







文章目录
- 参考
- https://zhuanlan.zhihu.com/p/446607767
- https://mp.weixin.qq.com/s?__biz=Mzk0MjE3NDE0Ng==&mid=2247494866&idx=1&sn=0ebeb60dbc1fd7f9473943df7ce5fd95&chksm=c2c5967ff5b21f69030636334f6a5a7dc52c0f4de9b668f7bac15b2c1a2660ae533dd9878c7c&cur_album_id=1703494881072955395&scene=190#rd
IO流程
- 代码io流程

- 操作系统 read读函数 io流程

IO阻塞问题
服务端的线程阻塞在了两个地方,
- 一个是 接受连接 accept 函数,
- 一个是 read 读函数
该线程将会一直阻塞在 read 函数上不返回,也无法接受其他客户端连接。直到读取结束
方案1:多线程
每次都创建一个新的进程或线程,去调用 read 函数,并做业务处理。
为每个客户端创建一个线程,服务器端的线程资源很容易被耗光。
方案2:非阻塞 IO
一个线程接收多个客户端io,数据到达时(到达网卡并拷贝到了内核缓冲区),立刻返回一个错误值(-1),而不是阻塞地等待。

不是完全非阻塞
- 非阻塞的 read,指的是在数据到达前,即数据还未到达网卡,或者到达网卡但还没有拷贝到内核缓冲区之前,这个阶段是非阻塞的。
- 当数据已到达内核缓冲区,此时调用 read 函数仍然是阻塞的,需要等待数据从内核缓冲区拷贝到用户缓冲区,才能返回。
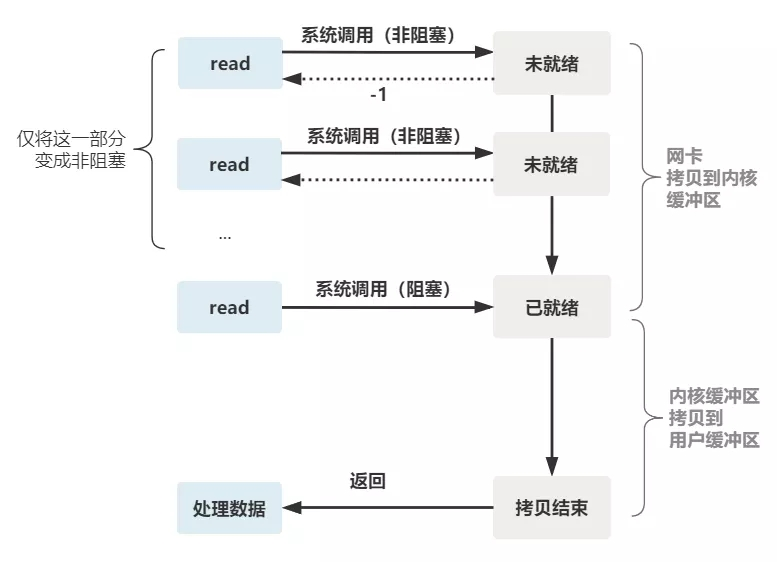
遇到 read 返回 -1 时仍然是一次浪费资源的系统调用。
IO多路复用
前提:操作系统能在同一个进程/线程中同时监听多个fd上的可读可写状态。
每 accept 一个客户端连接后,将这个文件描述符(connfd)放到一个数组里。
将这一批文件描述符通过一次系统调用传给内核,由内核层去遍历,才能真正解决这个问题。

IO多路复用模型
这里的多路指多个文件描述符(fd),复用指复用同一个进程/线程
-
多路复用就是一个线程处理多个socket
在网络服务中,IO多路复用起的作用是「一次性把多个连接的事件通知业务代码处理」。至于这些事件的处理方式,到底是业务代码循环着处理、丢到队列里,还是交给线程池处理,由业务代码决定。 -
单线程单IO 与 IO多路复用 对比
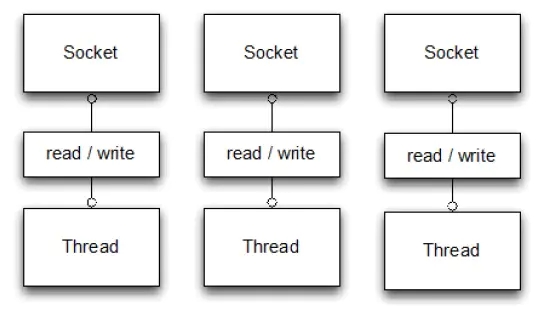
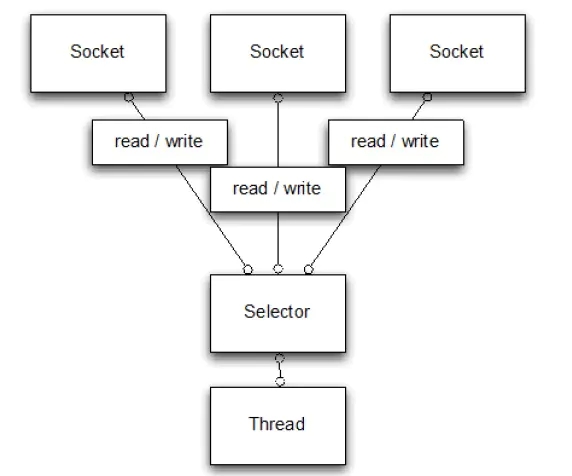
IO多路复用的内核(一个线程监视多个socket的原理)
- 客户端socket服务端时会产生三种
文件描述符(fd):writefds(写)、readfds(读)、和exceptfds(异常)。
通过一种机制(select、poll、epoll)一个线程可以监视多个描述符,一旦某个描述符就绪,能够通知程序进行相应的操作。
inux内核提供了select,poll,和epoll这3种I/O多路复用方案
- 整个处理过程只在select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是
事件驱动,所谓的reactor模式。
select
无差别轮询,select 只能监听 1024 个文件描述符
- 轮询
select会阻塞住监视文件描述符,等有数据、可读、可写、异常或超时。select线程就会执行; - 遍历
返回后通过遍历fdset整个数组来找到就绪的描述符fd,然后进行对应的IO操作。

select的三个缺点:
- 连接数受限
- 采用遍历文件句柄集合方式获取就绪的句柄,在文件连接数多的情况下效率低
- 内核用同步遍历的方式
- 数据由内核copy到用户态
- 缺点产生原因
- fd用数组存储,有长度限制
- select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)
- select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)
- select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
poll
与select一致,也是轮询+遍历;解决了select的问题1
唯一的区别就是poll没有最大连接数的限制(使用链表的方式存储fd)
epoll (event poll)
时间复杂度O(1),epoll为Linux独占
不是轮询的方式,用户socket对应的fd注册进epoll,然后epoll帮你监听哪些socket上有消息到达
只有活跃可用的FD才会调用callback函数;
即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
- 没有fd个数限制,用户态拷贝到内核态只需要一次,使用事件通知机制来触发。
- 通过epoll_ctl注册fd,一旦fd就绪就会通过callback回调机制来激活对应fd,进行相关的io操作。
比select的优化
- 内核中保存一份文件描述符集合,无需用户每次都重新传入,只需告诉内核修改的部分即可。
- 内核不再通过轮询的方式找到就绪的文件描述符,而是通过异步 IO 事件唤醒。
- 内核仅会将有 IO 事件的文件描述符返回给用户,用户也无需遍历整个文件描述符集合。
epoll之所以高性能是得益于它的三个函数:
1. epoll_create():创建一个用于事件轮询的数据结构
系统启动时,在Linux内核里面创建一个用于事件轮询的数据结构,返回epoll对象,也是一个fd
mmap\红黑树\就绪队列
2. epoll_ctl() 每新建一个连接,都通过该函数操作epoll对象,在这个对象里面修改添加删除对应的链接fd, 绑定一个callback函数
3. epoll_wait() 轮训所有的callback集合,并完成对应的IO操作
kqueue
epoll为Linux独占,而kqueue则在许多UNIX系统上存在
为什么数据库连接池不采用 IO 多路复用?
https://mp.weixin.qq.com/s/ZVdDBIyYPpLl9WPOSg4Tew
参考
https://www.zhihu.com/question/28594409
https://www.shuzhiduo.com/A/A7zgyBYY54/















 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









