






cityscapes数据集内容
训练模型的时候下载了cityscapes里的disparity、gtFine和leftImg8bit。
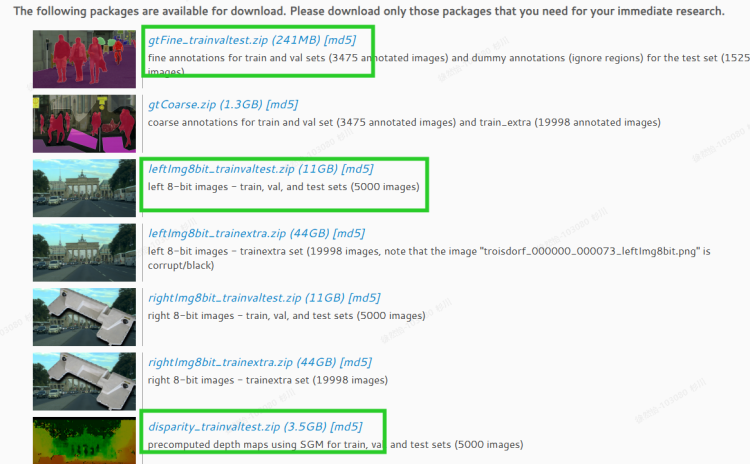
共5000张图片。2975张训练,500张验证,1525test。每个目录下都有train、test和val的子目录,这些子目录下又有一些城市名命名的子目录。train下有18个子文件夹对应德国的16个城市,法国一个城市和瑞士一个城市。train集总共有2975张png格式的大小为2048 x 1024的0-255的RGB图片。val下有3个子文件夹对应德国的3个城市。test下有6个子文件夹对应德国的6个城市。
对于disparity目录,里面放的都是深度图片;对于leftImg8bit里面放的都是原图片;对于gtFine中train目录下含有以下类型的文件:

文件的命名规则:

模型在训练的时候用到了哪些数据?
在train.py文件中加载并使用的是train_loader和val_loader。
self.train_loader, self.val_loader, self.test_loader, self.nclass = make_data_loader(args, **kwargs)
train.py中的make_data_loader()在dataloader中的__init__.py中:
def make_data_loader(args, **kwargs):
if args.dataset == 'cityscapes':
train_set = cityscapes.CityscapesSegmentation(args, split='train')
val_set = cityscapes.CityscapesSegmentation(args, split='val')
test_set = cityscapes.CityscapesSegmentation(args, split='test')
num_class = train_set.NUM_CLASSES
train_loader = DataLoader(train_set, batch_size=args.batch_size, shuffle=True, **kwargs)
val_loader = DataLoader(val_set, batch_size=args.val_batch_size, shuffle=False, **kwargs)
test_loader = DataLoader(test_set, batch_size=args.test_batch_size, shuffle=False, **kwargs)
return train_loader, val_loader, test_loader, num_class
cityscapes.py中的CityscapesSegmentation():
self.images_base = os.path.join(self.root, 'leftImg8bit', self.split)
self.disparities_base = os.path.join(self.root, 'disparity', self.split)
self.annotations_base = os.path.join(self.root, 'gtFine', self.split)
self.images[split] = self.recursive_glob(rootdir=self.images_base, suffix='.png')
self.images[split].sort()
self.disparities[split] = self.recursive_glob(rootdir=self.disparities_base, suffix='.png')
self.disparities[split].sort()
self.labels[split] = self.recursive_glob(rootdir=self.annotations_base, suffix='labelTrainIds.png')
self.labels[split].sort()
从代码中可以看到从leftImg8bit读取原图片,从disparity读取深度图片,从gtFine读取标签图片。其中标签图片是灰度图,灰度值就是种类对应的标签值。
所以制作自己的数据集需要原RGB图片、深度图片、标签图片。如何得到标签图片?cityscapes提供了标注工具获得josn文件,再将josn文件转为labelTrainIds.png。
如何标注数据得到标签图片
1.可以利用github上提供的标注工具
2.也可以利用labelme标注
这里选择labelme,创建文件夹images,里面放rgb图片和label.txt(里面放标签),再创建文件夹labels,把标注好的json文件存在这里。
标注的时候点物体的轮廓,点回到第一个点的时候形成闭合区域,弹出对话框选择种类。

得到josn文件后,要进行一下处理。因为labelme生成的josn和原数据集的josn并不一样。一种方法是修改生成的josn文件,一种方法是修改原代码。为了以后更方便,不用标注过后再进行一次json处理,这里直接修改源代码。主要修改对应的key值,目录地址。
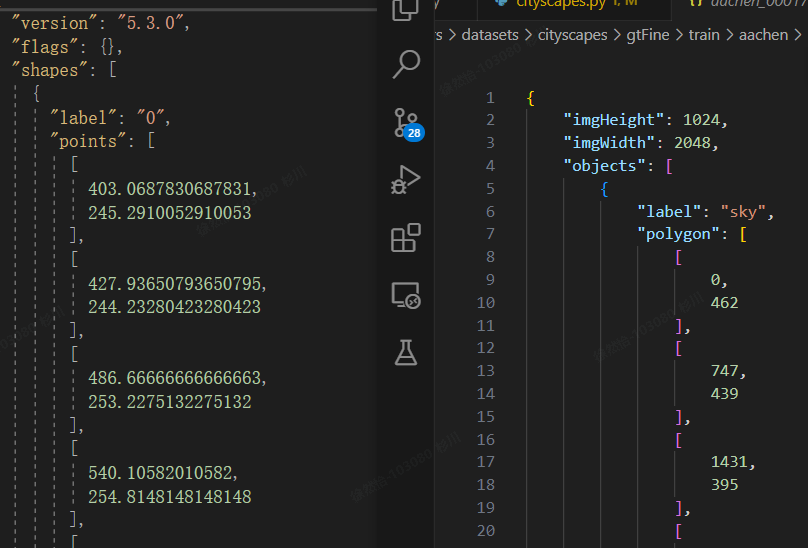
利用citscapesscripts生成标签图片。先修改/helper/labels.py中的标签,然后把数据集的目录给/preparation/createTrainIdLabelImgs.py,生成标签图片。标注了两张图片得到json测试得到如下结果:


为更高效的标注可以先试用分割模型输出分割结果josn文件,然后人为进行修正即可。















 4616
4616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









