







文章目录
AutoML作用
降低机器学习模型的开发门槛,算法的选择、训练、调优、部署等一系列过程都可以交给自动化组件来完成。
- 典型的机器学习流程
- 开发者必须学会数据预处理,特征工程,特征提取和特征选择方法,使数据集适合机器学习。
- 在这些数据预处理步骤之后,开发者必须选择合适的算法,并完成超参数及优化方法的选择。
- 自动化机器学习
开发者只需要提供数据,例如不同类别的图片。接下来,算法的选择,算法的训练,参数的调优,模型的部署等一系列过程都可以交给 AutoML 组件来完成
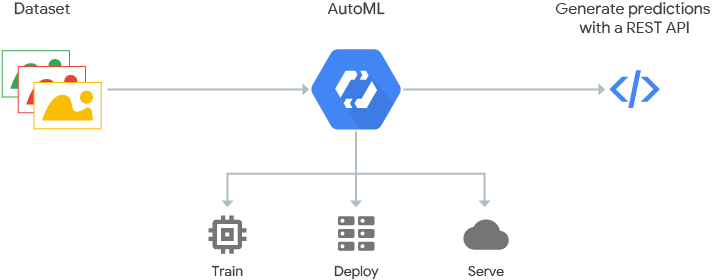
模块
自动化特征工程 Automated Feature Enginnering
主要包含像特征选择,特征提取,元学习,以及检测和处理不均衡数据或缺失数据等操作
特征选择(Feature selection)也被称为变量选择:为了构建模型而选择相关特征子集的过程
特征提取:可以被看作是数据降低维度的步骤
自动化模型选择 Automated Model Selection
传统的机器学习中,模型的选择一般由机器学习专家根据经验,以及交叉验证的结果来对比决定。
超参数自动优化 Hyperparameter Optimization
超参数是那些不是由机器学习算法本身学习出来的参数,而是需要人为设定的参数。
例如:
批量大小(batch size): 每次训练迭代使用的样本数量。
正则化因子(regularization factor): 用于控制模型复杂度,防止过拟合。
迭代次数(number of epochs): 模型训练的轮数。
神经结构搜索 Neural Architecture Search
深度学习的核心是人工神经网络,但搭建一个深度神经网络或涉及到大量的参数和超参数, 需要大量应用随机搜索 Random Search 或者网格搜索 Grid Search 方法来进行调参
AutoML 框架、服务
-
开源框架:例如 Auto-Keras,auto-sklearn 等开源工具本地完成。
auto-sklearn:基于 scikit-learn 开发的自动机器学习框架
Auto-Keras:深度学习框架 Keras 官方维护的自动深度学习框架。
NNI:由微软官方维护的自动深度学习框架,并支持 TensorFlow,PyTorch 等主流深度学习框架。 -
商业服务:例如 Google Cloud,Microsoft Azure 等云服务商工具在云端完成。
auto-sklearn
auto-sklearn API 主要分为 4 个部分:
Classification:分类问题相关的训练方法。
Regression:回归问题相关的训练方法。
Metrics:算法质量评估方法。
Extension Interfaces:扩展接口。
pip install auto-sklearn
# 分类
autosklearn.classification.AutoSklearnClassifier()
# 回归
autosklearn.regression.AutoSklearnRegressor()















 2287
2287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









