






1.安装LLaMA-Factory
先在github上拉取项目代码
https://github.com/hiyouga/LLaMA-Factory.git 进入项目目录
cd LLaMA-Factory 创建虚拟环境
conda create -n factory python=3.11 下载安装包
pip install -e ".[torch,metrics]" 2.启动 LLaMA-Factory前端页面
llamafactory-cli webui 这里可能会报错,直接重新创建虚拟环境,按照流程重新安装:
RuntimeError: Failed to import trl.trainer.dpo_trainer because of the following error (look up to see its traceback):
cannot import name 'log' from 'torch.distributed.elastic.agent.server.api' (/opt/conda/lib/python3.10/site-packages/torch/distributed/elastic/agent/server/api.py)3.训练参数设置
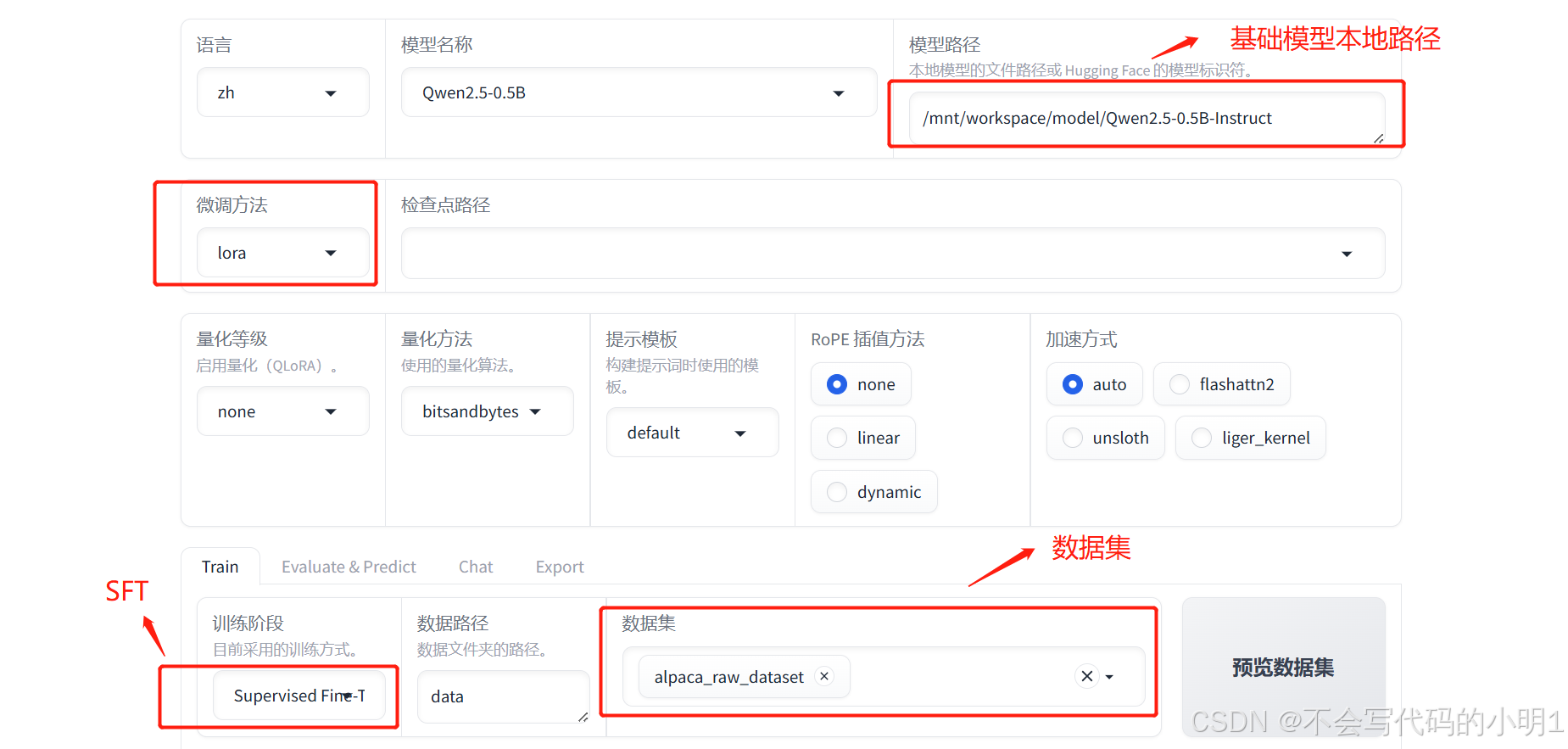 设置完成后点击开始
设置完成后点击开始
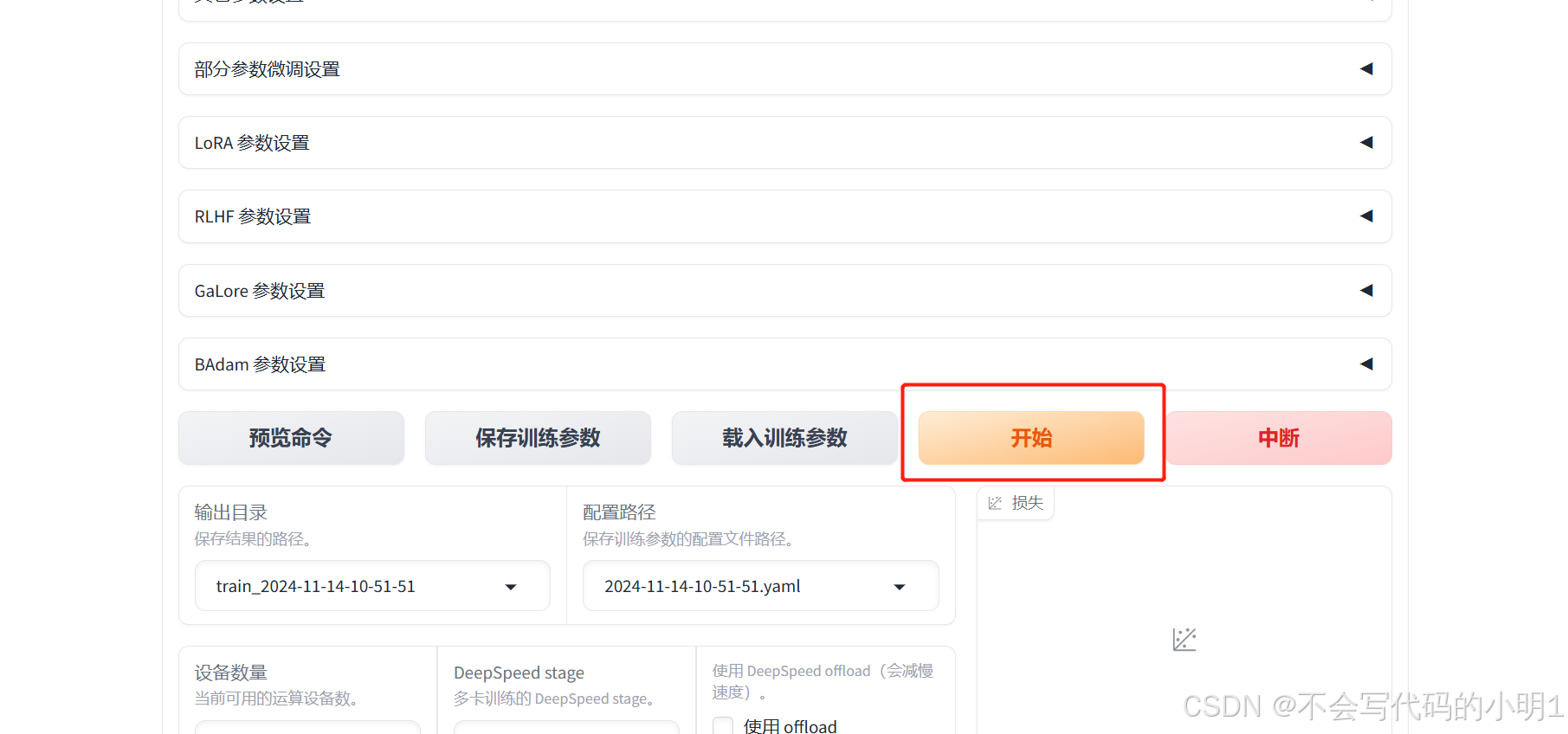
训练正常开始
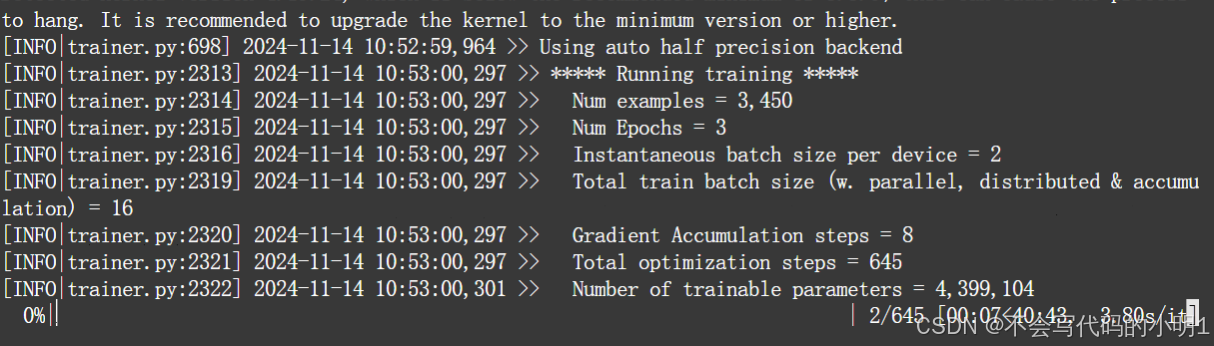
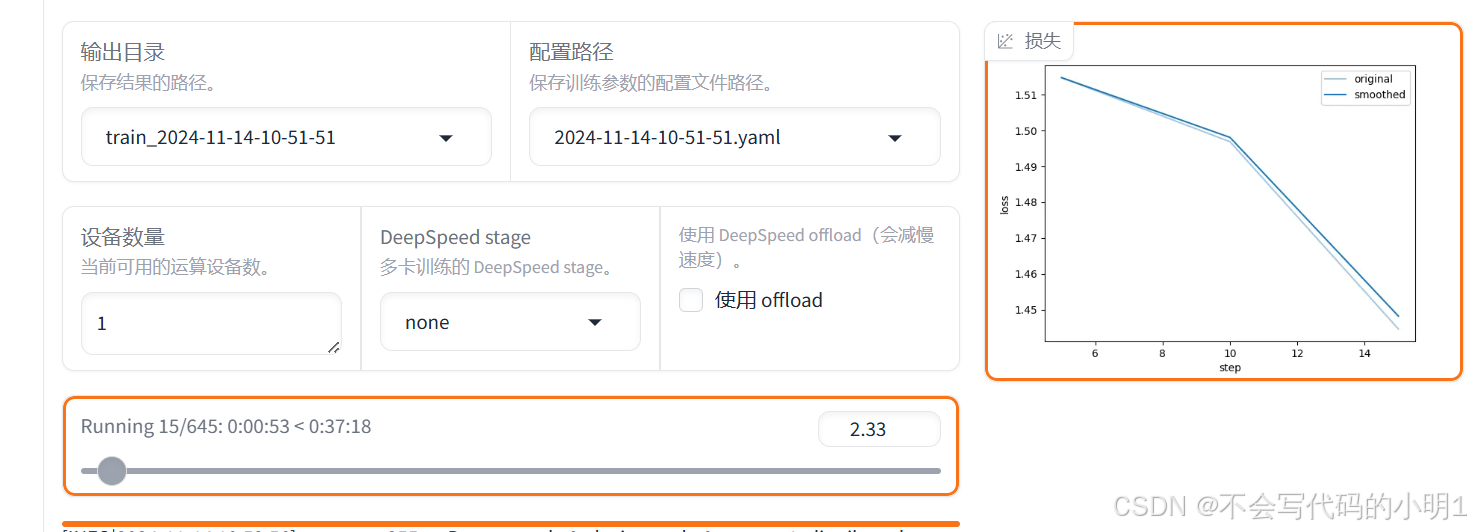
训练过程中,损失函数可以实现可视化
4.推理
采用lora动态合并的方式,会加载基础模型并应用 LoRA 微调适配器,从而实现微调后的模型效果。
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat
--model_name_or_path /model/Qwen2.5-0.5B-Instruct/
--adapter_name_or_path /LLaMA-Factory/LLaMA-Factory/saves/Qwen2.5-0.5B/lora/train_2024-11-13-16-17-06/checkpoint-186
--template qwen推理效果正常
 5.Lora权重合并
5.Lora权重合并
进入Lora合并的yaml文件夹下:
cd LLaMA-Factory/LLaMA-Factory/examples/merge_lora新建一个qwen2.5_lora_sft.yaml文件,仿照项目中的llama3_lora_sft.yaml,创建合并的yaml文件
### model
model_name_or_path: /model/Qwen2.5-0.5B-Instruct #基础模型路径
adapter_name_or_path: /LLaMA-Factory/LLaMA-Factory/saves/Qwen2.5-0.5B/lora/train_2024-11-14-09-03-29/checkpoint-321 #微调保存的Lora权重路径
template: qwen
finetuning_type: lora
### export
export_dir: /model/Qwen2.5-0.5B-merge #合并后模型文件导出路径
export_size: 2
export_device: cpu
export_legacy_format: false进入到LLaMA-Factory根目录下,执行合并命令
llamafactory-cli export examples/merge_lora/qwen2.5_lora_sft.yaml推理测试
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat
--model_name_or_path /model/Qwen2.5-0.5B-merge
--template qwen有一个小问题,实验采用的是刑法instruct数据集,发现采用上面的动态lora合并推理效果好像更好,有了解的朋友还请帮忙解答,感谢!


















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









