






文章目录
- 前言:为什么我要使用mongodb
- 一.mongodb的安装:使用docker安装
- 二.mongodb的核心概念
- 三. 库的相关操作
- 四. 集合的相关操作
- 五. 文档的相关操作
- 六. 文档的查询操作:
- 七.$type操作符
- 八. mongo中的索引
- 九. 聚合查询
- 十. springboot整合mongo
- 1.引入依赖:
- 2.编写配置文件:
- 3.MongoTemplate的api操作
- 创建集合:mongoTemplate.createCollection("集合名");
- 判断某个集合在库中是否已经存在:mongoTemplate.collectionExists("集合名");
- 删除一个集合:mongoTemplate.dropCollection("集合名");
- spring-boot-starter-data-mongodb中的注解:
- @Document:必须写在类上
- @Id:可以写在成员变量或方法上
- @Field:可以写在成员变量或方法上
- @Transient:可以写在成员变量或方法上
- MongoTemplate操作文档
- 保存文档 与 插入文档:save函数,insert函数
- 关于save函数跟insert函数的注意事项:
- 查询所有文档:findAll函数
- 根据下划线id查询文档:findById函数
- 条件查询:find函数
- 4.使用mql语句查询
- 5.文档的修改
- 6.文档的删除
- 十一. 副本集
前言:为什么我要使用mongodb
一.mongodb的安装:使用docker安装
先把镜像pull下来,这里我使用的5.0.5版本
docker pull mongo:5.0.5
再在root目录下创建一个/dockerdata/mongodb/data,所有安装在docker中的容器的挂载目录都统一放在dockerdata文件夹中,/mongodb/data专门用于挂载mongodb容器的数据目录;
注意:在linux中root目录就是~目录;
启动容器
这里要注意:
①mongo容器中的数据存在目录在/data目录下的db目录;
②mongodb的默认端口是27017
③-e MONGO_INITDB_ROOT_USERNAME=root,-e MONGO_INITDB_ROOT_PASSWORD=115409表示给mongo中的保留库:admin库,设置账户密码;
④最后的 mongod --auth我不知道是啥意思,后面我再提升一下docker方面的知识;
docker run -d --restart=always --name mongo --privileged -p 27017:27017 -v /root/dockerdata/mongodb/data:/data/db -e MONGO_INITDB_ROOT_USERNAME=root -e MONGO_INITDB_ROOT_PASSWORD=115409 mongo:5.0.5 mongod --auth
进入mongodb容器,为mongo的每个库设置账户密码
docker exec -it mongo bash
mongo --version
mongo
我们现在只是进入了mongo容器,还没有连接它;
mongo --version
进入后可以使用mongo --version查看mongo的版本
mongo
进入后我们再使用mongo命令来连接mongodb,但是用这种命令进行连接确实能连接成功,但是你根本操作不了,不能创建集合,不能创建库,啥都干不了,因为你没有登录;
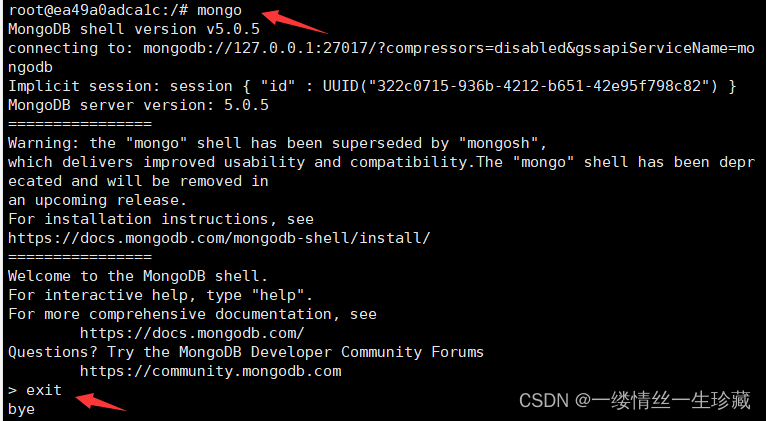
所以你一定要使用下面这个命令来启动:–authenticationDatabase "admin"表示你要进行登录认证的库是admin这个库;
mongo --port 27017 -u "root" -p "115409" --authenticationDatabase "admin"
登录进去后,我们能看到还是处于test这个保留库中:
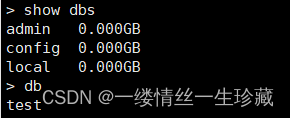
然后我们再切换到admin这个库,再使用db.auth()命令进行认证一次(这里为啥还要认证一次?为了保险吧,我之前没认证就老是提示报错,但这个问题是小问题,我就没有反复测试);
认证成功后,我们再新建一个库:mytestdb;
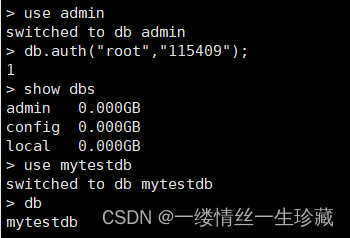
注意:为什么我要新建一个库mytestdb?
这是因为我们之前的操作,设置的账户密码是属于admin这个保留库的密码,test库,或者其他库的账户密码是都没有设置,mongo不像mysql那样所有库共用一个账户密码,mongo是一个库一个密码,你不先对库的账户密码进行设置的话,就算你创建了这个库,你也是操作不了它的;所以我要新建一个库mytestdb,然后演示对其创建账户密码的过程;
db.createUser({user:'root',pwd:'115409',roles:[{role:"readWrite",db:"mytestdb"}]});
我们再在mytestdb中使用db.createUser命令来为mytestdb这个库创建一个用户,用户名为root,密码为115409,并且为其分配了一个角色:readWrite,表示这个用户可以对mytestdb库进行读写操作,并且使用db字段来明确表示这个用户就是创建给mytestdb这个库的;
docker exec -it mongo mongo mytestdb
然后我们再连续使用两个exit命令退出一下容器,第一个exit命令是退出当前库,第二个exit是退出当前容器:
然后我们再进入mongo容器,这一次进入,就把mongo的启动命令mongo带上了,同时带上了库名mytestdb,表示我进入mongo容器后,立即就将mongo启动起来,并且连接到mytestdb这个库中,这样,你进入mongo后,所在的库就不是test而是mytestdb了;
db.auth("root","115409");
进入后,我们直接用auth函数进行验证,可以看到验证通过;

我们再创建一个集合,剩下的就随便我们玩儿了;

这样,我们就完成了对一个库的账户密码设置,显然这比较麻烦;
二.mongodb的核心概念
三. 库的相关操作
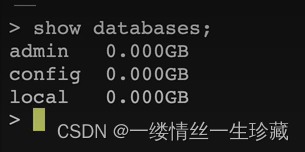
查看所有库:show databases
show databases 或者 show dbs
我们可以看到,mongodb默认会初始化三个库,就像mysql中默认也会初始化几个库一样;
创建一个库/切换一个库:use 库名
当库名不存在时,就会创建一个库,当库名存在时就会切换到这个库;
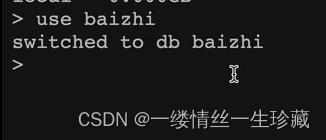
use baizhi
使用use+库名的命令会创建一个库,同时会切换到该库进行使用,switched to就表示切换到的意思;
mongodb的库的特性
注意:在mongodb中,如果你创建了一个库,但是库中没有创建任何集合,那么你使用show databases命令是查看不到该库的,也就是在mongodb中没有集合的库是默认隐藏的;

查看当前所处的库,也就是查看当前所在的位置:db
db
使用db命令可以查看当前所处是哪个库中;
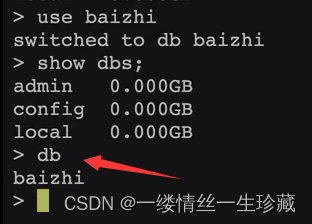
mongodb默认库test
当你登录进mongodb时,默认就会自动进入一个名为test的库中,这个库是mongodb自带的,但是里面没有任何数据,所以你使用show databases命令是显示不出来test这个库的,但是你可以使用db命令,就能看到你当前确实是在test这个库中;

删除当前库:db.dropDatabase();
删除当前所在的库,也就是说如果你要删除某个库,你首先要用use命令切换到这个库;
如果删除成功,会返回一个json格式的ok;
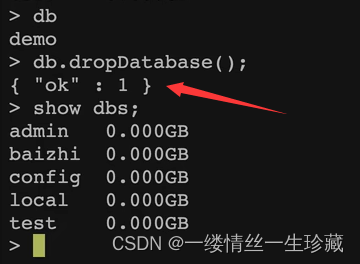
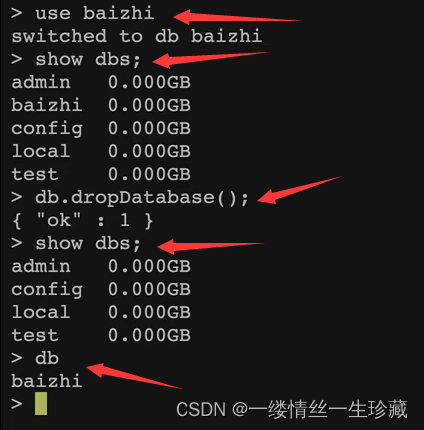
关于删除库的一个特殊的点
当你进去某个库,将该库删除后,你再使用db命令,你会发现你还在这个库中,这是mongodb跟其他库不同的点,但实际上这个库已经被删除了;
四. 集合的相关操作
查看当前库中所有的集合:show collections 或 show tables;
mongodb中的集合对应关系型数据库中table,所以也可以使用show tables来查看所有集合;
如果当前库中没有集合,那么查出来就是下图这样;

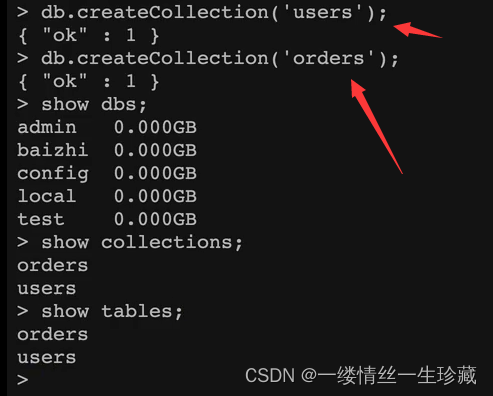
创建集合:db.createCollection(‘集合名称’,[options]);
案例:
db代表当前数据库,[options]代表当前集合的配置,选项,可写可不写,如果不写options,就代表使用默认的配置;
db.createCollection(‘users’) 代表在当前库中创建名为users的集合
options参数

案例:

集合的插入/隐式创建
插入:
db代表当前库;
db.(db点儿)中的点儿代表下一级的意思,库的下一级是集合,所以db.后面的emps就代表集合,
这个emps是我们写的一个不存在的集合名,再继续点儿insert,意思就是往emps这个集合中插入数据:数据为{name:‘编程不良人’},这里插入的数据就是json数据了;
注意:我们使用db.createCollection()时,createCollection函数中并不是填的json格式数据,这是为什么呢?
这里需要搞清楚,你创建集合名的时候,你指定名称就行了,最多再指定配置就行,集合名用一个字符串就能表示,只有往集合里面插入数据,才是传json格式进去;

隐式创建:
上面的例子就是隐式创建,因为你emps这个集合根本就不存在,你直接往emps集合中执行插入操作,那么mongodb就会自动把这个集合创建出来,这就是隐式创建,你使用db.createCollection函数就是显示创建;
注意:集合是没有修改操作的
集合的删除操作:db.集合名称.drop();调用drop函数就能删除集合
五. 文档的相关操作
文档是集合中的最小单元
BSON格式与JSON格式
JSON格式中,强制要求k必须使用双引号,v根据类型绝对是否使用双引号,但是在BSON格式中,k不用加双引号,v还是一样,而在mongodb中文档类型就默认以BSON格式进行存储,并不是严格的JSON格式,这一点需要注意;
另外你需要注意:
你往集合中插入一个BSON,那么这就是一个文档,不管这个文档中的字段有多少,就算只有一个字段,这也是一个文档;
{
name:"许海",
age:"28",
sex:"男",
}
这就是一个文档;
关于JSON格式再多啰嗦一句:
json中数组格式是下面这种写法:数组不用加大括号,直接用中括号就搞定;
{
"name":"许海",
"age":18,
"hobby":["美女","大美女","小美女"]
}
关于文档id
跟es非常类似,当你插入一条文档后,mongodb会自动给这条文档维护一个下划线id(_id),如果你指定了下划线id,比如你用_id:1,将_id指定为1,int类型是不用打双引号的,那么mongodb就会使用你指定的这个id;
往集合中插入单条文档
db代表当前库,点儿代表下一级,由于在mongo中,文档格式是采用BSON格式,所以name,age你想加双引号就加,但不加也行;
insert()表示单挑插入函数;
db.集合名称.insert({"name":"许海","age":28})
db.集合名称.insert({name:"许海",age:28})
如果插入成功则会显示:
WriteResult({"nInserted":1})
往集合中一次性插入多条文档
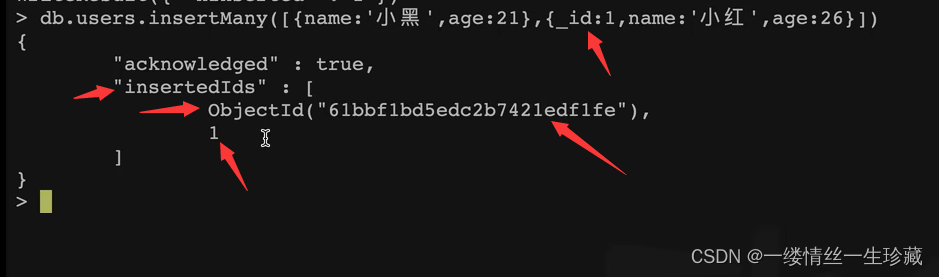
第一种批量插入的方式:使用批量插入函数insertMany();
这里解释一下:
①【中括号】中,尖括号《》括起来的document 1表示文档数组
②后面的{}大括号中的东西跟create
db.集合名称.insertMany(
[<document 1>,<document 2>,...],
{
writeConcern: 1,
ordered: true
}
)
db.集合名称.insert({name:"许海",age:28})
下图中的案例,我没有指定writeConcern与ordered的值,默认就是0和true;
同时给第二个文档指定了一个下划线id为1,这个下划线_id你写在文档的哪里都行,不一定非要在第一个字段;
如果批量插入成功,就会出现下图中的提示;
其中acknowledge:true表示插入成功
objectId表示mongodb为我们生成的下划线id(我们刚才插入了两个文档,这是给第一个文档生成的id),后面的1表示我们自己给第二个文档指定的下划线id为1,也就是说当你插入如成功后,它会把本次批量插入生成的所有文档id都返回回来;insertedIds就表示本次生成的所有文档id;
第二种批量插入的方式:insert函数也可以批量插入,你传一个数组进去就行;

以javascript脚本的方式往集合中插入多条文档
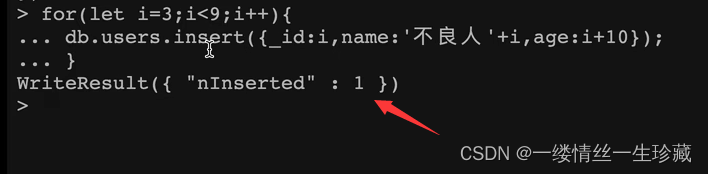
比如看下图中的for循环,我使用es6的语法,用let定义了一个变量i,然后循环往里面插入;
执行后得到的结果是:“nInserted”:1表示插入进去了一条;
但注意:虽然这里显示是只插入了一条,因为在mongo中,当你使用for循环往里面插入文档时,只会显示最后一条的结果,而不是显示整个for循环插入的结果;
注意:你要是命令行中写for循环,你写到大括号这里,你应该换行,但是你按回车就直接执行了,你该按什么换行呢?
按住shift+回车进行换行;
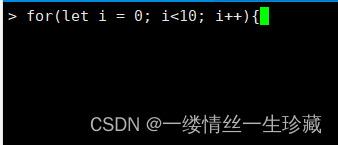
换行后就是这种效果,有三个点;
或者你直接写成一行也行,但就是不太美观;

查询集合中所有的文档;
db.集合名.find();
所以我们使用db.firstCollection.find();就能查询到我们刚才往集合firstCollection中插入的所有文档,如下图所示;

删除文档
db.集合名.remove(
<query>,
{
justOne:<boolean>,
writeConcern:<document>
}
);
删除的注意事项1:
调用remove函数即可进行删除:
①remove中有两个参数,第一个参数query表示删除条件,可以按照某个条件进行删除,这个query是一个对象属性(所以你在query条件的时候,也得使用大括号括起来),你也可以不填query,那么就是删除集合中的全部文档;
②第二个对象就是remove函数的配置对象,其中包含了justOne字段,writeConcern字段,我们可以看到justOne后面跟的是boolean,所以它的值就是布尔值;writeConcern后面跟的document类型,所以它的值就是对象类型,也就是一个json格式;
justOne为true时表示仅仅删除一条文档,默认为false,意思就是:当你按照某个条件查出来多个符合删除条件的文档,如果你justOne为true,那么就只会删除一条文档,为false就默认全删了;
writeConcern:表示删除失败时抛出的异常级别(是可选的),这个异常级别我们基本也不会去动它,所以就使用默认的即可;
删除的注意事项2:
db.集合名.remove();
如果你直接使用 db.集合名.remove()命令,那么会报错,提示remove函数needs 一个query,也就是说remove函数需要一个查询条件,我明明就想删除所有,我要啥查询条件?注意了,你要删除所有,你的查询条件要设为空,也就是传一个空的大括号进去,这是mongo的设定,没有办法

所以下面这这写法才是真正的删除集合中所有文档的正确写法:
db.集合名.remove({});
删除文档的条件如何设置?
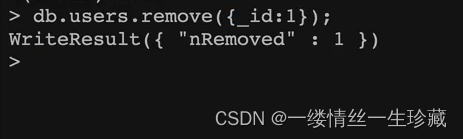
你可以按照下划线id来进行删除,比如你要删除下滑线id为1的文档,你就可以这么写:
db.集合名.remove({_id:1});
这就是删除成功了;
上面演示的是,我们以我们自定义的下划线id为条件来进行删除,再演示一下以mongo自动生成的下滑线id为条件来进行删除:
db.集合名.remove({_id:ObjectId("63c798a1d90dfd8b0e71f40a")});
k你就写_id,v你要写ObjectId(“63c798a1d90dfd8b0e71f40a”),这个v不加双引号或者单引号啊?因为ObjectId是一个函数,不用加单双引号;

注意:如果你直接把id拿出来作为v来进行删除,这样是删不掉的,必须带上ObjectId函数;
db.集合名.remove({_id:"63c798a1d90dfd8b0e71f40a"});
另外再提两句:①mongo中不区分单双引号;②你把集合中的文档都删完了,这个集合还是存在的,不会因为文档没了,集合就没了;
文档的修改操作

修改操作使用update函数,update函数中需要你传是三个参数:第一个参数query是你要根据哪些条件进行修改,第二个参数update表示你要修改哪些内容,最后一个参数是update函数的配置项;query和update参数必须要有,配置项可以没有;
注意:
①update函数中的update,你可以填对象,也可以填操作符,如美元符号,$inc…等等;你可以把update函数中的update理解为sql中update语句中的set关键字后面的内容;
②配置项讲解:
upsert:这个单词时update跟insert的结合体,是一个布尔值,为true的意思是:你在做更新操作时,如果有就进行更新,如果没有就进行插入;默认是false不开启;这个功能很蛋疼,我建议还是就默认为false就好,为true问题太多,且不实用;
multi:你通过query这个条件可能会查出来很多个符合条件的文档,当查出来多个时,你到底要我更新一条文档,还是把所有满足条件的文档都更新了?如果true就是更新所有符合条件的,为false就只更新找到的第一条记录,默认就是false;
writeConcern:也是异常级别,基本我们不会管这个字段,就让它用默认值;
修改操作中的$set关键字(引)
我现在先查出当前集合中的所有文档;
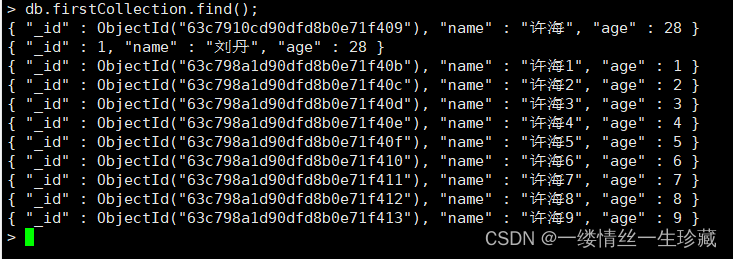
然后我再将年龄为28的文档,修改为年龄为18;
所以说update语句我就这么写:第一个{age:28}就是query,表示查询条件,第二个{age:18}就是要执行的修改内容;
意思就是:找到age等于28的文档,并将age改为18;
db.firstCollection.update({age:28},{age:18});
可以看到,执行的结果是:nMatched为1表示匹配上的有1条文档,nUpserted为0表示插入的有0条,nModified为1表示修改的有1条;

修改完成,我们再来查询看一下:结果一看,这是个大坑,update函数直接把name:'许海’这个字段干没了,只剩下了一个下划线id字段跟更新后的age字段;
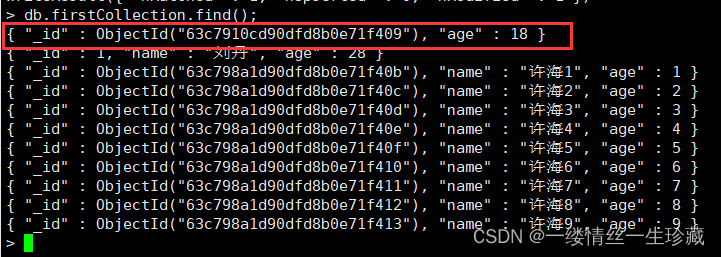
所以这里就有个机制需要讲解一下:mongo在执行update函数时,会先将这个文档原来的内容全部删掉,然后再将修改后的内容填进去,但是整个过程,对文档id不会做修改的,所以这就很蛋疼,你明明只想修改age这个字段,结果把其他字段玩儿没了;
所以就引出来我们的下一个知识点:$set关键字;
修改操作中的$set关键字(正式使用)
db.firstCollection.update({age:28},{$set:{age:18}},{multi:true});
这里我们还是将age等28的文档修改为18,在update部分,加上了$set,以其为key,以之前的修改内容{age:18}为值v;这样就可以了;
同时我加上了配置项:{multi:true},multi默认值是false,意思就是只修改找到的第一条,改为true就修改所有符合条件的;

所以说总结一下:多勒set关键字的作用就是:让你能在保留原始数据的情况下进行更新,也就是让能够做到只更新你想要更新的字段,其他字段保留原样;
六. 文档的查询操作:
文档的查询操作是重中之重,所以我们单独开一章;
查询语法:find函数
db.集合名称.find(query,projection)
db.集合名称.find(query,projection).pretty() 将查询结果进行格式美化(注意:只有文档的长度到达一定值后才会进行格式化,短的没必要格式化)
find函数有两个参数,
参数1:query,可选,表示查询条件;
参数2:projection,可选,你可以把这个参数理解为sql中的select *,sql中select如果没有指定字段名的话,那么就会把所有字段都查出来,projection的作用也一样,因为有时候我们并不像把文档的所有字段都查出来,我们只想查出部分字段的数据,projection就提供了这样一个作用,它是可选的,如果你填projection这个参数,那么默认就是查询出所有字段;
mongo中条件语句查询跟sql中的条件语句对比:

再进一步解释一下:
等于
键值对{k:v}就表示k等于v,这就是等于;
{age:18} 就表示查询条件为age等于18
小于
{age:{$lt:18}} 就表示查询条件为age小于18,lt就是less than的意思,写法就是value改成大括号包裹起来,将$lt跟具体的值都包裹起来;
这里你要注意跟{$set:{age:18}}的区别,两者写法有点小差异,$lt是跟值一起被大括号包起来,$set是没有被大括号包起来,而是单独作为一个k;
小于等于
{age:{$lte:18}}
比lt多了一个e,equals的意思,就表示age小于等于18
大于
{age:{$gt:18}}
不等于
{age:{$ne:18}}
ne就是not equals的意思
AND
db.集合名称.find({k1:v1,k2:v2,k3:{$lt:v3},...});
只要你的键值对是写在query参数中(find函数中第一个大括号包起来的键值对,就表示是find函数的query参数),用逗号隔开,就表示AND的意思;
举例:
db.集合名称.find({address:'重庆',sex:'女',legLength:{$gt:80}});
这句话的意思就是,在重庆范围内查找腿长大于80cm的女的;
关于AND的注意事项:
当你在find函数的query参数时,你写成下面这样:
db.集合名称.find({sex:'女',age:18,age:{$gt:28}});
意思就是:你要找一个年龄等于18,并且年龄还要大于28的女的,根据正常的逻辑上说,这是矛盾的,应该查不出来,但是在mongo中,如果你查询条件中同一个字段出现了两次,那么它就会以后出现的条件为准;也就说它不会以age等于18作为查询条件,而是以age大于28作为查询条件;
OR
mongo中表示or的语法为:

你需要将条件放到一个数组中,不同的条件用逗号隔开,mongo会自动在中间拼上OR,然后以$or为k,整个数组为v;
注意:数组中的每个条件要用大括号括起来;
举例:
db.集合名称.find({$or:[{age:18},{age:{$gt:28}}],sex:'女'});
意思就是给我找一个年龄要么等于18,要么年龄大于28的女的;
数组中的查询
数组中的查询,什么意思?举个例子:
我现在有一个user集合,里面有两条文档,如下图:

我现在要查询有哪些文档,爱好包含刷剧的;
可以看到hobby这个字段,值就是一个数组,这就是一个数组中的查询;
直接使用下面的语句即可:
db.user.find({hobby:"刷剧"});

这里需要注意的是:在数组中的查询,我们也是直接使用冒号来表示就行了,冒号就是等于的意思,在数组中查询的话,你可以理解为查询一个文档,只要这个文档的hobby字段包含"刷剧"就行;
模糊查询
sql中使用like关键字来实现模糊查询的,mongo不一样,是依靠正则表达式来实现模糊查询的;
举例:
> db.user.find({"name":/丹/});
这句话的意思:就是查询name字段包含丹字的文档,这里就跟sql中的%丹%非常像,但是你一定要注意,/丹/是正则表达式,你把它当成%%来用就错了,因为 如果你使用 丹/或者/丹来进行模糊查询,你就会发现会报语法错误;
另外需要注意:你要进行模糊查询的话,/丹/这里就不能加单双引号,你不能写成下面这样:
> db.user.find({"name":"丹"});
因为加单双引号的话,就代表是一个值了,而不是正则表达式,实际上正则表达式比sql中的%%更加好用,更加灵活;
$size在数组查询中的应用
> db.user.find({hobby:{$size:3}});
意思就是:在user这个集合中查询,hobby字段的数组长度为3的那些文档;这里数组长度指的是里面元素的个数
结果为:
{ "_id" : ObjectId("63c8042a6534d53a124b0a6e"), "name" : "许海", "age" : 28, "hobby" : [ "美女", "年轻美女", "成熟美女" ] }
注意:如果你要用$size,那么它所描述的那个字段必须是个数组,比如hobby这个字段必须是个数组,如果是普通的字段不是数组,那么是查不出来的,因为数组才有长度
降序、升序
举例:
现在我的user集合中有两个文档:
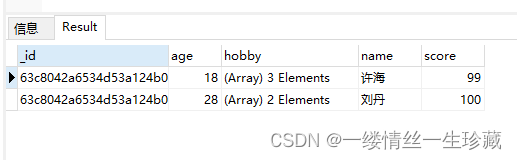
我希望能按照份数进行降序排序,如果分数相同,相同的部分就按照年龄升序排序;
那么语句就该这么写:-1表示降序,1表示升序;
db.user.find().sort({score:-1,age:1});
给某文档新增字段
db.user.update({_id:ObjectId("63c8042a6534d53a124b0a6e")},{$set:{name:"许海",age:18,hobby:["美女","小美女","大美女"]}});
注意:更新语句在执行时,如果它定位到你这个文档,没有name字段,那么它就会这个文档添加上这个字段,如果有这个字段,它就会对这个字段做修改;
删除某文档的某个字段
db.user.update({score:{$exists:true}},{$unset:{score:null}},{justOne:false});
这句话意思就是:将user集合中所有拥有score字段的文档的score字段给删除;
skip函数
skip函数的意思就是忽略查询结果前面的n个文档;
比如我现在查出来有10条文档,那么我skip(3)就把前面3条忽略了,只要了后面7条;
skip(0)就是不忽略;
limit函数
limit函数的意思就是:本次查询展示的文档条数限制范围
比如查出来总共有10条,我就在最后加上limit(5),那么最终展示的就只有前面5条了;
所以
db.user.find().limit(1);意思就是只展示查出来的第一条
db.user.find().skip(1);意思就是跳过第一条,只展示后面的;
分页查询
limit函数跟skip函数配合起来使用就能达到分页的效果;
db.user.find().sort({score:-1}).skip(0).limit(5);
db.user.find().sort({score:-1}).skip(5).limit(5);
db.user.find().sort({score:-1}).skip(10).limit(5);
这样做的意思就是:按每页5条文档进行分页;
统计条数:count()
db.user.find().count();
db.user.count();也可以这么写,表示直接查询集合中的文档总条数;
去重:distinct(“字段名”)
对姓名进行去重,返回的结果是一个数组:
db.user.distinct("name");

比如这样的一个数据,我按照名字进行去重,得到的结果就是【许海,刘丹,我叫0】,如果按照job来去重,得到的结果就是【英雄】,注意是没有null的,不是【英雄,null】;
db.user.find().distinct("name"); 这种是错误写法的示范
注意:mongo中不能对查询结果去重,如果你在find函数后面跟上distinct函数,会报语法错误,这是跟关系型数据库不一样的地方,但是我感觉很不合理,后面再研究一下;
find函数的projection参数(作用:选择返回的字段)
db.user.find({},{age:1,name:1}) 注意,当你的projection参数要写东西时,如果你不想指定查询条件,那么你query也必须指定为{},否则mongo也不知道你这个projection到底是query还是projection;
意思就是你把结果查询出来后,我只展示age跟name字段,1表示展示,0表示不展示;
但是注意:你不能同时在projection参数中写0又写1,会报语法错误:
db.user.find({},{age:1,name:0}) 比如你这样写就是错的
或者你按照下面这种写法也是对的,意思就是除了age属性不展示,其他属性都展示;
db.user.find({},{age:0})
七.$type操作符
$type操作符的作用:
就是让我们可以按照BSON的类型去进行检索;
在BSON格式中的数据类型有哪些:

Binary data:表示二进制类型;
Regular Expression:表示正在表达式类型;上表中可见还有其他复杂类型,我就不多做说明了;
值得注意的是:在mongo中,mongo给每个类型都用数字进行了编号,比如Double类型的编号就是1;
为什么mongo要给类型编号呢?
这是因为当你使用$type来基于类型查询时,就可以写数字1,而不用写Double,Double是6个字母,挺麻烦的,其实就是为了方便,但是你非要写Double也能检索出来;
$type的案例
db.集合名称.find("title":{$type:2});
db.集合名称.find("title":{$type:"string"});
这两句话的意思,都是查出title字段为String类型的文档
关于$type的注意事项
当你用类型名称来进行查找时,你的类型首字母不能大写;
db.集合名称.find("title":{$type:"String"}); 比如你的String的首字母大写了,这就是错的
db.集合名称.find("title":{$type:"string"}); 这才是对的
关于mongo中数字类型的注意事项
注意:在mongo中数字,不管是整数还是小数,默认都是Double类型;
举例:

这样一组数据,我要你查询出age字段类型为Double的文档,你很容易就能查出来;
db.user.find({age:{$type:"double"}}); 这样一条语句即可
但如果你认为18,28是Integer类型,那么你使用16,18去查,恭喜你,你就查不到
db.user.find({age:{$type:16}});
db.user.find({age:{$type:18}});
结果就是这样的:
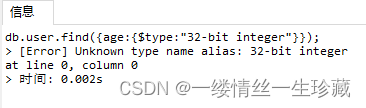
如果你以类型名称去查:恭喜你,直接就报找不到32-bit integer,64-bit integer这种类型
db.user.find({age:{$type:"32-bit integer"}});
db.user.find({age:{$type:"64-bit integer"}});
八. mongo中的索引
我强烈建议你在使用mongo时建立索引,如果不建立索引,当它在查询时,它会一条条的遍历集合中的所有文档,效率非常低;
索引的流程:
首先,假如你的集合中有很多文档,其中某些文档有score这个字段,并且每个score的值都是不一样的,杂乱无章;

此时没有索引,当你要查出score等于18的,那么mongo就会把所有文档全部遍历一遍最后再返回你结果,显然这个效率很低;
此时你可以建立索引,如何建立?
请看下面的创建索引章节:
mongo的索引跟mysql索引的相通之处
①mongo中,在建立索引后,跟mysql一样,mongo是把索引存入了一个方便遍历查找的结构中,就如红黑树;
②mongo中,跟mysql一样,也会以下划线id建立一个默认的唯一索引,这跟mysql默认以主键id建立唯一索引一模一样;
创建索引createIndex函数详解:
db.集合名称.createIndex(keys,options);
keys就是你要对我这个集合中的哪些字段建立索引,以及索引规则是什么;
比如{score:1} 就表示:以score字段建立索引,且是建立的升序索引,1就表示升序,-1表示降序;
建立索引后,就变成下面这个样子了(为了方便理解,实际上不是);

那下一次你要以score作为条件进行查询时,根据这个排好的顺序,就可以快速的找到你想要的文档了;
options就是createIndex函数的配置项,配置项包含很多参数:
①background(Boolean):表示是否后台创建索引,默认值是false,也就是默认是在前台完成的创建索引,但是在前台创建索引的过程中会阻塞其他的数据库操作,所以你可以将其改成true,变成后台创建索引,就不会阻塞了;
②unique(Boolean):表示是否建立唯一索引,如果为true,则表示是唯一索引,那么则必须要求建立索引的这个字段所对应的value必须是不重复的;
③name:意思就是:你可以给你建的索引取一个名字,如果你不取,mongo会自动给它取一下名字,比如你看getIndexes函数中返回的值,就会包含name这个属性;
④sparse:默认值为false,表示是否创建稀疏索引,这里需要注意:假如你要对一个有20条文档的集合创建索引,比如要对age这个字段创建索引,但是其中只有10个文档有age这个字段,剩下10个文档根本没有age这个字段;sparse默认为false,表示不创建稀疏索引,意思就是:在对age创建索引时,会把10个没有age字段的文档当成age字段为null,然后跟着那10个有age字段的文档一起来建立索引;相当于对整个集合全覆盖了;但是如果你把sparse改成了true,那么这10个没有age字段的文档,就不会参与到索引的创建中去;
那么sparse到底是true好还是false好呢?通过还是就用默认的false就行了,一般都是保持索引的全覆盖;
⑤expireAfterSeconds:integer类型,这个参数很有意思,是用来指定索引的有效期的,比如我要按照小朋友的糖果数量来进行排序查询,那么此时我就要对糖果数量这个字段建立一个索引,但是很显然,我平常的业务中会经常以糖果数量作为查询条件吗?显然不会,可能只有在某些儿童节办活动的时候才会这么做;所以一个不经常用的索引放在那里是很浪费空间的,所以可以通过expireAfterSeconds来给索引指定过期时间;如果你不指定这个参数,默认创建的索引都是永久存在的;注意:这个参数构建出来的过期时间,固定以秒作为单位;
⑥v:我们在创建索引时,还可以给这个索引指定一个版本号,如果你不指定,mongo自己也会维护一个版本号;
⑦weights:String类型,表示索引的权重值,数值在1~99999之间,表示该索引相对于其他索引字段的得分权重;说实话,这个属性我不太懂,但是目前用的不太多,后期遇到了再深入学习;
⑧default_language:String类型,对于文本类型,该参数决定了停用词及词干和词器的规则的列表,默认为英语;
说实话,这个属性我不太懂,但是目前用的不太多,后期遇到了再深入学习;
⑨language_override:String,对于文本类型,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为language;说实话,这个属性我不太懂,但是目前用的不太多,后期遇到了再深入学习;
删除索引:
db.集合名称.dropIndex("索引名称"); 删除集合中的指定索引,这里的索引名称不能直接填字段名,要填你创建索引时给索引起的名字,或者mongo自己维护的那个索引名字;
db.集合名称.dropIndexes();删除集合中的所有索引,但这个所有索引是不包含下划线id的;
查看当前集合中有哪些索引:getIndexes();

我们可以看到除了它自带的下划线id索引外,还有一个我们自己建的name索引,
"key":{
"name":1
}的意思这是以name作为索引;
"name":"name_1"的意思是这个索引的名称为"name_1",也就是mongo自己给这个索引取了个名字叫"name_1";
查看集合中所有索引一起占用的空间大小,以字节为单位
db.集合名称.totalIndexSize();
创建复合索引
什么叫复合索引,将两个或者两个字段以上合在一起建立出来的索引,就叫复合索引;
db.user.createIndex({score:-1,age:1},{expireAfterSeconds:20,name:"score_age_index"});
这句话的意思就是,以score字段,age字段创建复合索引,也就是这两个字段放在一颗B+树上面来作为索引;先以score升序排序,如果score相同,就以age降序排序;这就是这两个字段产生的复合索引的效果;同时我给它指定了一个过期时间为20秒,给这个复合索引取了一个名字叫"score_age_index";
关于索引过期时间,需要注意的是:
你创建了一个索引,到期了,但是你会发现,你通过getIndexes函数还能查看到它,但是实际上它已经失效了,但是mongo不会主动去删除它,需要你自己手动删除;
关于复合索引的注意事项:
假如你以age,name,sex三个字段构建了一个复合索引,那么在关系型数据库中,这个索引的B+树的节点,是从左到右维护了三列,第一列是age,第二列是name,第三列是sex;这种就要满足左包含原则,意思就是:你以age来查可以命中这个复合索引,以age,name共同作为条件也可以命中这个索引,以age,name,sex共同作为查询条件也可以命中该索引,但是如果你以name,age或者name或者age作为查询条件的话,是无法命中该复合索引的;
在mongo中复合索引跟关系型数据库中的复合索引可以说没啥区别,也需要满足左包含原则;
注意:左包含原则重在包含,假如你是以name,age,sex这样的顺序来作为条件去查询,也是能命中索引的,因为你确实是从左到右包含了索引字段(也就是包含了age字段),所以可以命中索引,跟你查询时条件的顺序无关;
注意:在排序的时候也能利用索引
sort({age:1,name:-1})跟查询一样,只要你age,name字段满足最左包含原则,就可以命中复合索引;
九. 聚合查询
聚合查询:aggregate([数组]) 聚合函数
mongo中的聚合查询跟es中聚合查询差不多;
举例:
我现在有三个文档存入了集合中,如下:

我现在有一个需求:我要求出每个作者各自的文章数量,这时候就可以使用聚合查询;
注意:
①首先我们需要知道aggregate函数中,你要传进去的是一个数组,而不是一个对象,一定要注意了;
所以你aggregate(【】)的小括号里面就得是中括号;
聚合查询:分组操作符
db.集合名称.aggregate([{$group:{_id:'$by_user'}}]);
你在传入aggregate的数组中,给第一个参数设置成$group就表示你要进行分组操作,那到底以哪一个字段分组呢?
_id后面跟的值by_user,就表示以by_user这个字段进行分组,但是注意:你在写by_user时,一定要在前面加上多勒,并且多勒by_user要用引号括起来,如果你不写多勒,那么mongo是不知道你要以哪个字段进行分组的,因为mongo要拿着字段名字去取这个字段的值,然后根据值进行分组,所以要用到多勒符号,表示根据字段名去找值;
注意:这里的_id并不是代表文档id,只是跟文档id一个样,它是作为key,在分组操作符中用来表示到底以哪个字段进行分组的,你把这里的_id当成一个标志位就行了;
聚合查询:求和操作符
分组后,再求和
db.集合名称.aggregate([{$group:{_id:'$by_user'}},sum_by_user:{$sum:1}]);
在这里需要注意:sum_by_user是我们自己定义了的一个名字,就是求和后的结果的名字为sum_by_user;
这个结果的值呢,用{$sum:1}进行表示,多勒sum是求和操作符,为1表示进行求和,为0的话,表示不进行求和操作;
db.集合名称.aggregate([{$group:{_id:'$by_user'}},sum_by_user:{$sum:2}]);
注意:如果你把多勒sum的值也成了2,那么mongo则会把求和后的结果乘以2;
聚合查询:求平均值操作符 $avg
聚合查询:最小值操作符 $min
聚合查询:最大值操作符 $max
聚合查询:加入数组操作符 $push(不会去重)

聚合查询:加入数组操作符 $addToSet(会去重)

常见聚合表达式:

十. springboot整合mongo
1.引入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
2.编写配置文件:
分为两种情况,假如你的mongo没有设置账户密码的话,那么你就使用下面这种配置即可;
spring:
data:
mongodb:
uri: mongodb://192.168.11.10:27017/mytestdb
注意:mongodb代表协议,表示你要连接的mongodb,这个不能少,mytestdb表示你要连接mongo中的哪一个库;
如果你的mongo设置了账户密码,则需要使用下面这种配置:
spring:
data:
mongodb:
host: 192.168.11.10
port: "27017"
password: "115409"
username: root
database: mytestdb
# auto-index-creation: false 在springboot2.2.1版本后自动创建索引的方式已经不被推荐,建议你把auto-index-creation配成false,或者干脆就不配,默认就是false;
注意:
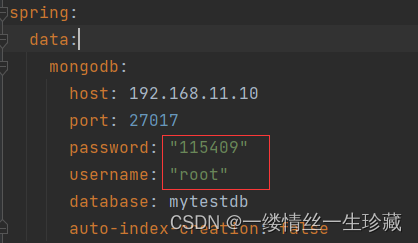
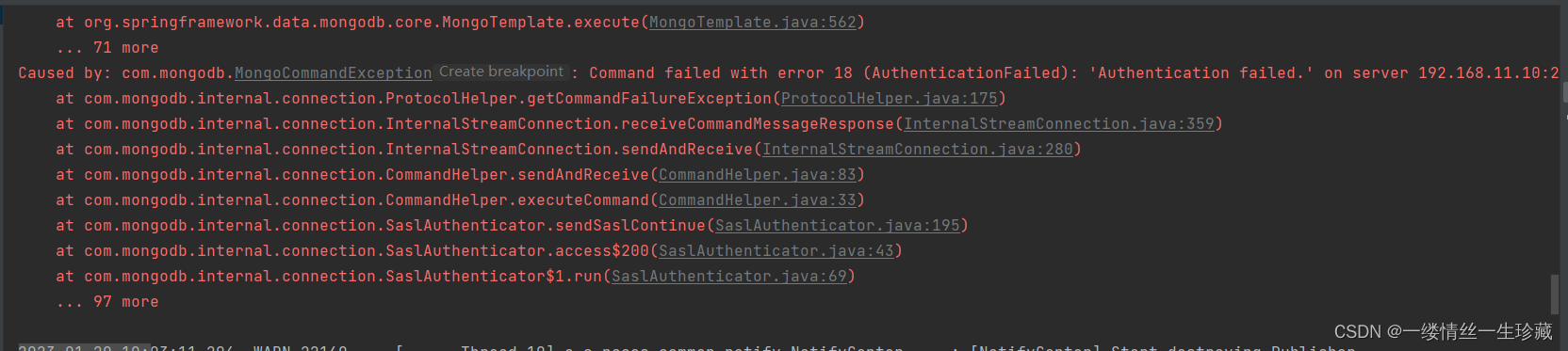
你在配置账户密码时,必须给账户密码加上双引号,否则启动时会报认证失败,报错如下: 这个跟连mysql不一样,mysql不用加双引号;
3.MongoTemplate的api操作
创建集合:mongoTemplate.createCollection(“集合名”);
判断某个集合在库中是否已经存在:mongoTemplate.collectionExists(“集合名”);
如果一个集合已经存在了,你再调用createCollection去创建这个集合,就会报错,所以在创建集合前,建议你先调用collectionExists函数判断一下该集合是否已经存在;
删除一个集合:mongoTemplate.dropCollection(“集合名”);
注意:删除一个不存在的集合,也是可以的,没有任何关系,也不会报错;
spring-boot-starter-data-mongodb中的注解:
这里要注意:springboot整合mongodb其实存在一个难点:mongo中的文档跟java中的对象类型并不完全一致,你要将对象存到mongo中,其实要转成 json格式或者bson格式,才能存进去,否则存不进去;
spring-boot-starter-data-mongodb这个框架就为了我们方便,所以就设计了一套注解,只要在实体类上使用对应的注解,就将这个类的对象转换为对应的文档类型存入mongo中,这在很多其他的框架,JPA,MP中也是非常常见的操作;
@Document:必须写在类上
这个注解必须写在类上,表示这个类可以作为mongo中的文档进行存储,你加了这个注解后,日后mongo在处理到这个类的对象时,它就会把这个对象转成文档类型存到mongo中;
但是mongo仅仅是知道把要把这个对象转成文档还不行,它怎么知道要把这个文档放在哪个集合中呢?
所以@Document注解就有两个属性,一个是value,一个是collection,这两个属性是一个作用,都是用来指定这个文档要存到哪个集合中的,你使用其中一个属性就行了;(为什么要设计两个,我暂时也不知道);
@Id:可以写在成员变量或方法上
作用是:将成员变量的值映射成文档的下划线id;
@Field:可以写在成员变量或方法上
作用:比如我们实体类中的一个属性叫name,但是我希望它存入mongo时,文档对应的属性叫username,那么这时候就得使用@Field注解了,它可以在将对象转换为文档存入mongo的过程中,将属性名进行一个修改;
如果你在属性上不加@Field,那么由于你在类上加了@Document,那么spring-boot-starter-data-mongodb就会默认将属性名作为key存入mongo;
属性:有两个属性,name和value,这两个属性也是等价的,你用哪一个都行;
比如:
@Field(name = "username")
private String name;
跟
@Field(value= "username")
private String name;
是等价的
@Transient:可以写在成员变量或方法上
作用:假如你的实体类的属性有很多,其中age属性,你并不希望它序列化成文档对象,也就是你不想把age这个属性存到mongo中,那么你就可以使用@Transient注解;
@Transient
private Integer age;
这样之后,age属性就参与文档的序列化了;
注意:@Transient这个注解,是java自带的注解,它的作用是,日后这个属性在参与序列化的过程中,不会进行序列化,也就是不会转成json格式或者bson格式或者其他格式;
MongoTemplate操作文档
保存文档 与 插入文档:save函数,insert函数
新增文档有两个api:save(),insert()
这两个函数都能完成文档的插入,但是两者区别在于:
①
insert函数在插入时,如果你插入了一个下划线id已经存在的文档,此时就会报错EuplicateKeyException;
但save函数在插入时,如果下划线id跟集合中的id重复了,那么就会执行更新操作;
②
insert函数有重载,除了传单个对象进去,你还可以传一个集合进去(同时指定对象的类型或者集合名称),也就是insert可以进行批量插入;但是save函数是没有批量插入的,只能for循环一个个的插入,所以速度比较慢,同时每次save的时候,它都会遍历整个集合来判断是否有下划线id重复,有重复就进行更新,所以导致它的速度更慢了;
关于save函数跟insert函数的注意事项:
当你使用对象映射成文档的方式插入文档时,mongo会额外生成一个下划线class字段_class,mongo专门用这个字段来记录你存入进来这个对象所在的包路径,以便日后再查询这个文档时再将其反序列化成对象;只有将对象映射成文档插入才有,如果你只是单纯的使用mql语句插入是不会自动生成这个下划线class字段的;

查询所有文档:findAll函数

findAll函数表示查询所有文档,你使用这个函数时,因为你查询出来的文档最终要反序列化成对象,所以你必须告诉它反序列化后的类型,它才知道怎么去反序列化,所以你要传一个entityClass对象进去;同时你也可以告诉它集合的名称,你到底要到哪个集合里面去查,这也能查出所有,但是注意:如果你这个类没有加@Document注解,那么你不在findAll函数中指定集合名称的话,就查不出来;
根据下划线id查询文档:findById函数

跟findAll函数同理,你需要告诉它返回的类型是什么,springdata才好去进行反序列化;
如果你这个类没有加@Document注解,那么你还必须把集合名称告诉它,它才知道去哪个集合中查找;
如果你加了@Document注解,你就不用指定集合名称了;
条件查询:find函数
find函数中,要传的第一个参数就是Query对象,这个Query对象就是用来构建查询条件的;
查询所有
mongoTemplate.find(new Query(), User.class,"mytestdb");
这句话的意思就是:查询所有,当你构建了一个没有设置属性的Query对象时,就代表是查询所有;
等值查询
首选你需要知道:Query.query()这个静态方法,这个方法是专门用来构造Query对象的;
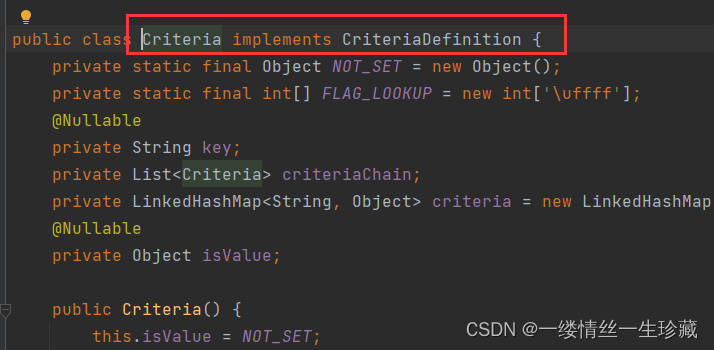
Query query = Query.query(CriteriaDefinition criteriaDefinition);
query方法需要传一个CriteriaDefinition类型的参数,这个是一个接口,Criteria是它的实现类:
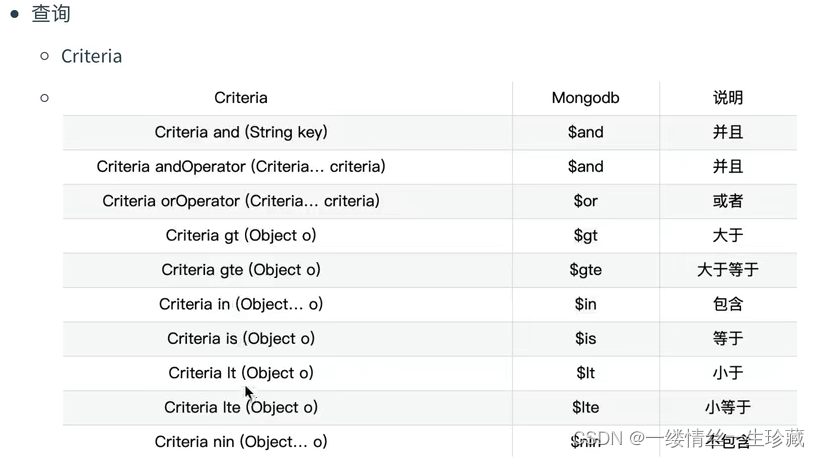
然后Criteria类也有一个静态方法where,它也是返回一个Criteria类型的对象,where方法要传一个字段名进去(也就是下图中的key),表示你要按照哪个字段来构造查询条件;

然后Criteria类又有很多实例函数,比如is函数(表示等于),lt函数(表示小于),看下图;
所以说假如你要实现一个username字段等于许海的文档的查询,那么代码你可以这样写:
mongoTemplate.find(Query.query(Criteria.where("name").is("许海")), User.class,"mytestdb");
这里where函数中为什么用name而不是username呢?明明文档中就是以username作为字段,注意了:这里springdata做的很智能,你实体类中字段叫name,文档中叫username,只要你这两个字段用@Field注解进行了映射,那么在使用where函数时不管你传name进去还是传username进去都是可以的;
and查询
再举个例子:
查询name等于许海,并且salary大于20000的,就是下面这种写法;
mongoTemplate.find(Query.query(Criteria.where("name").is("许海").and("salary").gt(20000)), User.class,"mytestdb");
or查询
使用or查询时比较特殊,假如我要查询姓名是许海的,或者姓名是刘丹的;
mongoTemplate.find(Query.query(Criteria.where("name").is("许海").orOperator(Criteria.where("name").is("刘丹"))),User.class);
这样写就是错的,为什么呢?这里一定要注意了,单独的一个Query.query(Criteria.where(“name”).is(“许海”)就表示and的意思了,你后面再跟一个orOperator(Criteria.where(“name”).is(“刘丹”))的话,就又表示or的意思;
and name = “许海” or name = “刘丹”这个语法就不通,所以根本查不出来东西;但是这里我也很困惑,为什么第一个Query.query(Criteria.where(“name”).is(“许海”)就表示and了,搞不懂,就死记吧;
但是如果你要查姓名是许海的,或者年龄等于28的,那么你这么写就是对的,因为不是两个字段了,and or语句就通顺了;
mongoTemplate.find(Query.query(Criteria.where("name").is("许海").orOperator(Criteria.where("age").is(28))),User.class);
那如果我非常查询姓名等于许海或者姓名等于刘丹的呢,非要用这种两个字段相同的或进行查询呢?
那你就要这么写,你要先将Criteria 对象单独new出来,再使用Criteria.orOperator函数,这个函数是传一个Criteria类型的可变参数进去,
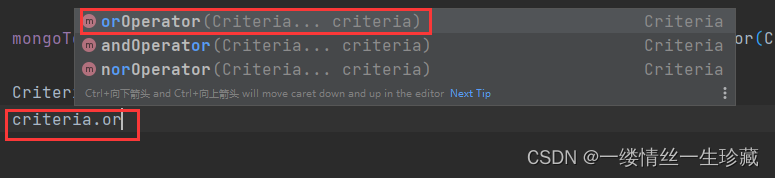
所以你可以在里面构建多个查询条件,就像下面这样写就行;
Criteria criteria = new Criteria();
criteria.orOperator(
Criteria.where("name").is("许海"),
Criteria.where("name").is("刘丹")
); # orOperator函数中可以传多个条件进去,就表示or,可以一直or;
mongoTemplate.find(Query.query(criteria),User.class);
and和or连用的查询
mongoTemplate.find(Query.query(Criteria.where("name").is("许海").orOperator(Criteria.where("age").is(28))),User.class);
我们上面举的例子中,就是and or连用的查询,注意字段要不同,相同的话,语法就错了,也就是说你第一个Criteria.where函数中传进去的字段要跟第二个Criteria.where函数传进去的字段名不相同;同时这是一个and跟一个or的连用,你还可以有多个进行连用;
排序
如果你要进行排序,你要将query对象单独提出来,也就是单独new出来,再调用query的with方法,可以看到with可以传Sort进去,表示进行排序,也可以传Pageable进去,表示进行分页;

这样写,就代表按照age字段进行降序排序,注意with函数里面的写法;
Query query = new Query();
query.with(Sort.by(Sort.Order.desc("age")));
mongoTemplate.find(query,User.class);
你也可以这样写:表示按照age降序排序,当age相同时再按照score升序排序,by函数是可以传可变参数进去的;
query.with(Sort.by(Sort.Order.desc("age"),Sort.Order.asc("score")));
分页查询
第一种:使用skip函数和limit函数,这样可以实现分页效果;
Query query = new Query();
query.with(Sort.by(Sort.Order.desc("age")))
.skip(0)
.limit(5);
mongoTemplate.find(query,User.class);
第二种:你也可以使用springdata维护的Pageable对象来进行分页,既然有了skip函数跟limit函数,我就不写这种方式了;
Query query = new Query();
query.with(Sort.by(Sort.Order.desc("age"),Sort.Order.asc("score")))
.with(....); # 这里可以采用链式调用的方式继续with以进行分页;
mongoTemplate.find(query,User.class);
查询条数
查询总条数:相当于没有条件,所以用new Query();
mongoTemplate.count(new Query(), User.class)
查询年龄大于30的条数
mongoTemplate.count(Query.query(Criteria.where("age").lt(30)), User.class)
去重
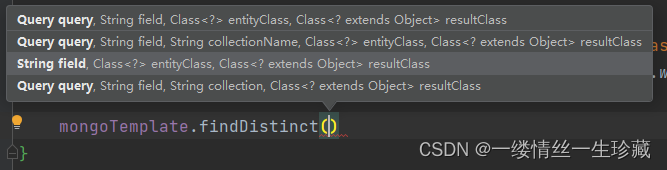
findDistinct函数有几个参数:
String field:代表你要对哪个参数去重
Query query:因为去重之前,你肯定要先查出来有一个查的动作,所以这个Query就代表查询条件,也就代表你要按什么条件查询出来然后去重;
String collection:代表你要操作哪个集合的文档;
Class《?》 entityClass:代表文档映射到java中的对象类型;
Class《 ? extends object》 resultClass:代表你去重后得出的结果的类型,在我们学习mongo的原生mql语言时,我们调用distinct函数对name去重,我们最终得到的就是全是name,而不是根据name去重后的文档对象,所以,在springdata中,你通过去重得到的,其实也是name字段的值,由于name字段都是String类型,所以这里的参数:resultClass就应该填String;
举例:
我要对下面这个集合的文档的年龄去重:
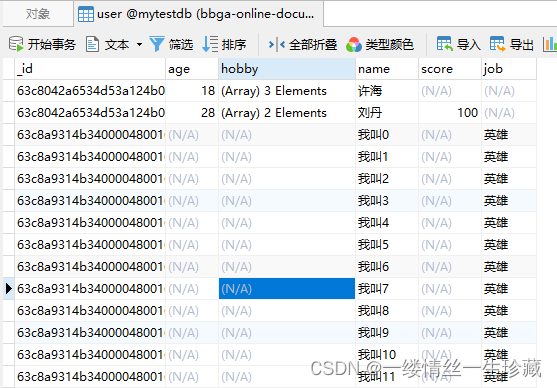
那么语句就这么写:
mongoTemplate.findDistinct(new Query(), "age", User.class, Integer.class)
那么得到的就是:

所以我们可以得到的结论就是:去重后,并不会展示null;
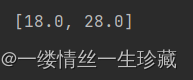
注意:如果你把resultClass的类型该成Double.class,就像下面这样
mongoTemplate.findDistinct(new Query(), "age", User.class, Double.class)
那么你得到的结果就是:
4.使用mql语句查询
如果你觉得使用springdata提供的api进行查询很麻烦,记不住api,springdata也支持使用mql语句进行查询
BasicQuery与Query
Query是用来构建查询条件的,但是它无法实现使用mql语句进行查询,我们查看它的api发现它全是面向对象的查询;
如果要使用mql语句的话,我们需要使用Query的子类BasicQuery;
BasicQuery的作用是:可以让我们使用BSON格式mql语句的方式来进行查询,但是你还是得用find方法;
find函数在传入参数时,还必须是传一个Query类型的query进去,所以我们可以new 一个BasicQuery出来,它是Query得子类,所以也能放到find函数里去;
再看BasicQuery的构造方法:
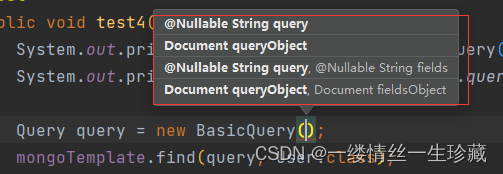
参数解释:
String query:代表你要执行的mql语句;
String fields: 表示你想要返回的字段;
原生mql中,我们使用
db.集合名称.find({name:"许海"});
可以查询出集合中名字等于许海的文档;
使用BasicQuery就得这么写:
Query query = new BasicQuery("{name:'许海'}");
mongoTemplate.find(query, User.class);
相当于说你只需要写find函数中的内容,mongoTemplate.find就相当于外面db.集合名称.find,你不用在new BasicQuery中写"db.集合名称.find"了;
再举个例子:我要查询姓名等于许海,或者姓名等于刘丹的,并且只展示age字段跟job字段
Query query = new BasicQuery("{$or:[{name:'许海'},{name:'刘丹'}]}","{age:1,job:1}");
mongoTemplate.find(query, User.class);
最后得到的结果是:
[
User(id=63c8042a6534d53a124b0a6e, age=18, hobby=null, name=null, score=null, job=null),
User(id=63c8042a6534d53a124b0a6f, age=28, hobby=null, name=null, score=null, job=null)
]
这是为什么?明明我只展示age字段跟job字段,为什么得到的结果还会有hobby这些其他字段?
其实:mongo在查询出来时,确实只返回了age字段跟job字段,但是由于你在find函数中指定了一个User.class,也就是说,springdata会根据你给的User.class,将mongo返回的结果反序列化成User类型,由于User是有这些其他属性的,所以就导致你最后展示出来有这些属性,但是都为null,因为你mongo返回来的BSON格式中根本就没有这些字段,所以全是null;
5.文档的修改

文档的更新是update函数,update函数又分为:
update:
updateFirst:表示只更新复合条件的第一条,后面那些就算复合条件的也不更新了
updateMulti:表示更新多条,只要满足的条件的都更新;
updateFirst函数:
updateFirst函数有几个参数:
- Query query:表示更新条件,满足什么条件的才更新,还是跟查询一样,可以用Query.query()方法来构建,你也可以传一个BasicQuery进来用mql语句来构建;
- UpdateDefinition update:翻译过来是更新定义对象,也就是你要用这个对象来告诉springdata你到底要更新哪些字段,以及更新成什么样子;
UpdateDefinition 是一个接口,Update是它的实现类,我们要用的话,要用Update这个类
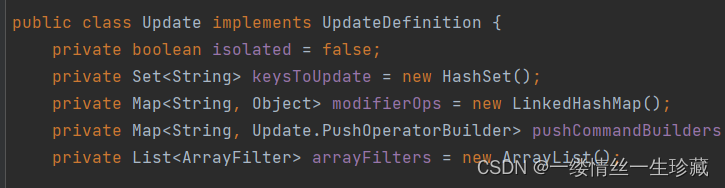
Update类有一个set(String columnNam,Object )函数;表示你可以set(“age”,99),意思就是将你将age字段改成99;
例子:
Update update = new Update();
update.set("age",99);
mongoTemplate.updateFirst(Query.query(Criteria.where("name").is("许海")),update,User.class);
- 最终的效果就是,age确实被修改了99,但是注意:其他字段并没有被修改掉,只修改了age字段,相当于springdata的这Update类在做更新时,已经封装了$set操作符,才没有将其他字段给置空;

updateMutil函数
updateMutil函数用起来跟updateFirst函数没有任何区别,只不过它是批量更新:
Update update = new Update();
update.set("age",99);
mongoTemplate.updateMutil(Query.query(Criteria.where("name").is("许海")),update,User.class);
upsert函数

除了update函数,还有upsert函数,upsert函数的意思就是:如果你在执行更新操作时,没有找到复合条件的文档,那么就直接执行插入;
Update update = new Update();
update.setOnInsert("id",10);
update.setOnInsert("name","鸡你太美");
update.set("age",100);
mongoTemplate.upsert(Query.query(Criteria.where("name").is("你叉叉")),update,User.class);
注意:
这句话最后的意思就是:我先去集合中找,看有没有姓名叫"你叉叉"的,如果有,我就把他age改成100,;如果找不到姓名叫"你叉叉"的,我就新插入一条数据,插入的这条新数据,id为10,姓名是"鸡你太美",同时age也是100;Update的实例方法setOnInsert方法的意思是:当你在执行插入操作的时候,setOnInsert方法里面设置的值就会生效,也就是id等于10,name等于鸡你太美会生效,也就是说会把id,name一起插入进去,但是如果你是在执行更新操作,你setOnInsert里面设置的k,v就不会生效;但是你set函数里面设置的,不管你是插入还是修改都会生效,这就是set和setOnInsert的区别;
UpdateResult ,getMatchedCount,getModifiedCount,getUpsertedId
upsert,updateMutil,updateFirst这三个函数的返回值都是UpdateResult 类型;
UpdateResult类有三个方法:
- getMatchedCount表示获取匹配到的条数:你在执行更新时,通过这个方法可以拿到匹配成功你更新条件的文档的总条数;
- getModifiedCount表示获取到最终更新的总条数:你执行更新,你到底更新了多少条,通过这个方法可以拿到;但是注意:如果你调用的upsert函数,并且它执行的是插入的话,getModifiedCount是获取不到插入的条数的,只能获取到更新的条数;
- getUpsertedId表示获取本次更新或者插入的_id,如果你执行的是更新操作,这个方法就可以把被你更新的那条文档的_id返回回来,如果你执行的是插入操作,返回的就是你新插入的那条文档的_id;
举例:
Update update = new Update();
update.setOnInsert("id",101);
update.setOnInsert("name","鸡你太美");
update.set("age",100);
UpdateResult result = mongoTemplate.upsert(Query.query(Criteria.where("name").is("穷哈哈")), update, User.class);
long matchedCount = result.getMatchedCount(); # 结果为0,因为没有满足条件的,集合中没有姓名为穷哈哈的 ;
long modifiedCount = result.getModifiedCount(); # 结果为0,因为没有满足条件就执行的插入操作,,没执行更新操作;
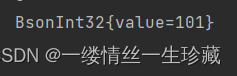
BsonValue upsertedId = result.getUpsertedId(); # 结果为一个BsonValue 对象,里面的属性值value为101,因为你提前已经设置好了id;
System.out.println(upsertedId);
BsonValue 对象打印出来的效果就是这样的;
6.文档的删除
删除所有
调用remove方法传一个没设置参数的Query对象进去就表示删除所有;最后通过getDeletedCount可以获取到最终删除的条数;
DeleteResult remove = mongoTemplate.remove(new Query(), User.class);
remove.getDeletedCount();
条件删除
条件删除跟条件修改,条件查询这些都一样,你用Query.query构建一个条件即可
DeleteResult remove = mongoTemplate.remove(Query.query(Criteria.where("salary").lt(3000)), User.class);















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









