







论文笔记-Hybrid Retrieval-Generation Reinforced Agent for Medical Image Report Generation
创新点:混合检索生成+强化学习
report 包括finding,impression,comparison和indication。其中finding部分的内容包括心脏大小、肺阴影、骨结构、肺、主动脉、肺门等部位的异常,以及积液、气胸、实变等潜在疾病的内容。并发现这些内容是有顺序的,例如心脏大小,纵隔轮廓,然后是肺不清,明显的异常,然后是轻度或潜在的异常。
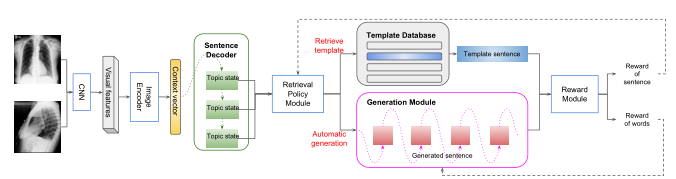
总体框架
论文建立一个层次结构框架,首先使用cnn提取图像特征转化成上下文向量然后通过增加了注意力机制的rnn,生成一系列句子主题,然后预测每个主题的句子词汇,使用retrieval policy module模块判断主题然后决定是通过generation module自动生成句子还是在模板库(模板数据库是基于从可用的医疗报告中收集的人类先验知识建立的,由一组在训练语料库中经常出现的句子组成,通常描述一般的观察)中检索特定句子然后通过分层决策依次生成多个句子。然后利用强化学习(增强算法)在句子级和词级奖励分别训练retrieval policy module和generation module。
细节
- rnn的主题生成过程
c
i
s
c^s_i
cis为生成的上下文向量,
h
i
s
h^s_i
his为当前时间步隐藏向量,
q
i
q_i
qi为生成的主题,
z
i
z_i
zi为句子主题生成的控制概率[0,1]
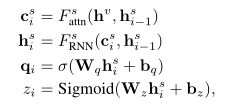
- retrieval policy module:给一个生成主题
q
i
q_i
qi,预测在自动生成生成新句子和候选模板|T|中的概率
u
i
∈
R
1
+
∣
T
∣
u_i\in{R^{1+|T|}}
ui∈R1+∣T∣,
u
0
u_0
u0表示自动生成的概率,后面的表示在T中选择模板的概率,
m
i
m_i
mi是概率最高的索引,如果
u
0
u_0
u0最大,则进行generation module,如果其他的大,则在候选模板中选择概率最大的模板作为生成句子
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dj8tHgPI-1645262081927)(C:\Users\诃西\AppData\Roaming\Typora\typora-user-images\image-20220219093307798.png)]](https://img-blog.csdnimg.cn/4b0457c0a664462389f0943a2236482d.png)
- Generation module:基于生成主题
q
i
q_i
qi和图像上下文向量
h
v
h^v
hv作为原始输入的RNN,
h
i
,
t
g
h^g_{i,t}
hi,tg为当前时间步的隐藏向量,
a
t
a_t
at为所有词的概率分布,
y
t
y_t
yt为取最大的概率索引单词为one-hot,
e
i
,
t
e_{i,t}
ei,t为该序列生成的单词
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W69fw1s7-1645262081928)(C:\Users\诃西\AppData\Roaming\Typora\typora-user-images\image-20220219094220050.png)]](https://img-blog.csdnimg.cn/3b7395d513f1493a9434759f04cba57c.png)
- 强化学习:句子奖励:生成的第i个句子
y
i
=
(
y
i
,
1
,
y
i
,
2
,
.
.
.
,
y
i
,
N
,
)
\pmb{y_i}=(y_{i,1},y_{i,2},...,y_{i,N},)
yiyiyi=(yi,1,yi,2,...,yi,N,)计算CIDEr得分
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FBTt5PtF-1645262081930)(C:\Users\诃西\AppData\Roaming\Typora\typora-user-images\image-20220219095730281.png)]](https://img-blog.csdnimg.cn/9b7361c8e4eb48b98c3a32b7117d309c.png)
词级奖励:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HSUALRsn-1645262081946)(C:\Users\诃西\AppData\Roaming\Typora\typora-user-images\image-20220219095802440.png)]](https://img-blog.csdnimg.cn/028e2bc436b64b0d8a3ebd3ab3f463f5.png)
gt为真实报告
- 损失函数: Y Y Y为生成报告, Y ∗ Y^* Y∗为真实报告
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K0GvbYem-1645262081948)(C:\Users\诃西\AppData\Roaming\Typora\typora-user-images\image-20220219102331323.png)]](https://img-blog.csdnimg.cn/12f5ad53ae794196920affabd049b2bc.png)
1
(
)
1()
1()为二进制指示器,
z
i
z_i
zi为上面提到的主题生成的控制概率,
m
i
m_i
mi是上面提到的最大索引,
L
(
θ
)
L(\theta)
L(θ)有两部分组成,retrieval policy module中的损失
L
(
θ
r
)
L(\theta_r)
L(θr)和generation module中的损失
L
(
θ
g
)
L(\theta_g)
L(θg)。
L
(
θ
r
)
L(\theta_r)
L(θr)由句子级奖励影响,其中
θ
r
\theta_r
θr包括前面retrieval policy module中的参数
W
u
W_u
Wu和
b
u
b_u
bu。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6Cyuyb7R-1645262081950)(C:\Users\诃西\AppData\Roaming\Typora\typora-user-images\image-20220219143041444.png)]](https://img-blog.csdnimg.cn/0ab964c4ad8b4a1b9ddb0f1dfbdf2833.png)
L
(
θ
g
)
L(\theta_g)
L(θg)由词级奖励影响,其中
θ
g
\theta_g
θg由前面generation module中的
W
y
W_y
Wy、
b
y
b_y
by和
W
e
W_e
We等其隐藏参数构成。















 633
633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









