







在jdk5之后Java 5.0 在 java.utilconcurrent 包中提供了多种并发容器类来改进同步容器的性能 , 下面我们来介绍这些类
目录
ConcurrentHashMap
我们说, hashMap是线程不安全的, 如果同时有多个线程对它进行操作就有可能会出现问题 , 所以在此之上出现了ConcurrentHashMap , 它是线程安全的 , 它保证的线程安全介于hashMap和Hashtable之间 . 其内部采用的是锁分段机制 ( jdk8前用了分段锁的方式, 使用CAS(比较并交换) + synchronized替代) , 大大提高了性能
上面提到了锁分段和分段锁 , 来解释一下这两个名词
分段锁 : 将锁进行细化 , 在细化的每个分段单独加锁, 提高并发效率
锁分段 : 将锁进行分解 , 只在某些必须加锁的分段上加锁
这里我们先来说一下 : Hashtable
我们知道, Hashtable是线程安全的, 那么为什么还要用ConcurrentHashMap呢?
Hashtable虽然是线程安全的, 但是它在绝大部分方法上都加了Synchronized锁, 它的线程安全完全由synchronized保证, synchronized是一种独占锁, 就是说, 我这个线程在操作的时候, 其他线程就只能在外面等着, 等我把锁释放给你才行, 所以Hashtable的这种做法就导致了它的效率不高, 所以并不适合于高并发的情况下
接着上一个问题 , 为什么放弃分段锁的做法 ? 锁分段是怎样来做的? 有怎样的好处呢?
放弃分段锁的原因
首先就是在每个分段上加锁浪费内存空间 , 再一个就是在map 的底层结构中, 竞争同一把锁的概率也是不大的 , 分段锁可能反而导致操作时间变长, 效率变低
锁分段的做法与好处
java 8 放弃了分段锁, 而使用了Node锁 , 我们知道hashMap存储结构是 : 每个位置存储一个节点node, 在往map中 put 值的时候, 如果要插入的位置上还没有结点, 此时采用CAS机制插入第一个结点, 使用CAS保证了node的原子性, 无需加锁 , 但是如果要插入的位置上已经有结点node, 那么此时就使用这个node作为锁(使用的是synchronized)
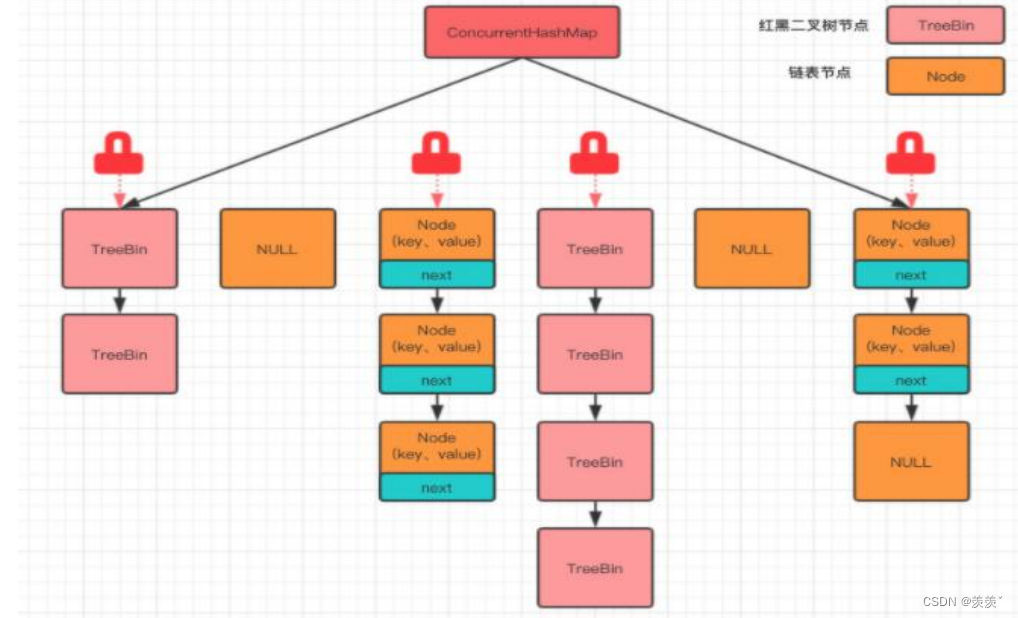
如上图 , 添加过结点的位置就采用第一个node作为锁, 没有添加过结点的位置就暂时不加锁,这样的做法极大提高了效率
我们可以去看concurrentHashMap底层的 put() 方法实现, 部分如下 :


在之后添加结点就会有加锁操作 , 如下 :
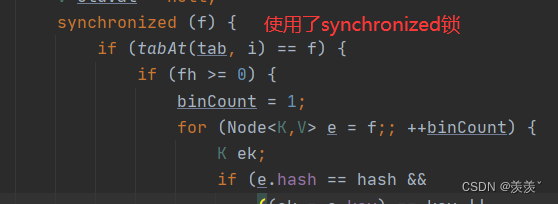
可以看到 , 加锁的力度明显降低 , 同时保证了安全和效率
CopyOnWriteArrayList
同样的 , ArrayList也是线程不安全的 , Vector虽然线程安全, 但由于是在方法上直接加锁, 锁的力度太大, 导致效率也不高, 所以就出现了CopyOnWriteArrayList
我们了解 , 在正常的程序中, 读操作远远大于写操作, CopyOnWriteArrayList 就采用了读写分离的做法, 因为读操作并不会影响数据的值, 所以读操作是没有必要去加锁的 , 多个线程同时去访问读取 list 也是没有事情的 , 写操作单独加锁就行 , 相对于Vector而言 , Vector甚至在读操作上都加了synchronized锁 , 那么可想而知它的效率肯定就跟不上了
另外 , CopyOnWriteArrayList 的一个比较厉害的点就是 : 写入也不会阻塞读取操作,只有写入和写入之间需要进行同步等待,读操作的性能得到大幅度提升。我们下面来说这点是如何做到的
我们来看CopyOnWriteArrayList底层的 add() 与 get()方法是怎样去做的
add() 方法如下 :
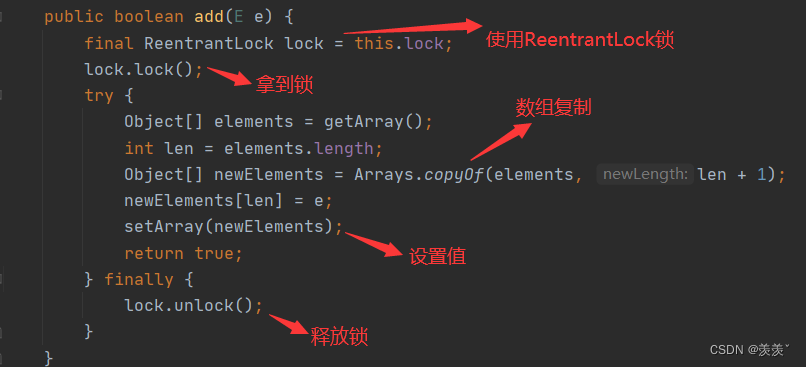
我们可以注意到 , add() 方法中复制了一个新数组 , 为什么有这一步操作呢 ?
原来, CopyOnWriteArrayList中涉及到对数据的操作 , 如add(), set()等, 每次都会去创建原数组的副本, 然后才会去进行写操作 , 在副本中进行写操作之后, 再将副本中的数据替换原数组的数据, 这样做的目的是为了保证读与写操作之间互不影响(也就是说, 即使在写的过程中, 其他线程也是可以去进行读操作的)
get()方法如下 :
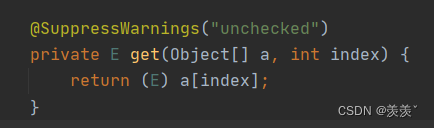
可以发现, get() 方法并没有加任何的锁, 这就使得CopyOnWriteArrayList完美的实现了读写分离
CopyOnWriteArraySet
在集合的容器类体系中, 我们知道, List接口底下的实现类存储的数据是可重复的, 而Set接口底下的实现类都是不可重复的, 当然CopyOnWriteArraySet也一样 , 不过它和 HashSet 与 TreeSet不同 , HashSet不重复和无序性是因为 它使用了HashMap的key(键)作为了自己的底层数据结构, 我们知道hashMap的键是不可重复的 , 而 TreeSet也是使用了TreeMap作为自己的底层, 但CopeOnWriteArraySet与他两却不同 , 我们来看它的源码实现 ,如下:

可以发现, 它的底层竟然使用的是CopyOnWriteArrayList , 所以我们可以断定它是有序的, 而不像HashSet等是无序的, 当然它也具有CopyOnWriteArrayList的大部分特性
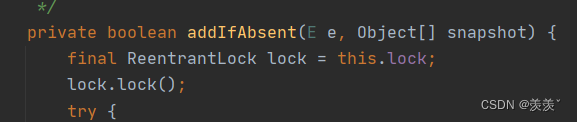
通过它底层的add() 方法可以看出, 在添加数据时做了判断, 不加入重复的数据
CountDownLatch
CountDownLatch是一个辅助类, 这个类可以使得一个线程等待其他线程各自执行完毕后再执行, 它通过一个计数器实现, 计数器的初始值是等待线程执行的数量, 当一个线程执行完毕后, 这个计数器就 - 1, 当计数器为 0 时, 等待中的线程才可以执行
public static void main(String[] args) throws InterruptedException {
CountDownLatch downLatch = new CountDownLatch(6);//计数
for (int i = 0; i < 6 ; i++) {
new Thread(
()->{
System.out.println(Thread.currentThread().getName());
downLatch.countDown();//计数器减一操作
}
).start();
}
downLatch.await();//关闭计数
System.out.println("main线程执行");
}上面代码的意思是 : 计数器为6, 我们创建6个线程, 每个线程执行完后计数器 -1 , 当计数器为0 时, 执行await() 方法关闭计数, 此时main()线程才能继续执行
相当于一个减法计数器
CyclicBarrier
CyclicBarrier也是一个辅助类, 相对于CountDownLatch来说, 它可以当做一个加法计数器, 它是对一组线程到达一个屏障时被阻塞, 直到最后一个线程到达时, 才会放行它们, 每当一个线程到达,计数器就加 1 ,达到期待值时放行
它有两个构造方法:
public CyclicBarrier(int parties)
public CyclicBarrier(int parties, Runnable barrierAction)
对于第二个构造方法, 第一个参数是计数的值, 第二个参数是最后一个线程到达时要做的事情
public static void main(String[] args) {
CyclicBarrier c = new CyclicBarrier(5, ()->{
System.out.println("大家都到齐了 ");
});
for (int i = 0; i < 5; i++) {
new Thread(
()->{
System.out.println(Thread.currentThread().getName());
try {
c.await();//加一计数器
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}
).start();
}
}以上代码表示当阻塞线程到达5 时放行它们















 3431
3431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









