







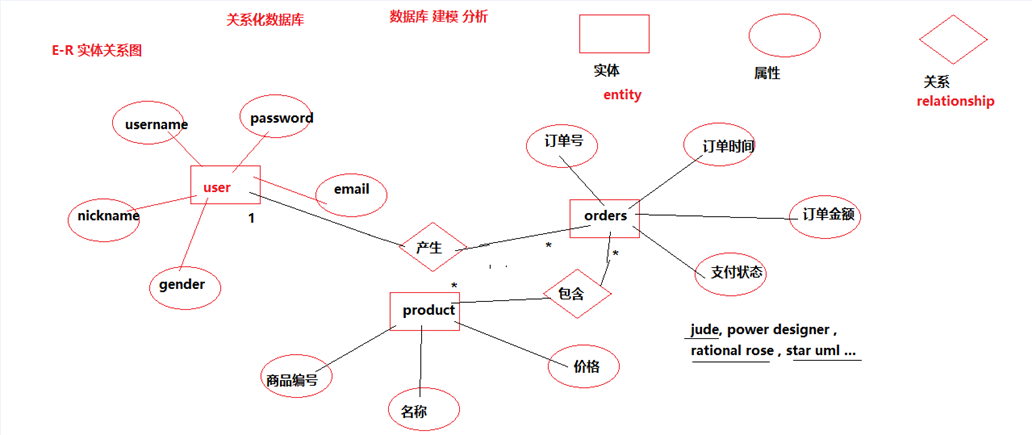
1.E-R实体关系图介绍1.E-R实体关系图介绍

关系化数据库就是用来保存有实体关系的 数据的 软件.
实际开发过程中,一套 标准的流程是 画E-R实体关系 图, 做数据库建模分析, 分析 实体之间的 关系, 确定
需要的 属性信息, 最终 建立 不同的表, 从而完整的 去描述 实体 之间的关系.
2.常见的关系型数据库介绍
MYSQL 是一种小型的数据库,适合小规模的网站使用, Hadoop 架构实现数据库集群提升性能
SQLite 小型的 专门用在嵌入式设备的数据库, 手机,pad等-------------适合安卓,安卓的默认集成数据库
安卓和IOS、Winphone都用sqlite
IBM的DB2 卖的一套解决方案,DB2和WebSphere web 服务器一起卖
DBA –数据库管理员,按天结算工资
数据库只是一个软件, 这个软件 帮组咱们将 数据以特定的形式保存到硬盘上去了, 并且 可以使用 标准的 sql 语句去操作他们.
关系型 数据库都支持 标准的sql 语句去操作的.
Mysql 的使用必须要先安装...
3.如何卸载mysql
假设你已经安装了一个msyql 数据库, 安装失败了 .
第一步:
进到 你安装的文件夹下 . 找到 这个 文件


进到 控制 面板,然后 卸载掉 ...
同时 进到 c盘的安装文件夹, 将 整个 mysql 文件夹给删掉.
第二步:
进入到 如上的数据保存的位置 ..

结论: 如果安装的时候 出现了问题, 就按照 如上的步骤去完整的卸载.
4.mysql的安装
Mysql 有多个版本, 你直接去网上 下一个就可以了.

双击 傻瓜式的一步步往下走 就可以了
如下是需要 注意的 步骤, 其他的 没有列出来 就 默认继续可以往下走.
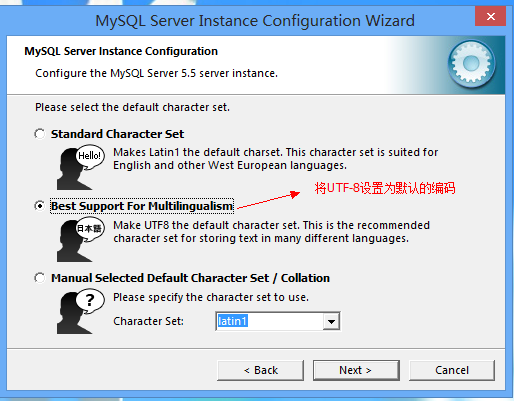
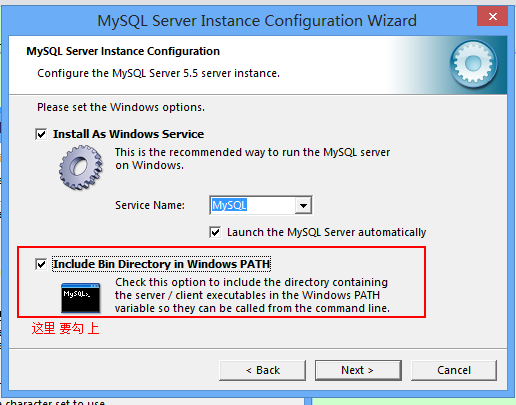
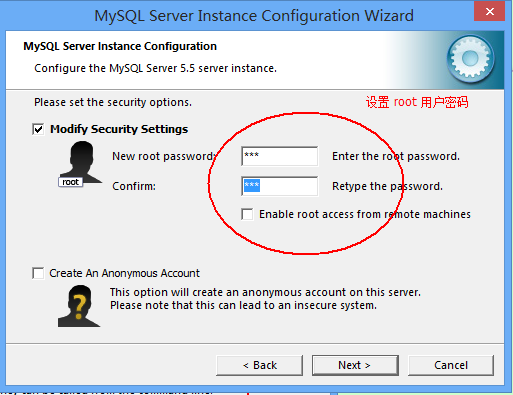
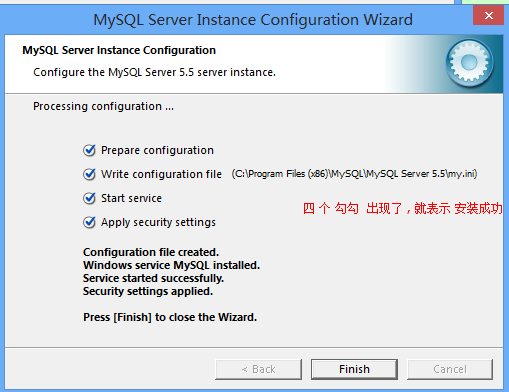
使用dos 命令行,
敲 一个 mysql , 如果没有出现 既不是内部命令, 也不是外部 命令, 那么 就 o 了 .
5.数据库服务器&数据库&表的关系
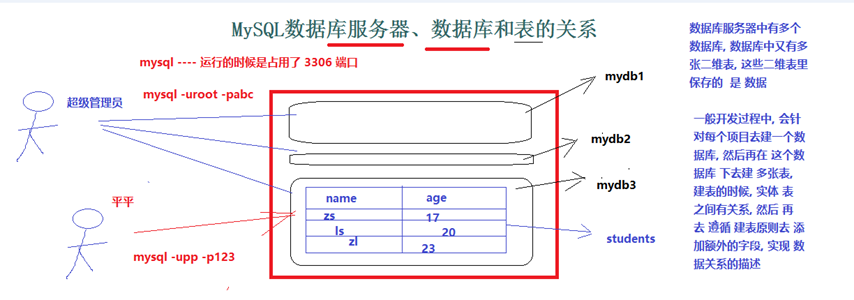

使用 mysql -- help 查看mysql的命令参数
6.表中的数据是怎样存的&表示的是什么
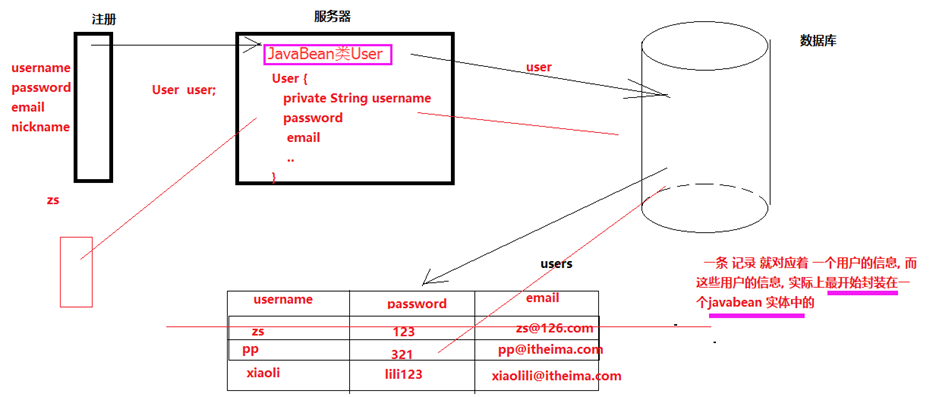
7.sql语句分类


8.DDL语句之操作数据库相关的语句

+++++++++++++++++++++++++++++++++++DDL 语句 +++++++++++++++++++++++++++++++++++
====创建数据库
语法:
create database 数据库名称 character set 编码集 collate 比较规则;
练习:
创建一个名称为mydb1的数据库。
create database mydb1;
创建一个使用utf8字符集的mydb2数据库。
create database mydb2 character set utf8;
创建一个使用utf8字符集,并带校对规则的mydb3数据库。
create database mydb3 character set utf8 collate utf8_general_ci;
首先查看下现有的数据库:
show databases;
查看数据库的建库语句:(如何创建数据库)
show create database mydb2;
删除数据库:
语法:
drop database 数据库名称;
练习:
查看当前数据库服务器中的所有数据库
show databases;
查看前面创建的mydb2数据库的定义信息
show create database mydb2;
删除前面创建的mydb1数据库
drop database mydb1;
修改数据库:
语法:
alter database 数据库名称 更改后的信息;
切换数据库:
use 数据库名称;
查看当前使用的数据库:
select database();
练习
查看服务器中的数据库,并把其中某一个库的字符集修改为gbk;
show databases;
alter database mydb2 character set gbk;
9.mysql中列的数据的类型
==== 如何创建表
表是二维表, 有行有列 , 表中存的一行行的记录, 每一行记录对应着 javabean 的一个实体
语法:
create table 表名
(
字段一 字段类型,
字段二 字段类型,
字段三 字段类型(这里没有逗号)
);
字段一, 字段二... 就是二维表的 列的名称, 但是每一列实际上是有列的 数据的类型的
而这里每一行都对应着 javabean的一个实体,javabean 中每个 字段的数据是有具体的类型的,
在msyql 中 的字段的类型与 java中的字段类型又 是怎样的对应 关系呢?
java与MYSQL的类型对应关系
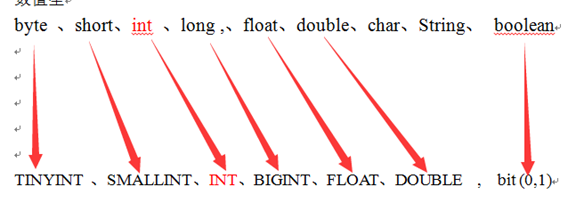
java 中:
byte, short ,int ,long , float,double, char,String, boolean
mysql: (C 语言写的)
数值型
TINYINT 、SMALLINT、INT、BIGINT、FLOAT、DOUBLE , bit (0,1)
字符串型
VARCHAR、CHAR
varchar(1), char(1)
varchar(5), char(5)
大数据类型
BLOB(字节流)、TEXT(字符流)
字符流字节流
text:
blob:
日期型
DATE(只有日期)、TIME(只有时间)、DATETIME(有日期,有时间)、
TIMESTAMP(时间戳,是自动生成的,不需要人工是维护)(就是当前的时间)
10.创建员工表
练习:
创建一个员工表employee:
字段 属性
id 整形 int
name 字符型 varchar(20)
gender 字符型 varhcar(10)
birthday 日期型 date
entry_date 日期型 date
job 字符型 varchar(100)
salary 小数型 float
resume 大文本型 varchar(255)
代码:
create table employee
(
id int,
name varchar(20),
gender varchar(10),
birthday date,
entry_date date,
job varchar(100),
salary float,
resume varchar(255)
);
查看数据库下表:
-- 会将当前数据库下所有的表都 都列出来(这叫做注释)
show tables;
11.单表约束的(主键约束,非空约束,唯一约束)
查看表结构:
desc 表名;
desc employee;
查看 表的创建语句:
show create table employee;
| employee | CREATE TABLE `employee` (
`id` int(11) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
`gender` varchar(10) DEFAULT NULL,
`birthday` date DEFAULT NULL,
`entry_date` date DEFAULT NULL,
`job` varchar(100) DEFAULT NULL,
`salary` float DEFAULT NULL,
`resume` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
定义单表字段的约束:
不管是单表还是多表, 添加约束的都是为了保证数据库中表的数据的有效性和完整性
单表约束:
a) 主键约束 --- 不允许 为空, 也不允许 重复
b) 唯一约束----不允许重复
c) 非空约束-----不允许为空
对于以上三种 约束, 通常会根据需求 将某些字段设置为 非空, 唯一约束或者 主键约束
其中 设置 某个字段为主键约束时, 如果那个 字段是 数值 类型, 那么通常可以在主键约束后
加上 auto_increment (表示主键的值自动增长),
create table emp2
(
id int primary key auto_increment,
name varchar(20) not null,
gender varchar(10) not null,
birthday date,
entry_date date,
job varchar(100),
salary float not null,
resume varchar(255)
);
12.修改表的信息(很复杂)
======修改表:
添加列:
语法:
alter table 表名 add 列名称 列字段类型;
修改列:(不改列名,只改类型)
alter table 表名 modify 列名称 列字段类型;
删除列:
alter table 表名 drop 列名;
修改表的名称:(这个不是alter开头,是rename)
rename table 表名 to 新表名;
修改列的名称(类型、列名同时改):
alter table 表名 change 现有的列的名称 新的列的名称 新的列的类型;
修改表的字符集:
alter table 表名 character set utf8;
练习
在上面员工表的基本上增加一个image列。
alter table employee add image blob;
修改job列,使其长度为60。
alter table employee modify job varchar(60);
删除gender列。
alter table employee drop gender;
表名改为users。
rename table employee to users;
修改表的字符集为utf8
alter table users character set utf8;
列名name修改为username
alter table users change name username varchar(30);
13.插入数据的三种语法

++++++++++++++++++++++DML语句+++++++++++++++++++++++++++++++++++
dml 语句 包括 ,增加(insert ), 删除(delete) , 修改 (update)
=====insert 语句:
插入数据记录到表中
语法:
insert into 表名 (列名一,列名二,列名N) values(列一的值,列二的值,列N的值);
第一种写法(全部都写):
insert into users (id,username,birthday,entry_date,job,salary,resume,image) values(1,'bb','1995-09-09','2015-07-15','developer',15000,'a good boy','not uploaded');
第二种写法(只写部分,但是缺少的部分必须可以为空,即没有NOT NULL):
insert into users (id,username,entry_date,job,salary,resume) values(2,'pp','2015-06-30','project manager',20000,'a hansome man');
第三种写法
(不写列名,直接写值,所有的值都要按照表的列的顺序去写):
insert into users values(3,'junjie','1993-10-10','2015-08-02','a good coder',21000,'a lady killer','clik to visit');
注意: 以上三种语法中用的最多的是 第三种.
14.dos命令行插入中文数据乱码解决
没有设置,插入中文导致乱码
insert into users values(3,'童林','1999-10-10','2015-08-10','a good boy',22000,'一个钻石王老五的哥们','点我吧');
错误提示:
mysql> insert into users values(3,'童林','1999-10-10','2015-08-10','a good boy',22000,'一个钻石王老五的哥们','点我吧');
ERROR 1366 (HY000): Incorrect string value: '\xC1\xD6' for column 'username' at row 1
解决方式:
两种
方式一(临时的解决):
只针对当前的窗口有效
set names gbk;
方式二(一劳永逸的解决):
进到 mysql安装文件夹下, 将编码改为 gbk ,然后重新启动mysql的服务就可以了.
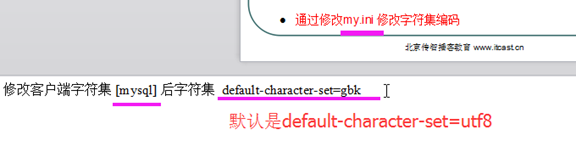
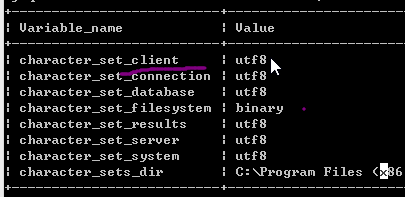
show variables like 'character%';(单纯的显示编码类型)
15.为什么会出现乱码
因为DOS命令行的编码格式为GBK,但是MYSQL数据库设置客户端的编码格式为utf8,所以出现了编码不一致的情况

16.更新表中的记录&删除表中的记录
=====update 语句:
主要用于对表中现有的数据进行更新操作
语法:
update 表名 set 列名一=列名的值,列名二=列名的值,列名三=列名...;
where 从句-- 加上限定条件, 只有满足条件的才会被修改,更新
不加where 从句, 那就是所有的都更新
要求
将所有员工薪水修改为5000元。
update users set salary=5000;
将姓名为'pp'的员工薪水修改为6000元。
update users set salary=6000 where username='pp';
将姓名为'junjie'的员工薪水修改为4000元,job改为ccc。
update users set salary=4000,job='ccc' where username='junjie';
将童林的薪水在原有基础上增加1000元。
update users set salary=salary+1000 where username='童林';
=====delete 语句:
删除表中的数据
语法:
delete from 表名 [where从句];
如果不加where 从句,就会全部删除
练习:
删除表中名称为'阿花'的记录。
delete from users where username='阿花';
删除表中所有记录。
-- 属于 DML语句
delete from users;
使用truncate删除表中记录。
-- 先将表给摧毁,然后新建一个同样的表
-- 属于DDL语句
truncate users;
17.select语句的使用(一)
++++++++++++++++++++++++DQL语句++++++++++++++++++++++++++++++++++++
DQL 语句, 指的是使用sql 语句对数据库表中的记录做查询操作 .
关键字是 select , 非常的复杂,
create table exams(
id int,
name varchar(30),
chinese double,
english double,
math double
);
insert into exams values(1,'马云',96,97,55);
insert into exams values(2,'童林',88,92,91);
insert into exams values(3,'何生',89,82,99);
insert into exams values(4,'何生2',89,83,91);
语法一:
select *| 列名一,列名二 from 表名;
select * from exams;
select distinct chinese from exams;(默认是没有distinct的,即会显示重复的数据)
练习:
查询表中所有学生的信息。
select * from exams;
查询表中所有学生的姓名和对应的英语成绩。
-- select 后面跟的是 最终显示的数据
select name,english from exams;
过滤表中重复数据。
-- 过滤表中语文重复的数据
select distinct chinese from exams;
练习
在所有学生分数上加5分特长分。
-- 这个语句只是将查询到的结果 进行 加法运算,并没有真正的修改表中的数据
select name,chinese+5, english+5,math+5 from exams;
统计每个学生的总分。
select name,chinese+math+english from exams;
使用别名表示学生分数。
select name as 姓名,chinese+math+english as 总分 from exams;
select name 姓名,chinese+math+english 总分 from exams;
使用where子句,进行过滤查询。
练习:
查询姓名为何生的学生成绩
select * from exams where name='何生';
查询英语成绩大于90分的同学
select * from exams where english>90;
查询总分大于255分的所有同学
select * from exams where chinese+math+english>255;
18.select语句使用时where从句后接的符号介绍
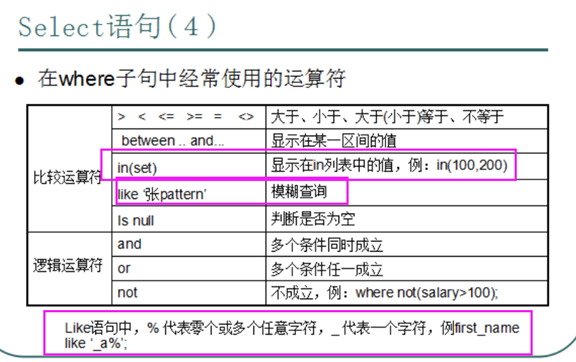
练习:
查询英语分数在 80-90之间的同学。
select * from exams where english>=80 and english<=90;
select * from exams where english between 80 and 90;
查询数学分数为89,90,91的同学。
select * from exams where math in(89,90,91,92,99);
查询所有姓何的学生成绩。
select * from exams where name like '何%';
查询数学分>80,语文分>80的同学。
select * from exams where math>80 and chinese>80;
注意点:
一:
Like语句中,% 代表零个或多个任意字符,_ 代表一个字符,例first_name like '_a%';
查询所有姓何的学生成绩。
select * from exams where name like '何__';
insert into exams values(5,'小何生',89,83,91);
查询名字中包含 何字 的哥们..
select * from exams where name like '%何%';
二:
and 和or ?
当一个sql语句中既有 and 还有or 时, 哪个先执行?
and 优先级 高于 or
select * from exams where math<80 or math>0 and english<90;
19.使用order_by进行排序输出
===== 使用order by 进行 排序===
order by 列名 desc|asc
asc: ascend 升序
desc: descend 降序
练习:
对数学成绩排序后输出。
-- 升序排列, 不加asc 时 默认的也是升序.
select * from exams order by math asc;
对总分排序按从高到低的顺序输出
select * from exams order by math+chinese+english desc;
对姓何的学生总成绩排序输出
select * from exams where name like '何%' order by math+english+chinese desc;
20.select语句中常见的聚合的函数的使用
====聚合函数 使用:
count ---- 用于 进行 求和, 求的是满足条件列的总的行数
练习:
统计一个班级共有多少学生?
select count(*) from exams;
统计数学成绩大于90的学生有多少个?
select count(*) from exams where math>90;
统计总分大于270的人数有多少?
select count(*) from exams where chinese+math+english>270;
sum求和运算
练习:
统计一个班级数学总成绩?
select sum(math) from exams;
统计一个班级语文、英语、数学各科的总成绩
select sum(chinese),sum(english),sum(math) from exams;
select sum(chinese) 语文总分,sum(english) 英语总分,sum(math) 数学总分 from exams;
统计一个班级语文、英语、数学的成绩总和
select sum(chinese+math+english) from exams;
统计一个班级语文成绩平均分
select sum(chinese)/count(*) 语文平均分 from exams;

avg--求平均
练习:
求一个班级数学平均分?
select avg(math) from exams ;
select sum(math)/count(*) from exams ;
求一个班级总分平均分
select avg(math+english+chinese) from exams;
聚集函数-MAX/MIN
求最大值,最小值
求班级数学最高分和最低分(数值范围在统计中特别有用)
select max(math),min(math) from exams;
21.使用分组进行筛选&select语句书写顺序小结
练习:
查询购买了几类商品,并且每类总价大于100的商品
select product,sum(price) from orders group by product having sum(price)>100;
where , having 的区别?
1.where 后面是不允许接 聚合函数的, 而having 是可以接 聚合函数的
2.where 是在分组前进行操作, having是在分组后操作.
select 语句中关键字的书写顺序?
select语句书写顺序:
s...f...w...g...h..o
select语句解析顺序:
f...w..g...h...s...o















 146
146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









