







循环神经网络学习笔记一(吴恩达深度学习)
一、序列模型
例如语音识别中给定输入的音频片段x输出对应的文字记录y,输出输入都是序列数据;音乐生成问题,只有输出数据y是序列,输入可以是空集也可是数字代表想要的音乐风格或音符;情感分类问题,输入x是序列等等
定义符号
使用x<1>, x<2>, ……,x<t>……来表示一句话中的各个单词 使用t索引序列中的位置,用y<1>, y<2>, ……来表示输出数据,同时使用Tx,Ty表示输入和输出序列的长度,输入输出长度可以不同。
使用x(i)<t>表示训练样本i的序列中的第t个元素 ,Tx(i)表示第i个训练样本的输出序列长度,输出同理
通过建立n维向量词表做到用一个n维向量来表示一个单词,即用ont-hot向量表示,ont-hot的意思是向量中只有一个值是1,其余为0

二、循环神经网络
1、前向传播
每个单词x<t>传入一个神经网络上时都会受到前一个单词的激活值的影响然后输出预测值
y
^
\widehat{y}
y
<t>,这个例子中Tx=Ty。即,在预测
y
^
\widehat{y}
y
<t>时,不仅受到x<t>的影响,还会通过循环受到x<t-1>,x<t-2>……x<1>的影响,但是循环神将网络的缺点是他只使用了序列前的信息进行预测,双向循环神经网络就解决了这个问题,后面会进行讲解。

计算预测值和激活值的方法如下图所示,即循环神经网络的前向传播,使用的激活函数g有可能不同

我们将[waa wax]定义为Wa,所以上面框起来的通式便可以简化成下图右上角的形式,其中下面式子中的[a<t-1>, x<t>]是a<t-1>和x<t>竖着堆叠起来的列向量,这样我们就可已将Wya定义成Wy,这样Wy便是计算
y
^
\widehat{y}
y
的参数,Wa是计算a的参数

2、反向传播
反向传播的方向与前向传播基本上是相反的,也叫时间反向传播。
首先定义损失函数,
y
^
\widehat{y}
y
是这单词对应的概率值,y是1或0,定义损失函数为交叉熵损失函数
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
=
−
y
<
t
>
log
y
^
<
t
>
−
(
1
−
y
<
t
>
)
log
(
1
−
y
^
<
t
>
)
L^{<t>}(\hat{y}^{<t>}, y^{<t>})=-y^{<t>}\log\hat{y}^{<t>}-(1-y^{<t>})\log(1-\hat{y}^{<t>})
L<t>(y^<t>,y<t>)=−y<t>logy^<t>−(1−y<t>)log(1−y^<t>)
整个序列的损失函数就是
L
(
y
^
,
y
)
=
∑
t
=
1
T
x
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
L(\hat{y},y)=\sum^{Tx}_{t=1}L^{<t>}(\hat{y}^{<t>}, y^{<t>})
L(y^,y)=t=1∑TxL<t>(y^<t>,y<t>)
然后根据损失函数使用梯度下降等算法进行反向传播

3、其他类型的循环神经网络
在Tx不等于Ty时,有多对一,一对多,多对多多种情况。
如对一句话进行判断电影的评价,输出只有一个,便可以对之前的RNN模型进行简化,只在最后一个时间上得到输出,这就称为多对一结构。如下图右面的结构图

除了多对一的结构还有一对多的结构,比如音乐生成的例子,输入一个x或是空集,得到多个输出,生成序列时会将之前的输出输入到下一层中,不理解的可以看下图左侧图中的红色线部分

对于多对多的结构除了上一小节中讲的Tx等于Ty的情况,还有,不相等的情况,如将法语翻译成英语的情况,输入和输出不一定相等,这个时候就需要一个新的网络结构,如上图中右侧图的结构图,用编码器获得输入,使用解码器读取输入然后进行输出 。
4、语言模型和序列生成
在进行语音识别时,读法相同的两句话,系统可以选择出正确的一句,依靠的就是语言模型判断两句话正确的概率。语言模型就是判断一句话或者说是一个文本序列(y<1>, y<2>, ……,yTy)可能出现的概率P 。
建立一个这样的语言模型,需要一个训练集,包含一个很大的英文文本语料库
语料库就是数量众多的句子组成的文本。
语言模型:第t次的预测输出
y
^
\widehat{y}
y
<t>为在前t-1次的输入的前提下输出词典中各个单词以及结束标志<EOS>和未知词<UNX>的概率,这个可以计算出在前面单词的前提下这个单词的出现概率

整个句子的概率就是这些概率的乘积,例如只有三个单词的句子概率如下所示
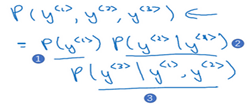
代价函数为
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
=
−
∑
i
y
i
<
t
>
log
y
i
^
<
t
>
L^{<t>}(\hat{y}^{<t>}, y^{<t>})=-\sum_iy_i^{<t>}\log\hat{y_i}^{<t>}
L<t>(y^<t>,y<t>)=−i∑yi<t>logyi^<t>
L
=
∑
t
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
L=\sum_tL^{<t>}(\hat{y}^{<t>}, y^{<t>})
L=t∑L<t>(y^<t>,y<t>)
5、新序列采样
在你训练一个序列模型之后,要想了解到这个模型学到了什么,一种非正式的方法就是进行一次新序列采样,来看看到底应该怎么做。
首先对得到的
y
^
\widehat{y}
y
<1>里面的各个单词的概率值进行随机采样,将取得值作为下一个x<2>输入,再对
y
^
\widehat{y}
y
<2>进行随机采样,依次类推直到采样得到<EOS>句子结束,停止采样

6、梯度消失
基础的RNN模型有一个很大的问题就是梯度消失问题。如果很深的神经网络,得到的y很难通过反向传播影响前面层的计算,这样便导致后面产生的词很难收到前面词的影响。
下面几小节便讲一下解决梯度消失的方法
1、GRU
从上一节的循环神经网络的基础结构可以画出下图的单元图,即输入a<t-1>和x<t>后使用参数wa、ba通过tanh激活函数后得到a<t>,在通过softmax等方法得到预测值
y
^
\widehat{y}
y
<t>,这样如果神经网络够深,前面的a是很难影响后面的结果的。

GRU定义了一个新的变量c,称为记忆细胞,可以记忆前面对后面有影响的激活值。
我们先令c<t>=a<t>,在每个时间步t上用一个候选值
c
~
\widetilde{c}
c
<t>重写c<t>,即更新c<t>
c
~
<
t
>
=
tanh
(
W
c
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
\tilde{c}^{<t>}=\tanh(W_c[c^{<t-1>},x^{<t>}]+b_c)
c~<t>=tanh(Wc[c<t−1>,x<t>]+bc)
然后定义一个更新门
Γ
u
\Gamma_u
Γu,值的范围在0-1之间,所以可以用sigmoid函数来得到
Γ
u
=
σ
(
W
u
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
u
)
\Gamma_u=\sigma(W_u[c^{<t-1>},x^{<t>}]+b_u)
Γu=σ(Wu[c<t−1>,x<t>]+bu)
Γ
u
\Gamma_u
Γu是用来决定什么时候用
c
~
\widetilde{c}
c
<t>来更新c<t>的,更新的公式为:
c
<
t
>
=
Γ
u
∗
c
~
<
t
>
+
(
1
−
Γ
u
)
∗
c
<
t
−
1
>
c^{<t>}=\Gamma_u*\tilde{c}^{<t>}+(1-\Gamma_u)*c^{<t-1>}
c<t>=Γu∗c~<t>+(1−Γu)∗c<t−1>
这样就可以看出如果
Γ
u
\Gamma_u
Γu为1,便将
c
~
\widetilde{c}
c
<t>赋值给c<t>,若为0,则c<t>仍然为旧的值c<t-1>,a<t>=c<t>。

如果中间大部分单词的
Γ
u
\Gamma_u
Γu很接近0,则会大程度的维持住前面的c,这样前面的c便可以影响到后面的值,缓解了梯度消失的问题
注:这里的c可以是一个向量,里面的值便是一些要更新的比特,
c
~
\widetilde{c}
c
、
Γ
u
\Gamma_u
Γu也是相同维度的向量,这样就可以根据
Γ
u
\Gamma_u
Γu保持一些比特,更新其他比特。
上图就是一个简化过的GRU单元,完整的GRU单元需要给记忆细胞的候选值增加一个新的门
Γ
r
\Gamma_r
Γr告诉你计算出的下一个c<t>的候选值
c
~
\widetilde{c}
c
<t>跟c<t-1>有多大的相关性。(这里还需要新的参数Wr和br)
Γ
r
=
σ
(
W
r
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
r
)
\Gamma_r=\sigma(W_r[c^{<t-1>},x^{<t>}]+b_r)
Γr=σ(Wr[c<t−1>,x<t>]+br)

2、LSTM
LSTM定义了三个门,更新门,遗忘门和输出门,同时在LSTM中不再有a<t>=c<t>的情况,于是控制LSTM行为的公式就变成了下图左上角的公式

7、双向循环神经网络
前面说过,普通的循环神经网络
y
^
\widehat{y}
y
<t>只受前面t-1个信息的影响,而双向的RNN还能受到后面信息的影响。这种改进方法不仅能用于基础的循环神经网络还适用于GRU和LSTM。
双向的RNN就是在普通的RNN中添加反向连接,从a<Tx>开始向前进行前向传输,这样就可以得到两个方向的a<t>,然后再进行预测
y
^
<
t
>
=
g
(
W
g
[
a
→
<
t
>
,
a
←
<
t
>
]
+
b
y
)
\hat{y}^{<t>}=g(W_g[\overrightarrow{a}^{<t>},\overleftarrow{a}^{<t>}]+b_y)
y^<t>=g(Wg[a<t>,a<t>]+by)
8、深层循环神经网络
深层神经网络在得到
y
^
\widehat{y}
y
时会通过n个神经节点,这些也可以用到RNN中,我们定义a[m]<n>表示第t个时间步上的第m层的激活值。计算方法如图所示,每层的参数w和b是相同的

这种深层的RNN很少有很多层堆叠,有三层已经很多了,但另一种情况会更常见些,就是在将预测y改成深层的网络进行预测输出,并没有水平方向上的连接,这种类型用的会稍微多一些.
总结
RNN的基础知识已经结束了,后面将会介绍一些NLP(自然语言处理)等问题。















 1403
1403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









