 GPU 和CPU 上进行推理。但在后续的开发中,遇到了灵活性不足、相容性及难以维护的问题。
为什么要转换GGUF 格式
在传统的 Deep Learning Model 开发中大多使用 PyTorch 来进行开发,但因为在部署时会面临相依 Lirbrary 太多、版本管理的问题于才有了 GGML、GGMF、GGJT 等格式,而在开源社群不停的迭代后 GGUF 就诞生了。
GGUF 实际上是基于 GGJT 的格式进行优化的,并解决了 GGML 当初面临的问题,包括:
1)可扩展性:轻松为 GGML 架构下的工具添加新功能,或者向 GGUF 模型添加新 Feature,不会破坏与现有模型的兼容性。
2)对 mmap(内存映射)的兼容性:该模型可以使用 mmap 进行加载(原理解析可见参考),实现快速载入和存储。(从GGJT开始导入,可参考 GitHub)
3)易于使用:模型可以使用少量代码轻松加载和存储,无需依赖的 Library,同时对于不同编程语言支持程度也高。
4)模型信息完整:加载模型所需的所有信息都包含在模型文件中,不需要额外编写设置文件。
5)有利于模型量化:GGUF 支持模型量化(4 位、8 位、F16),在 GPU 变得越来越昂贵的情况下,节省vRAM成本也非常重要。
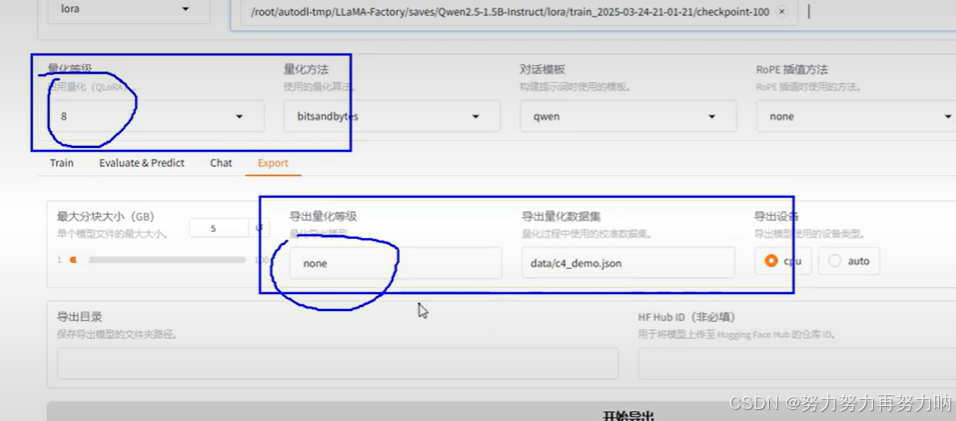
量化等级和导出量化等级并没有直接关系
六、大模型转换为 GGUF(linux环境)
1、将hf模型转换为GGUF
1.1 需要用llama.cpp仓库的convert_hf_to_gguf.py脚本来转换
git clone https://github.com/ggerganov/llama.cpp.git
pip install -r llama.cpp/requirements.txt
1.2 执行转换
# 如果不量化,保留模型的效果
python llama.cpp/convert_hf_to_gguf.py ./Meta-Llama-3-8B-Instruct --outtype f16
--verbose --outfile Meta-Llama-3-8B-Instruct-gguf.gguf
# 如果需要量化(加速并有损效果),直接执行下面脚本就可以
python llama.cpp/convert_hf_to_gguf.py ./Meta-Llama-3-8B-Instruct --outtype
q8_0 --verbose --outfile Meta-Llama-3-8B-Instruct-gguf_q8_0.gguf
这里--outtype是输出类型,代表含义:
q2_k:特定张量(Tensor)采用较高的精度设置,而其他的则保持基础级别。
q3_k_l、q3_k_m、q3_k_s:这些变体在不同张量上使用不同级别的精度,从而达到性能和效率的平衡。
q4_0:这是最初的量化方案,使用 4 位精度。
q4_1 和 q4_k_m、q4_k_s:这些提供了不同程度的准确性和推理速度,适合需要平衡资源使用的场景。
q5_0、q5_1、q5_k_m、q5_k_s:这些版本在保证更高准确度的同时,会使用更多的资源并且推理速度较
慢。
q6_k 和 q8_0:这些提供了最高的精度,但是因为高资源消耗和慢速度,可能不适合所有用户。
fp16 和 f32: 不量化,保留原始精度。
1.3 转换后的模型
2. 使用ollama运行gguf
2.1 安装ollama
curl -fsSL https://ollama.com/install.sh | sh
2.2 启动ollama服务
ollama serve
2.3 创建ModelFile
复制模型路径,创建名为“ModelFile”的meta文件,内容如下
#GGUF文件路径
FROM /root/autodl-tmp/Llama3-8B/LLM-Research/Meta-Llama-3-8B-Instruct-gguf8.gguf
2.4 创建自定义模型
使用ollama create命令创建自定义模型
ollama create qwen2.5-1.5B-Instruct --file ./ModelFile
ollama create qwen2.5-1.5B-Instruct-q8 --file ./ModelFile
2.5 运行模型:
ollama run qwen2.5-1.5B-Instruct:latest
ollama run qwen2.5-1.5B-Instruct-q8:latest
七、大模型转换为 GGUF(windows环境)
1、将hf模型转换为GGUF
1.1 需要用llama.cpp仓库的convert_hf_to_gguf.py脚本来转换
git clone https://github.com/ggerganov/llama.cpp.git
### 需要cd进入到llama.cpp/requirements.txt目录,然后在安装
pip install -r llama.cpp/requirements.txt
1.2 执行转换
# 如果不量化,保留模型的效果
python "D:\Program Files\python\PycharmProjects\AiStudyProject\demo07\llama.cpp\convert_hf_to_gguf.py" "D:\Program Files\python\PycharmProjects\AiStudyProject\demo07\models\Qwen\Qwen2___5-1___5B-Instruct-merge" --outtype f16 --verbose --outfile "D:\Program Files\python\PycharmProjects\AiStudyProject\demo07\models\Qwen\Qwen2___5-1___5B-Instruct-merge-gguf.gguf"
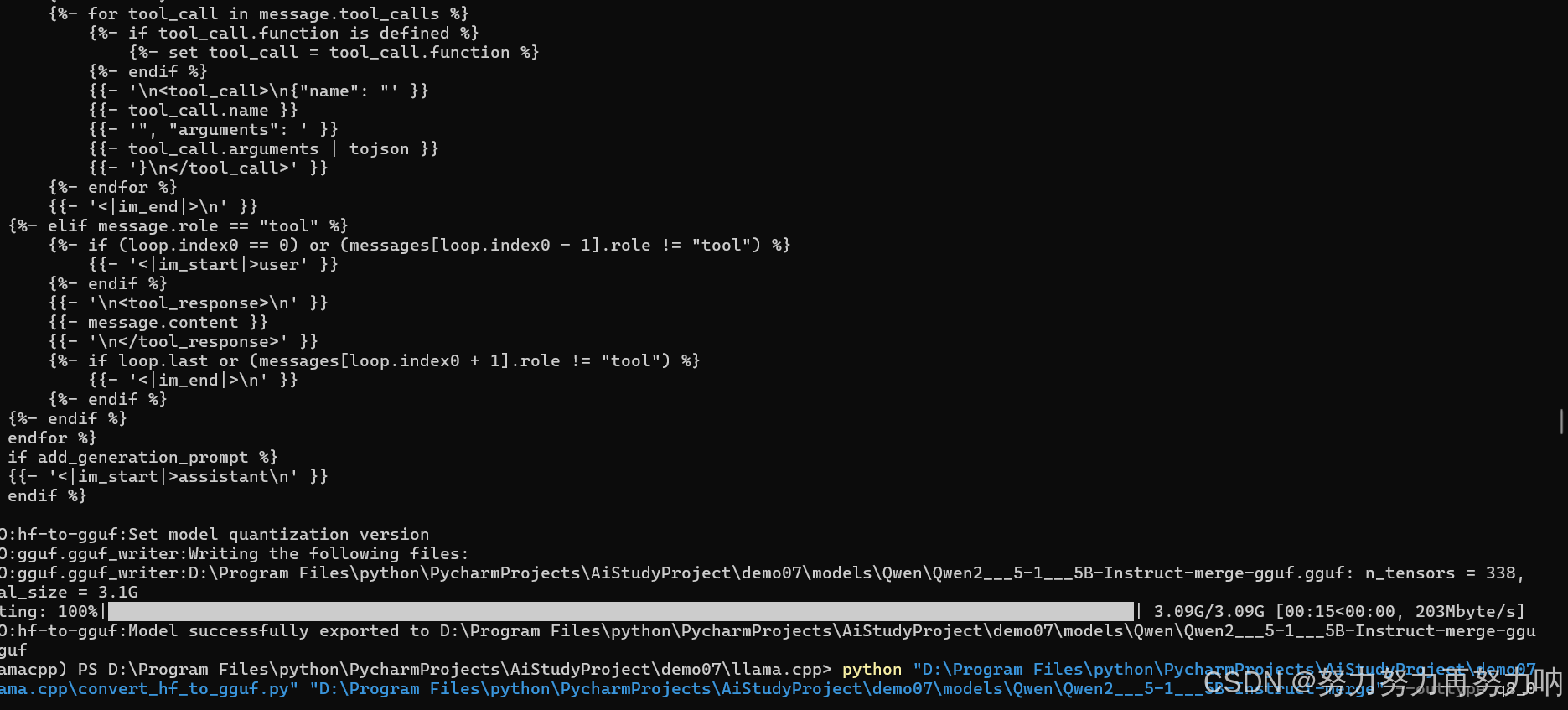
# 如果需要量化(加速并有损效果),直接执行下面脚本就可以
python llama.cpp/convert_hf_to_gguf.py ./Meta-Llama-3-8B-Instruct --outtype
q8_0 --verbose --outfile Meta-Llama-3-8B-Instruct-gguf_q8_0.gguf
python "D:\Program Files\python\PycharmProjects\AiStudyProject\demo07\llama.cpp\convert_hf_to_gguf.py" "D:\Program Files\python\PycharmProjects\AiStudyProject\demo07\models\Qwen\Qwen2___5-1___5B-Instruct-merge" --outtype q8_0 --verbose --outfile "D:\Program Files\python\PycharmProjects\AiStudyProject\demo07\models\Qwen\Qwen2___5-1___5B-Instruct-merge-ggufq8.gguf"
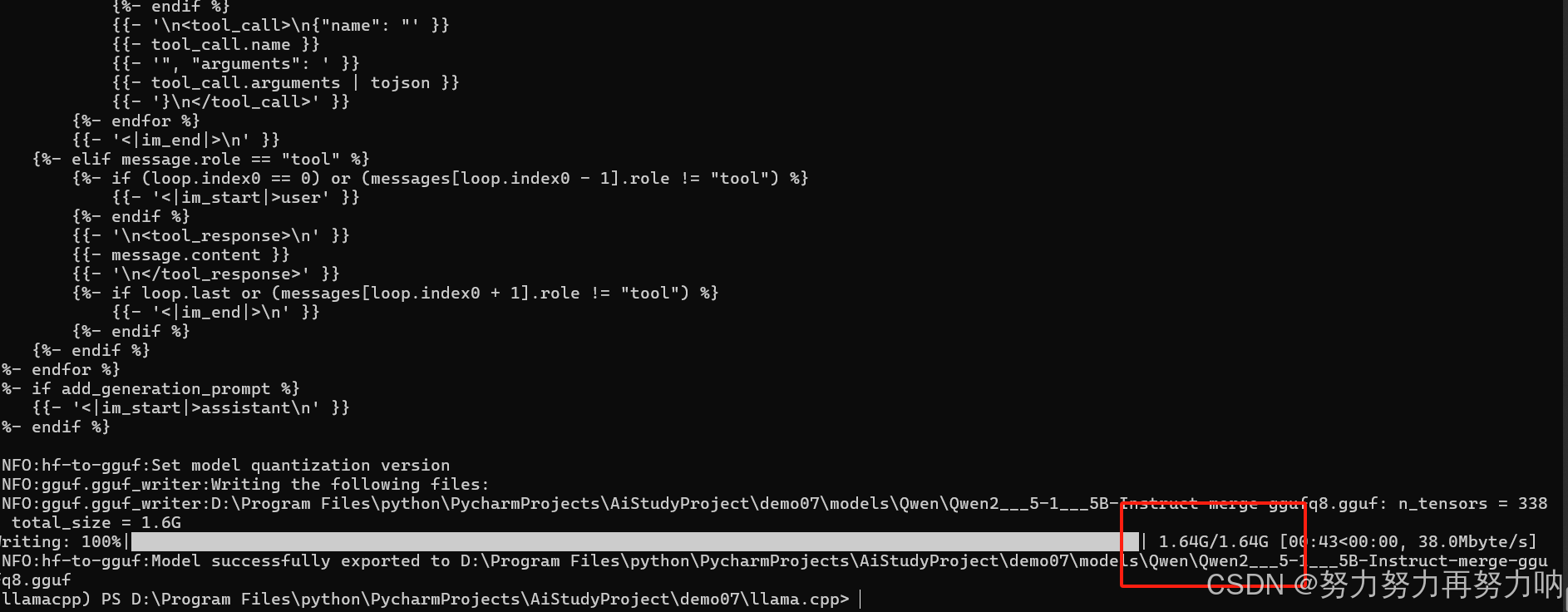
这里--outtype是输出类型,代表含义:
q2_k:特定张量(Tensor)采用较高的精度设置,而其他的则保持基础级别。
q3_k_l、q3_k_m、q3_k_s:这些变体在不同张量上使用不同级别的精度,从而达到性能和效率的平衡。
q4_0:这是最初的量化方案,使用 4 位精度。
q4_1 和 q4_k_m、q4_k_s:这些提供了不同程度的准确性和推理速度,适合需要平衡资源使用的场景。
q5_0、q5_1、q5_k_m、q5_k_s:这些版本在保证更高准确度的同时,会使用更多的资源并且推理速度较
慢。
q6_k 和 q8_0:这些提供了最高的精度,但是因为高资源消耗和慢速度,可能不适合所有用户。
fp16 和 f32: 不量化,保留原始精度。
1.3 转换后的模型
2. 使用ollama运行gguf
官网下载安装就行
2.2 启动ollama服务
双击就可以了
2.3 创建ModelFile
复制模型路径,在本地创建名为“ModelFile”的meta文件,内容如下
#GGUF文件路径
FROM "D:\Program Files\python\PycharmProjects\AiStudyProject\demo07\models\Qwen\Qwen2___5-1___5B-Instruct-merge-gguf.gguf"
2.4 创建自定义模型
使用ollama create命令创建自定义模型
ollama create qwen2.5-1.5B-Instruct --file "D:/Program Files/python/PycharmProjects/AiStudyProject/demo07/ModelFile"
如下图安装好了不量化的模型
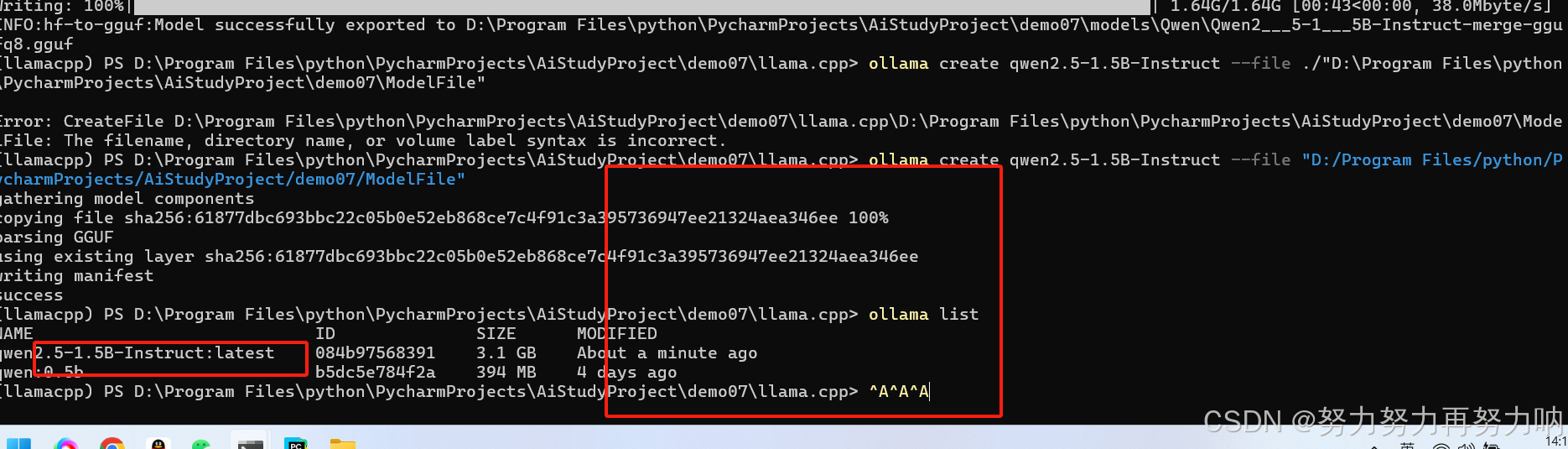
量化的模型
ollama create qwen2.5-1.5B-Instruct-q8 --file "D:/Program Files/python/PycharmProjects/AiStudyProject/demo07/ModelFile"

同样查看一下

2.5 运行模型:
ollama run qwen2.5-1.5B-Instruct:latest
ollama run qwen2.5-1.5B-Instruct-q8:latest
2.6运行open-webui看效果
如图我们自己训练的大模型就有了



















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









