







入门和gpu相关知识。作为开篇应该在完美不过了。
阅读《CUDA专家手册》第三章硬件架构后的一个笔记。之所以将目录都打出来,因为这就是CUDA的软件架构。
软件层
从应用程序本身到CUDA硬件上执行的CUDA驱动程序。
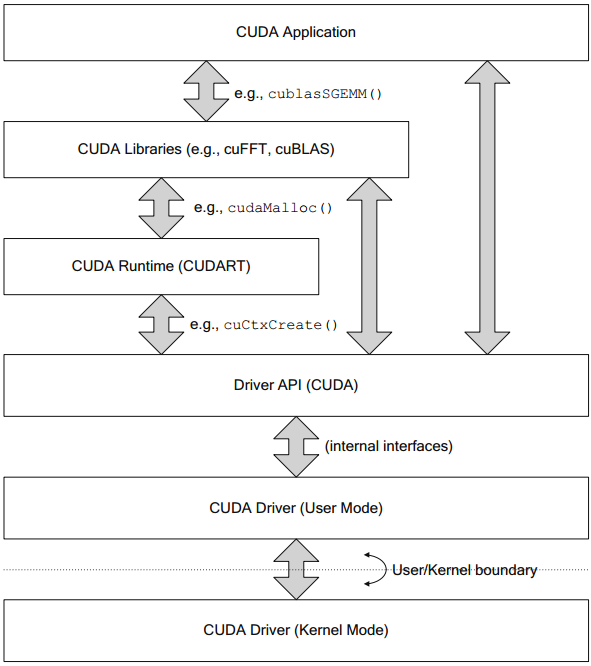
驱动程序API和CUDA运行时中的函数名称分别以cu*()和cuda*()大头。3对尖括号<<<>>>为启用内核函数。
CUDA运行时和驱动程序
驱动程序版本可由cuDriverGetVersion()函数获取。
驱动程序模型
- 统一虚拟寻址
- Windows显式驱动模型
- 超时检测与恢复
- 特斯拉计算集群驱动程序
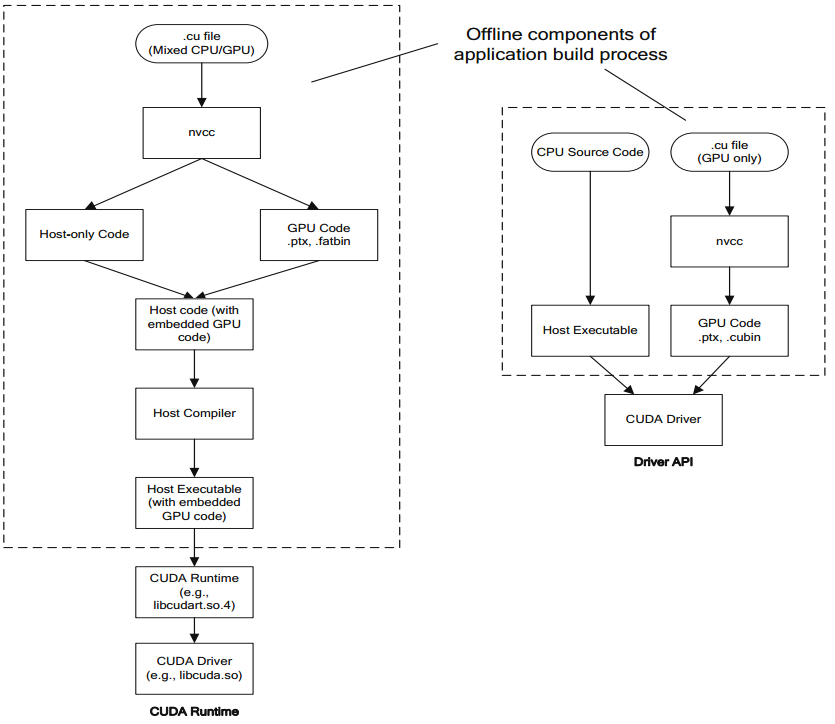
nvcc, PTX和微码
- nvcc是CUDA开发者使用的编译器驱动程序。例如编译、链接。
- 并行线程执行(PTX, Parallel Thread eXecution)代码是编译后的GPU代码的一种中间形式,它可以再次编译为原生的GPU微码。
设备与初始化
设备数量
调用cuDeviceGetCount()或cudaGetDeviceCount()函数查询范围为[0…DeviceCount - 1]的设备可用。
设备属性
- cuDeviceGetName()->查询设备名称
- cuDeviceTotalMem()->查询全局内存
- cuDeviceComputeCapability()->查询计算能力
- cuDeviceAttribute()->查询设备属性
- cudaGetDeviceProperties()->返回包括设备名称和属性信息的结构体cudaDeviceProp
无CUDA支持情况
CUDA运行时程序可以运行在不能运行CUDA的机器或未安装CUDA的机器上。如果cudaGetDeviceCount()函数返回cudaSuccess和一个非0的设备数,CUDA是可以用的。
上下文
上下文类似CPU中的进程,管理CUDA程序中所有对象生命周期的容器,包括如下部分:
- 所有内存分配(线性设备内存,主机内存,CUDA数组)
- 模块
- CUDA流
- CUDA事件
- 纹理与表面引用
- 使用本地内存的内核的设备内存
- 进行调试、分析、同步操作时,所使用的内部资源
- 换页内存复制所使用的锁定中转缓冲区
cudaSetDevice()函数,为调用的线程设置当前上下文。
生命周期与作用域
所有与CUDA上下文相关的分配资源都在上下文被销毁的同时被销毁。
资源预分配
少数情况下,CUDA不会预分配一个给定操作所需的全部资源。
地址空间
一组私有的虚拟内存地址,它可以分配线性设备内存或用以映射锁页主机内存。
当前上下文栈
三个主要功能。
- 单线程应用程序可以驱动多个GPU上下文
- 库可以创建并管理它们自己上下文,而不需要干涉调用者的上下文。
- 库不知晓调用它的CPU线程信息。
当前上下文栈的最初动机是使单线程CUDA应用程序可以驱动多个CUDA上下文。
上下文状态
类似于CPU中的malloc()和printf()函数,cuCtxSetLimit()和cuCtxGetLimit()函数可以设置和获取内核函数中对应函数的GPU空间上限。cuCtxSetCacheConfig()函数在启动内核时指定所期望的缓存配置。
模块与函数
模块是代码与一同加载的数据的集合,类似于windows中的动态链接库(DLL)和Linux中的动态共享对象(DSO)。模块只在CUDA驱动程序API中可用。
模块被加载,应用程序就可以查询其中包含的资源:
- 全局资源
- 函数(内核)
- 纹理引用
内核(函数)
在.cu文件中,用global标识内核。三对尖括号<<<>>>为启用内核函数。
设备内存
设备内存(或线性设备内存)驻留在CUDA地址空间上,可以被CUDA内核通过标准C/C++指针和数组解引用操作访问。CUDA硬件并不支持请求式换页,所以,所有的内存分配被真实的物理内存支持着。CUDA内存分配在物理内存耗尽时会失败。
流与事件
流与事件使主机与设备之间的内存复制与内核操作可并发执行。
CUDA流被用来粗粒度管理多个处理单元的并发执行:
- GPU/CPU
- 在SM处理时可以执行DMA操作的复制引擎
- 流处理器蔟(SM)
- 并发内核
- 并发执行的独立GPU
流的操作是按顺序执行的,像CPU的线程。
软件流水线
软件流水线解决因只有一个DMA引擎服务于GPU各种各样的粗粒度硬件资源,应用软件必须对多流中执行的操作进行流水操作。
开普勒架构减少了软件流水线操作的需求,Hyper-Q技术实际上消除了流水线需求。
流回调
不懂。
NULL流
NULL流失GPU上所有引擎的集结地,所有的流内存复制函数都是异步的。NULL流最有用的场合是在不需要使用多流来利用GPU内部的并发性时,它可以解决应用程序的CPU/GPU并发。一旦流操作使用NULL流初始化,应用程序必须使用同步函数来确保操作在执行下一步之前完成。
事件
CUDA事件表示了另一个同步机制。同CUDA流一同引入,记录CUDA事件是CUDA流中应用程序跟踪进度的一个方式。当之前的所有CUDA流的操作执行结束后,全部的CUDA事件通过写入一个共享同步内存位置而起作用。
主机内存
主机内存(CPU内存)。在所有运行CUDA的操作系统上,主机内存是虚拟化的。
为了便利DMA,操作系统VMM(虚拟内存管理器)提供了一个页面锁定功能。被VMM标记为锁页的内存就不能被换出,所以物理内存地址不能被修改。没被锁页的内存称作可换页。
锁页主机内存
锁页主机内存由CUDA函数cuMemHostAlloc()/cudaHostAlloc()分配。该内存是页锁定的并且由当前CUDA上下文为DMA设置。异步内存复制操作只在锁页内存上工作。
在CUDA中,锁页内存(pinned memory)是经过页锁定后且为硬件访问而映射后的主机内存,而页面锁定(page-locking)只是操作系统的一种不允许换页的机制。但是在操作系统文档中,这个两个概念是同义的。
可分享的锁页内存
可分享页内存在页锁定后映射给所有CUDA上下文。
映射锁页内存
映射锁页内存映射到CUDA上下文中的地址空间中,所以内核可能读写这块内存。
主机内存注册
用于开发者分配他们想要访问的内存。
CUDA数组与纹理操作
纹理引用可以把输入的任何坐标转化到设置的输出格式,表面引用则暴露了一个常规的逐位操作接口来读写CUDA数组内容。
纹理引用
纹理引用是CUDA用来设置纹理硬件解释实际内存内容的对象。
表面引用
表面引用可以是CUDA内核使用表面加载/存储内建函数读写CUDA数组。
图形互操作性
图形互操作性函数族使得CUDA可以读写属于OpenGL或Direct3D API的内存。
CUDA运行时与CUDA运动程序API
驱动程序API没有提供任何性能优势,但它为应用程序提供了显式的资源管理。
尾巴
草草结束该章内容,没有实际的操作真得让人很容易犯困。最后用一句话结束尾巴的内容——“当一位作家略去他所不知道的东西时,它们在作品中像漏洞似的显示出来。”
参考:
《GPGPU编程技术——从GLSL、CUDA到OpenCL》♥♥♥♥♥
《数字图像处理高级应用——基于MATLAB与CUDA的实现》♥♥♥
《基于CUDA的并行程序设计》♥♥♥
《CUDA专家手册》♥♥♥♥♥
《高性能CUDA应用设计与开发》♥♥♥♥















 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









