







Part 4-1 : 特征工程
现在开始数据挖掘中最玄妙也是最重要的部分:特征工程(Feature Engineering)。
初学机器学习,一般只是对此概念及相关内涵有所了解,此处试图以实践性的角度,详细阐述特征工程。引用一句老掉牙的话,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
好特征即使使用一般的模型,也能得到很好的效果!好特征的灵活性在于它允许你可以选择不复杂的模型,同时,运行速度也更快,也更容易理解和维护。好的特征,即使参数不是最优解,模型性能也能表现很好,因此,不需要太多时间去寻找最优参数,大大的降低了模型的复杂度,使模型趋向简单。模型的性能包括模型的效果,执行的效率及模型的可解释性。特征工程的最终目的就是提升模型的性能。
许多课程中将前述part-3的数据分析与预处理合并为特征工程,无论如何,整体的思路和流程是这样的,我们要将原始数据处理成格式化的矩阵喂给模型,前面part-3将数据整理得漂亮了一些,接下来特征工程是为了将“数据”变为“特征”。说到“数据”,它还是一些有意义的数值,有含义,有量纲,而“特征"则可以认为仅仅是一些数字了,模型需要有用的特征来分类和预测,但是它并不理解它是否有含义,在这个精准医疗的比赛中,可以看到大佬们创造出了各种各样的特征提高了模型的准确度,这些特征大多很”奇葩“,但是只要是有用的,我们就要使用,学习构造这样的特征的一套理论。
这一部分中,我们首先介绍特征工程那一套理论,包括一些有效的方法、一套实践起来比较有效的流程,然后贴出鄙人比赛的代码作为示例,并看一下一些大佬的特征的样子拓宽思路。这一部分会引用许多网上的内容,文中会给出几个链接供详细学习~
1)特征工程的流程
推荐知乎上这一回答,也可看对应的博文:
特征工程到底是什么? - 城东的回答 - 知乎
https://www.zhihu.com/question/29316149/answer/110159647
另外知乎上一些其他人的回答也不错往下翻。建议结合大佬们的理解阅读,多看一些加深理解。大佬们的基本框架就是这样的:
预处理: 无量纲化,对定量特征二值化,对定性特征哑编码,数据变换
特征选择: Filter(过滤)、Wrapper(包裹)、Embedded(嵌入)
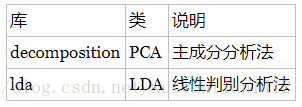
降维: 主成分分析法(PCA)、线性判别分析法(LDA)
① 无量纲化:数据的标准归一化,对于后续的训练速度和模型的准确性有很大作用,不再赘述(基础知识就不啰嗦了),都可以用sklearn包实现,选择合适的方法也是一门学问。
② 编码:分为二值化编码,以及著名的独热(one-hot)编码又称哑编码。处理的对象是我们上游工作流程得到的DF对象,字段内容一般是,非数值型(文本)、离散数值、连续型数值。此中设计到不少实践性很强的内容,略述如下。
非数值型的特征此处要进行处理了,模型不能识别非数字的东西,此处一般指的是文字型字段。例如性别{‘男’,‘女’},可以设置为{‘男’:0,‘女’:1},这不是二值化处理。需要说明的是,对于性别这一类的在DataFrame对象中可以用map函数进行处理,十分方便,具体可见下面的代码。除了文字型字段,若是离散的、大小无意义的数字的字段,也需独热处理。在面对大量独热编码时,一个一个用map函数十分不便,而用sklearn上的OneHotEncoder() 会将DF对象变为数组,无法后续处理,也不便于观察特征的名字(当然你可以把这一步放到最后),同样sklearn的无量纲化操作也是这样,破坏美丽的DF数据结构。
此处,需要传授一些人生经验,不要听信sklearn那些预处理工具。无量纲化直接用pandas自带的统计量进行计算,哑编码用pd.get_dummies(),十分方便。
对于连续值的编码,即离散化处理,连续值本来直接送给模型就很好,如果有必要简化、编码,可以将连续值分段,再参考独热编码。比如年龄字段可以这样处理,但是本题没有这么做;具体的年龄数值很有用处,年龄的相关性极大,但是又不能说50岁就是25岁的2倍,编码处理也许也有帮助。
③ 特征构造
数据变换,明显也使得数据无量纲,需要注意的是数据变换的本质上是什么呢?没错,实际上就是构造新特征。sklearn里实现了PolynomialFeatures 以及 FunctionTransformer,一个是多项式特征,一个是函数变换。
特征组合,基本利用简单的四则运算,但是一般基于对问题专业知识的理解,对现有几个字段加以组合生成新的特征。
这个表格非常明了:
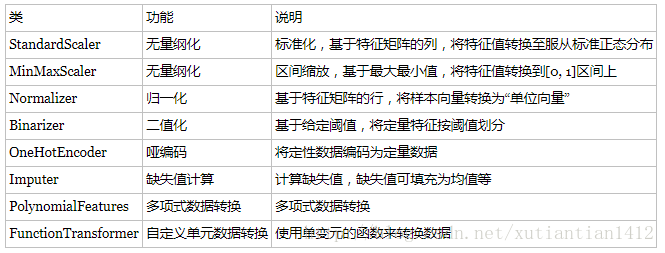
此处对特征构造总结一下。编码(数值规约)是对字段内容(离散型、文本)的特征化,而数据变换则是创造新的特征,方法除了多项式的,函数变换的,四则运算也是最基本的手段。此时,我们得到的‘数据’更像是一些高维的‘特征’了,也许我们只有40个字段,经过这个阶段的处理可以有1000个特征(因为各种函数变换,你想有多少特征都可以)。这就是这一阶段的目的,但是没有特征筛选的支撑这一工作也毫无意义,喂过多的特征会使模型准确性下降。下面我们认识一下特征选择。
特征选择的方法各种资料上说了一大堆,一般分为过滤、包裹、嵌入,鄙人根据自己理解,作如下分类:
① 基于指标的筛选:
大佬的文章中介绍了方差选择法(VarianceThreshold)、相关系数法(pearsonr)、卡方检验法(chi2)和互信息法(MINE),辅助使用SelectKBest()工具依据每个特征的指标选出K个最佳特征,相关系数只能评价线性关系,而卡方检验和互信息可以找到更多有用的特征,鄙人在比赛中辅助使用了互信息和相关系数,并没有完整的应用流程,还需在实践中加强。
有时间鄙人会扩展一下这部分的内容,在此先略过。。
② 基于模型的筛选:
特征递归消除: RFE(estimator, n_features_to_select, step, estimator_params, verbose)
嵌入式方法,使用SelectFromModel(),模型一般是L1正则化的逻辑回归模型及基于树的模型如GBDT、RF,具体使用参考大佬的文章中的例子,更多的还是自己亲自在实践中使用。
要注意SelectFromModel(LogisticRegression(penalty="l1", C=0.1))这样的是不稳定的,这里向大家推荐sklearn.linear_model的两个方法:
随机lasso回归 RandomizedLasso(alpha='aic', scaling=.5, sample_fraction=.75,
n_resampling=200, selection_threshold=.25,
fit_intercept=True, verbose=False, normalize=True, precompute='auto',
max_iter=500, eps=np.finfo(np.float).eps, random_state=None,
n_jobs=1, pre_dispatch='3*n_jobs', memory=None)
随机逻辑回归 RandomizedLogisticRegression(C=1, scaling=.5, sample_fraction=.75,
n_resampling=200, selection_threshold=.25, tol=1e-3,
fit_intercept=True, verbose=False, normalize=True,
random_state=None, n_jobs=1, pre_dispatch='3*n_jobs', memory=None)
原型是这样的,相当于线性模型的集成算法,可以稳定的选出重要的模型,具体使用不妨查查资料、看看源码。另外,火热的深度学习也可以用来筛选特征,有兴趣的可以去查查~
③ 降维:当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。L1的正则也是一种降维。PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。与筛选不同的是,筛选是舍弃掉某些特征、保留一些特征,而降维后,留下的维度已不再是原来的任一特征,类似于特征之间作了复杂的变换和函数运算,因此降维的过程是新特征生成。但是将降维归到特征选择中,大概因为这一般是调用模型前的最后一步了,一般还是认为这是在筛选特征而不是构造特征。
总结如下:(加上随机lasso)

特征工程流程归纳:
无量纲化(标准归一化)→ 编码 → 特征构造 → 特征筛选 → 降维(如果维度大)
实际上,特征构造和特征选择是反复迭代的关系。上面知乎的回答中的有一位大佬是这样总结的:

还是知乎那个问题里,数据分析jacky 的回答也不错,理论很系统,实例也很丰富,建议翻到下面看一下。他将流程归纳为数据处理、特征选择、维度压缩。
特征工程到底是什么? - 数据分析jacky的回答 - 知乎
https://www.zhihu.com/question/29316149/answer/252391239
好了,特征工程的流程的理论部分就是这样了,给出了许多链接,还是多看看,本文就不搬运了。下面一节会贴出大赛的特征工程的代码供交流学习进步。















 1471
1471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









