






centos7 Hadoop安装配置
一、前置
1.新建虚拟机,先关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
2.配置虚拟机网络
cd到该目录
cd /etc/sysconfig/network-scripts
vi编辑配置文件(可以在vm中的编辑中的虚拟网络编辑器查看DHCP和NAT设置)
vi ifcfg-ens33
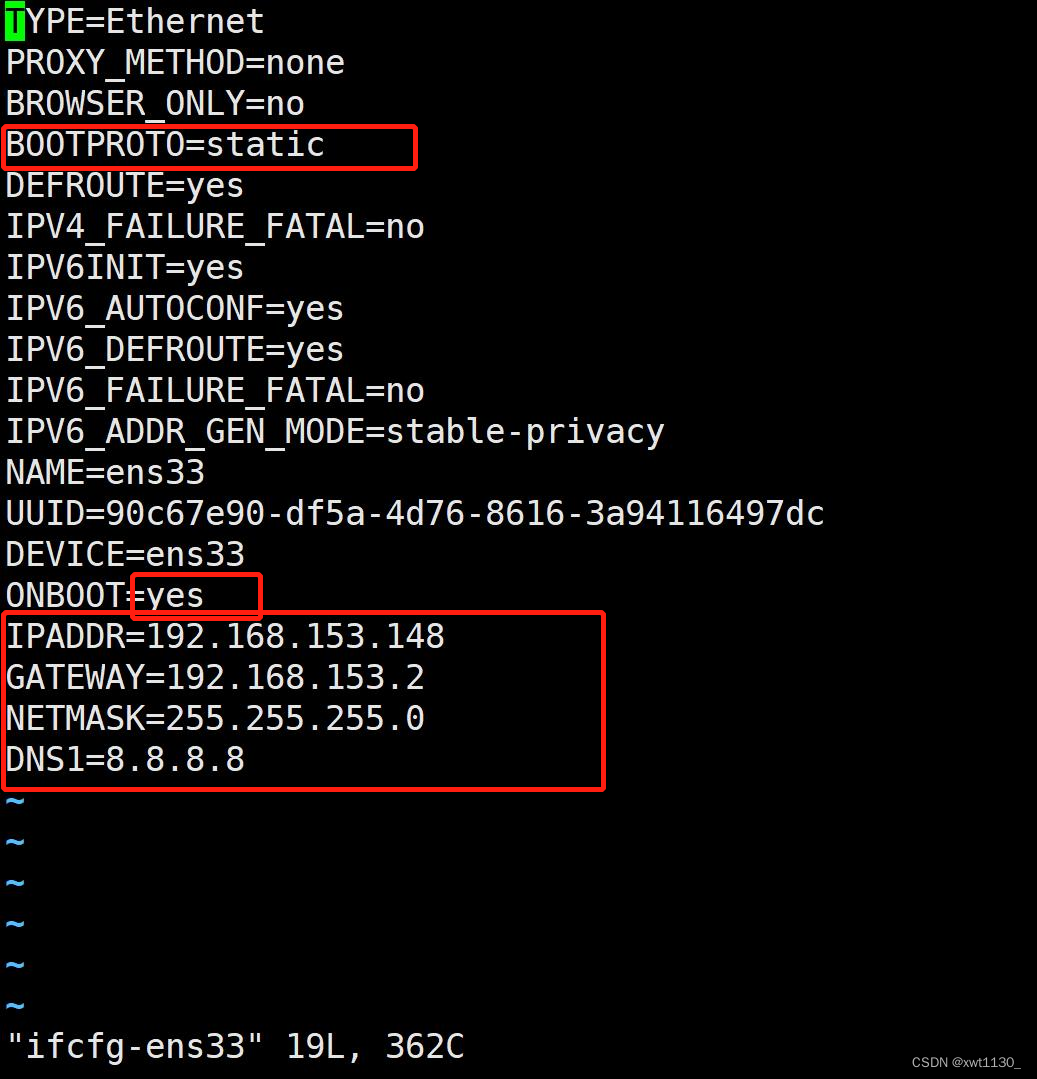
修改完后重启网络,ping百度,能ping通就行
systemctl restart network
ping www.baidu.com

3.安装vim工具
yum -y install vim
4.设置免密登陆
生成秘钥(注意是大写的P),运行后再次回车,生成秘钥
cd
ssh-keygen -t rsa -P ""

ll -a查看
ll-a
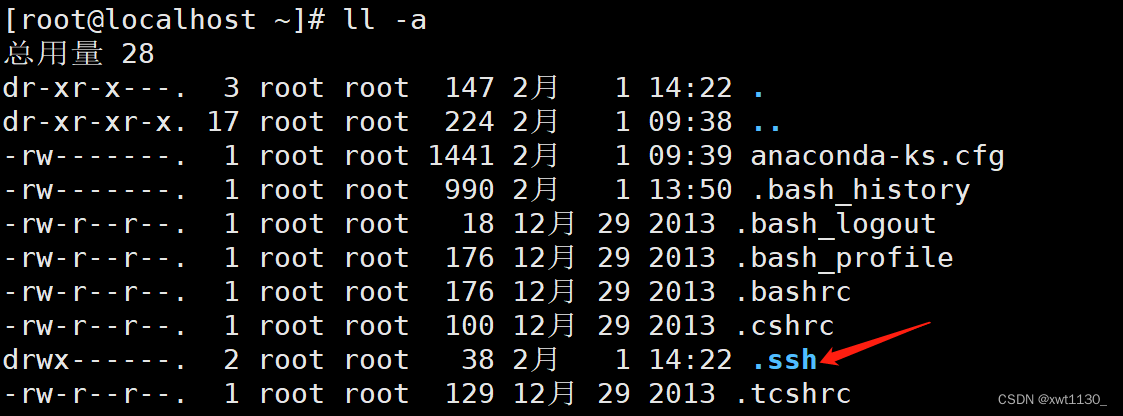
查看秘钥
cd .ssh/
ls
cat ./id_rsa.pub >> authorized_keys
开启远程免密登录配置
ssh-copy-id -i ./id_rsa.pub -p22 root@192.168.153.148
ssh -p22 root@192.168.153.148
免密登陆成功
5.安装同步时间工具
yum -y install ntpdate
同步时间
ntpdate time.windows.com
定时更新时间(定时任务)
crontab -e
* */5 * * * usr/sbin/ntpdate -u time.windows.com
定时任务 启动/停止/重启/状态
service crond start/stop/restart/status
6.修改本计算机名字
vim /etc/hostname
或者
hostnamectl set-name xwt148
通过vim /etc/hosts配置其他计算机的ip以及主机名的映射,可以直接ping设置好的主机名
二、安装配置JDK和Hadoop
1.通过xftp或者类似软件在opt目录新建soft和install目录,将准备好的hadoop压缩包和jdk传到install目录
解压缩,将hadoop和jdk解压到soft目录,如果觉得解压完的文件名太长可以用mv修改
tar -zxvf ./jdk-8u321-linux-x64.tar.gz -C ../soft/
tar -zxvf ./hadoop-3.1.3.tar.gz -C ../soft/
2.配置JDK环境变量
vim /etc/profile
在74行加入
# JAVA_HOME
export JAVA_HOME=/opt/soft/jdk180
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAV_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
检测是否配置成功
java -version
能出来就说明成功

3.修改解压郭的hadoop文件目录以及子目录文件的所有者为root
chown -R root:root /opt/soft/hadoop313/
4.修改Hadoop配置文件
在该目录下进行
cd /opt/soft/hadoop313/etc/hadoop

配置core-site.xml
vim ./core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://gree143:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop313/data</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>读写队列缓存:128K</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
配置hadoop-env.sh
vim ./hadoop-env.sh
将54行修改为,其中jdk180是你解压出来的目录,上面我将其修改为了jdk180
export JAVA_HOME=/opt/soft/jdk180
配置hdfs-site.xml
vim ./hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>hadoop中每一个block文件的备份数量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/soft/hadoop313/data/dfs/name</value>
<description>namenode上存储hdfsq名字空间元数据的目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/soft/hadoop313/data/dfs/data</value>
<description>datanode上数据块的物理存储位置目录</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>关闭权限验证</description>
</property>
</configuration>
配置mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>job执行框架: local, classic or yarn</description>
<final>true</final>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>gree143:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>gree143:19888</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1024</value>
</property>
</configuration>
配置yarn-site.xml
vim ./yar-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>20000</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>gree143:8040</value>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>gree143:8050</value>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>gree143:8042</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/soft/hadoop313/yarndata/yarn</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/soft/hadoop313/yarndata/log</value>
</property>
</configuration>
配置Hadoop环境变量
在jdk环境变量后加上
# HADOOP_HOME
export HADOOP_HOME=/opt/soft/hadoop313
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
5.刷新配置文件
source /etc/profile
查看是否刷新成功,能出现即成功
echo $HADOOP_HOME

6.初始化并测试运行
初始化
hdfs namenode-format
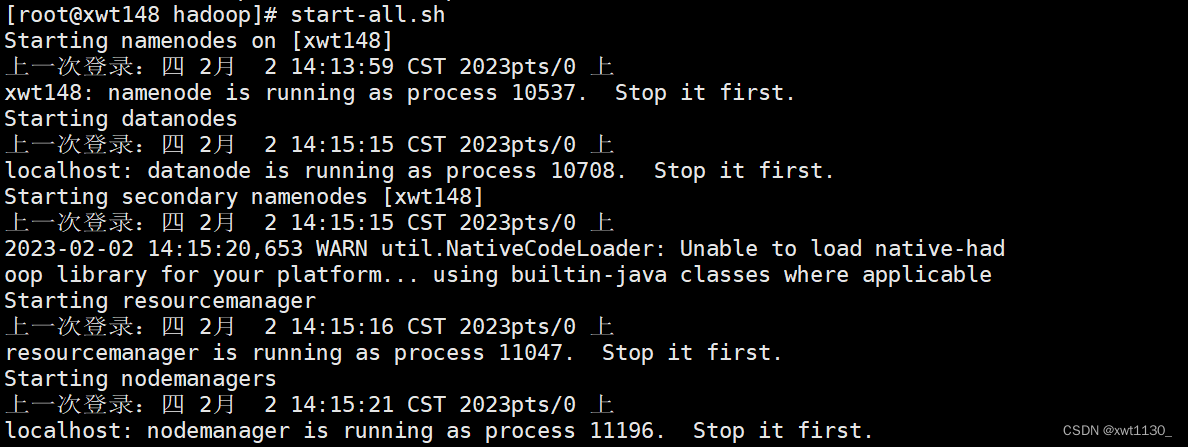
启动服务
start-all.sh
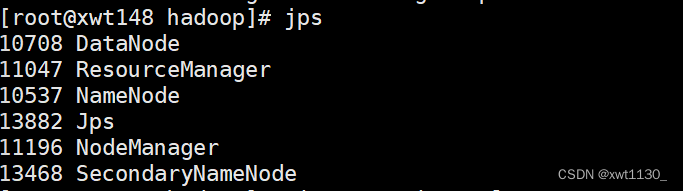
jps查看服务
在浏览器输入
http://IP地址:9870访问网站
















 5306
5306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









